






写在前面
- 需求:工作中有个业务需要用到千人千面的规则判定,即对于用户,会经常对不同的群体执行不同的逻辑,业务中就把这块逻辑抽出来用表达式执行来执行,只需要圈定用户远程配置中配置表达式即可, 也随时可以在远程配置中修改表达式
- 属于造轮子吗?是也不是, 写之前搜索了已有的使用人数较多的几个go表达式执行引擎, 功能都基本较为完善, 但是和我们的使用场景配合起来需要强行拓展, 代码拓展后速度上也就不是特别快了, 所以借鉴并写了个完全符合我们业务需求, 基本没有冗余功能的引擎
- 不巧的是刚写完业务就从Go转C++了…, C++有基于JIT的表达式引擎,性能非常强悍
- 本项目代码地址
- 参考项目地址:一些逻辑或者优化参考此项目
一、功能介绍
1、支持的操作符:
注:与go语言中用法不同或者增加的都予以注明
- 三元操作符:
? :(与其他语言中用法一致, eg:逻辑表达式 ?表达式1 : 表达式2)(注意表达式1与表达式2的执行结果类型可以不同) - 二元操作符:
- 逻辑操作符:
||、&& - 比较操作符:
==、!=、<、<=、>、>=、in(可以类比sql中的in, 用法例子: 1 in [1, 2, 3],其将返回true) - 运算操作符:
+、-、*、/、%、**(幂) - 位运算操作符:
|、^(按位异或,注意在引擎中其不能作为按位取反, 按位取反为~)、&、&^、<<、>>
- 逻辑操作符:
- 一元操作符:
++,--, 注意自增与自减只支持前缀, eg: ++2, 而2++是不被允许的, 因为表达式引擎只是运行一个表达式, 后缀的自增自减毫无意义!(逻辑反)、~(位取反, 注意不是^)、-(负)
- 操作符优先级:按由低至高顺序排列,可以加括号方便表达式书写
?与:,注意这其实是2个二元操作符组成的三元操作符,它们优先级最低||&&==、!=、<、<=、>、>=、in+、-、|、^*、/、%、&、&^、<<、>>**- 一元操作符
2、支持的数据类型:
- 数值: 表达式中所有数值使用go中的float64, 表达式中数值书写可以写成1、1.0等都是允许的, 数值只支持10进制, 且不支持指数的表示方式(一是我不想写,二是真的有人平时开发会用到各种各样的数据表示形式吗)
注:使用函数时, 如果函数中返回数值,需要明确的为float64类型(这一点当然也可以改为支持任何数值类型,但是笔者觉得没必要)
- 布尔: 书写为 true、false、t、f、True等部分或全部大写
- 字符串: 用小引号包裹, eg: ‘go_expression’, 支持转义。特别的, 如要表示小引号需要转义(eg:"a == 'ssss1234\\‘567’ ")
3、支持变量:
变量在表达式执行时以map[string]any形式传入
注:
- 变量的类型不为函数参数的时候,只能传第二点中所述的三种类型(数值、布尔、字符串),且传入的参数为数值类型时, 类型需要为float64
- 变量作为函数的参数时,可以传入任意类型
非函数参数的变量不支持结构体访问(eg:user.a),原因是如果支持,将要利用反射,性能将降低,笔者的应用场景需要较高的性能
注意变量在运算过程中是否改变, 不同使用场景有不同结果:
- 场景1: ++a == 1 && a == 2。注意, 此时如果执行时传入a的值为0, 那么 ++a == 1将为true, 但是当运行到 a == 2时, a还是等于0, 这有点反直觉, 当然也可以优化, 目前暂时不优化
- 场景2: func1(a) == 1 && func2(a) == 2, 如果a为非值类型, 比如是个map, 那么func1中对a的操作func2将会感知到, 这需要使用者知道
最后, 附简单的使用例子:
// 第一个参数为表达式字符串,第二个参数为执行时期是否进行类型检查, 当确定自己使用无误测试环境测试无问题后可设置为false加快执行
// 第三个参数为函数, 将在下一节介绍
exp, err := goexpression.NewExpression("a == 1 && b == true", true, nil)
if err != nil {
// ...
}
ret = exp.Bool(map[string]any{
"a": float64(1), // 非函数参数,数值类型一律为 float64
"b": true,
})
// ...
4、支持函数:
函数的类型定义如下:
type Function func(params ...any) (any, error)
简单的使用例子,例子中忽略错误与类型转换错误与参数个数检查等错误,由例子可以看出,函数支持嵌套
exp, _ := NewExpression("age(get(ctx)) == 1", true, map[string]Function{
"age": func(params ...any) (any, error) {
return params[0].(float64), nil
},
"get": func(params ...any) (any, error) {
ctx := params[0].(context.Context)
return float64(ctx.Value("age").(int)), nil
},
})
ret = exp.Bool(map[string]any{
"ctx": context.WithValue(context.Background(), "age", 1),
})
二、笔者的使用场景
注:举的例子是实际用法经过处理与精简,不代表业务中一模一样的用法,比如真实的表达式长达几十个子布尔表达式
对于一个用户,当满足其a字段值>=70 且<80,并且b字段值>14时有50%的概率进行一些操作
注:
- 如果只有这一个需求,那么也没必要搞个表达式引擎了,但是如果针对不同用户有不同的表达式且表达式的值易变,才适用。核心点就是多且易变
代码实现:
func init() {
rand.Seed(time.Now().Unix())
}
type User struct {
A int
B int
}
func main() {
// 实际使用中,表达式的值肯定是远程配置的
exp, _ := goexpression.NewExpression(`IntUserA(user) >= 70 && IntUserA(user) < 80 &&
IntUserB(user) > 14 && IntRand() < 50`, true, map[string]goexpression.Function{
"IntUserA": IntUserA,
"IntUserB": IntUserB,
"IntRand": IntRand,
})
// 显然,业务中运行的时候,User肯定是个运行时传入的
ret, _ := exp.Bool(map[string]any{
"user": User{A: 71, B: 15},
})
fmt.Println(ret)
}
func IntUserA(params ...any) (any, error) {
user := params[0].(User)
return float64(user.A), nil
}
func IntUserB(params ...any) (any, error) {
user := params[0].(User)
return float64(user.B), nil
}
func IntRand(params ...any) (any, error) {
return float64(rand.Intn(100)), nil
}
还有一点笔者需要强调,实际使用中A字段与B字段可能不是User结构体中自带的,它们可能是由C、D、E等字段计算得到的,比如计算用户两个切片特征的交集大小,我们使用函数传参而不使用结构体不但可以省略反射,还能让计算延迟,避免不必要的计算(用户的表达式的中包含的函数才会**可能(由于逻辑表达式短路不一定会执行)**运行,eg:UserA(user) > 10 && UserB(user) == 1,当UserA(user) > 10 为假时UserB(user)不执行,用结构体需要提前计算所有值
当然,例子中用了值传递,User结构体很大时将有影响(较小的时候可以自行测试,可能值传递效率还更高),我们可以将其放入ctx中等方法
实际使用中,由于编译较为耗时,我们可以使用一个全局map(选用并发安全map或者读写锁 + map等等),key为string格式的表达式,value为编译好的表达式。这样只会在远程配置变动的时候会有一定量的编译,当有一个协程编译好并放入map后,后续的所有协程都将从map中取用
三、原理简介
首先,编译原理不熟悉的同学可以看笔者之前的两篇文章:简析Go词法分析、简析Go语法分析
我们需要实现的只是一个功能不完备的表达式执行,所以代码其实很简单,笔者主要强调其中的一些地方
0、词法分析:
- 词法分析没啥好说的,由上面的代码演示我们可以看到编译的时候需要传入函数map,可以在词法分析阶段区分函数与变量:
// 当词法分析遇到字符,可能是:关键字,函数名,变量名
if unicode.IsLetter(char) {
name := l.letters(char) // 获取连续字符
if ok := l.isKeyLetter(name); ok { // 关键字优先级最大, 把true,in这些看做关键字
continue
}
if f, ok := functions[name]; ok { // 注册的函数
l.addToken(f, Func, false)
continue
}
l.addToken(name, Var, false) // 最后才是变量
continue
}
- 关于负号与减号的处理:减号与自减和其它如&与&&一样的容易处理,以&&与&为例,解析规则为:&&解析为逻辑与,&解析为按位与& &解析为两个按位与,因为其有空格,&&&解析为&&与&。当然& &和&&&的写法都是错误的表达式
- 但是负号与减号的区分不应该词法分析阶段来做,放入语法分析阶段将更加符合场景,所以词法阶段 “-” 一律被解析为减号Token
1、语法分析:参考Go编译器源码,性能上与正确性上都能得到保障,可以去简析Go语法分析中了解Go是如何解析表达式的(核心点还是结合性与优先级的处理)
语法分析后为一颗抽象语法树,树节点结构体如下:
type astNode struct {
left, right *astNode // 左右子节点
op Operator // 节点是操作符时记录操作符,执行优化时用到
opFunc opFunc // 节点执行函数
typeCheck typeCheck // 类型检查函数
}
type opFunc func(l any, r any, params map[string]any) (any, error)
type typeCheck func(left, right any) bool
以 1 + 1这个表达式来展示下解析后的抽象语法树
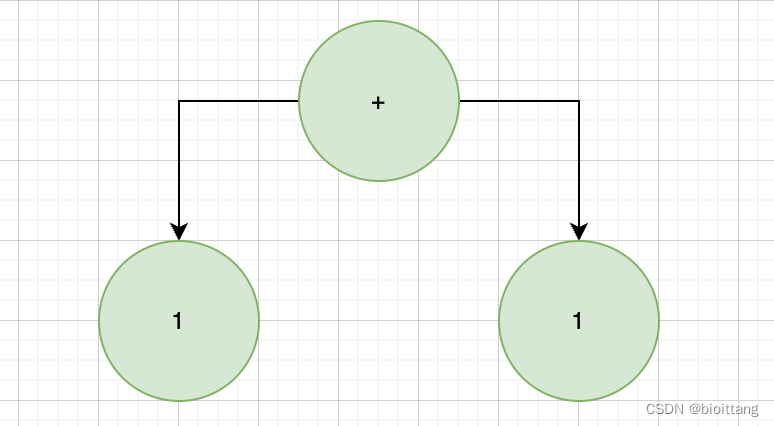
其中,三个节点的执行函数为:
// + 节点的执行函数
func addFunc(left, right any, _ map[string]any) (any, error) {
if IsString(left) && IsString(right) {
return left.(string) + right.(string), nil
}
return left.(float64) + right.(float64), nil
}
// 语法解析的时候传入lit为1,从而返回两个1的执行函数
func makeLitFunc(lit any) opFunc {
return func(l any, r any, params map[string]any) (any, error) {
return lit, nil
}
}
+节点的类型检查函数为如下(代表左右子节点调用计算函数的返回值必须满足同时为float64或者同时为string),显然的,字面量不需要类型检查函数:
func canCmp(left, right any) bool {
return IsFloat64(left) && IsFloat64(right) || IsString(left) && IsString(right)
}
显然的只有操作符需要类型检查函数
比较特殊的三个Token的执行函数如下:
// 获取变量Token的执行函数,如 a + 1,中a获取执行函数时调用makeVarFunc("a")
func makeVarFunc(name string) opFunc {
return func(l, r any, params map[string]any) (any, error) {
ret, ok := params[name]
if !ok {
return nil, fmt.Errorf("execute: %s param not in the passed parameter list", name)
}
return ret, nil
}
}
// 获取函数Token的执行函数
func makeFuncFunc(function Function) opFunc {
return func(left, right any, params map[string]any) (any, error) {
if right == nil {
return function()
}
switch right.(type) {
case []any:
return function(right.([]any)...)
default:
return function(right)
}
}
}
// ","Token 执行函数,函数参数或者数组列表需要用到 "," (如[1, 2, 3]这种)
func commaFunc(left, right any, _ map[string]any) (any, error) {
var ret []any
switch left.(type) {
case []any:
ret = append(left.([]any), right)
default:
ret = []any{left, right}
}
return ret, nil
}
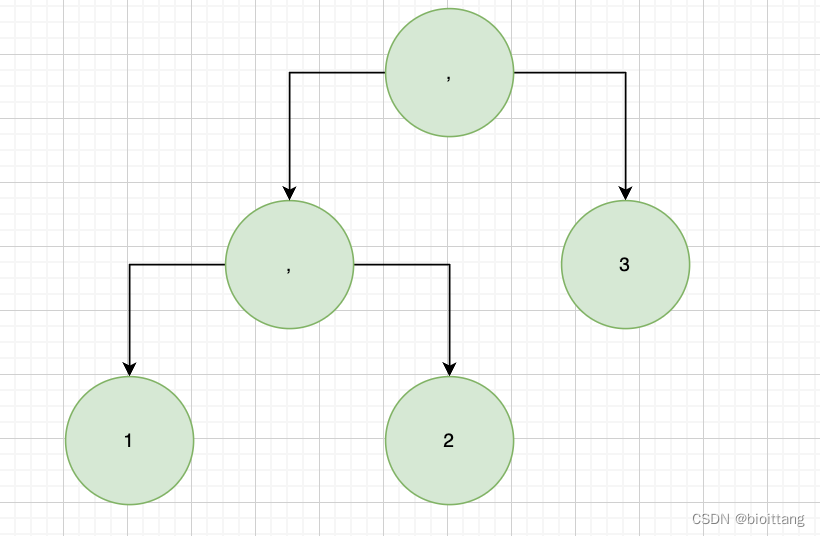
比较特殊的是对于类似于 [1, 2, 3],funcName(4, 5, 6)这两者的处理,有兴趣的同学可以打开源码查看。其中 [1, 2, 3]与(4, 5, 6)都将被解析为一颗树(见下图),这个树执行结果为数组(上面提到了commaFunc这个函数),(4, 5, 6)这颗树将作为funcName这个函数节点的右子树。 [1, 2, 3]可能作为单独的一个表达式,即一颗树或者作为in操作符的右子树
2、表达式执行:执行即DFS方式遍历抽象语法树的树根,调用左右子节点的计算函数opFunc与类型检查函数typeCheck
主要执行加速在于逻辑表达式的熔断与类型检查可关闭(初始化表达式的时候的第二个参数)
func (e *Expression) executeASTNode(root *astNode, params map[string]any) (any, error) {
if root == nil {
return nil, nil
}
var (
left, right any
err error
)
// 先调用左子节点,计算左子树的最终计算结果
if left, err = e.executeASTNode(root.left, params); err != nil {
return nil, err
}
// 左边结果可能可以直接决定结果的,eg:true || 2 == 3, 这个2 == 3就没必要执行了
switch root.op {
case AndAnd: // &&
if left == false {
return false, nil
}
case OrOr: // ||
if left == true {
return true, nil
}
case TernaryT: // ?
if left == false {
return nil, nil
}
case TernaryF: // :
if left != nil {
return left, nil
}
default:
}
// 计算右子树计算结果
if right, err = e.executeASTNode(root.right, params); err != nil {
return nil, err
}
// 如果开启了类型检查, 检查左右子树计算结果是否符合预期
if e.NeedCheck && root.typeCheck != nil {
if !root.typeCheck(left, right) {
return nil, fmt.Errorf("execute: type check error")
}
}
// 调用自身的计算函数并返回结果
return root.opFunc(left, right, params)
}















 1960
1960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









