







目录
该论文的bibtex引用格式
@misc{ji2021refine,
title={Refine Myself by Teaching Myself: Feature Refinement via Self-Knowledge Distillation},
author={Mingi Ji and Seungjae Shin and Seunghyun Hwang and Gibeom Park and Il-Chul Moon},
year={2021},
eprint={2103.08273},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
标题的意思:通过自知识蒸馏进行特征细化(FRSKD)
摘要:
知识蒸馏是一种将预先训练好的复杂教师模型的知识转移给学生模型的方法,使得在部署阶段较小的网络可以取代一个庞大的教师网络。为了减少训练大型教师模型的必要性,最近的文献引入了自知识蒸馏方法,逐步训练学生网络以提取自己的知识,而无需预先训练的教师网络。虽然自知识蒸馏在很大程度上分为基于数据增强的方法和基于辅助网络的方法,但数据增强方法在增强过程中丢失了局部信息,这限制了其在语义分割等各种视觉任务中的适用性。此外,这些知识蒸馏方法没有获得精细的特征映射,而在目标检测和语义分割社区中这是普遍存在的。本文提出了一种新颖的自知识蒸馏方法,名为“通过自知识蒸馏进行特征细化(FRSKD),该方法利用辅助的自教师网络来传递分类器网络的精细化知识。我们提出的方法FRSKD可以利用软标签和特征图蒸馏进行自知识蒸馏。因此,FRSKD可以应用于强调保留局部信息的分类和语义分割等任务。我们通过在不同任务和基准数据集中列举其性能改进来展示FRSKD的有效性。已实现的代码可在 https://github.com/MingiJi/FRSKD 上找到。
1.介绍
深度神经网络(DNNs)由于卷积神经网络的指数级发展,已被应用于计算机视觉的各个领域[7,27,12]。为了在移动设备上取得成功,视觉任务需要克服有限的计算资源[11,42]。为解决这一问题,模型压缩已成为一个关键的研究任务,而知识蒸馏是一项突出的技术,具有良好的压缩效果和相当的性能[9]。知识蒸馏是一种从预训练的教师网络向学生网络转移知识的方法,使得在部署阶段较小的网络可以取代一个大型教师网络。知识蒸馏通过接收教师网络的知识,可以利用以下方式:1)作为软标签的类别预测[9];2)倒数第二层的输出[29,21,23];或者3)包括中间层的空间信息的特征图[26,2,8]。虽然知识蒸馏使得能够以精简的方式利用较大的网络,但在这样的大型网络上进行推理,也就是所谓的教师网络,会成为其实际使用的最终负担。此外,对大型网络进行预训练需要大量的计算资源来准备教师网络。
为了减少训练大型网络的必要性,近期的文献介绍了一种替代性的知识蒸馏[6,43];这是从一个与学生网络具有相同架构的预训练网络进行的蒸馏。这种知识蒸馏仍然被认为对具有相同规模的学生网络具有信息价值。此外,还有关于自知识蒸馏的文献,该方法逐步训练学生网络来提取和规范化其自身知识,而无需预先训练的教师网络[44,36,18,32,40]。
自知识蒸馏与之前的知识蒸馏不同,因为它不需要对教师网络进行先期准备。自知识蒸馏主要分为基于数据增强和基于辅助网络两种方法。基于数据增强的自知识蒸馏会诱导出与相关数据一致的预测,即对于同一类别的不同扭曲版本的单个实例或一对实例[32,36,18]。而基于辅助网络的方法则利用分类器网络中间的额外分支,并通过知识传递诱导这些额外分支产生类似的输出[44,40]。然而,这些方法依赖于辅助网络,该网络的复杂度与分类器网络相同或更低;因此很难通过特征(卷积层的输出)或软标签为分类器网络生成精炼的知识[32,36,18,44,40]。此外,基于数据增强的方法容易丢失实例之间的局部信息,比如不同扭曲的实例或旋转的实例。因此,难以利用特征蒸馏这种通常用于改善普通知识蒸馏表现的技术[32,36,18]。
为了应对现有自知识蒸馏的局限性,本文提出了一种新颖的自知识蒸馏方法,名为“通过自知识蒸馏进行特征细化”(FRSKD),该方法引入了一个辅助的自教师网络,以使精炼的知识传递给分类器网络。图1显示了FRSKD与现有知识蒸馏方法之间的区别。我们提出的方法FRSKD可以利用软标签和特征图蒸馏两种方式进行自知识蒸馏。
因此,FRSKD 可应用于强调保留局部信息的分类和语义分割任务。与其他自知识蒸馏方法相比,FRSKD 在多个数据集上的图像分类任务中展现了最先进的性能。此外,FRSKD 在语义分割任务上也提升了性能。另外,FRSKD 与其他自知识蒸馏方法以及数据增强方法兼容。我们通过各种实验展示了 FRKSD 与大幅性能改进的兼容性。
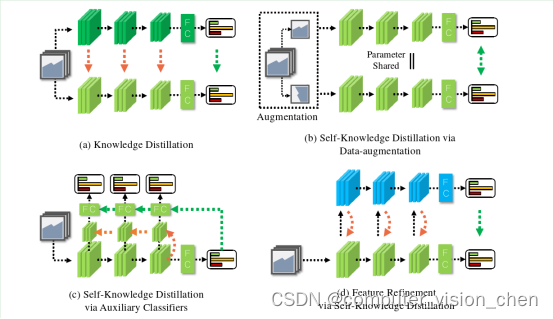
图1:各种蒸馏方法的比较。黑色线条表示前向路径;绿色线条表示软标签蒸馏;橙色线条表示特征蒸馏。
(a) 传统的知识蒸馏方法,使用预训练的教师模型[9,26,37,14,1]。
(b) 通过数据增强进行的自知识蒸馏方法[32,36,18]。
© 基于辅助弱分类器的自知识蒸馏方法,该方法创建一组逐层分类器,在每一层生成反向传播信号,逐层分类器根据橙色线条的特征蒸馏和绿色线条的logit蒸馏产生其估计[40]。
(d) 我们提出的方法。原始分类器将原始特征作为输入传递给辅助自教师网络(蓝色块)。随后,自教师网络将精炼的特征图蒸馏传递给原始分类器(橙色线条)。
2.Related Work
知识蒸馏的目标是通过将预先训练的复杂网络(即教师网络)的知识传递给一个更简单的网络,即学生网络,从而有效地训练学生网络。这里的知识包括隐藏层的特征或最终层的 logit 等。
Hinton 等人提出了一种通过将教师网络的输出 logit 传递给学生网络的知识蒸馏方法[9]。随后引入了中间层蒸馏方法,这些方法利用教师网络的知识,要么是来自具有特征图级别局部性的卷积层[26,37,14,34,16],要么是来自倒数第二层[24,29,21,23,30]。
对于特征图蒸馏,先前的工作诱导学生模仿教师网络的
1)特征[26],
2)抽象的注意力图[37],
3)教师网络的 FSP 矩阵[34]。
对于倒数第二层蒸馏,现有文献利用了实例之间的关系作为知识,即同一倒数第二层的特征集合之间的余弦相似度[24,29,21,23,30]。此外,先前的实验得出结论,当不同蒸馏方法联合应用时,在不同层上表现更好。
然而,存在两个明显的限制:
1)知识蒸馏需要对复杂的教师模型进行预训练,
2)教师网络的变化会导致相同学生网络的性能不同。
自知识蒸馏通过利用学生网络自身的知识而不使用教师网络来增强训练学生网络的效果。首先,一些方法利用辅助网络进行自知识蒸馏。例如,BYOT 引入了一组辅助的弱分类器网络,利用中间隐藏层的特征对输出进行分类[40]。BYOT 的弱分类器网络是通过估计的 logit 值和真实监督的联合监督来训练的。ONE 利用了额外的分支来增加模型参数的多样性,并在中间层估计特征。这种多样性通过集成方法进行聚合,集成输出创建了由分支共享的联合反向传播信号[44]。这些辅助网络方法的共同之处在于在相同层级或中间层使用 Ad-hoc 结构或弱分类器网络。因此,这些方法在没有增强网络的情况下可能缺乏更精细的知识。
其次,数据增强也被用于自知识蒸馏。DDGSD 通过提供不同增强的实例来诱导一致的预测,使分类器网络能够面对实例的变化[32]。CSKD 利用同属于同一类别的其他实例的 logit 值进行正则化,使分类器网络能够为相同类别预测相似的结果[36]。然而,数据增强不一定能够保留空间信息,即简单的翻转可能会破坏特征的局部性,因此特征图蒸馏难以在数据增强的情况下应用。
SLA 提出了通过将自我监督任务与原始分类任务相结合来增强数据标签。自我监督采用输入旋转等增强方式,并且增强实例的集成输出为反向传播提供了额外的监督[18]。理想情况下,特征图蒸馏可以通过从复杂模型中提取精细化的知识来改进。然而,先前工作的辅助结构并没有提供使特征更加复杂的方法。相反,数据增强可能会在某些情况下增加数据变化或细化,但它们的可变性可能会阻碍特征图蒸馏,因为变化会阻止参数方面的一致局部建模。
因此,我们推测向特征图蒸馏提供改进可以是基于辅助网络的自知识蒸馏的一个突破。因此,我们建议使用辅助自教师网络生成精细化的特征图以及其软标签。据我们所知,本文是第一篇关于使用自教师网络从单个实例中生成精细化特征图的工作。
我们建议的辅助自教师网络结构是从目标检测领域中使用的特征网络发展而来。特征聚合以不同尺度是处理多尺度特征的关键之一,目标检测领域已经研究了这种尺度变化[19,15,41,20,28]。我们的辅助自教师网络通过将处理多尺度特征的网络调整为知识蒸馏目的来生成精细化的特征图。虽然我们将在第3.1节解释这种结构的调整,但这一小节列举了特征网络的最新发展。FPN 利用自上而下的网络同时利用了1)来自上层的抽象信息和2)来自骨干网底层的小目标信息[19]。PANet 引入了额外的自下而上网络,用于为 FPN 提供一个短路径连接,使检测层与骨干网层之间产生连接[20]。BiFPN 提出了一种更高效的网络结构,与 PANet 一样使用了自上而下和自下而上的网络[28]。本文提出了一个辅助自教师网络,其结构改编自 BiFPN 结构以适应分类任务。此外,通过调整网络结构,特征图蒸馏变得更加高效,因为辅助自教师网络所需的计算量比 BiFPN 更少,根据特征图的深度变化而改变通道维度。
3.Method

Ti是自下而上的层,Pi是自上而下的层,Li是侧向卷积层
图2:我们提出的自知识蒸馏方法“Feature Refinement via Self-Knowledge Distillation(FRSKD)”的概述。
自上而下路径和自下而上路径聚合不同尺寸的特征,并将精炼的特征图提供给原始的分类器网络。
利用自教师网络的特征图,FRSKD对精炼的特征图和软标签进行蒸馏`。
本节介绍了特征细化自知识蒸馏(FRSKD)。图2显示了我们蒸馏方法的概述,在接下来的第3.1节中从自教师网络的角度进行了进一步讨论。然后,我们在第3.2节回顾了我们自知识蒸馏的训练过程。
符号表示:
令D={(x1,y1),(x2,y2)),…,(xN,yN))}为一组带标签的实例,其中N为其大小;
令Fi,j为第i个样本的分类器网络第j个块的特征图;
令cj为分类器网络第j个块的通道维度。
为了简化表示法,在本文的其余部分中我们将省略索引i。
3.1. 自教师网络
自教师网络的主要目的是为分类器网络提供一个精细化的特征图及其软标签。自教师网络的输入是分类器网络的特征图F1,...,Fn,假设有n个分类器网络的块。我们通过修改BiFPN的结构来建模自教师网络以适应分类任务。具体来说,我们借鉴了PANet和BiFPN的自上而下路径和自下而上路径[28,20]。在自上而下路径之前,我们使用以下的侧向卷积层:

Conv表示一个输出维度为di的卷积操作。与现有的侧向卷积层不同,其di维度在网络设置时是固定的,我们设计di取决于特征图的通道维度ci。我们将di设置为di=w×ci,其中w是一个通道宽度参数。对于分类任务,自然而然地要为更深层设置更高的通道维度。因此,我们调整每一层的通道维度以包含其特征图深度的信息。此外,这种设计减少了侧向层的计算量。
思考: 侧向卷积层是来调整通道维度的? 分类任务,要为更深层设置更高的通道维度。要调整每一层的通道维度让它包含其特征图深度的信息。
自上而下路径和自下而上路径聚合不同的特征如下:
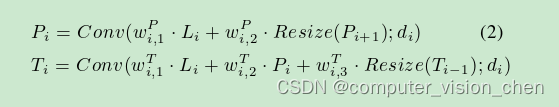
Pi表示自上而下路径的第i层;Ti表示自下而上路径的第i层。与BiFPN[28]类似,正向传播连接的结构取决于层的深度。
在图2中,在最浅的自下而上路径层T1和最深的自下而上路径层T4的情况下,分别为了效率,每个层直接利用了相应的侧向层L1和L4作为输入,而不是使用自上而下路径的特征。
在这些设置中,为了创建连接所有最浅层、中间层和最深层的自上而下结构,添加了两个正向传播的对角连接:
1)从最后的侧向层L4到自上而下路径的倒数第二层P3的连接;
2)从P2到自下而上路径的第一层T1的连接。我们采用快速归一化融合(如wP和wT等参数)[28]。
我们使用双线性插值进行上采样,使用最大池化进行下采样,作为调整大小的运算符。
为了进行高效计算,我们使用深度卷积进行卷积操作[11]。我们进行了各种实验,并根据第4.3节中的自教师网络结构来分析结果。
最后,我们在自下而上路径的顶部添加了全连接层来预测输出类别,而自教师网络提供其软标签,表示为

其中ft表示自教师网络,由参数θt参数化。
3.2 自特征蒸馏
我们提出的模型 FRSKD 利用自教师网络的输出,即精炼的特征图 Ti 和软标签 pˆt。首先,我们引入特征蒸馏,使得分类器网络模仿精炼的特征图。对于特征蒸馏,我们采用了注意力传递方法[37]。方程 3 定义了特征蒸馏损失 LF:

其中 φ 是通道-wise 池化函数与 L2 正则化的组合[37],θc 是分类器网络的参数。φ 提取了特征图的空间信息。因此,LF 使分类器网络学习从自教师网络中提炼的特征图的局部性。此外,可以训练分类器网络精确地模仿精炼的特征图[26,8],或者利用特征图的变换[34]。除非另有说明,本文采用基于注意力传递的特征蒸馏方法,我们将在第 4.3 节讨论特征蒸馏的方法论。与其他自知识蒸馏方法类似,FRSKD 也通过软标签 pˆt 进行蒸馏,具体如下:

其中 fc 是分类器网络,K 是温度缩放参数。此外,分类器网络和自教师网络使用交叉熵损失 LCE 学习地面真实标签。通过整合上述损失函数,我们构建以下优化目标:
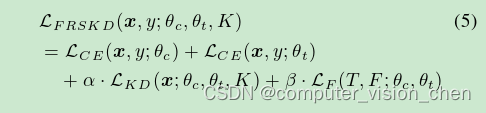
其中 α 和 β 是超参数,我们选择 α ∈ [1, 2, 3] 和 β ∈ [100, 200];详细信息请参见附录中的敏感性分析。优化是通过同时对分类器和自教师网络进行反向传播来启动的。为了防止模型崩溃问题[22],FRSKD 通过仅应用于学生网络的蒸馏损失 LKD 和 LF 来更新参数。
4.Experiments
实现细节:我们对CIFAR-100和TinyImageNet使用了ResNet18和WRN-16-2[7,38]。为了适应小型数据集,我们修改了ResNet18的第一个卷积层,将其设置为3×3的卷积核大小,单个步幅和单个填充。我们也删除了最大池化操作。对于FGVR任务,我们使用标准的ResNet18;并且我们将ResNet18和ResNet34应用于ImageNet。对于所有分类实验,我们使用随机梯度下降(SGD)作为优化器,初始学习率为0.1,权重衰减为0.0001。我们将总的训练周期设置为200,在CIFAR-100、TinyImageNet和FGVR上在第100和第150个周期将学习率除以10。对于ImageNet,我们将总的训练周期设置为90,在第30和第60个周期将学习率除以10。我们将批量大小设置为CIFAR-100和TinyImageNet为128;FGVR为32;ImageNet为256。对于所有实验,我们使用标准的数据增强方法,即随机裁剪和翻转。关于超参数,我们为CIFAR-100将α设置为2,β设置为100;对于TinyImageNet,将α设置为3,β设置为100;对于FGVR和ImageNet,将α设置为1,β设置为200。此外,我们将温度缩放参数K设置为4,并将通道宽度参数w设置为2。更多细节请参阅附录的“实现细节”。
结论
本文提出了一种具有自上而下和自下而上路径的自知提炼专用神经网络结构,这些路径的增加有望为分类器网络提供精炼的特征图及其软标签。 最后,FRSKD 能够将自我知识提炼应用于分类和语义分割等视觉任务。我们从定量上证实了性能的大幅提升,并通过各种相关研究展示了工作机制的效率。
总结:
本文方法是引入了一个辅助的自教师网络,以使精炼的知识传递给分类器网络。可以用利用软标签和特征图蒸馏进行自知识蒸馏。本文名字为 通过自知识蒸馏进行特征细化”(FRSKD)
自知识蒸馏主要分为基于数据增强和基于辅助网络两种方法。基于辅助网络的方法则利用分类器网络中间的额外分支,并通过知识传递诱导这些额外分支产生类似的输出[44,40]。
使用辅助自教师网络生成精细化的特征图以及其软标签
我们的辅助自教师网络通过将处理多尺度特征的网络调整为知识蒸馏目的来生成精细化的特征图。
本文提出了一个辅助自教师网络,其结构改编自 BiFPN 结构以适应分类任务。此外,通过调整网络结构,特征图蒸馏变得更加高效,因为辅助自教师网络所需的计算量比 BiFPN 更少,根据特征图的深度变化而改变通道维度。
文中的部分参考文献
原文 releated work中的:
The in-termediate layer distillation methods were then introduced,so such methods utilize the teacher network’s knowledgefrom either the convolutional layer with feature-map levelpreserving localities[26,37,14,34,16];or penultimate layer[24,29,21,23,30].
翻译成中文为:随后引入了中间层蒸馏方法,这些方法利用教师网络的知识,要么是来自具有特征图级别局部性的卷积层[26,37,14,34,16],要么是来自倒数第二层[24,29,21,23,30]。
这一堆参考文献的引用如下:
[26,37,14,34,16]
[26] Adriana Romero,Nicolas Ballas,Samira Ebrahimi Kahou,Antoine Chassang,Carlo Gatta,and Yoshua Bengio.Fitnets:Hints for thin deep nets.arXiv preprint arXiv:1412.6550,2014.
@misc{romero2015fitnets,
title={FitNets: Hints for Thin Deep Nets},
author={Adriana Romero and Nicolas Ballas and Samira Ebrahimi Kahou and Antoine Chassang and Carlo Gatta and Yoshua Bengio},
year={2015},
eprint={1412.6550},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
[37]Sergey Zagoruyko and Nikos Komodakis.Paying more at-tention to attention:Improving the performance of convolu-tional neural networks via attention transfer.arXiv preprintarXiv:1612.03928,2016.
@misc{zagoruyko2017paying,
title={Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer},
author={Sergey Zagoruyko and Nikos Komodakis},
year={2017},
eprint={1612.03928},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
[14]Jangho Kim,SeongUk Park,and Nojun Kwak.Paraphrasingcomplex network:Network compression via factor transfer.In Advances in neural information processing systems,pages2760–2769,2018.
@misc{kim2020paraphrasing,
title={Paraphrasing Complex Network: Network Compression via Factor Transfer},
author={Jangho Kim and SeongUk Park and Nojun Kwak},
year={2020},
eprint={1802.04977},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
[34]Junho Yim,Donggyu Joo,Jihoon Bae,and Junmo Kim.Agift from knowledge distillation:Fast optimization,networkminimization and transfer learning.In The IEEE Conferenceon Computer Vision and Pattern Recognition(CVPR),July2017
@INPROCEEDINGS{8100237,
author={Yim, Junho and Joo, Donggyu and Bae, Jihoon and Kim, Junmo},
booktitle={2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
title={A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning},
year={2017},
volume={},
number={},
pages={7130-7138},
doi={10.1109/CVPR.2017.754}}
[16]Animesh Koratana,Daniel Kang,Peter Bailis,and Matei Za-haria.Lit:Learned intermediate representation training formodel compression.In International Conference on Ma-chine Learning,pages 3509–3518,2019.
@InProceedings{pmlr-v97-koratana19a,
title = {{LIT}: Learned Intermediate Representation Training for Model Compression},
author = {Koratana, Animesh and Kang, Daniel and Bailis, Peter and Zaharia, Matei},
booktitle = {Proceedings of the 36th International Conference on Machine Learning},
pages = {3509--3518},
year = {2019},
editor = {Chaudhuri, Kamalika and Salakhutdinov, Ruslan},
volume = {97},
series = {Proceedings of Machine Learning Research},
month = {09--15 Jun},
publisher = {PMLR},
pdf = {http://proceedings.mlr.press/v97/koratana19a/koratana19a.pdf},
url = {https://proceedings.mlr.press/v97/koratana19a.html},
abstract = {Researchers have proposed a range of model compression techniques to reduce the computational and memory footprint of deep neural networks (DNNs). In this work, we introduce Learned Intermediate representation Training (LIT), a novel model compression technique that outperforms a range of recent model compression techniques by leveraging the highly repetitive structure of modern DNNs (e.g., ResNet). LIT uses a teacher DNN to train a student DNN of reduced depth by leveraging two key ideas: 1) LIT directly compares intermediate representations of the teacher and student model and 2) LIT uses the intermediate representation from the teacher model’s previous block as input to the current student block during training, improving stability of intermediate representations in the student network. We show that LIT can substantially reduce network size without loss in accuracy on a range of DNN architectures and datasets. For example, LIT can compress ResNet on CIFAR10 by 3.4$\times$ outperforming network slimming and FitNets. Furthermore, LIT can compress, by depth, ResNeXt 5.5$\times$ on CIFAR10 (image classification), VDCNN by 1.7$\times$ on Amazon Reviews (sentiment analysis), and StarGAN by 1.8$\times$ on CelebA (style transfer, i.e., GANs).}
}
[24,29,21,23,30]
[24]Baoyun Peng,Xiao Jin,Jiaheng Liu,Dongsheng Li,YichaoWu,Yu Liu,Shunfeng Zhou,and Zhaoning Zhang.Correla-tion congruence for knowledge distillation.In Proceedingsof the IEEE International Conference on Computer Vision,pages 5007–5016,2019
@misc{peng2019correlation,
title={Correlation Congruence for Knowledge Distillation},
author={Baoyun Peng and Xiao Jin and Jiaheng Liu and Shunfeng Zhou and Yichao Wu and Yu Liu and Dongsheng Li and Zhaoning Zhang},
year={2019},
eprint={1904.01802},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
[29]Yonglong Tian,Dilip Krishnan,and Phillip Isola.Contrastive representation distillation.arXiv preprintarXiv:1910.10699,2019.
@misc{tian2022contrastive,
title={Contrastive Representation Distillation},
author={Yonglong Tian and Dilip Krishnan and Phillip Isola},
year={2022},
eprint={1910.10699},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
[21]Yufan Liu,Jiajiong Cao,Bing Li,Chunfeng Yuan,Weim-ing Hu,Yangxi Li,and Yunqiang Duan.Knowledge distil-lation via instance relationship graph.In Proceedings of theIEEE Conference on Computer Vision and Pattern Recogni-tion,pages 7096–7104,2019.
@InProceedings{Liu_2019_CVPR,
author = {Liu, Yufan and Cao, Jiajiong and Li, Bing and Yuan, Chunfeng and Hu, Weiming and Li, Yangxi and Duan, Yunqiang},
title = {Knowledge Distillation via Instance Relationship Graph},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2019}
}
[23]Wonpyo Park,Dongju Kim,Yan Lu,and Minsu Cho.Rela-tional knowledge distillation.In Proceedings of the IEEEConference on Computer Vision and Pattern Recognition,pages 3967–3976,2019.
@InProceedings{Park_2019_CVPR,
author = {Park, Wonpyo and Kim, Dongju and Lu, Yan and Cho, Minsu},
title = {Relational Knowledge Distillation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2019}
}
[30]Frederick Tung and Greg Mori.Similarity-preserving knowl-edge distillation.In Proceedings of the IEEE InternationalConference on Computer Vision,pages 1365–1374,2019.
@misc{tung2019similaritypreserving,
title={Similarity-Preserving Knowledge Distillation},
author={Frederick Tung and Greg Mori},
year={2019},
eprint={1907.09682},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
补充
什么是特征图?
特征图是卷积神经网络(CNN)中卷积层的输出。它们是二维数组,包含卷积滤波器从输入图像或信号中提取的特征。
训练流程分析
第一轮训练时:
1.图片输入到学生网络的F1网络,得到F1特征图。
2.F1特征图输入到L1得到L1特征图。
3.L1特征图输入到T1,此时自上而下还没有开始,此时只向T1输入了L1特征图,没有自上而下融合的特征。 得到T1特征图后,返回到F1网络,对T1特征图进行计算,传到F2。
3.同上。
第二轮以后每个层都有特征图,此时就有自上而下融合的特征了。
















 264
264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











