







这篇博客我写了简单和中等难度两个比对方法
1.简单的动态规划,得出基因的最短编辑距离
简介在注释中,代码如下:
#!/usr/bin/perl -w
use strict;
use autodie;
#这个程序就是一个简单的动态规划,它只能算出最短的编辑距离,理论上与Needleman-Wunsch 算法相似
#不同的是,这个dp矩阵存的是最短编辑距离,而Needleman-Wunsch 算法的dp矩阵存的是得分情况
#这题的思想是,dp矩阵第一行与第一列都是代表某一条序列对上一条空序列,所以距离逐渐加一
#其它的每一个位置,值的来源有三种(左上角、左边、上边)分别对应(序列对比上、序列没对比上、序列没对比上)后
#2种分别代表某一条序列删除或插入。dp矩阵的最后一个元素就是距离了
open IN,"<$ARGV[0]";
while(my $s1=<IN>){ #读取第一条序列,while循环是用来可读取多条的
chomp $s1;
chomp(my $s2=<IN>); #读取第二条1序列
my $l1=length $s1; #储存第一条序列长度
my $l2=length $s2; #储存第二条序列长度
my @as1=split //,$s1; #再把序列存在数组中,方便下面程序取出单个序列
my @as2=split //,$s2;
my @dp; #dp矩阵
$dp[0][0]=0; #起点为1,因为还未比对
for(1..$l1){ #第一行赋值,相当于一条序列对应一条空序列,所以每次加一
$dp[0][$_]=$_;
}
for(1..$l2){ #第一列赋值,相当于一条序列对应一条空序列,所以每次加一
$dp[$_][0]=$_;
}
for my $i(1..$l2){ #这里就是动态规划了,当前的2个碱基对应上了距离不变,没对应上都加一(在最小的基础上加一)
for(1..$l1){
if($as1[$_-1] eq $as2[$i-1]){
$dp[$i][$_]=$dp[$i-1][$_-1];
}else{
$dp[$i][$_]=&findmin($dp[$i-1][$_],$dp[$i][$_-1]);#这几行比对的是2个不同碱基比对上,删除,和缺失3种情况的最小值,取最小值加一
$dp[$i][$_]=&findmin($dp[$i][$_],$dp[$i-1][$_-1]);
$dp[$i][$_]++;
}
}
}
print "The shortest editing distance is: $dp[$l2][$l1]\n\n";
}
close IN; #关闭句柄
sub findmin{ #返回2个中较小值的子程序
# my $m1=shift @_;
# my $m2=shift @_;
my ($m1,$m2)=@_;
$m1<$m2?return $m1 : return $m2;
}
2.第二种方法就是生信中的Needleman-Wunsch 算法
有很多在线工具,他们比对的结果如下:

这里面的算法就有点复杂了,可视化的结果考虑了很多,“|”代表完全比对上,还有没比对上的工具也给了各种分类和评分,如插入删除“-”,相似“:”,最终找出最好的。
在我的程序中简化了许多。所有比对三种情况:
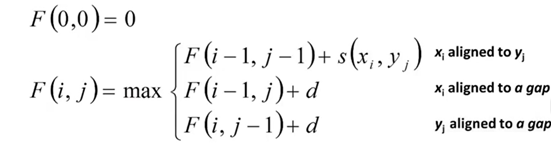
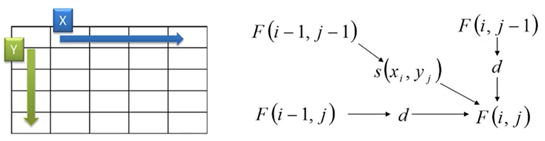
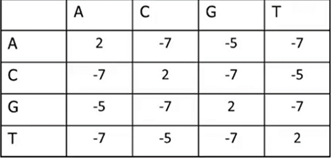
S(x_i+y_j)如下表:比如A对上A得2分,A对上C得 -7分。用哈希存储这个表
第二个和第三种情况的d统一取-5
有的时候最高得分相同的有许多种,要是全列出来程序会很长,所以就只显示出其中一种最优解:
如:AAG与AGC比较,按上面的规则最优解有2个,编辑距离都为2:
AAG- AAG-
-AGC A-GC
在程序中,当三条路径或其中两条得分相同时,优先级定为左上角 > 上 > 左
程序中,还使用了一个回溯矩阵,只含1,2,3,分别代表从左上角、 上 、左而来,方便打印出可视化对比情况。
代码如下:
#!/usr/bin/perl -w
use strict;
use autodie;
#对于程序的说明:这个程序采用的是生信的Needleman-Wunsch 算法,起源较早,算是最早的序列比对算法了
#Needleman-Wunsch 算法简介:首先创建一个二维的得分矩阵,行和列相等,都比序列长度大一,还要有一个数据结构储存打分表,即2种相同或不同的碱基对上得多少分
#我在这里用一个哈希表存储打分参考表,对于插入或删除要罚分,我在程序中都罚5分。然后还要一个二维矩阵存储每个元素的来源信息,便于在回溯时从终点回溯到起点
#程序输出信息:程序运行后,会有输出一个得分矩阵,一个回溯用的矩阵,2条序列比对的可视化,和最短编辑距离
#程序读取序列是从文件中读取,文件中只存在2个长度相等的序列,并非手动输入,程序在Linux下编写调试,运行时输入:perl 程序名 文件名 (linux中),
print "Enter 2 sequences in 1.txt file\n\n"; #请在1.txt文件中输入2条序列(没写循环一次比对多对序列)
open IN,"<$ARGV[0]";#读取文件,可以依据需要改成全路径或者相对路径,如把1.txt放在和.pl文件一起,只要把$ARGV[0]换成1.txt即可
chomp(my $s1=<IN>); #读取第一条序列,储存在$s1中
chomp(my $s2=<IN>); #读取第二条序列,储存在$s2中
close IN; #关闭文件句柄
my @as1=split //,$s1; #把第一条序列存在@as1数组中
my @as2=split //,$s2; #把第二条序列存在@as2数组中
my $l=length($s1); #将序列长度存在$l中,用在建立二维数组的长度
my @F; #@F二维数组用来存储对比的得分矩阵
my @huishuo; #@huishuo二维数组用来在最后的回溯中找到序列对比路径的信息
$F[0][0]=0; #第一个元素为0,因为此时得分为0
$huishuo[0][0]=0; #第一个元素为0,在后面用来终止回溯
for(1..$l){ #在此程序中我采用序列插入和缺失相同罚分,罚5分,这个for循环是将矩阵第一行和第一列打分。
$F[0][$_]=$F[0][$_-1]-5;
$F[$_][0]=$F[$_-1][0]-5;
$huishuo[0][$_]=3; #回溯矩阵中填3代表此空得分矩阵的值从左边来,2代表值从上边来,1代表从左上角来
$huishuo[$_][0]=2;
}
sub findmax{ #找三个数中的最大值子函数
# my $max1=shift @_;
# my $max2=shift @_;
# my $max3=shift @_;
my ($max1,$max2,$max3)=@_;
my $y=$max1>=$max2 ? $max1 : $max2;
return $y>=$max3 ? $y : $max3;
}
sub findfraction{ #打分表函数,用来打分,这里相同碱基对应上2分,不同的对应上是罚分
my %fraction=qw(AA 2 CC 2 GG 2 TT 2
AC -7 AG -5 AT -7
CA -7 CG -7 CT -5
GA -5 GC -7 GT -7
TA -7 TC -5 TG -7);
my $ij=shift @_; #$ij中储存着此时要比对的2个碱基
return my $f=$fraction{$ij};
}
for my $i(1..$l){ #填满得分矩阵
for(1..$l){
my $ij="$as1[$_-1]".$as2[$i-1]; #要填的空所对应的2个序列连起来,方便在哈希表中找分值
my $f1=$F[$i-1][$_-1]+&findfraction($ij);#从左上角过来(2个序列对上)的得分
my $f2=$F[$i-1][$_]-5; #第一条序列对应第二条序列上的空位的得分
my $f3=$F[$i][$_-1]-5; #第二条序列对应第一条序列上的空位的得分
$F[$i][$_]=&findmax($f1,$f2,$f3); #取最高分即为得分矩阵要填的分
if($F[$i][$_]==$f1){ #序列比对上则回溯矩阵记录1
$huishuo[$i][$_]=1;
}elsif($F[$i][$_]==$f2){
$huishuo[$i][$_]=2; #序列对应插入或者删除则回溯矩阵记录为2或3
}else{
$huishuo[$i][$_]=3;
}
}
}
print "The score matrix is as follows: \n";
for my $i(0..$l){ #输出得分矩阵
for(0..$l){
printf "%4d",$F[$i][$_];
}
print "\n";
}
print "\nThe matrix used for backtracking is as follows: \n";
for my $i(0..$l){ #输出回溯矩阵
for(0..$l){
print "$huishuo[$i][$_] ";
}
print "\n";
}
#以下是回溯
my @res1; #用来可视化输出第一条序列对比情况
my @res2; #用来可视化第二条序列对比情况
my $n; #记录最小编辑距离
&findpath($l,$l); #从终点开始回溯,$l在上面记录的是序列长度
sub findpath{
my $i=shift @_;
my $j=shift @_;
if($huishuo[$i][$j]==0){ #代表回朔到了起点,退出迭代
return;
}
if($huishuo[$i][$j]==1){ #回溯矩阵等于1时代表要向左上角回溯,即2个序列比对上了,没有插入和删除
unshift @res1,$as1[$j-1]; #取出当前位置的碱基放在储存可视化的数组中
unshift @res2,$as2[$i-1]; #同上
if($as1[$j-1] ne $as2[$i-1]){ #序列不一样时编辑距离加一
$n++;
}
&findpath($i-1,$j-1); #迭代
}elsif($huishuo[$i][$j]==2){ #回溯矩阵等于2时,代表要向上方回溯,即有插入
unshift @res1,"-"; #这里的“—”号代表某条序列有插入或者删除
$n++; #编辑距离加一
unshift @res2,$as2[$i-1];
&findpath($i-1,$j);
}else{ #回溯矩阵等于3时,代表要向左方回溯,即有删除
unshift @res1,$as1[$j-1];
unshift @res2,"-";
$n++; #编辑距离加一
&findpath($i,$j-1);
}
}
print "\nSequence comparison visualization: \n";
print @res1,"\n"; #可视化对比
print @res2,"\n"; #可视化对比
print "\nShortest editing distance:",$n,"\n\n"; #输出最短编辑距离















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









