







这篇文章是相对于Swin-Transformer和PVT进行改进,加入了可变形机制,同时控制网络不增加太多的计算量,作者认为,缩小q对应的k的范围,能够减少无关信息的干扰,增强信息的捕捉,于是引入了DCN机制到注意力模块中,提出了一种新的注意力模块:可变形多头注意力模块——对k和v进行DCN偏移后再计算注意力。将这个模块替换到Swin-Transformer的第三四阶段的滑动窗口注意力部分,获得了较好的实验性能。
原文链接:Vision Transformer with Deformable Attention
源码地址:https://github.com/LeapLabTHU/DAT
Vision Transformer with Deformable Attention
Abstract
我们知道Transformer模型比CNN模型具有更高的表现能力。因为他有着全局的感受野,只有着建模长距离关系的能力。但是单纯扩大感受野也会引起一些问题。
- 在ViT中使用密集的注意力会导致内存和计算成本过高,特征会受到超出相关区域的无关部分的影响。
- 在PVT或Swin Transformer 中采用的稀疏注意力是数据不可知的,可能会限制建模长期关系的能力。
为了缓解这些问题,本文提出了一种新的可变形的自注意力模块,该模块以数据依赖的方式选择自注意力中的key和value对的位置。这种灵活的方案使自注意力模块能够聚焦于相关区域并捕获更多信息。
在此基础上,提出了一种可变形注意力Transformer(Deformable Attention Transformer)模型,该模型具有可变形注意力,适用于图像分类和密集预测任务。大量的实验表明,本文的模型在综合基准上取得了持续改进的结果。
1 Introduction
Transformer最初是用来解决自然语言处理任务的。它最近在计算机视觉领域显示出巨大的潜力。Transformer第一次应用于视觉领域的工作Vision Transformer(ViT)将多个Transformer块堆叠在一起,以处理非重叠的图像patch(即视觉Token)序列,从而产生了一种无卷积的图像分类模型。与CNN模型相比,基于Transformer的模型具有更大的感受野,擅长于建模长期依赖关系,在大量训练数据和模型参数的情况下取得了优异的性能。然而,视觉识别中的过度关注是一把双刃剑,存在多重弊端。具体来说,每个query patch中参与的key数过多会导致较高的计算成本和较慢的收敛速度,并增加过拟合的风险。
为了避免过度的注意力计算,已有的研究设计了高效注意力模块来降低计算复杂度。其中有两种具有代表性的方法:
- Swin Transformer采用基于Window的局部注意力来限制Local Window中的注意力;
- Pyramid Vision Transformer(PVT)则通过对key和value特征映射进行采样来节省计算量。
理想情况下,给定query的候选key/value集应该是灵活的,并且能够适应每个单独的输入。
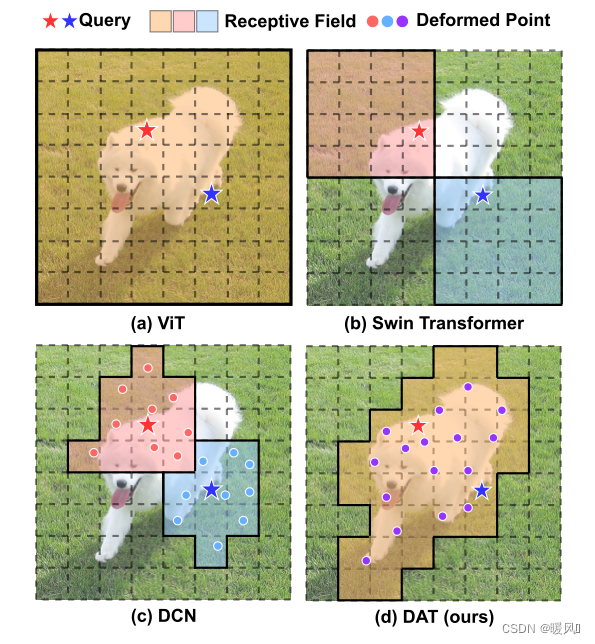
在DCN中已经证明了学习卷积滤波器的可变形感受野已被证明在依赖于数据的基础上有选择性地关注更多信息区域是有效的。受到该启示或许可以将DCN引入到Vision Transformer中,探索一种可变形的注意力模式。这种想法会来带不合理的高内存/计算复杂度:由Deformable offsets引入的开销是patch数量的平方。因此,虽然已经有一些工作研究了变形机制的思想,但由于计算成本高,没有人将其作为构建强大的Backbone(如DCN)的基本构件,只是用作一些辅助模块。
而在本文中提出了一种简单有效的可变形的自注意力模块,并在此模块上构造了一个强大的Pyramid Backbone,即可变形的注意力Transformer(Deformable Attention Transformer, DAT),用于图像分类和各种密集的预测任务。不同于DCN:在整个特征图上针对不同像素学习不同的offset,DAT中学习几组与query无关的offset(所有query共享),将key和value移到重要区域。不同query的全局注意力通常会导致几乎相同的注意力模式。这种设计既保留了线性空间的复杂性,又为Transformer的主干引入了可变形的注意力模式。
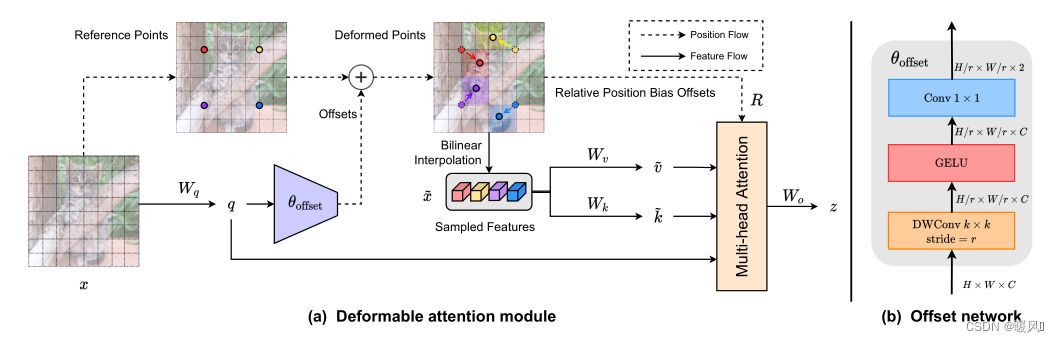
2 Method
现有的分层Vision Transformer,特别是PVT和Swin Transformer试图解决过度关注(减少计算量)的问题。前者的降采样技术会导致严重的信息丢失,而后者的注意力转移会导致感受野的增长要慢得多,这限制了建模大物体的能力。因此,需要一种依赖数据的稀疏注意力来灵活地建模相关特征。这也启发我们将DCN引入Transformer中。
然而,怎样在Transformer模型中实现 DCN 是一个重要且复杂的问题。在DCN中,特征图上的每个元素分别学习其offset,其中 H × W × C H×W×C H×W×C特征图上的 3 × 3 3×3 3×3可变形卷积的空间复杂度为 9 H W C 9HWC 9HWC。如果直接在自注意力模块应用相同的机制,空间复杂度将急剧上升到 N q N k C N_qN_kC NqNkC, N q N_q Nq、 N k N_k Nk为query和key的数量,通常有相同的特征图大小 H W HW HW,带来近似四次复杂度。
作者观察到在先前的工作中,不同的query在视觉注意力模型中具有相似的注意力图。因此,选择了一个更简单的解决方案,为每个query共享偏移的key和value以实现有效的权衡。具体来说,本文提出了Deformable Attention,在特征映射中重要区域的引导下,有效地建模Token之间的关系。这些集中的regions由offset网络从query中学习到的多组Deformable sampling点确定。采用双线性插值对特征映射中的特征进行采样,然后将采样后的特征输入key投影得到Deformable Key。
2.1 Deformable Attention
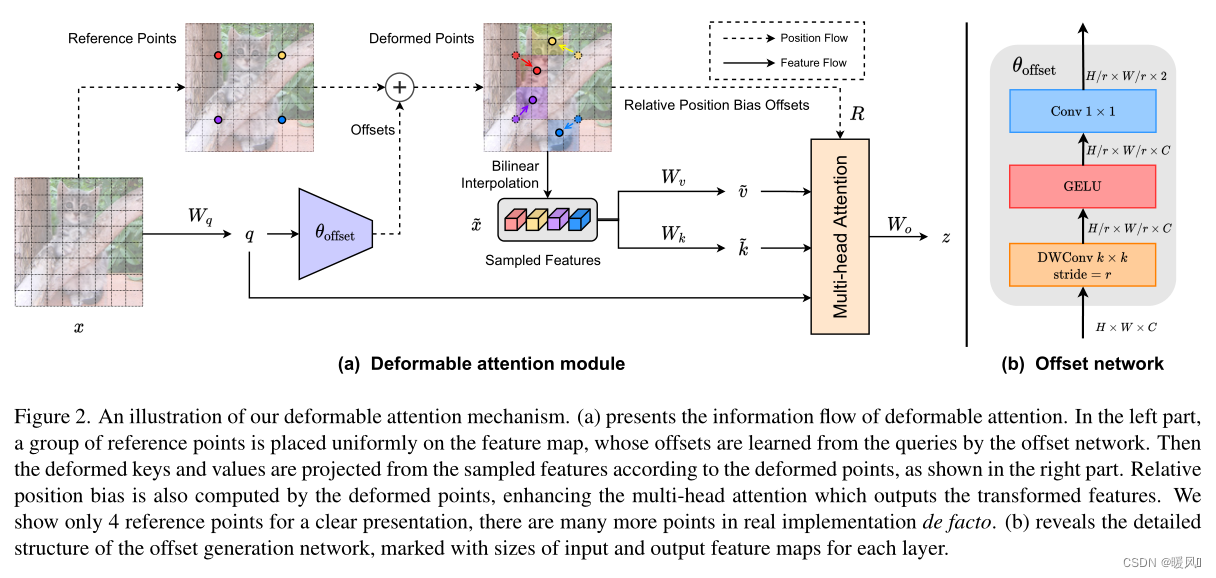
可变形注意力模块:
如图所示,输入特征图像
x
∈
R
H
×
W
×
C
x∈R^{H×W×C}
x∈RH×W×C,生成一个参考网格,其中参考点
p
∈
R
H
G
×
W
G
×
2
p∈R^{H_G×W_G×2}
p∈RHG×WG×2。该网格是从输入特征图
x
x
x降采样而来,降采样系数为
r
r
r,
H
G
=
H
/
r
,
W
G
=
W
/
r
H_G=H/r,W_G=W/r
HG=H/r,WG=W/r。参考点的值代表的是坐标值
(
0
,
0
)
,
.
.
.
(
H
G
−
1
,
W
G
−
1
)
(0,0),...(H_G-1,W_G-1)
(0,0),...(HG−1,WG−1),再归一化到
[
−
1
,
+
1
]
[-1,+1]
[−1,+1],其中
(
−
1
,
−
1
)
(-1,-1)
(−1,−1)表示左上角,
(
+
1
,
+
1
)
(+1,+1)
(+1,+1)代表右下角。
输入特征图像
x
x
x将特征线性投影到
q
=
x
W
q
q=xW_q
q=xWq,再输入到一个轻量级子网络offset network(如上图右侧b),生成偏移量
Δ
p
=
θ
o
f
f
s
e
t
(
q
)
Δp=θ_{offset(q)}
Δp=θoffset(q)。为了稳定训练过程,使用了一些预定义的因子来衡量
Δ
p
Δp
Δp的振幅,以防止太大的offset,即
Δ
p
←
s
t
a
n
h
(
Δ
p
)
Δp←stanh(Δp)
Δp←stanh(Δp)。(其实就是DCN-v2)(其实代码中并没有对参考网格进行降采样,使用的是原始大小和输入特征大小一致,所以产生的offset大小也是一致的,否则offset和参考点加不上,可能同时对offset进行降采样。其次offset中包含该采样点周围一共九个点的偏移,代码中仅使用中间的偏移量作为该点的offset,类似光流)
然后将获得的offset作用在参考点上,获得变形点的位置,进行特征采样(双线性插值)得到
x
^
\hat x
x^,再通过投影矩阵生成Key和Value,
k
^
=
x
^
W
k
,
v
^
=
x
^
W
v
\hat k=\hat xW_k,\hat v=\hat xW_v
k^=x^Wk,v^=x^Wv。
qkv进行多头注意力计算,同时加入相对位置偏移嵌入(注意,相对位置嵌入也同样使用是插值
∅
\varnothing
∅)。最后将获得的多头
z
(
m
)
z^{(m)}
z(m)特征拼接起来,通过投影矩阵获得最终的注意力模块输出Z。
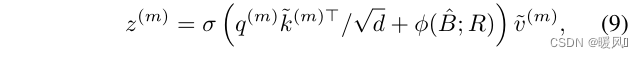
offset的生成:
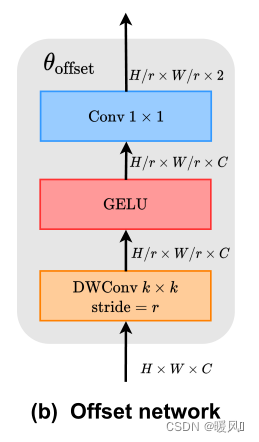
offset子网络使用query特征输出参考点的offset值。输入特征首先经过一个5×5的深度卷积来捕获局部特征。然后采用GELU激活和1×1卷积得到二维偏移量。同样值得注意的是,1×1卷积中的偏差被降低,以缓解所有位置的强迫性偏移。
复杂度计算:
可变形多头注意力模块(DMHA)的计算成本与同级别的Swin-Transformer和PVT相似,略高于Swin-Transformer一丢。
DMHA的计算复杂度:Ns为采样点数量49
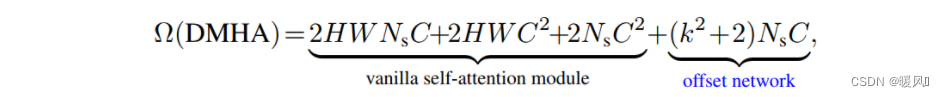
Swin-Transformer的计算复杂度:M为窗口大小7
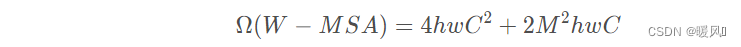
复杂度计算简方法,不清楚的同学可以看下面的图
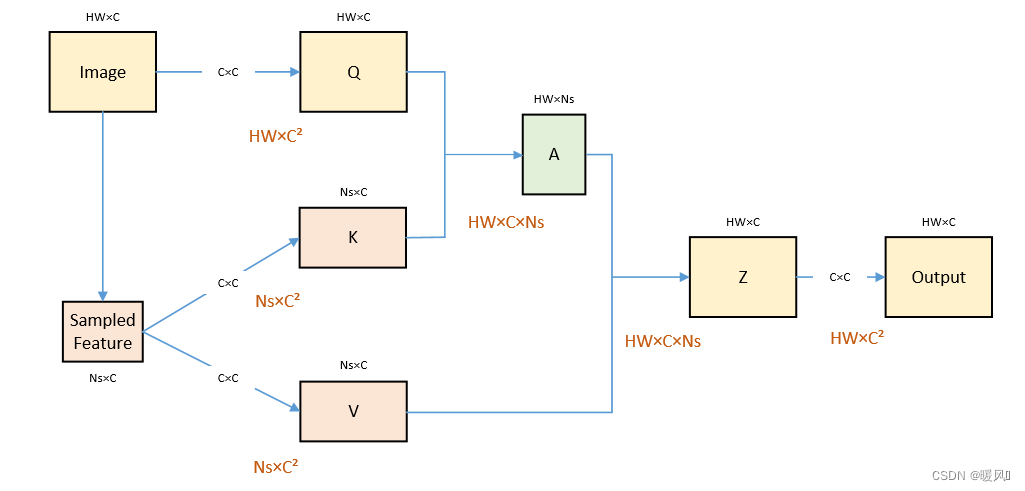
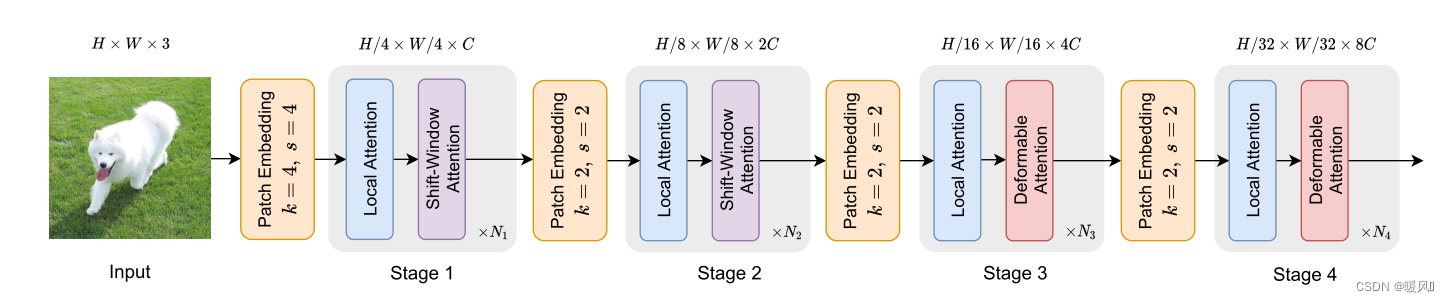
2.2 Model Architectures
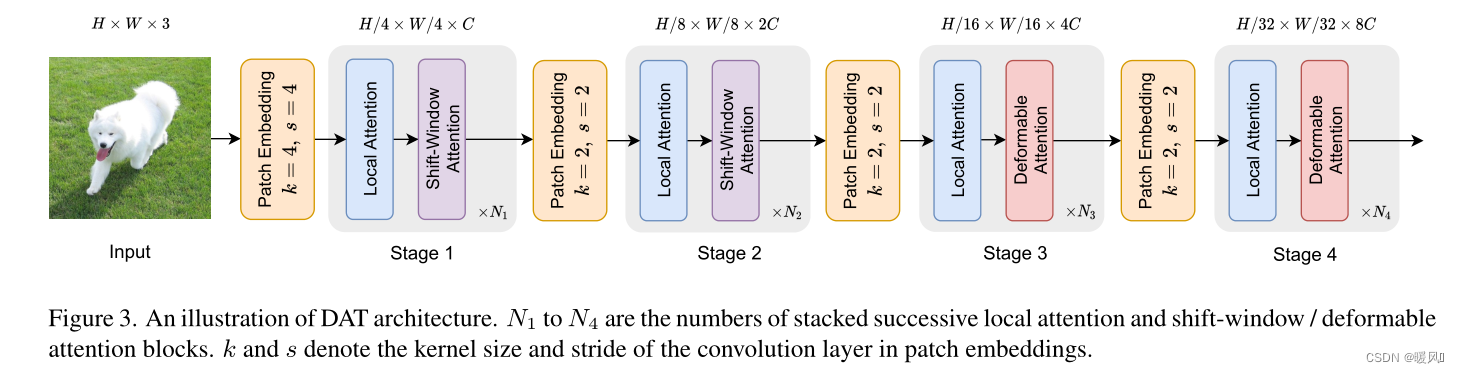
模型整体结构,有没有觉得很熟悉,我们放一下Swin-Transformer的模型架构(不能说是毫无关系,只能说是一摸一样了(不是)😏)
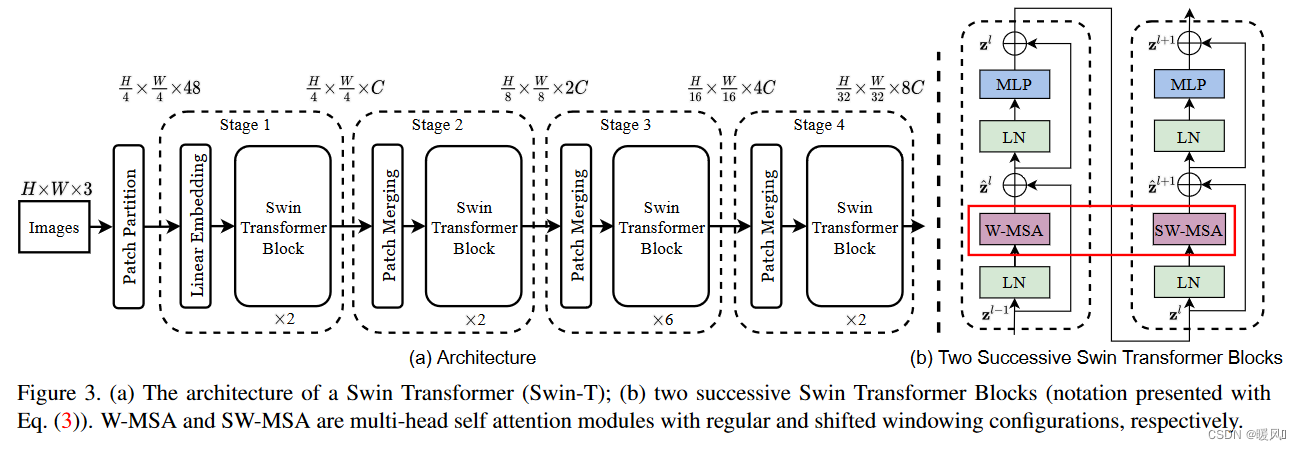
唯二改动的地方就是在第三和第三阶段的SW-MSA(滑动窗口注意力模块)部分替换成了DMHA,网络深度设计也是一样的。
首先对形状为 H × W × 3 H×W×3 H×W×3的输入图像进行 4 × 4 4×4 4×4不重叠的卷积嵌入,然后进行层归一化,得到 H / 4 × W / 4 × C H/4×W/4×C H/4×W/4×C的patch嵌入。为了构建一个层次特征金字塔,Backbone包括4个阶段,stride逐渐增加。在2个连续的阶段之间,有一个不重叠的 2 × 2 2×2 2×2卷积与 s t r i d e = 2 stride=2 stride=2来向下采样特征图,使空间尺寸减半,并使特征尺寸翻倍。(和Swin-Transformer一样滴)
在DAT的第三和第四阶段引入Deformable Attention Block。特征图首先通过基于Window的Local Attention(Swin-Transformer Block的第一个注意力计算)进行处理,以局部聚合信息,然后通过Deformable Attention Block对局部增强token之间的全局关系进行建模。这种带有局部和全局感受野的注意力块的替代设计有助于模型学习强表征,在GLiT、TNT和Point-Former中具有相似的模式。
由于前两个阶段主要是学习局部特征,因此在这些早期阶段的Deformable Attention不太适合。此外,前两个阶段的key和value具有较大的空间大小,大大增加了Deformable Attention的点积和双线性插值的计算开销。因此,为了实现模型容量和计算负担之间的权衡,这里只在第三和第四阶段放置Deformable Attention,并在Swin Transformer中采用Shift Window Attention,以便在早期阶段有更好的表示。事实上,前两个阶段还有其他的设计选择,例如,PVT中的SRA模块。
作者设置了不同参数和FLOPs的3个变体,以便与其他Vision Transformer模型进行公平的比较。通过在第三阶段叠加更多的块和增加隐藏的维度来改变模型的大小。如表1。DAT-T的模型设计和Swin-T是一样的,可以看到后面的参数Swin-T是4.5G,DAT-T是4.6G非常相似。
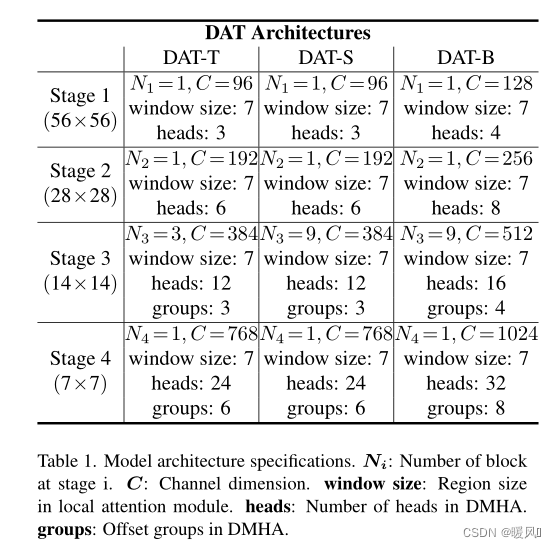
应用:
在分类任务中,首先对最后一阶段输出的特征图进行归一化处理,然后采用具有合并特征的线性分类器来预测logits。
在目标检测、实例分割和语义分割任务中,DAT扮演着Backbone的作用,以提取多尺度特征。
实验部分具体可以看原文,可以看到DAT的参数量和Swin-Tranformer、PVT、DeiT、GLiT对应模型非常相似,但效果要高于其他模型。作者分别对比了分类任务、目标检测任务、语义分割任务上各模型性能的对比。
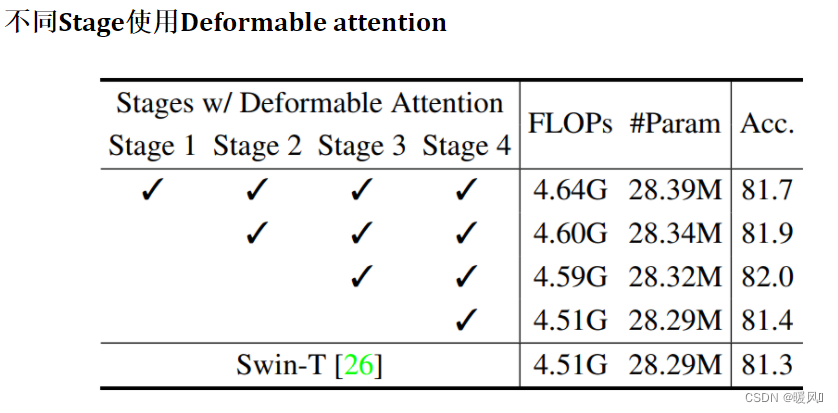
在消融实验中可以看出:
- 可变形偏移量和可变形相对位置嵌入的有效性。
- 在前两个阶段适应不同的注意力模块(PVT的SRA和Swin做对比 ),实验表明使用swin的效果要更好。
- 在第三阶段第四阶段使用DAT效果最好。
原文中还有可视化结果,有兴趣的可以去看一看。
3 Conclusion
作者提出了一种新的注意力模块,融入了可变形机制,叫可变形多头注意力模块DMHA,替换Swin-Transformer第三四阶段的滑动窗口注意力模块。
- 只替换第三四阶段是因为,可变形卷积非常吃计算量,而到了第三四阶段,特征的大小已经降到非常小了,并不会消耗太多的计算量了。
- 并且Swin-Transformer中基于窗口的注意力计算是一种局部信息聚合,而可变形注意力能够对全局关系进行建模,这种方法同时结合了局部和全局感受野的注意力计算有助于模型学习强表征。
- 可变形注意力模块中保持q不变,通过q计算出offset,得到偏移后的特征用于产生k、v,再进行注意力计算。这种方式能够有选择性地关注更重要的区域,增强模型的建模能力。
最后祝各位科研顺利,身体健康,万事胜意~














 2893
2893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









