









通过自学来完善自己:基于自知识蒸馏的特征提取
(收录于CVPR2021,”知识提取“均可替换为“知识蒸馏”)
作者:Mingi Ji, Seungjae Shin, Seunghyun Hwang, Gibeom Park1
Il-Chul Moon
摘要
知识蒸馏是一种将知识从预先训练的复杂教师模型转移到学生模型的方法,因此在部署阶段,较小的网络可以取代较大的教师网络。为了减少培训大型教师模型的必要性,最近的文献介绍了一种自我知识蒸馏方法,该方法在没有预先培训的教师网络的情况下,逐步训练学生网络提取自己的知识。虽然自知识蒸馏在很大程度上分为基于数据增强的方法和基于辅助网络的方法,但数据增强方法在增强过程中失去了其局部信息,这妨碍了其对各种视觉任务(如语义分割)的适用性。
此外,这些知识提取方法没有得到细化的特征映射,这在目标检测和语义分割领域非常普遍。本文提出了一种新的自知识提取方法,即基于自知识蒸馏的特征细化(FRSKD),该方法利用辅助自教师网络将细化后的知识传递给分类器网络(学生网络)。我们提出的方法FRSKD可以利用软标签和特征映射提取来进行自我知识蒸馏。因此,FRSKD可以应用于分类和语义分割,强调保留局部信息。
通过列举FRSKD在不同任务和基准数据集中的性能改进,我们证明了FRSKD的有效性。实现的代码可在https://github.com/MingiJi/FRSKD.

图1.各种蒸馏方法的比较。黑线是前进的道路;绿线是软标签蒸馏;橙色线是蒸馏的特征。(a) 传统的知识提炼方法与预先培训的教师[9,26,37,14,1]。(b) 通过数据扩充的自我知识提取方法[32,36,18]。(c) 基于辅助弱分类器的自知识提取,创建一组分层分类器以在每一层生成反向传播信号,分层分类器根据橙色线的层特征提取和绿线的logit提取生成其估计[40]。(d) 我们提出的方法。原始分类器提供原始特征作为辅助自教师网络(蓝色块)的输入。然后,自教师网络提取细化的特征映射到原始分类器(橙色线)。
1.介绍
由于卷积神经网络的指数级发展,深度神经网络(DNN)已应用于计算机视觉的各个领域[7,27,12]。为了在移动设备上取得成功,视觉任务需要克服有限的计算资源[11,42]。为了解决这一问题,模型压缩一直是一项关键的研究任务,而知识蒸馏是一项突出的技术,具有良好的压缩性能和等效性能[9]。
知识蒸馏是一种将知识从预先培训的教师网络转移到学生网络的方法,因此在部署阶段,较小的网络可以取代较大的教师网络。知识提炼通过以下方式利用教师的知识:
1)将课堂预测作为软标签[9];2) 倒数第二层输出[29、21、23]或 3)特征图,包括中间层的空间信息[26、2、8]。
尽管知识蒸馏能够以浓缩的方式利用更大的网络,但在如此大的网络(即教师网络)上的推理成为其实际使用的最终负担。此外,对大型网络进行预训练需要大量的计算资源来准备教师网络。
为了减少训练大型网络的必要性,最近的文献引入了一种替代性的知识蒸馏[6,43];这是一个与学生网络结构相同的预训练网络的蒸馏。
众所周知,这种知识提炼对同样规模的学生网络仍然是有用的。此外,还有关于自我知识蒸馏的文献,该文献逐步训练学生网络,以提炼并规范其自身知识,而无需预先训练的教师网络[44、36、18、32、40]。自我知识蒸馏不同于以往的知识蒸馏,因为它不需要事先准备教师网络。
自知识蒸馏主要分为基于数据增强的方法和基于辅助网络的方法。基于数据增强的自知识蒸馏导致了对相关数据的一致预测,即不同扭曲版本的单一实例或来自同一类的一对实例[32,36,18]。基于辅助网络的方法利用了分类器网络中间的分支,并通过知识转移(44,40)诱导额外的分支进行类似的输出。然而,这些方法依赖于辅助网络,它的复杂性与分类器网络相同或较小;因此很难为分类网络[32、36、18、44、40]生成关于卷积层的特征或软标签的精炼知识。此外,基于数据增强的方法很容易丢失实例之间的位置信息,例如不同扭曲的实例或旋转的实例。因此,很难利用特征蒸馏技术来提高普通知识蒸馏的性能[32,36,18]。
为了解决现有的自我知识蒸馏的局限性问题,本文提出了一种新的自知识精馏法,即Feature refine - via self-knowledge精馏法(FRSKD),该方法引入了一种辅助的自教师网络,使精炼知识能够转移到分类器网络。图1显示了FRSKD与现有知识蒸馏方法的区别。本文提出的方法FRSKD可以同时利用软标签和特征图两种方法进行自知识蒸馏.
因此,FRSKD可以应用于强调局部信息保存的分类和语义分割。与其他自知识提取方法相比,FRSKD在各种数据集上显示了图像分类任务的最新性能。此外,FRSKD提高了语义分割的性能。此外,FRSKD与其他自知识蒸馏方法以及数据扩充方法兼容。我们通过各种实验证明了FRSKD的兼容性和性能的大幅提高。
2.相关工作
知识蒸馏
知识蒸馏的目标是为了有效地训练一个更简单的网络,又称为一个学生网络。通过传递预先训练的复杂网络的知识,又称为一个教师网络。在这里,知识包括隐藏层的特征或者final层的日志,等等。Hinton等人提出了一种将教师网络输出逻辑传递给学生网络的知识升华方法[9]。
然后介绍了中间层蒸馏方法,这些方法利用教师网络的知识,无论是在具有特征映射级保持局部性的卷积层[26,37,14,34,16];或者是惩罚层[24,29,21,23,30]。在特征图提取方面,前人的工作促使学生去模仿
1)教师网络的特征[26],2)教师网络的抽象注意图[37],或3)教师网络的FSP矩阵[34]。
对于倒数第二层的提取,现有文献利用实例之间的关系作为知识,即同一倒数第二层特征集之间的余弦相似性,从对的情况[24,29,21,23,30]。此外,先前的实验表明,当不同的蒸馏方法联合使用时,这些蒸馏方法在不同的蒸馏装置上表现得更好。然而,存在两个明显的局限性:1)知识蒸馏需要预训练复杂的教师模型;2)教师网络的变化会导致同一学生网络的不同表现。
自我知识蒸馏
通过在没有教师网络的情况下利用自己的知识来提高培养学生网络的有效性。
首先,一些方法利用辅助网络进行自我知识的升华。例如,BYOT引入了一组辅助弱分类器网络,利用中间隐藏层的特征对输出进行分类[40]。BYOT的弱分类器网络通过对估计的logit值和真实监督的联合监督进行训练。其中一个利用额外的分支在中间层使模型参数和估计的特征多样化。这种多样性通过集成方法聚合,集成输出产生分支共享的联合反向传播信号[44]。这些辅助网络方法的共同点是在同一层使用Adhoc结构,在中间层使用弱分类器网络。因此,这些没有增强网络的方法可能缺乏更精确的知识。
第二,数据增强也被用于自我知识蒸馏。DDGSD通过提供不同的增强实例来诱导一致性预测,因此分类器网络将面临实例的变化[32]。CSKD使用属于同一类别的其他实例的Logit进行正则化,因此分类器网络将预测相同类别的类似结果[36]。然而,数据扩充并不一定保留空间信息,即简单的翻转会破坏特征的局部性,因此特征映射提取很难应用于数据扩充中。SLA提出将自我监督任务与原始分类任务相结合来扩充数据标签。自我监督采取了诸如输入旋转之类的增强,而增强实例的集成输出为反向传播提供了额外的监督[18]。
理想情况下,可以通过从复杂模型中提取精炼知识来改进体征图的提取。然而,先前工作的辅助结构并没有提供这样一种使特征更复杂的方法。相反,在某些情况下,数据增加可能会增加数据变化或细化,但它们的变化可能会阻碍特征图提取,因为这种变化会阻止从参数方面进行一致的局部建模。因此,我们推测,为特征映射蒸馏提供细化是基于辅助网络的自知识蒸馏的一个突破。因此,我们建议使用辅助自教师网络来生成精细的特征图及其软标签。据我们所知,本文是第一个在自教师网络上从单个实例生成精细特征映射的工作。
特征网络
我们建议的辅助自教师网络结构是从用于目标检测领域的特征网络发展而来的。不同尺度特征的聚集是处理多尺度特征的关键之一,目标检测领域在[19,15,41,20,28]中研究了这种尺度变化。
我们的辅助自教师网络通过使处理多尺度特征的网络适应知识提取的目的来生成细化的特征图。虽然我们将在第3.1节中解释该结构的适应性,但本小节列举了功能网络的最新发展。FPN利用自上而下的网络同时利用1)上层的抽象信息和2)骨干网络下层的小对象信息[19]。PANet为FPN引入了额外的自底向上网络,以实现检测层和主干层之间的短路径连接[20]。BiFPN提出了一种更有效的网络结构,使用与PANet相同的自顶向下和自底向上网络[28]。本文提出了一种辅助自教师网络,该网络由BiFPN的结构改变为适合于分类任务。
此外,通过改变网络结构,特征映射提取变得高效,因为自教师网络比BiFPN需要更少的计算,而BiFPN是通过根据特征映射的深度改变通道维度来实现的。
3.方法
本节介绍一种特征细化自知识蒸馏(FRSKD)。图2显示了我们蒸馏方法的概述,第3.1节从自学网络的角度对其进行了进一步讨论。
然后,我们在第3.2节回顾了自我知识提炼的培训步骤。
标注:让
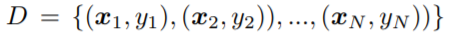
是一组带标签的实例,其中N是其大小;设Fi,j(i,j是下标)是第i个样本的分类器网络的第j个块的特征映射;让cj(下标)是分类器网络的第j个块的通道维度。为了简单起见,我们在本文的其余部分省略了索引i。
3.1自教师网络
自教师网络的主要目的是为分类器网络自身提供一个精确的特征映射及其软标签。自教师网络的输入是分类器网络的特征映射F1,…,Fn,其假设分类器网络的n个块。我们通过修改分类任务的BiFPN结构来建模自教师网络。具体来说,我们采用了PANet和BiFPN[28,20]中的自顶向下路径和自底向上路径。在自上而下路径之前,我们利用横向卷积层,如下所示:
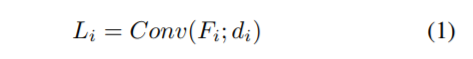
tips:(xb)说明是下标
Conv是一种具有di(xb)维输出的卷积操作。不像在网络创建时就已经修理过的已经存在的横向卷积层,我们设计的di(xb)依赖于特征图的通道维度ci(xb)。我们让di=w×ci(xb),w是通道宽度元素。对于分类任务,对于更深的层数去设置一个更高的通道维度是很自然的事情。
因此,我们调整了每一层的通道维数来保持它的特征图深度的信息。这种设计也减少了横向层的计算量。

图2.概述我们提出的自知识蒸馏方法,通过自知识蒸馏进行特征细化(FRSKD)。自顶向下路径和自下而上路径聚合不同大小的特征,并向原始分类器网络提供细化的特征映射。FRSKD利用自教师网络的特征映射,对细化后的特征映射和软标签进行提取。
自上而下路径和自下而上路径聚合了不同的功能,如下所示:
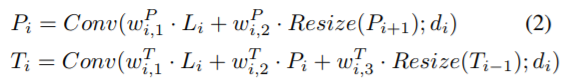
Pi(xb)代表自上到下路径的第i层,Ti(xb)是自下到上的第i层。和BiFPN[28]一样,不同深度的层的前向传递连接有着不同的结构。在图2中,在这个例子里,自下而上路径中的最浅的层T1和自下而上路径中最深的层T4,每一层都为了效率而分别直接使用了横向层L1和L4作为输入,而不是使用自上到下路径中的特征。在这些设置中,为了创造一个自上而下的能够连接所有最浅的层和中间层和最深的层的结构,将添加用于正向传播的两个对角连接:1)从最横向的层L4的连接到自上而下路径的倒数第二层P3;和2)从P2到自下而上路径中的第一层T1的连接。
我们应用了一种带有参数的快速归一化融合,如WP和WT [28]。我们使用双线性插值进行上采样,使用最大池进行下采样,作为调整大小的操作。为了高效计算,我们对卷积运算使用深度卷积[11]。我们根据第4.3节中的自我教师网络结构进行了各种实验,并对结果进行了分析。最后,我们在自底向上路径的顶部附加全连接层来预测输出类,自教师网络提供其软标签,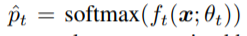
,其中ft(xb)代表自教师网络,由θt(xb)参数化。
3.2自特征提取
我们提出的模型FRSKD利用了自教师网络的输出、细化的特征映射Ti和软标签pˆt(^在p上方,t是下标)。首先,我们添加了特征提取,这导致分类器网络模仿细化的特征图。对于特征提取,我们采用注意转移[37]。方程3定义了特征蒸馏损失LF(xb):
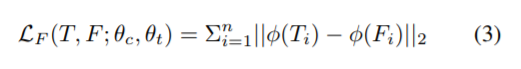
这里,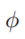 是通道池功能与L2规范化的组合[37];θc(xb)是分类器网络的元素。提取特征图的空间信息。因此,LF(xb)让分类器网络学习自教师网络细化特征映射的局部性。此外,训练一个分类器网络去精确模拟细化的特征图是可能的[26,8];或者使用特征图的转移[34]。除非标注出来的,本文利用了基于注意转移的特征提取,我们在第4.3节讨论了特征提取的方法。
是通道池功能与L2规范化的组合[37];θc(xb)是分类器网络的元素。提取特征图的空间信息。因此,LF(xb)让分类器网络学习自教师网络细化特征映射的局部性。此外,训练一个分类器网络去精确模拟细化的特征图是可能的[26,8];或者使用特征图的转移[34]。除非标注出来的,本文利用了基于注意转移的特征提取,我们在第4.3节讨论了特征提取的方法。
与其他自蒸馏方法类似,FRSKD也通过软标签pˆt进行蒸馏,如下所示:
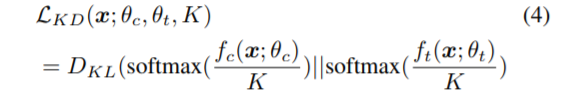
其中,fc(xb)是分类器网络;K是温度缩放参数。同时,这个分类器网络和自教师网络学习了一个使用交叉熵损失的真实标签,L(CE)。通过积分上述的损失函数,我们构建了以下优化目标:
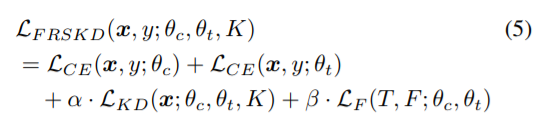
其中,α和β是超参数;我们选择α∈[1,2,3],β∈[100,200];更多细节见附录敏感性分析。对于分类器网络和自教师网络,同时通过反向传播启动优化。为了防止模型崩溃问题[22],FRSKD通过蒸馏损失LKD和LF更新参数,这仅适用于学生网络。
4.实验
我们评估了我们的自我知识提取方法在各种任务上的表现:分类和语义分割。
在本节中,我们主要使用三种设置;仅使用软标签蒸馏(FRSKD\ F);采用L(FRSKD)优化,蒸馏精制特征图及其软标签(FRSKD);并使用我们的方法(FRSKD+SLA)[18]附加基于自我知识提取的数据增强,即SLA。
4.1分类
数据集:我们证明了FRSKD在各种分类数据集上的有效性:CIFAR-100[17]、Tiny ImageNet、加州理工大学UCSD Bird(CUB200)[31]、麻省理工学院室内场景识别(MIT67)[25]、斯坦福40行动(斯坦福40)[33]、斯坦福狗(狗)[13]和ImageNet[3]。Cifar-100和TinyImageNet由小比例图像组成,我们调整了TinyImageNet图像的大小,以满足与Cifar-100相同的大小(32× 32)。CUB200、MIT67、Stanford40和Dogs是用于精细视觉识别(FGVR)任务的数据集。与CIFAR-100和ImageNet相比,FGVR每个类包含的数据实例更少。ImageNet是一个大型数据集,用于验证我们实际测试模型的方法。
实施细节:我们对CIFAR-100和TinyImageNet使用ResNet18和WRN-16-2[7,38]。为了使ResNet18适应小规模的数据集,我们将ResNet18的第一个卷积层修改为3×3的内核大小、一个步长和一个填充。我们还删除了最大池操作。我们使用标准ResNet18执行FGVR任务;我们将ResNet18和ResNet34应用于ImageNet。
对于所有分类实验,我们使用随机梯度下降(SGD),初始学习率为0.1,权重衰减为0.0001。对于CIFAR-100、TinyImageNet和FGVR,我们将总epoch设置为200,在epoch100和150,我们将学习率除以10。
对于ImageNet,我们将总epoch设置为90,并在epoch30和60将学习率除以10。对于CIFAR-100和TinyImageNet,我们将批量大小设置为128,FGVR为32,ImageNet为256。我们在所有实验中使用标准的数据扩充方法,即随机裁剪和翻转。在超参数方面,我们将CIFAR-100设置为α为2,β为100;TinyImageNet的α为3,β为100;FGVR在ImageNet上α和β分别为1和200。此外,我们将温度标度参数K设置为4;在所有实验中,我们将channel宽度参数w设置为2。更多详情见附录实施详情。
基线:我们将FRSKD与标准分类器(称为基线)进行比较,标准分类器不使用蒸馏,使用基于交叉熵的损失和六种自知识蒸馏方法,共有七条基线。
(七种基线见论文原文)
我们利用可用的官方代码进行实施[36,18,44]。另外,我们根据相应的论文实现了模型。我们根据数据集应用相同的训练设置,并调整基线模型的超参数。
表现比较:表1显示了具有两种不同分类器网络结构的CIFAR-100和Tiny-ImageNet的分类精度。大多数自知识蒸馏方法提高了标准分类器的性能。与基线相比,FRSKD始终显示出比其他自知识蒸馏方法更好的性能。此外,不利用特征提取的FRSKD\F显示出比其他基线更好的性能。结果表明,自教师网络的软标签优于基于数据扩充的方法。此外,特征提取的效果由FRSKD相对于FRSKD\F的性能表现来证明。我们提出的模型FRSKD不依赖于数据增广,因此FRSKD与其他基于数据增广的自知识蒸馏方法兼容,如SLA-SD。因此,我们通过集成FRSKD和SLA-SD (FRSKD+SLA)来进行实验,并且FRSKD+SLA在大多数实验中显示出大幅度的性能改进。

表1:CIFAR-100和Tiny-ImageNet上的性能比较。实验重复三次,我们记录最后一个epoch的准确度的平均值和标准偏差。表现最好的模型用黑体表示。第二好的模型用下划线表示。

表2:FGVR的性能比较。实验重复三次,我们报告最后一个时期的准确度的平均值和标准偏差。表现最好的模型用黑体表示。第二好的模型用下划线表示。
表2显示了FGVR任务的分类精度。与表1的结果类似,FRSKD显示出比其他自知识蒸馏方法更好的性能。FRSKD相对于FRSKD\F的优越性能表明,当使用更大的图像时,特征提取的效果更好。此外,FRSKD+SLA相比于其他方法都具有更大的优势,因此FRSKD与基于数据增强的自知识蒸馏方法的兼容性在FGVR任务中提供了显著的优势。
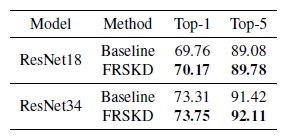
表3:ImageNet上的性能比较。表现最好的模型用黑体表示。
为了在大规模数据集上演示FRSKD,我们在ImageNet上用两个主干网络替代方案ResNet18和ResNet34来评估FRSKD。表3显示FRSKD提高了ImageNet上的性能。
4.2分割语义
我们进行了一个语义分割实验来验证FRSKD在不同领域的效率。我们遵循[8]中的大多数实验设置。我们使用VOC2007和VOC2012训练值的组合数据集作为训练集;并且我们使用VOC2007的测试集作为验证集,这是语义分割中广泛使用的设置[4,5]。该实验利用具有堆叠的BIFPN结构的高效探测器[28]作为基线。对于我们的实验,我们堆叠了三个BIFPN层,并且我们使用另外两个BIFPN层作为自教师网络。我们将初始学习率设置为0.01;我们把总时代定为60年;在第40个epoch,我们将学习率除以10。我们在附录实施细节中描述了更多细节。
表4显示FRSKD通过利用来自自教师网络的自知识蒸馏来提高语义分割模型的性能。
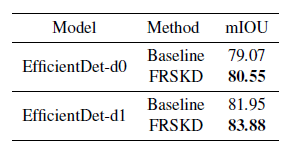
表4:语义分割任务的性能比较。表现最好的模型用黑体表示。
4.3FRSKD的进一步分析
定性的注意图比较:为了检查分类器网络是否从自教师网络接收到有意义的蒸馏,我们通过比较来自分类器网络和自教师网络的每个块的注意力图来进行定性分析。

表5:根据FRSKD的特征蒸馏方法的性能比较。Fit+SKD的特征提取方法基于FitNet[26];OD+SKD是基于over-haul蒸馏[8];而FRSKD是基于注意力转移的[37]。ResNet18用作分类器网络。表现最好的模型用黑体表示。第二好的模型用下划线表示。

图3:分类器网络(来自每个数据的第一行)和自我教师网络(来自每个数据的第二行)之间的分块注意力图比较。从上面,每个数据取自CUB200,狗和MIT67。
我们通过对来自不同数据集(CUB200、MIT67和Dogs数据集)的每个块的特征图应用通道宽度的池化来获得注意力图。我们选择第50个epoch的注意图来观察学习过程中的蒸馏行为。
图3显示了分类器网络和自学网络的分块注意力图的差异。对于来自CUB200数据集的数据,该数据集旨在区分鸟的种类,块2和块3的情况说明分类器网络没有捕获对主要对象(鸟)的适当关注。相比之下,自我教师网络中的区块2和区块3的情况通过利用聚集的特征在目标对象上显示连贯的注意力图。这种趋势也可以在狗数据集的数据中找到。自我教师的注意图相对于偏向人的分类器的注意图,相对集中地指向主要对象(狗),而人不是主要对象。注意力图比较也是在MIT67数据集上进行的,MIT67数据集通过反映整体上下文来执行室内场景识别,而不是专注于单个对象的任务。为了成功地识别数据的场景类(面包店),利用数据内部的上下文线索是很重要的。从区块3的情况来看,与分类器网络不同,自教师网络更关注面包,这可以作为场景类(面包店)的重要线索。
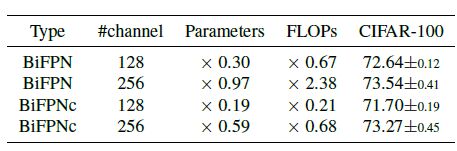
表6:自我教师网络结构之间的性能和效率比较。WRN-16-2在CIFAR-100上用作分类器网络。BIFPN是一种每层通道尺寸相同的结构,BiFPNc是一种通道尺寸根据层的深度而不同的结构,如第3.1节所提出的。#channel是最深层的通道维度,例如Ln,pn和自我教师网络的Tn。# BiFPNc的channel取决于channel宽度参数w,参数和FLOPs是分类器网络的参数和FLOPs的比值。
特征蒸馏法的消融实验:FRSKD能够集成多种特征提取方法,因此我们对集成特征提取的这些变化进行了实验。为了分析性能差异,我们比较了1)精确特征蒸馏方法,FitNet和overhaul蒸馏;和2)FRSKD中使用的注意力转移方法。表5显示FRSKD的注意力转移在各种数据集中获得了比来自精确特征提取的集成的准确性更好的准确性。
自教师网络的结构:为了显示所提出的自教师网络效率,我们实验了各种自教师网络结构,表6显示了实验的变化。高通道维数(256)的BIFPN性能最好,但其参数和FLOPs甚至比分类器网络更大或相似。就效率而言,虽然BIFPN由于其大的参数尺寸而不是自教师网络的适当选择,但是具有高信道维度(256)的BiFPNc以少得多的计算显示出与BIFPN兼容的性能。由于BiFPNc增加的计算量小于分类器网络的计算量,因此FRSKD比基于数据扩充的自知识蒸馏方法更有效,后者重复使用分类器网络。
与知识蒸馏对比:教师网络的知识蒸馏很容易利用蒸馏的特征图及其软标签。因此,我们比较了现有的知识蒸馏和FRSKD,它们扮演着相似的角色。假设我们有一个预训练的教师网络,我们比较精确特征蒸馏方法,FitNet和overhaul蒸馏[26,8];和注意力转移方法[37]。对于知识提炼,我们将教师网络设置为每个数据集上的预训练资源网络34,并将学生网络设置为未训练资源网络18。为了公平比较,每种知识提取方法都利用了特征提取以及软标签蒸馏。FRSKD利用ResNet18作为分类器网络来满足相同的条件。表7显示,在大多数数据集上,FRSKD优于使用预处理教师网络的知识蒸馏实验方法。
使用数据增强进行训练:数据增强的方法与FRSKD兼容。为了验证FRSKD的兼容性,我们用最近的数据增强方法对我们提出的方法进行了实验。Mixup利用了两幅图像及其标签之间的凸组合[39]。Cutmix将一对图像和标签混合在一起,方法是将一个图像切割成patches,然后在另一个图像上粘贴patch。众所周知,这种数据扩充提高了大多数数据集的准确性。表8显示,FRSKD在使用了数据增强后有很大的性能提升。
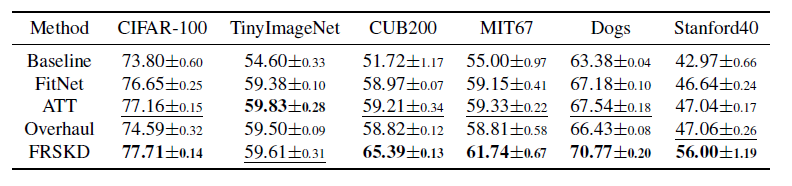
表7:知识蒸馏的性能比较。ResNet18用作分类器网络。表现最好的模型用黑体表示。第二好的模型用下划线表示。
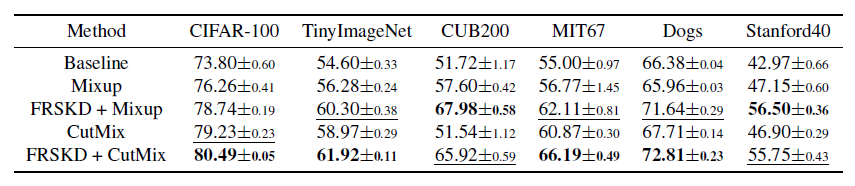
表8:使用FRSKD的数据增强方法的性能。ResNet18用作分类器网络。表现最好的模型用黑体表示。第二好的模型用下划线表示。
5.结论
本文提出了一种自顶向下和自底向上的自知识蒸馏神经网络结构。这些路径的添加有望为分类器网络提供精确的特征映射及其软标签。此外,在保持特征映射细化的同时,通过改变通道维数来减少参数。最后,FRSKD能够将自知识提取应用到分类和语义分割的视觉任务中。我们定量地确认了性能的大幅改善,并通过各种烧蚀研究展示了工作机制的效率。
6.实施细节
分类:WRN-16-2由通道尺寸分别为32、64和128的三个块组成,而ResNet18由通道尺寸分别为64、128、256和512的四个块组成。在本文的所有分类任务实验中,我们将宽度超参数w设置为2。因此,对于WRN-16-2,自教师网络的信道尺寸为64、128、256;对于ResNet18,自教师网络的信道尺寸为128、256、512、1028。
对于Mixup和Cutmix数据增强,我们需要将hyperparameter设置为确定混合权重的贝塔分布模型[35,39]。对于混合,我们将CIFAR-100和TinyImageNet的hyperparameter设置为0.2,将FGVR设置为0.3。对于Cutmix,我们将所有数据集的hyperparameter设置为1.0。
语义分割:对于语义分割,我们将width hyperparameter设置为一个,并在[28]之后为网络架构设置其他设置。在语义切分任务中,我们使用两个重复的BiFPN层来连接自教师网络,并且不改变BiFPN层的通道维度。因此,利用地面真值标签的交叉熵损失来训练三层BiFPN分类器网络,包括主干网络和自教师网络。此外,自教师网络通过软标签和特征对分类器网络进行蒸馏。
由于用于语义分割的标记数据集不足,通常使用预训练主干网络。我们在ImageNet上使用预训练的efficientnet-b0和efficientnet-b1。因此,分类器网络由预训练主干网和BiFPN层组成。我们将预热和退火技术应用于FRSKD的超参数,因为从学习开始的蒸馏可能会成为主干网络训练的一个障碍。我们将预热时间设置为40,预热后自适应增加超参数。我们将超参数α设为1,β设为50。
7.敏感性分析

图4:超参数α和β的敏感性分析。红线表示CIFAR100上WRN-16-2的精度;蓝线表示MIT67上ResNet18的精度。准确度是三次重复实验的平均值。
我们用不同的超参数值评估FRSKD,以研究超参数α和β的影响。我们用α进行实验∈ {1,2,3}和β∈ {50, 100, 200, 500}. 此外,我们在CIFAR-100上将分类器网络设置为WRN-16-2,在MIT67上将分类器网络设置为ResNet18。图4显示了具有不同超参数的每个数据集的准确性。除超参数外,我们保持所有设置与第4.1节相同。我们发现FRSKD对超参数α和β具有鲁棒性,但不同的超参数对不同的数据集表现良好。
8.定性注意图比较
本节提供了定性注意力图比较的额外结果。我们对特征图使用了一种通道方式的池,就像本文中对FRSKD的进一步分析一样。图5显示了随着学习的进展,注意力图的变化。随着训练的进行,分类器网络和自教师网络都将pm作为主要对象。此外,在训练的早期,专注于主要目标的差异比训练的后期更大。

图5:不同时期的分类器网络和自我教师网络之间的分块注意图比较。从上面来看,每个数据都来自CUB200、狗和MIT67。














 867
867











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









