






- 无锁的优缺点
1. 优点:无锁情况下即使重试失败,线程仍然在高速运行,而synchronized会让线程在没获得锁的情况下发生上下文切换,进入阻塞,等到下次唤醒还得启动线程,所以效率比较低
2. 不足:无锁状态下如果没有额外的cpu,虽然不会进入阻塞,但是会没有分到时间片而导致进入可运行状态,还是会导致上下文切换。
CAS----CompareAndSet(基于乐观锁)
- CAS的工作方式:
(ref.compareAndSet(prev, excp),CAS首先拿出预期的值来与内存中的值进行比较,即prev,如果内存中的值与预期的prev相等,那么就将内存中的值置换成想要修改的值excp。如果不相等,那么就进行一次自旋,从内存中不断的去获取最新的值,直到与自己的预期值相等,就进行修改。
【补充!!】:CAS必须借助volatile帮助,才能获取内存中最新的值 - CAS底层原理:
1. unsafe类:CAS实现的是用我们期望的数跟原本的数进行比较,如果相同我们就修改成我们需要改的数。在CAS的源码中是用unsafe类进行操作的,Java不能直接访问底层系统,unsafe类的所有方法是用native来修饰的,这样可以通过unsafe来直接操作底层特定的数据,通过valueOffset变量来得到内存的偏移地址,直接通过内存地址,获取到值。
2. 自旋锁理论:通过do-while来得到内存中的数并进行比较,不相等就继续去取得主存中的数(不相等可能是因为同时有多个线程取得这个数,准备 修改的一方突然被挂起,导致挂起前后主存中的数据不一致)
3. 用volatile保证可见性:CAS如果失败就重新去获取值,这个过程用volatile修饰变量保证了每次获取到的都是最新的值。 - CAS的缺点:
1. 循环时间长,开销大(因为执行的是do while,如果比较不成功一直在循环,最差的情况,就是某个线程一直取到的值和预期值都不一样,这样就会无限循环)
2. 只能保证一个共享变量的原子操作,对多个共享共享变量无法保证
3. ABA问题:CAS在某一时刻读取数据并从内存中取出值比较并替换,这个时间差可能会导致数据的被进行修改又被修改回去。
例如:两个执行时间不同的线程 一个执行10s 一个执行2s 在同一时刻读取主存中的数据后,2s的线程可能在多个时间段中将主存中数据进行修改后又修改回去,这样在10s的线程执行完毕后发现数据还是一样的,其实已经被修改了 - 怎么解决ABA问题:.通过原子引用类的AtomicStampedReference,这个类具有能更新版本号的功能,每当我们对数据进行一次CAS操作,类中的数据的版本号可以进行更新,只有具有最新版本号的线程才能进行修改,如果不是最新版本号需要去重新获取数据
原子类
- 基本原子类型:AtomicInteger、AtomicLong、AtomicBoolean
以AtomicInteger为例,常用的方法如下;
原理:利⽤ CAS (compare and swap) + volatile 和 native ⽅法来保证原⼦操作 - 原子数组类型:AtomicIntegerArray:整形数组原⼦类、AtomicLongArray:⻓整形数组原⼦类、AtomicReferenceArray:引⽤类型数组原⼦类
- 原子引用类型:AtomicReference:引⽤类型原⼦类、AtomicStampedReference:原⼦更新带有版本号的引⽤类型(每次更新都版本号+1)、AtomicMarkableReference :原⼦更新带有标记位的引⽤类型
- 原子字段更新器:AtomicIntegerFieldUpdater:原⼦更新整形字段的更新器、AtomicLongFieldUpdater:原⼦更新⻓整形字段的更新器、AtomicReferenceFieldUpdater:原子更新器
- LongAdder:LongAdder相对于AtomicLong性能会提升,具体原因是:在有竞争时,设置多个累加单元,Therad-0 累加 Cell[0],而 Thread-1 累加Cell[1]… 最后将结果汇总。这样它们在累加时操作的不同的 Cell 变量,因此减少了 CAS 重试失败,从而提高性能。而AtomicLong会多次使用CAS,造成性能消耗
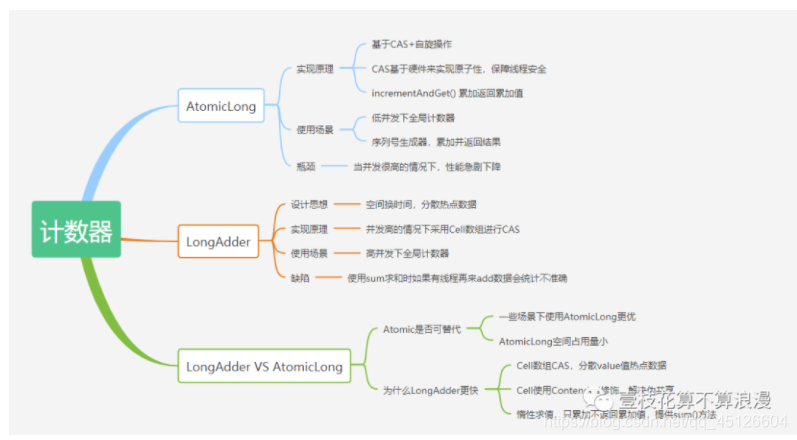
LongAdder特点:
1. 设计思想上,LongAdder采用"分段"的方式降低CAS失败的频次。AtomicLong中存放着内部变量value,所有操作都对这个值进行,高并发下会变成一个竞争热点造成性能消耗。而LongAdder中,采用的分散热点的形式优化这个问题,将value值的新增操作分散到一个数组中,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的那个value值进行CAS操作,这样热点就被分散了,冲突的概率就小很多。在并发度不高的情况下,LongAdder有一个全局变量volatile long base值,当并发不高的情况下都是通过CAS来直接操作base值,如果CAS失败,则针对LongAdder中的Cell[]数组中的Cell进行CAS操作,减少失败的概率。
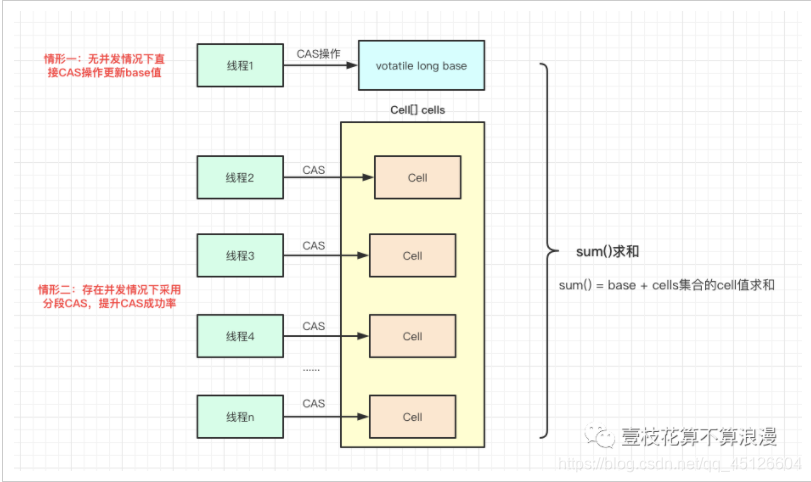
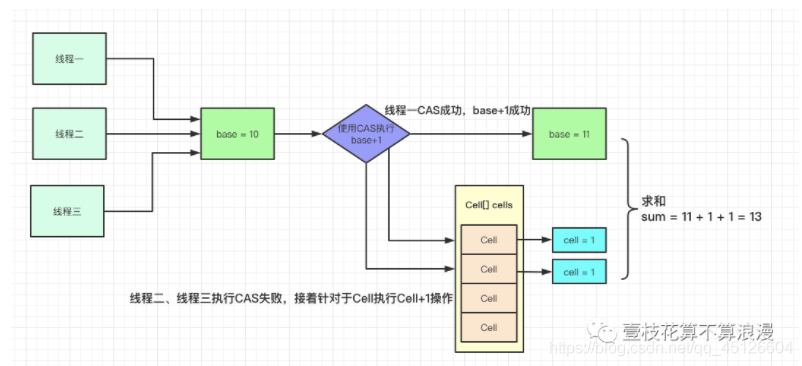
- 使用Contended注解来消除伪共享:
每个Cell都使用@Contended注解进行修饰,而@Contended注解可以进行缓存行填充,从而解决伪共享问题。伪共享会导致缓存行失效,缓存一致性开销变大。让每个Cell在不同的缓存行,同时对每个缓存行进行缓存填充,解决伪共享问题。
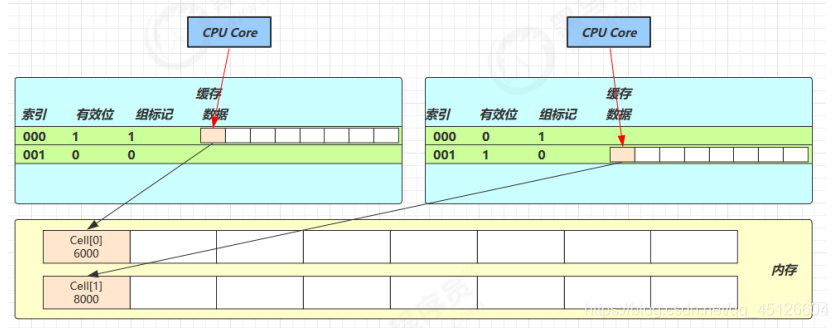
【伪共享问题】:一个缓存行中不会只单单存储 value 一个变量,可能还会存储其他变量,每次都从CPU中复制缓存行大小的内存。这样当一个线程更新了 value 之后,如果其他线程本地缓存中同样缓存了 value, value 所在的缓存行就会失效,这意味着该缓存行上的其他变量也会失效,那么线程对这个该缓存行上所有变量的访问都需要从主存中获取。我们都知道 CPU 访问主存的速度相对于访问缓存的速度有着数量级的差距,这就带了很大的性能问题。 - 惰性求值。LongAdder只有在使用longValue()获取当前累加值时才会真正的去结算计数的数据,longValue()方法底层就是调用sum()方法,对base和Cell数组的数据累加然后返回,做到数据写入和读取分离。而AtomicLong使用incrementAndGet()每次都会返回long类型的计数值,每次递增后还会伴随着数据返回,增加了额外的开销
- 使用Contended注解来消除伪共享:

















 724
724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









