







 文章介绍了VisionTransformer如何采用可变形注意力模块改进信息丢失问题。通过学习的偏移网络,动态调整采样点,提高对大目标的处理能力。这种方法结合了双线性插值和多头注意力,同时通过偏移组增加变形点的多样性。
文章介绍了VisionTransformer如何采用可变形注意力模块改进信息丢失问题。通过学习的偏移网络,动态调整采样点,提高对大目标的处理能力。这种方法结合了双线性插值和多头注意力,同时通过偏移组增加变形点的多样性。
《Vision Transformer with Deformable Attention》笔记
方法
1.可变形机制
- PVT的降采样导致信息丢失
- 滑动窗口注意力感受野增长慢(大目标不友好)
- DCN首次提出可变形机制(空间复杂度大)
- DETR设置比较小的keys减少开销(导致信息丢失)
- 本文利用特征图中重要区域去指导reference points
- 这些聚焦区域由多组deformable points确定,这些采样点通过偏移网络从query中学习到。
- 采用双线性插值法从特征图中采样特征
- 然后将采样的特征输入键和值投影,得到变形的键和值
- 最后,应用标准的多头注意方法来参与对采样键的查询
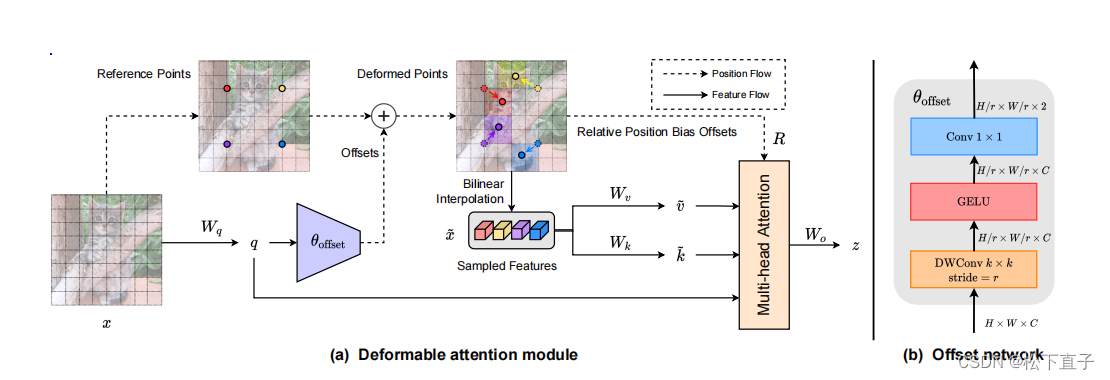
2.Deformable attention module.
-
给定输入特征图x∈H×W×C,生成一个点p∈HG×WG×2的统一网格作为参考。
-
网格大小从输入的特征图大小中降采样一个因子r,HG = H/r,WG = W/r
-
参考点的值为线性间隔的二维坐标{(0,0),……(HG−1,WG−1)}
-
然后根据网格形状HG×WG将其归一化到范围[−1,+1],其中(−1,−1)表示左上角,(+1,+1)表示右下角。
-
为了获得每个参考点的偏移量,将特征映射线性投影到查询标记q=xWq,然后输入一个轻量子网络θoffset(·),生成偏移量∆p=θoffset(q)。
-
为了稳定训练过程,我们用一些预定义的因子s来缩放∆p的振幅,以防止过大的偏移量,即∆p←tanh(∆p)。
-
投影矩阵:
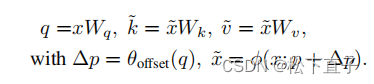
-
将采样函数φ(·;·)设置为双线性插值,使其可微:
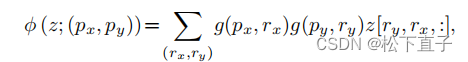
其中,g(a,b)= max(0,1−|a−b|),(rx,ry)索引在z∈RH×W×C上的所有位置
- 注意力头的输出公式为:

3.Offset generation.
- 考虑到每个参考点覆盖一个局部s×s区域(s是偏移的最大值),生成网络也应该有对局部特征的感知,以学习合理的偏移。
- 将子网络实现为两个具有非线性激活的卷积模块
- 首先通过一个5×5的深度卷积来捕获局部特征
- 然后,采用GELU激活和1×1卷积得到二维偏移量。
- 1×1卷积的偏差被降低,以缓解所有位置的强迫性偏移。
GELU激活和1×1卷积得到二维偏移量。
- 1×1卷积的偏差被降低,以缓解所有位置的强迫性偏移。
4.Offset groups.
- 为了促进变形点的多样性,在MHSA中遵循类似的范式,并将特征通道划分为G组。
- 每个组的特征使用共享的子网络分别生成相应的偏移量。
- 在实际应用中,注意模块的头数M被设置为偏移组G大小的多倍,确保多个注意头被分配给一组变形的键和值。


















 2444
2444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











