







目录
一、背景
基于深度学习的教程(卷积神经网络)详见:基于卷积神经网络的高光谱图像分类详细教程(含python代码)-CSDN博客
在高光谱图像分类领域,随机森林(Random Forest,RF)和支持向量机(Support Vector Machine, SVM)是两种广泛应用的机器学习算法。随机森林以其强大的集成学习能力,通过构建多个决策树并汇总它们的预测结果,能够有效地处理高维数据,捕捉到数据中的复杂模式。在高光谱图像中,每个像素点都包含了大量的光谱信息,随机森林能够利用这些信息构建出鲁棒的分类模型,尤其在处理非线性关系和噪声数据时表现出色。
相比之下,支持向量机通过寻找能够最大化不同类别之间间隔的超平面来进行分类,它在处理高维数据时同样表现出色,尤其是在数据线性可分或通过核技巧转换为线性可分的情况下。SVM的核函数能够将数据映射到更高维的空间,从而解决非线性分类问题。在高光谱图像分类中,SVM能够通过选择合适的核函数和参数,有效地识别出不同地物的光谱特征,实现高精度的分类。
两种算法各有优势,随机森林在处理大规模数据集和复杂特征交互时更为高效,而支持向量机在模型解释性和泛化能力方面表现突出。在高光谱图像分类任务中,选择哪种算法往往取决于数据的特性、分类目标以及计算资源的限制。实际应用中,研究人员常常会结合两种算法的优点,通过交叉验证和模型融合等技术,进一步提升分类性能。
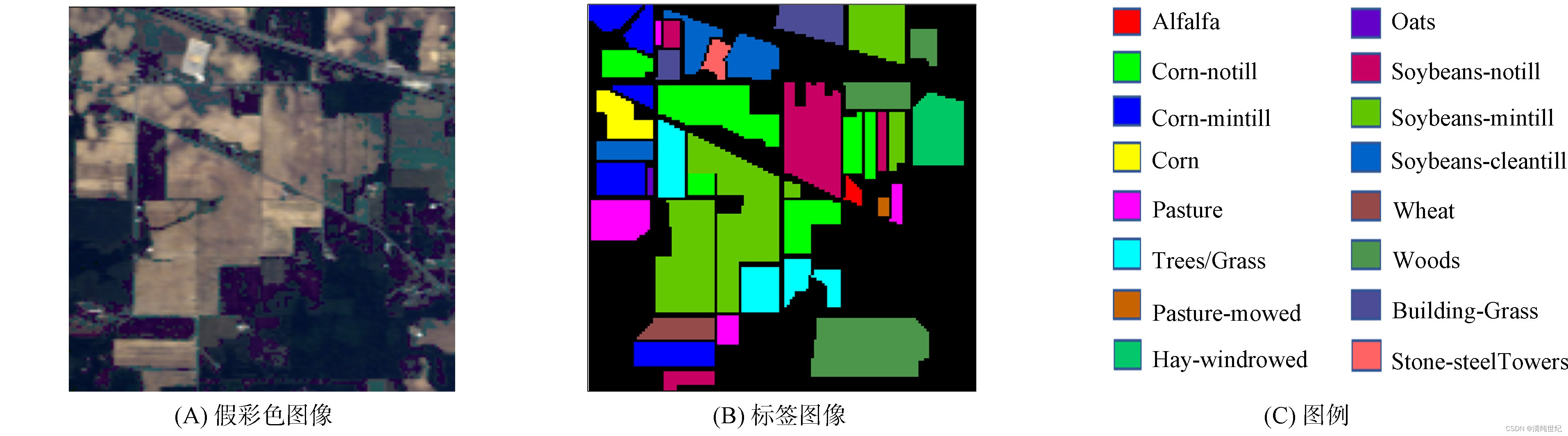
二、代码实现
下面我们以IP数据集为例子进行展开讲解。
1、加载数据
将下载的数据加载进内存,便于后续处理
X = sio.loadmat('./data/Indian_pines.mat')['indian_pines']
y = sio.loadmat('./data/Indian_pines_gt.mat')['indian_pines_gt']
2、数据标准化
对数据标准化,方便模型学习特征
# 数据标准化
standard_scaler = StandardScaler()
data_standard_scaled = standard_scaler.fit_transform(X.reshape(-1, X.shape[2])).reshape(X.shape[0], X.shape[1], X.shape[2])3、数据集的样本划分与标签分配
根据数据标签和数据,对其进行样本采样,并划分成训练集和验证集。这里以窗口为25的大小,训练集和测试集的占比分别为20%的训练,80%的验证。
print('\n... ... 数据预处理 ... ...')
mask = y>0
data, y = X[mask], y[mask]
print("获得的样本一共有:",len(data))
Xtrain, Xtest, ytrain, ytest = splitTrainTestSet(data, y, test_ratio)
print("训练集:",len(Xtrain),"验证集:",len(Xtest))
4、建立RF和SVM模型
# 建立模型并训练
model = RandomForestClassifier(n_estimators=500, random_state=42) # 随机森林
# model = SVC(kernel='rbf', C=500, random_state=42) # 支持向量机需要哪个模型,即用该模型,取消注释即可,另一个注释。
5、训练和预测结果
model.fit(Xtrain, ytrain)# 训练模型
model.predict(Xtest)# 预测测试集6、结果显示
classification, confusion, oa, each_acc, aa, kappa,names = reports(ytest, y_pred)
print(classification)
print("混淆矩阵\n",confusion)
print("kapap:", kappa)
print("aa:", aa)
print("oa:", oa)
print("训练时间:",train_time_1-train_time_0,"验证时间:",test_time_1-test_time_0)以下结果是SVM的,RF的取消RF注释,并注释SVM重新运行即可:
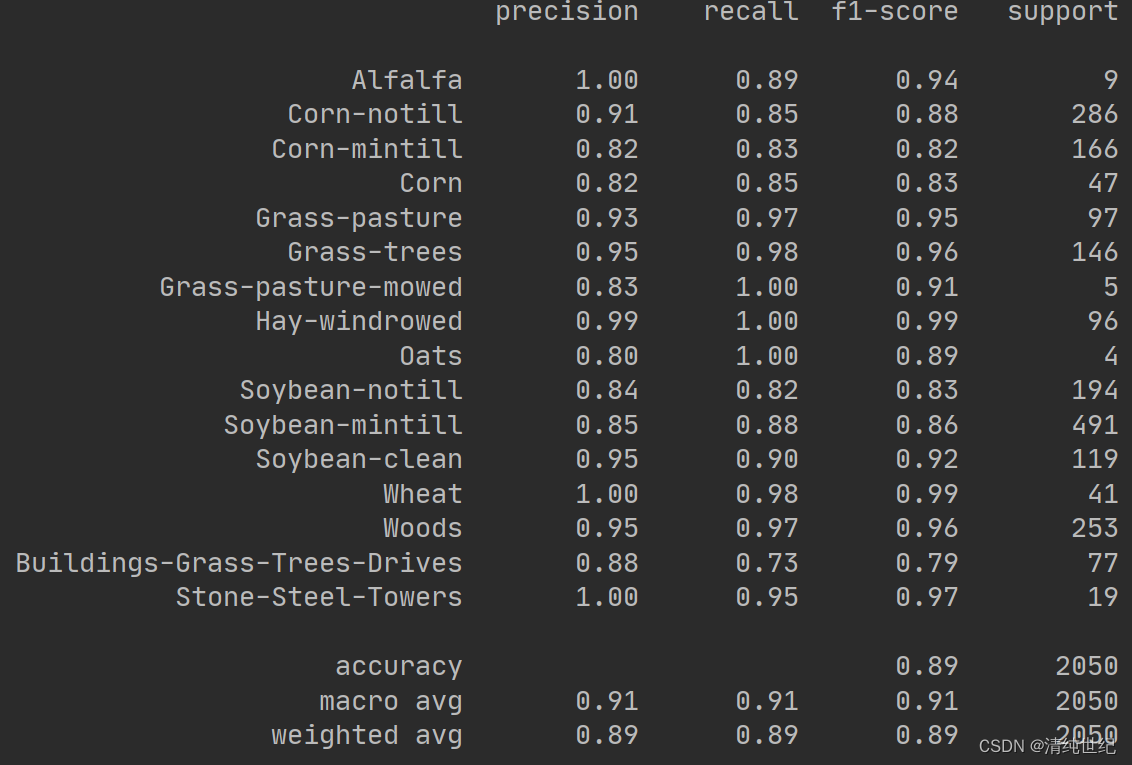

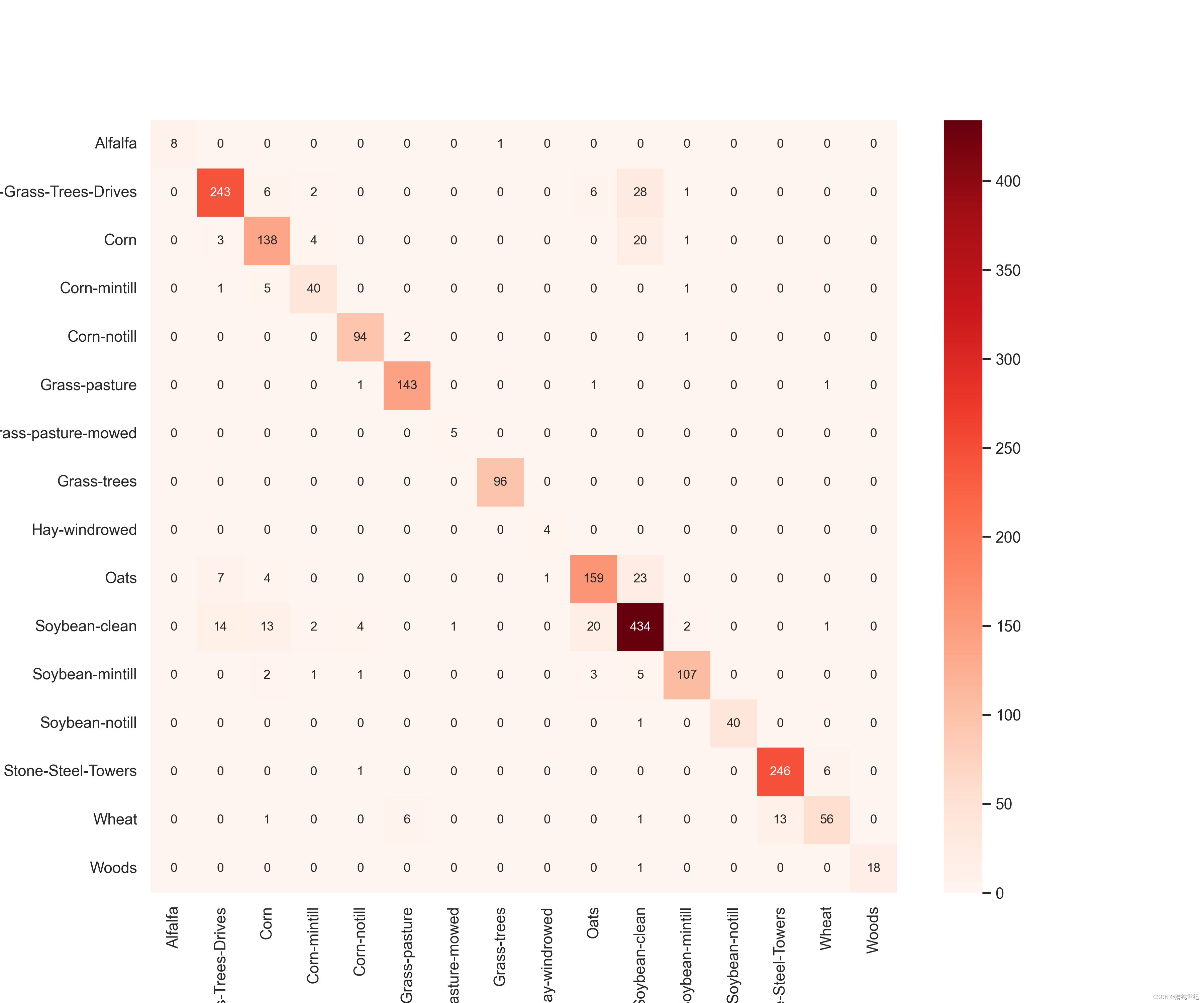
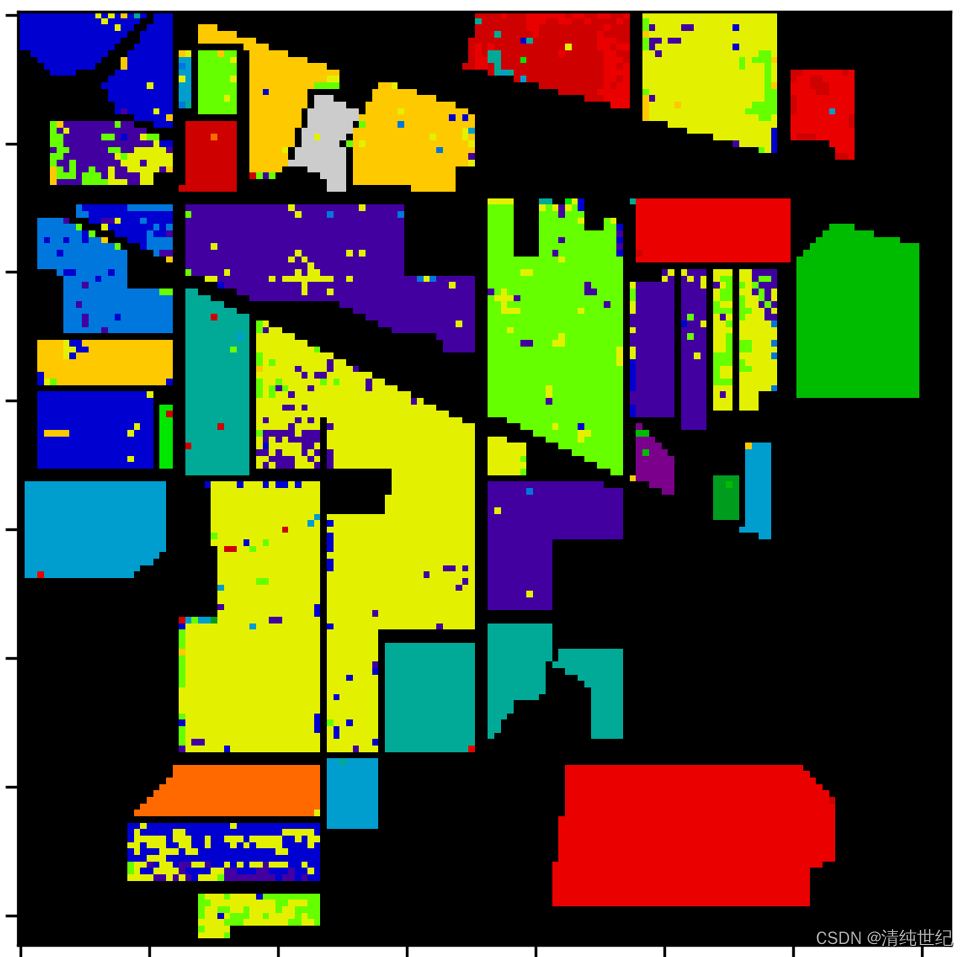
三、项目代码
本项目的代码通过以下链接下载:基于随机森林与支持向量机的高光谱图像分类python代码
















 1890
1890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











