







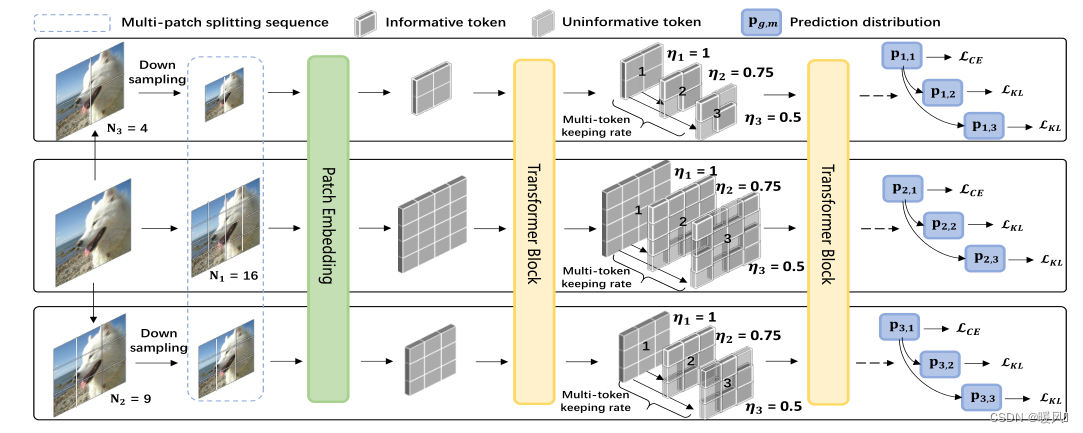
 这篇文章主要针对减少Vision Transformer的计算消耗,提出了一种新的方法。在ViT中我们已知Transformer的token数量与patch大小成反比,这表示patch大小越小的模型计算成本越高,而patch越大模型效果的损失就越大。这正和我们的目的相背离。SuperViT的作者从两个方面来提升性能:
这篇文章主要针对减少Vision Transformer的计算消耗,提出了一种新的方法。在ViT中我们已知Transformer的token数量与patch大小成反比,这表示patch大小越小的模型计算成本越高,而patch越大模型效果的损失就越大。这正和我们的目的相背离。SuperViT的作者从两个方面来提升性能:多尺度的patch分割和多种保留率。尽量的减少计算量加速计算并维持较好的模型性能。该种方法用在图像分类上基本没什么问题,但是在超分领域,像素的丢弃还是会较严重的影响模型的性能。
Super Vision Transformer
Abstract
作者试图降低VIT的计算成本。于是乎提出了一种新的训练范式,该范式一次只训练一个ViT模型,但能够以不同计算成本提供改进的图像识别性能。新模型被称为超级视觉Transformer(SuperViT),具有接受多个不同大小的patch以及以多个保留率来保留信息token的能力,以实现良好的硬件推理效率,因为可用的硬件资源经常会不时变化。
在ImageNet上的实验结果表明,SuperViT可以显著降低ViT模型的计算成本,同时提高性能。
1 Introduction
Vision Transformer (VIT)最初于2020年推出,现已在计算机视觉领域广泛推广,并很快成为各种主流视觉任务中最普遍和最有前景的架构之一,如图像分类、目标检测、视频理解。ViT的基本思想是将图像分解为一系列局部patch,并使用线性投影将这些patch标记为输入。ViT的优点在于能够利用多头自注意(MHSA)机制捕捉图像不同部分之间的长期关系。
ViT的最大缺陷在于巨大的计算消耗,Transformer的token数量与patch大小成反比,这表示patch大小越小的模型计算成本越高,这严重阻碍了其在实际应用中的使用。减小计算成本最直观的方法是通过增大patch大小来减少Transformer的token数。然而,在ViT文章中已经证明在以较小尺寸的patch作为输入时模型表现更好。因此模型的高效性和性能之间的平衡仍待我们去探索。
现有的几种利用图像的冗余信息,丢弃部分包含信息较少的像素的方法。
- Tang等人引入了自上而下的token丢弃方法。
- DynamicViT和IA-RED2方法使用可学习的预测模块对每个token进行评分;
- EViT利用预训练的类注意来衡量token的重要性;
- DVT用多个VIT级联,每张图像保留token数量由早期的策略决定。
虽然这些token丢弃的方法能够降低计算成本,但它们牺牲了识别精度。 例如
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1124
1124











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









