







前面已经简单介绍了LeNet网络,同时用Pytorch框架搭建LeNet-5网络并在MNIST数据集进行了简单训练。LeNet-5于1994年提出,从提出到2012年长达近20年时间在计算机视觉领域具有一定的影响力,但神经网络一直被其他机器学习方法超越,并未处于领导地位。当时限制神经网络发展的因素大概有三个,一是硬件不足以支持大量参数的深层多通道卷积神经网络;二是数据集相对较小;三是缺少训练神经网络的一些关键技巧。
本文将对AlexNet网络结构做简单介绍,同时用Pytorch框架搭建该网络并在Fashion-Mnist数据集上训练。
1.AlexNet简介
2012年,Alex Krizhevsky等人提出的AlexNet网络在ImageNet大赛中取得了很好的成绩,这是深度卷积神经网络的突破。该突破主要得益于两方面的因素:一是ImageNet数据集非常大,有100万个样本;二是应用GPU训练神经网络,打破了卷积神经网络中的计算瓶颈(卷积和矩阵乘法的计算)。
1.1网络结构
2012年,Alex Krizhevsky等人提出的AlexNet网络在ImageNet大赛中取得了很好的成绩,这是深度卷积神经网络的突破。
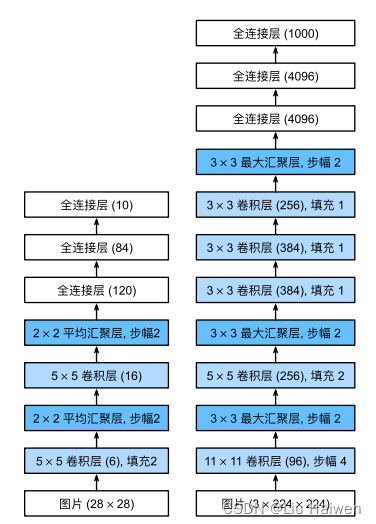
左边是LeNet,右边是AlexNet.。AlexNet与LeNet在结构非常类似,但也存在一点差异,一是AlexNet比LeNet要深,多了两个卷积层,二是激活函数使用ReLu函数而非Sigmoid函数。
1.2网络实现
本文暂不使用ImageNet数据集,依然使用MNIST数据集,MNIST数据集每张图片是(1,28,28),一共有10类图片,因此要对网络的输入输出层稍作修改即可(输入层的通道数,输出层的神经元个数,图像大小在加载数据时会处理为[1,244,244],这里不涉及)。
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
#input(1,244,244)
self.conv1=nn.Conv2d(1,96,kernel_size=11,stride=4)#(1,244,244)-->(96,59,59)
self.pool1=nn.MaxPool2d(kernel_size=3,stride=2)#(96,59,59)-->(96,29,29)
self.conv2=nn.Conv2d(96,256,kernel_size=5,padding=2)#(96,29,29)-->(256,29,29)
self.pool2=nn.MaxPool2d(kernel_size=3,stride=2)#(256,29,29)-->(256,14,14)
self.conv3=nn.Conv2d(256,384,kernel_size=3,padding=1)#(256,14,14)-->(384,14,14)
self.conv4 = nn.Conv2d(384, 384, kernel_size=3, padding=1) # (384,14,14)-->(384,14,14)
self.conv5 = nn.Conv2d(384, 256, kernel_size=3, padding=1) # (384,14,14)-->(256,14,14)
self.pool3=nn.MaxPool2d(kernel_size=3,stride=2)#(256,14,14)-->(256,6,6)
self.fc1=nn.Linear(256*6*6,4096)
self.fc2=nn.Linear(4096,4096)
self.fc3=nn.Linear(4096,10)
def forward(self,x):
x=self.pool1(torch.relu(self.conv1(x)))
x=self.pool2(torch.relu(self.conv2(x)))
x=self.pool3(torch.relu(self.conv5(self.conv4(self.conv3(x)))))
x=x.view(-1,256*6*6)
x=torch.relu(self.fc1(x))
x=torch.relu(self.fc2(x))
x=self.fc3(x)
return x
搭建好网络后,用一个[1,1,244,244]的tensor来验证一下:
net=AlexNet()
x=torch.randn(1,1,244,244)
Y=net(x)
print(Y.shape)
结果如下:
torch.Size([1, 10])
从输出张量的形状来看,网络没有问题,达到预期结果。
2.模型训练
2.1MNIST数据集
2.2数据迭代器
构建一个数据迭代器来加载训练数据和测试数据:
def load_data_fashion_mnist(batch_size):
transform=transforms.Compose([transforms.Resize((244,244)),transforms.ToTensor()])
mnist_train=torchvision.datasets.MNIST(root='data',train=True,transform=transform,download=True)
mnist_test=torchvision.datasets.MNIST(root='data',train=False,transform=transform,download=True)
return (data.DataLoader(mnist_train,batch_size,shuffle=True,num_workers=4),
data.DataLoader(mnist_test,batch_size,shuffle=True,num_workers=4))
加入了transforms.Resize((244,244))将图片分辨率修改为(244,244)
指定batch_size=100,输出如下:
torch.Size([100, 1, 244, 244])
2.3训练器
与上篇LeNet中一样,不做修改:
def train(net,train_iter,test_iter,num_epochs,lr):
def init(n):
if type(n)==nn.Conv2d or type(n)==nn.Linear:
nn.init.normal(n.weight.data)
net.apply(init)
optimizer =torch.optim.SGD(net.parameters(),lr=lr)
loss=nn.CrossEntropyLoss()
train_loss_list=[]
train_acc_list=[]
test_acc_list=[]
for i in range(num_epochs):
train_loss=0.0
train_acc=0.0
for j,(X,y) in enumerate(train_iter):
X=X.to(device)
y=y.to(device)
optimizer.zero_grad()
Y=net(X).to(device)
l=loss(Y,y)
l.backward()
optimizer.step()
train_loss+=l.item()
train_acc+=accuracy(Y,y)/X.shape[0]
if j%200==199:
a=train_loss/200.0
b=train_acc/200.0
train_loss_list.append(a)
train_acc_list.append(b)
train_loss=0.0
train_acc=0.0
with torch.no_grad():#在测试数据集上测试
for m,(X_test,y_test) in enumerate(train_iter):
X_test=X_test.to(device)
y_test=y_test.to(device)
output=net(X_test).to(device)
acc=accuracy(Y,y)/X.shape[0]
test_acc_list.append(acc)
print(f'train_loss:{a:.3f},train_acc:{b:.3f},test_acc:{acc:.3f}')
结果如下:
train_loss:nan,train_acc:0.098,test_acc:0.130
train_loss:nan,train_acc:0.099,test_acc:0.090
...
train_loss:nan,train_acc:0.098,test_acc:0.090
train_loss:nan,train_acc:0.098,test_acc:0.120
可以看到准确率和损失函数的值并没有过大的变化,损失函数的值nan,这说明学习过程异常,这个训练器在之前LeNet训练时没有问题,那么该异常是什么原因造成的?
查阅了一些资料,这种现象可能属于梯度消失/梯度爆炸,主要是权重初始化不恰当造成的。针对ReLu激活函数,Kaiming初始化方法能够有效缓解梯度消失和梯度爆炸:
nn.init.kaiming_normal_(n.weight.data)
train_loss:nan,train_acc:0.097,test_acc:0.090
train_loss:nan,train_acc:0.099,test_acc:0.120
...
train_loss:nan,train_acc:0.099,test_acc:0.120
train_loss:nan,train_acc:0.100,test_acc:0.060
结果问题依然没有解决!
最后把学习率减小了两个数量级,学习正常!
train_loss:0.566,train_acc:0.868,test_acc:0.970
train_loss:0.158,train_acc:0.956,test_acc:0.970
...
train_loss:0.043,train_acc:0.987,test_acc:0.990
train_loss:0.039,train_acc:0.988,test_acc:0.980
3.总结
本文首先介绍了AlexNet网络,比较了与LeNet的不同,然后用Pytorch搭建了该网络,但在MNIST数据集上训练时出现了异常,可能是梯度消失/梯度爆炸造成的,尝试了一些解决方案但并未成功,最后通过减小学习率成功解决问题。当然,解决梯度消失/爆炸的方法还有很多,后面再详细介绍。















 5003
5003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









