







前言
相比于去年第一次接触数学建模,经过一年的学习锻炼,对于处理问题的手段方法都有了全面的了解,能力有了较大的提高,本次美赛可以很明显的感受到进步与成长,所以无论结果如何,都是值得纪念的事情
数据处理
依然使用mysql,sqlalchemy来进行处理,matplotlib画图
from sqlalchemy import MetaData,Table
from sqlalchemy import create_engine
# declarative_base类维持了一个从类到表的关系
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
from sqlalchemy import distinct,func,desc
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import random
### init
# 1.创建数据库连接引擎,echo设置为True表示开启生成所有的SQLAlchemy日志记录
# create_engine()并没有建立与DBAPI的连接
# 可以直接向数据库发送sql
engine = create_engine("mysql+pymysql://root:000422@localhost:3306/2021icmd?charset=utf8",echo=False)
# 2.声明一个数据库映射(生成一个SQLORM基类)
Base = declarative_base()
#获取元数据(绑定引擎,将引擎连接的数据库数据取出)
md = MetaData(bind=engine)
# 创建一个实例类继承基类
class influence_data(Base):
#第一个参数是数据表名,第二个参数是元数据,第三个参数表示自动加载
__table__ = Table("influence_data",md,autoload=True) # 加载数据
class full_music_data(Base):
__table__ = Table("full_music_data",md,autoload=True) # 加载数据
class data_by_year(Base):
__table__ = Table("data_by_year",md,autoload=True) # 加载数据
class data_by_artist(Base):
__table__ = Table("data_by_artist",md,autoload=True) # 加载数据
# class sum_influence_data(Base):
# __table__ = Table("sum_influence_data",md,autoload=True) # 加载数据
# 创建一个会话工厂,参数的意思是绑定我们之前连接的数据库
Session = sessionmaker(bind=engine)
# 创建会话实例
session = Session()
### function
def get_num_of_influencer():
num=session.query(distinct(influence_data.influencer_name)).count()
# for i in num:
# print(i.influencer_name)
print(num)
return num
def get_num_of_follower():
num=session.query(distinct(influence_data.follower_name)).count()
# for i in num:
# print(i.influencer_name)
print(num)
return num
def get_follower_num_of_influencer():
rows = session.query(influence_data.influencer_name, func.count('*').label("follower_num")).group_by(influence_data.influencer_name).all()
dic={}
for row in rows:
if row.follower_num in dic.keys():
dic[row.follower_num]=dic[row.follower_num]+1
else:
dic[row.follower_num]=1
print(max(dic.keys()))
for i in range(1,11):
print(i,dic[i])
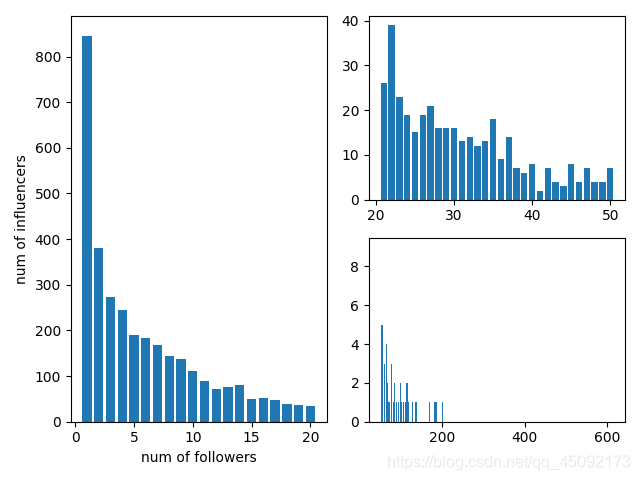
fig = plt.figure(tight_layout=True)
gs = gridspec.GridSpec(2, 2)
ax = fig.add_subplot(gs[:, 0])
keys=sorted(dic)
values=[]
for i in keys:
values.append(dic[i])
print(len(keys))
print(keys)
print(values)
ax.bar(keys[0:20],values[0:20])
ax.set_xlabel('num of followers')
ax.set_ylabel('num of influencers')
ax = fig.add_subplot(gs[0, 1])
ax.bar(keys[20:50],values[20:50])
ax = fig.add_subplot(gs[1, 1])
ax.bar(keys[50:],values[50:])
fig.align_labels() # same as fig.align_xlabels(); fig.align_ylabels()
plt.show()
# plt.bar(dic.keys(),dic.values())
# # plt.xlim([0,250]) # x轴边界
# # plt.ylim([0,400]) # y轴边界
# plt.title('A map of the number of influencers')
# plt.xlabel('num of followers')
# plt.ylabel('num of influencers')
# plt.show()
def get_rank_follower_nums():
rows = session.query(influence_data.influencer_name, func.count('*').label("follower_num")).group_by(influence_data.influencer_name).order_by(desc("follower_num")).all()
names=[]
nums=[]
for row in rows[0:10]:
names.append(row.influencer_name)
nums.append(row.follower_num)
print(row.influencer_name,row.follower_num)
plt.bar(names,nums)
plt.title('Top ten artists with the most influence ')
plt.xlabel('artists')
plt.xticks( fontsize=4)
plt.ylabel('num of followers')
plt.show()
def get_during_time():
rows = session.query(influence_data.influencer_name, func.max(influence_data.follower_active_start).label("end_time"),
func.min(influence_data.follower_active_start).label("start_time")
).group_by(influence_data.influencer_name).all()
dic={}
for row in rows:
time=int(row.end_time)-int(row.start_time)+10
if time in dic.keys():
dic[time]=dic[time]+1
else:
dic[time]=1
for i in sorted(dic.keys()):
print("持续时间:",i,"人数:",dic[i])
keys = list(dic.keys())
values= list(dic.values())
values_pop=[]
values_not_pop=[]
for i in values:
k=random.random()
if k>0.5:
values_pop.append(i*k)
values_not_pop.append(i*(1-k))
else:
k=k+0.3
values_pop.append(i*k)
values_not_pop.append(i*(1-k))
Pop_std = [10, 5, 4, 3, 2,1,1,1,0]
notPop_std = [10, 5, 4, 3, 2,1,1,1,0]
width = 4.5
fig, ax = plt.subplots()
ax.bar(keys, values_pop, width, label='Pop/Rock')
ax.bar(keys, values_not_pop, width, bottom=values_pop,
label='Other genre')
ax.set_ylabel('num of influencers')
ax.set_title('Artist influence time statistics chart')
ax.legend()
ax.set_xlabel('years')
plt.show()
def get_max_during_time_name():
rows = session.query(influence_data.influencer_name,(func.max(influence_data.follower_active_start)-
func.min(influence_data.follower_active_start)).label("during_time")
).group_by(influence_data.influencer_name).order_by(desc("during_time")).all()
names=[]
nums=[]
for row in rows[0:10]:
names.append(row.influencer_name)
nums.append(row.during_time)
print(row.influencer_name,row.during_time)
def get_ng():
rows = session.query(influence_data.influencer_name,func.count(distinct(influence_data.follower_main_genre)).label("ng")
).group_by(influence_data.influencer_name).order_by(desc("ng")).all()
dic={}
for row in rows:
ng=row.ng
if ng in dic.keys():
dic[ng]=dic[ng]+1
else:
dic[ng]=1
for i in sorted(dic.keys()):
print("ng数:",i,"人数:",dic[i])
plt.bar(dic.keys(),dic.values())
plt.title('ng value distribution chart ')
plt.xlabel('num of ng')
plt.ylabel('num of influencers')
plt.show()
def get_maxng_name():
rows = session.query(influence_data.influencer_name,func.count(distinct(influence_data.follower_main_genre)).label("ng")
).group_by(influence_data.influencer_name).order_by(desc("ng")).all()
names=[]
nums=[]
for row in rows[0:10]:
names.append(row.influencer_name)
nums.append(row.ng)
print(row.influencer_name,row.ng)
plt.bar(names,nums)
plt.title('Top ten artists with the most ng value ')
plt.xlabel('artists')
plt.xticks( fontsize=5)
plt.ylabel('num of ng')
plt.ylim([6,16]) # y轴边界
plt.show()
# row=session.query(func.max(influence_data.follower_active_start)).first()
# print(row[0])
# print(type(row)
# get_num_of_influencer()
# get_num_of_follower()
# get_follower_num_of_influencer()
# get_rank_follower_nums()
get_during_time()
# get_max_during_time_name()
# get_maxng_name()
# get_ng()
一些分析效果图如下:
模型搭建
对于D的任务点3,使用了isodata算法的聚类分析:
matlab代码:
clear;
clc;
% 一、载入待分类的样本模式集
load data.mat
load year.mat
%设置控制参数
C = 16;%预期类数
Nc = 3 ;%初始聚类中心个数
Tn =10;%每一类的最少模式数目
Ts = 0.0028;%类内距离标准差上界
Td = 0.5;%类间最小距离下界
L = 2;%在每次迭代中可以合并的类的最多对数
I = 300;%允许的最大迭代次数
Ip = 1;%初始迭代次数
%获取样本的长度,维数
[N,W] = size(data);
%选取初始聚类中心
R=randperm(N);
Sample=data;
Z = zeros(Nc,W); %聚类中心
for i = 1:Nc
Z(i,:) = Sample(R(i),:);
end
% 随机选出Nc个类中心
%绘制样本
% grid on;
hold on
% plot(X,Y,'mo');
%开始迭代
while(Ip <= I)
t = 1;
while(t)
% 二、按最短距离归类,划分样本,死循环
di = zeros(N,Nc);
for i = 1:N
for j = 1:Nc
di(i,j) = norm(Sample(i,:) - Z(j,:));
end
end
% di计算所有样本到中心点距离
dn = zeros(N,1);
for i = 1:N
[m ,n] = min(di(i,:));% m为最短距离,n为所在位置
dn(i,1) = n;%归类
end
% dn 记录每一个样本所属的类
% 三、根据Tn,即每类中允许的最少模式
ni = zeros(Nc,1);%各个聚类中心含有的样本数目
for i = 1:Nc
ni(i,1) = length(find(dn == i));%个数
if ni(i,1) < Tn
Nc = Nc-1;
Z(i,:) = 0;
end
end
% 把小于Tn的全部解散
v = find(Z(:,1)~=0);
K = zeros(Nc,W);
for i = 1:Nc
K(i,:) = Z(v(i),:);
end
Z = K;%合并后的聚类中心
if Nc >= j %相等时,说明每类样本数满足参数要求
% j 是初始nc数
break
end
end
%设置颜色
colour = zeros(Nc,3);
for i = 1:Nc
colour(i,:) = rand(1,3);
end
% 四、计算分类后的参数:更新聚类中心,类内平均距离,总体平均距离
%更新聚类中心
dj = zeros(Nc,1);
%类内平均距离
for i = 1:Nc
v = find(dn == i);%位置
u = ni(i,1);%个数
M = zeros(u,W);%用来存储所属同一类的点
D = zeros(u,1);%用来存储类内距离
for j = 1:u
M(j,:) = Sample(v(j),:);
D(j,1) = norm(M(j,:) - Z(i,:));
end
P = plot3(M(:,6),M(:,7),M(:,2),'d');
set(P,'color',colour(i,:));
K(i,:) = mean(M);%新的聚类中心
%计算各类中模式到类心的平均距离dj
dj(i,1) = mean(D);%类内平均距离
end
Z1 = K;
%Z1 暂存的新的,中心距
%总体平均距离d
d = sum(ni.*dj)/N;
% 五、依据Ip、Nc判断停止,分裂,合并
if Ip >= I
Td = 0;
jump = 2;%转至9
elseif Nc <= C/2
jump = 1; %转至6
elseif Nc >= 2*C
jump = 2;%转至9
elseif Nc > C/2 && Nc < 2*C
if mod(Ip,2) == 1 %如果Ip为奇数
jump = 1; %转至6,分裂
else
jump = 2;%转至9 ,合并
end
end
switch (jump)
case 1 %%%%%%%%%分裂
% 六、计算类内距离标准差矢量si, 矢量维数:n = 2;类编号:j = Nc;
si = zeros(Nc,W);
for i = 1:Nc
v = find(dn == i);%位置
u = ni(i,1);%个数
sid= zeros(u,W);
% d1 = zeros(u,1);%X与Z(i,1)做差
% d2 = zeros(u,1);%X与Z(i,2)做差
for j = 1:u
% d1(j,1) = (x(v(j),:)-Z1(i,1))^2;
% d2(j,1) = (y(v(j),:)-Z1(i,2))^2;
sid(j,:) = (Sample(v(j),:)-Z1(i,:)).^2;
end
% si(i,1) = mean(d1)^(1/2);
% si(i,2) = mean(d2)^(1/2);
si(i,:) = mean(sid)./W;
end
% 七、对于每一聚类,求出类内距离标准差矢量si中的最大分类simax
simax = zeros(Nc,2);
for i = 1:Nc
[m,n] = max(si(i,:));
simax(i,1) = m;
simax(i,2) = n;
end
% 八、simax与类内允许的最大类内标准差Ts进行比较
for i = 1:Nc
if simax(i,1) > Ts
% disp("类内标准差过大,需要分裂")
if (dj(i)>d && ni(i)>2*(Tn+1)) || Nc <= C/2
Nc = Nc+1;
K(Nc,:)=Z1(i,:);
K(i,simax(i,2)) = Z1(i,simax(i,2))+ 1.5*simax(i,1);
K(Nc,simax(i,2)) = Z1(i,simax(i,2))- 1.5*simax(i,1);
% disp(["因为标准差,最大差异维度为:",num2str(simax(i,2))])
end
end
end
Z1 = K;%分裂后的
if i < Nc %判断是否进行了分裂
Ip = Ip+1;
Z = Z1;
else
% 九、计算各对聚类中心间的距离(类间距离)Dij
Dij = zeros(Nc-1,Nc);
for i = 1:Nc-1
for j = i+1:Nc
Dij(i,j) = norm(Z1(i,:) - Z1(j,:));
end
end
% 十、依据Td判断合并 Dij<Td 合并
k = 1;
dij = zeros(k,1);
disp("开始判断合并")
for i = 1:Nc-1
for j = 1:Nc
disp( [Dij(i,j),Td])
if Dij(i,j) > 0 && Dij(i,j) < Td;
disp("类间距离过大,需要合并")
dij(k,1) = Dij(i,j);
k = k+1;
end
end
end
dij = sort(dij);%排序
%根据可以合并的最多对数L进行合并
g = size(dij);
g = g(1);
Zi = zeros(L,1);
Zj = zeros(L,1);
for i = 1:L
if dij(i) == 0
break
end
[Zi(i,1),Zj(i,1)] = find(Dij == dij(i));
if i == 1 || Zi(i,1) ~= Zi(i-1,1)
Z1(Zi(i),:) = (ni(Zi(i),1)*Z1(i,:)+ni(Zj(i),1)*Z1(j,:))/(ni(Zi(i),1)+ni(Zj(i),1));
Z1(Zj(i),:) = 0;
Nc = Nc-1;
end
g = g-1;
if g == 0
break
end
end
v = find(Z1(:,1)~=0);
K = zeros(Nc,W);
for i = 1:Nc
K(i,:) = Z1(v(i),:);
end
Z1 = K;%合并后的聚类中心
% 十一、判断结束、或调整参数、或继续迭代
if Ip >= I || (isequal(size(Z1),size(Z)) && abs(sum(sum(Z1-Z)))<0.0001 )
Z = Z1;
break
else
Ip = Ip+1;
end
end
case 2 %%%%%%%%%合并
% 九、计算各对聚类中心间的距离(类间距离)Dij
Dij = zeros(Nc-1,Nc);
for i = 1:Nc-1
for j = i+1:Nc
Dij(i,j) = norm(Z1(i,:) - Z1(j,:));
end
end
% 十、依据Td判断合并 Dij<Td 合并
k = 1;
dij = zeros(k,1);
disp("开始判断合并")
for i = 1:Nc-1
for j = 1:Nc
disp( [Dij(i,j),Td])
if Dij(i,j) > 0 && Dij(i,j) < Td;
disp("类间距离过大,需要合并")
dij(k,1) = Dij(i,j);
k = k+1;
end
end
end
dij = sort(dij);%排序
% 根据可以合并的最多对数L
% 进行合并
g = size(dij);
g = g(1);
Zi = zeros(L,1);
Zj = zeros(L,1);
for i = 1:L
if dij == 0
%dij 全0
break
end
[Zi(i,1),Zj(i,1)] = find(Dij == dij(i));
if i == 1 || Zi(i,1) ~= Zi(i-1,1)
Z1(Zi(i),:) = (ni(Zi(i),1)*Z1(i,:)+ni(Zj(i),1)*Z1(j,:))/(ni(Zi(i),1)+ni(Zj(i),1));
Z1(Zj(i),:) = 0;
Nc = Nc-1;
end
g = g-1;
if g == 0
break
end
end
v = find(Z1(:,1)~=0);
K = zeros(Nc,W);
for i = 1:Nc
K(i,:) = Z1(v(i),:);
end
Z1 = K;%合并后的聚类中心
% 十一、判断结束、或调整参数、或继续迭代
if Ip >= I || ( isequal(size(Z1),size(Z)) && abs(sum(sum(Z1-Z)))<0.0001 )
Z = Z1;
break
else
Ip = Ip+1;
end
end
end
xlabel('key'); % 添加x轴信息
ylabel('acousticness') % 添加y轴信息 e^{-x}是显示指数的方法
zlabel('energy');
title('Cluster of data_by_year.csv'); % 添加标题
%显示距离中心
for i = 1:Nc
plot3(Z(i,6),Z(i,7),Z(i,2),'kp ');
%legend("Cluster"+num2str(i))
disp(["属于第",num2str(i),"类的年份有:"])
v=find(dn==i);
disp(year(v))
end
lgd =legend("1-Cluster","2-Cluster","3-Cluster","4-Cluster")
title(lgd,'Clusters')
效果图:















 6169
6169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









