






一、文章背景
论文的意义:HR-MSI与LR-HSI融合的数据集获取困难,文章构建了无监督多注意力引导网络和无监督轻量注意力环形网络来融合MSI和HSI。
核心:通过深度学习的方法生成HR-HSI(HSI超分辨率重建)。
二、文章成果与重点
- 以随机编码和HR-MSI为输入,反复迭代学习先验,便可获得HR-HSI。
- 采用多注意力模块,NL模块可以更好的保留图像的光谱细节和空间细节,协调注意力模块可以抑制冗余信息。
- 采用轻化注意力块。
- 采用了无监督图像融合模型。
三、网络细节
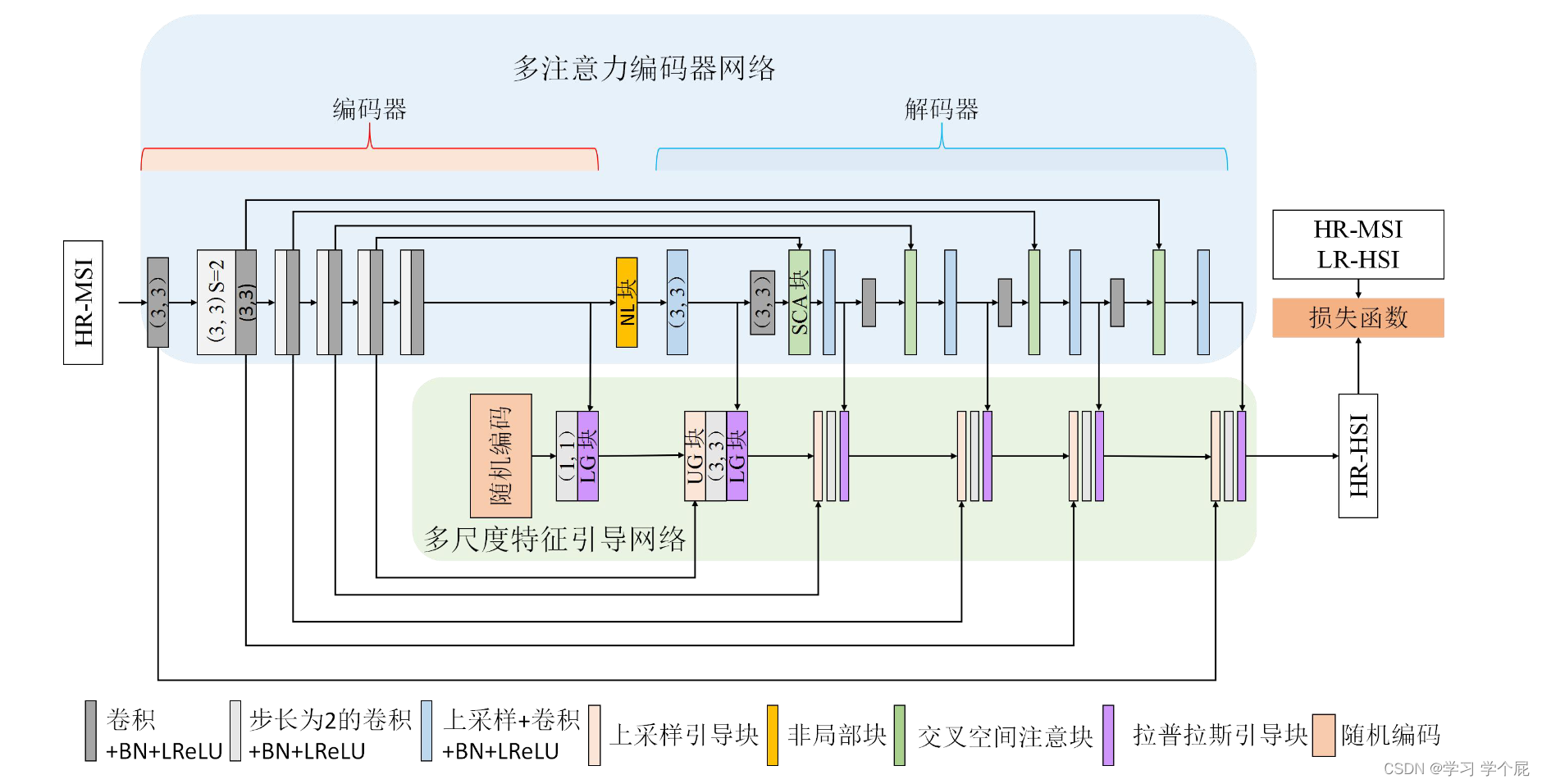
(一)无监督多注意力引导网络
融合算法框架(与GDD相似,后文会提到):
1.理论
a.深度图像先验(Deep Image Prior,DIP)理论
在Deep Image Prior论文中提出,神经网络本身就可以捕获低层级的图像先验知识,反复迭代学习一张图的先验知识实现图像去噪和图像超分辨率等任务。原论文提出的常规图像修复公式如下:
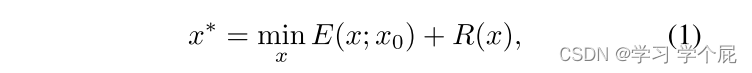
x*为网络输出,x0为网络的输入,R(x)为正则项
而采用深度卷积网络的图像修复公式如下:
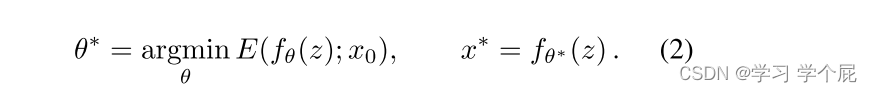
f就是神经网络,θ为网络参数(随机初始化得到),z是最初输入网络的一个固定的随机的编码。
对于图像修复、超分辨率等工作,可以理解为神经网络先学习的是低频的信息,而噪声则是高频信息。
b.Double-DIP 算法
在Double-DIP论文中提出,采用两个DIP,可以将复杂的图像分为两个内部相似性高的图层,从而使其适用于各类任务。
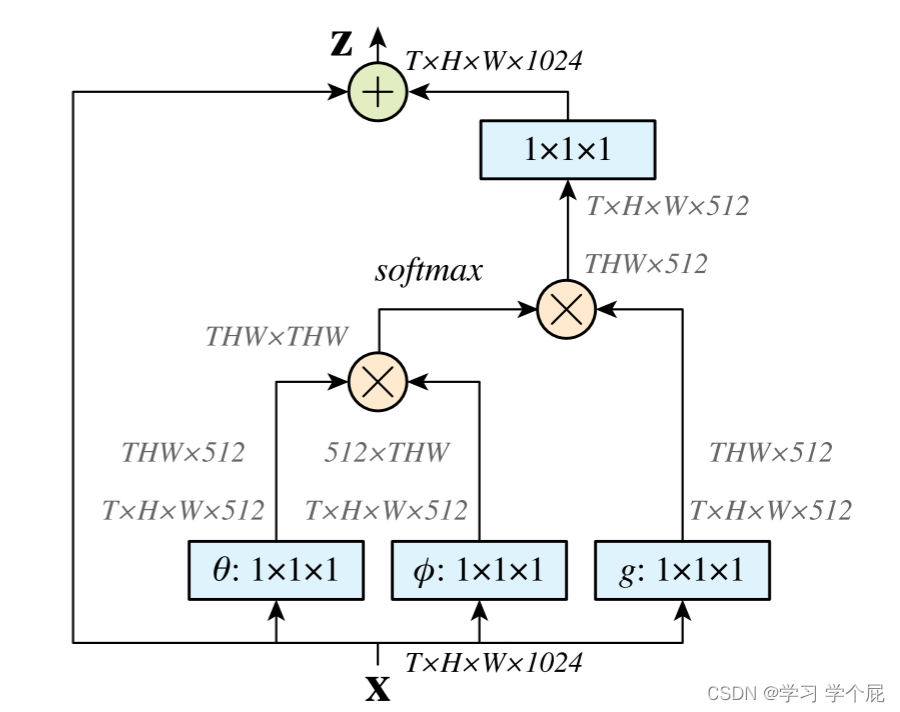
c.非局部注意力机制
Non-Local Network相当于transformer的self attention部分,不做赘述,是一个即插即用的模块。
文章采用NL块的原因是因为不同于其他端到端的网络,编码器的特征也会进入引导网络,
2.多注意力编码器网络 (MAE)
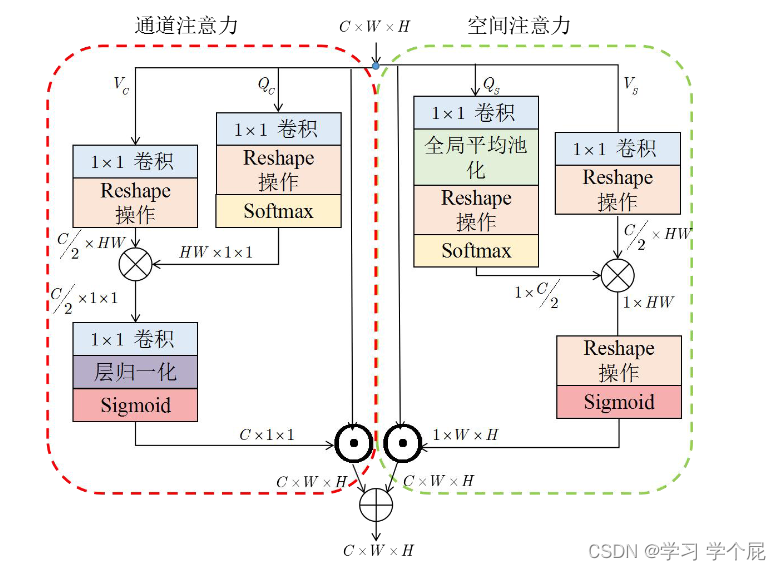
加入了非局部模块(Non-local,NL)模块和交叉空间注意力模块(Spatial Cross Attention,SCA)融合相同尺度的特征
SCA模块
其中红框内是空间注意(Spatial Attention,SA)块,虽然空间注意块能够在有效地减少对输入图像中不相关区域的关注度的同时聚焦相关区域的有效特征,但其产生结果可能包含噪声。因此,本章采用交叉空间注意块进 行图像的特征增强。
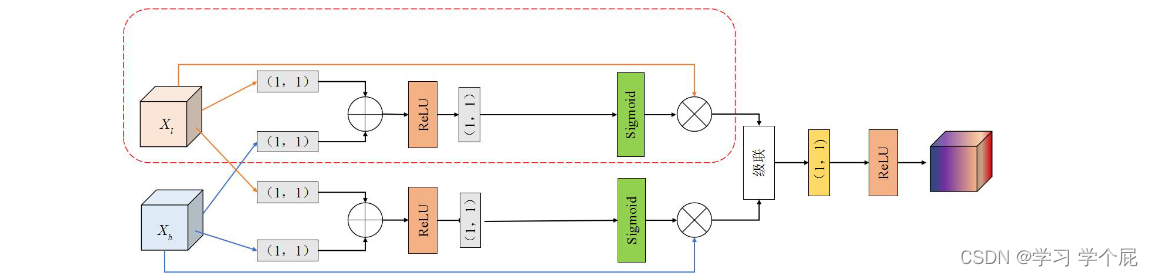
3.多尺度特征引导(MSFG)
a.上采样细化单元(URU)
为了避免图像边缘过于平滑,细节消失,不采用双线性插值模块

b.拉普拉斯引导块(LG)
采用拉普拉斯引导块可以使得在提取多尺度特征时保证输入特征与MSI特征对齐
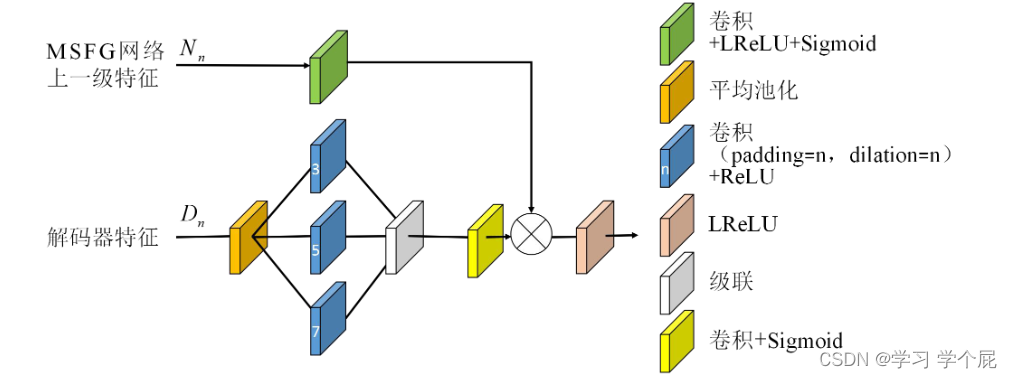
(二)无监督轻量注意力环形网络
网络由协调特征融合(Coordinate Feature Fusion,CFF)网络(绿色方框内)和双注意力解码(Dual-attention Decoder,DAD)网络(红色方框)组成。
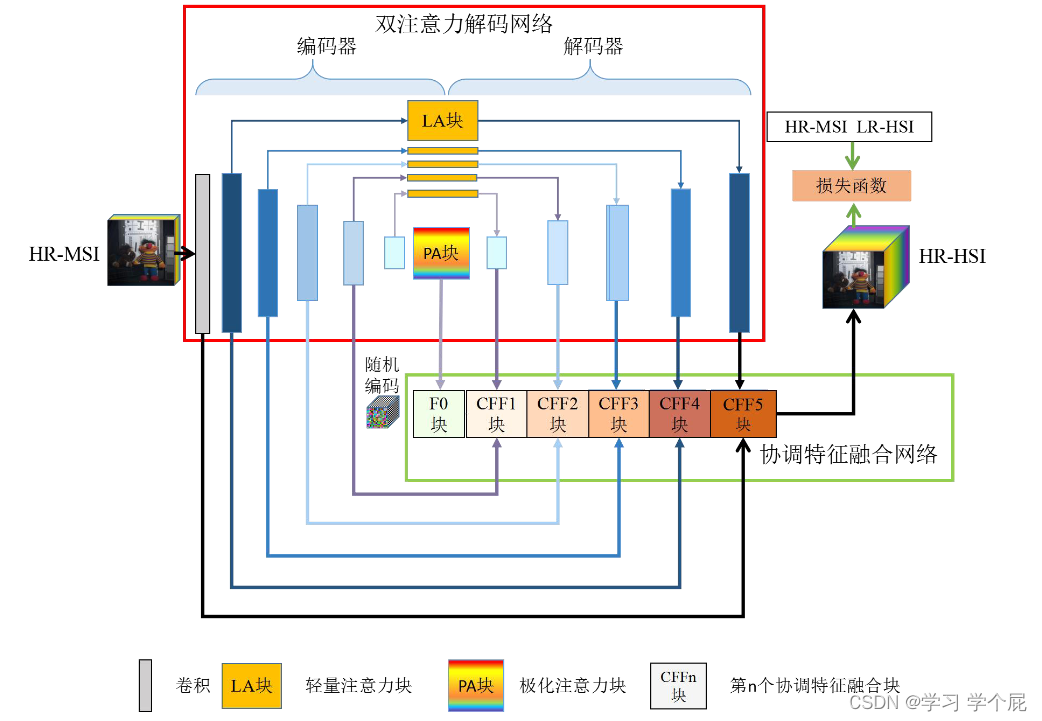
1.双注意力解码网络(DAD)
旨在提取多光谱图像的多尺度特征,增大信息量,为后续协调特征融合做准备
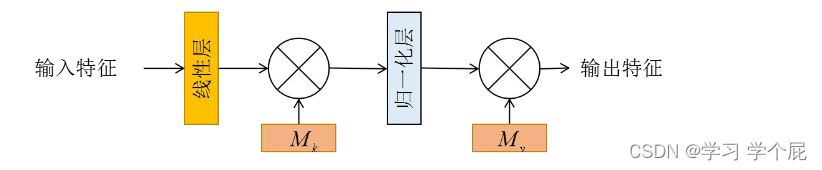
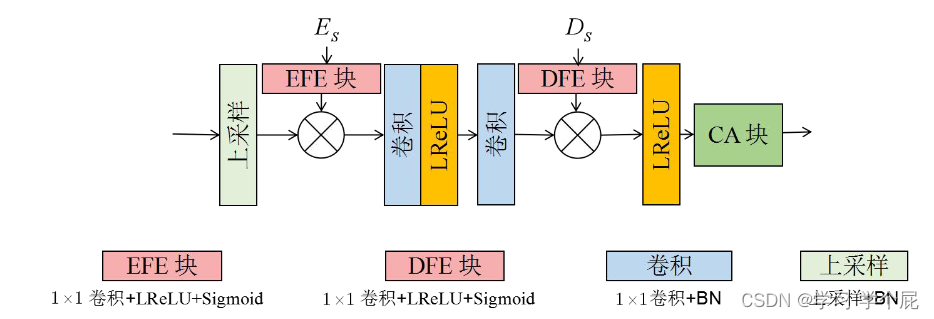
a.轻量注意力(Lightweight Attention, LA)块
采用EA文章中类似的模块,其中Mk是一个输入特征的可学习相关性参数
b.极化注意力(Polarize Attention,PA)块
采用Dual Attention Network中类似的结构,自适应地整合局部特征和全局依赖。该方法能够自适应地聚合长期上下文信息。
2.协调特征融合网络
采用类似GDD的网络,输入随机噪声生成HR-HSI
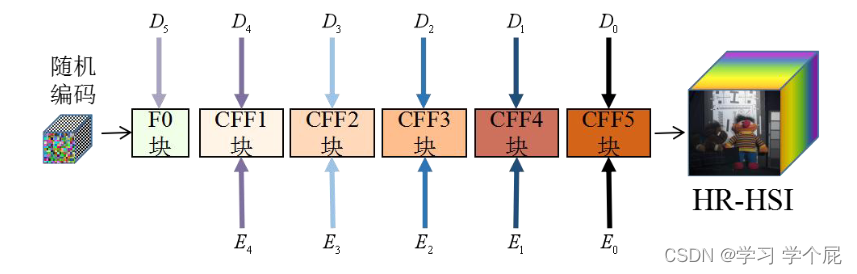
F0部分如下图所示,输入为随机噪声,进行初始化

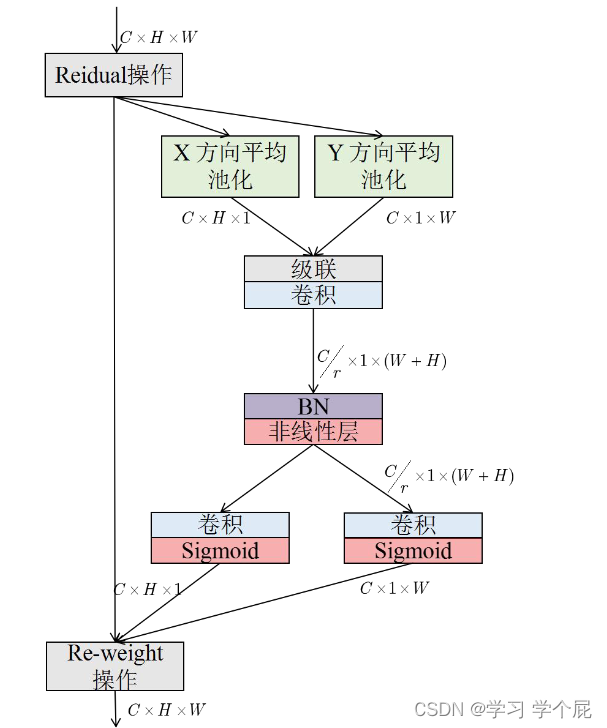
其中协调注意力(CA)模块兼顾通道和特征对图像进行增强,可以嵌入位置信息
其余的CFF模块为双输入模块
接下来介绍一下GDD
Guided Deep Decoder: Unsupervised Image Pair Fusion
一、文章背景
图像融合任务采用深度学习的方法避免了显示的先验知识,但是仍需要大量的训练数据,而高光谱图像较难获取,DIP的提出网络架构本身就有归纳偏差,但是采用DIP的不确定性,限制了DIP在各种图像融合问题中实现SOTA。
二、文章成果与重点
- 提出了一种新的无监督方法,不需要训练数据,可以适应不同的图像融合任务在一个统一的框架。
- 提出了一个新的网络架构解决一个正则化的无监督图像融合问题。在所提出的架构中使用的注意力门引导使用来自引导图像的多尺度语义特征来生成输出图像。
三、网络细节
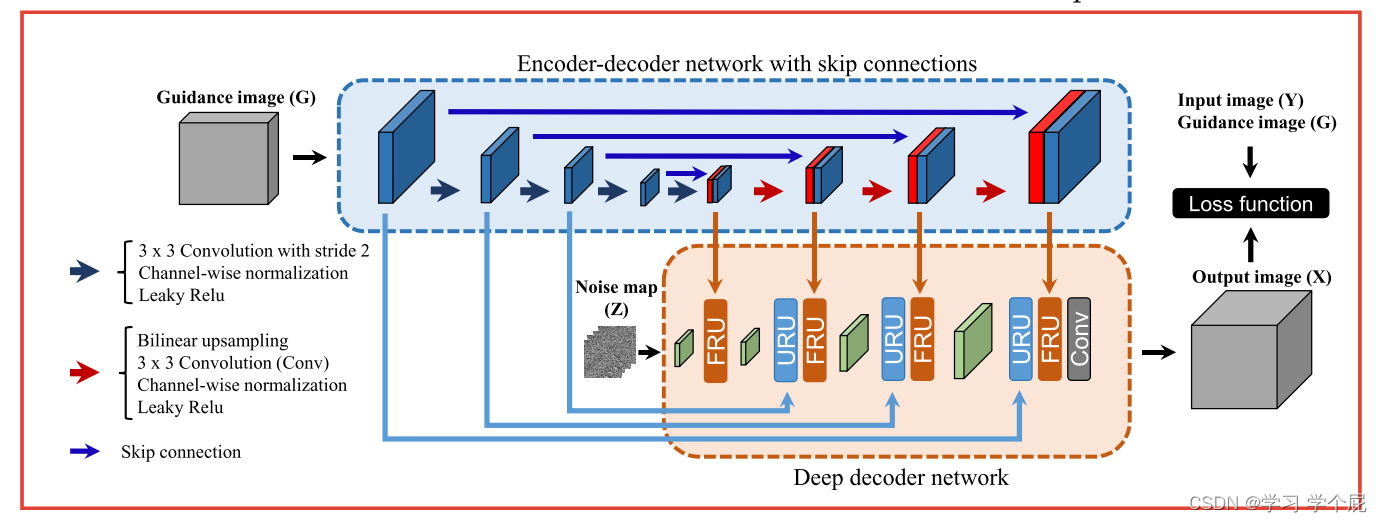
网络结构由如下,蓝色层代表编码器的功能。红色层代表解码器的功能。绿色层表示深度解码器网络的特征。G的语义特征用于在上采样和特征细化单元(URU和FRU)中指导深度解码器的特征。
要输出理想的图像X,可以被视为解决如下优化问题
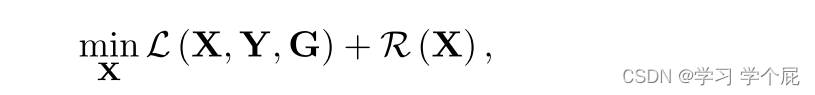
在DIP理论中

因此,问题可被简化如下,在该公式中,仅一个输入图像Y和引导图像G用于优化问题;因此,不需要训练数据。通过网络结构的隐式先验对X进行正则化。不同类型的架构可以导致不同的正则化器。文章提出的架构有效地结合了多尺度的空间细节和语义特征,可以是一个强大的正则化器。
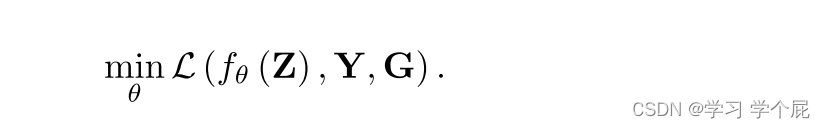
Guided deep decoder (GDD)
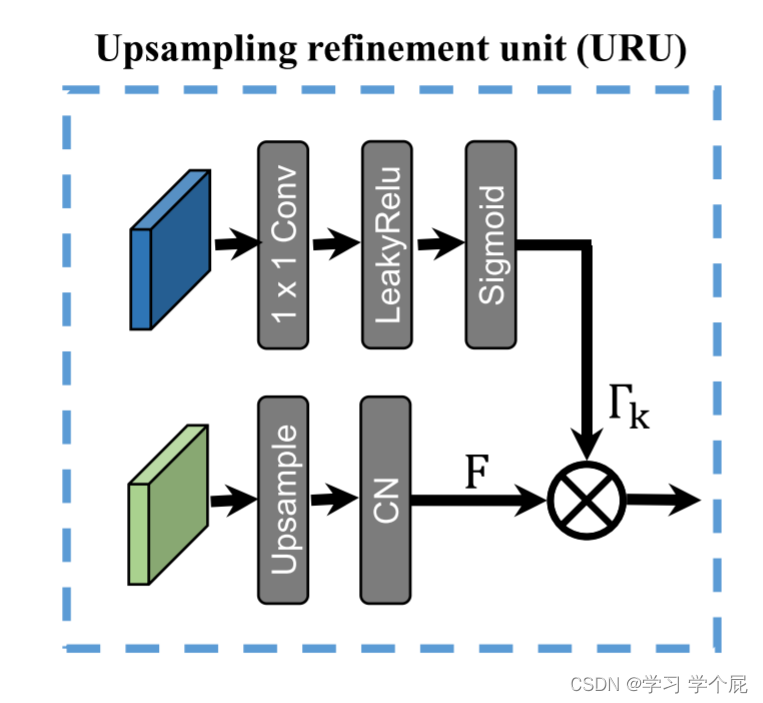
a. 上采样细化单元(URU)
在前文中提到,网络会先学习低频特征,这也就会导致在Decoder的过程中高频细节丢失。采用线性插值等方法,会使得边缘过于平滑,无法恢复精确空间结构或边界。
URU结合了一个注意力门,用于对深度解码器中的上采样和通道归一化(CN)后导出的特征进行加权。来自引导图像的特征通过1 × 1卷积、LeakyRelu、Sigmoid进行门控,生成条件权重以保持特征的空间局部性。
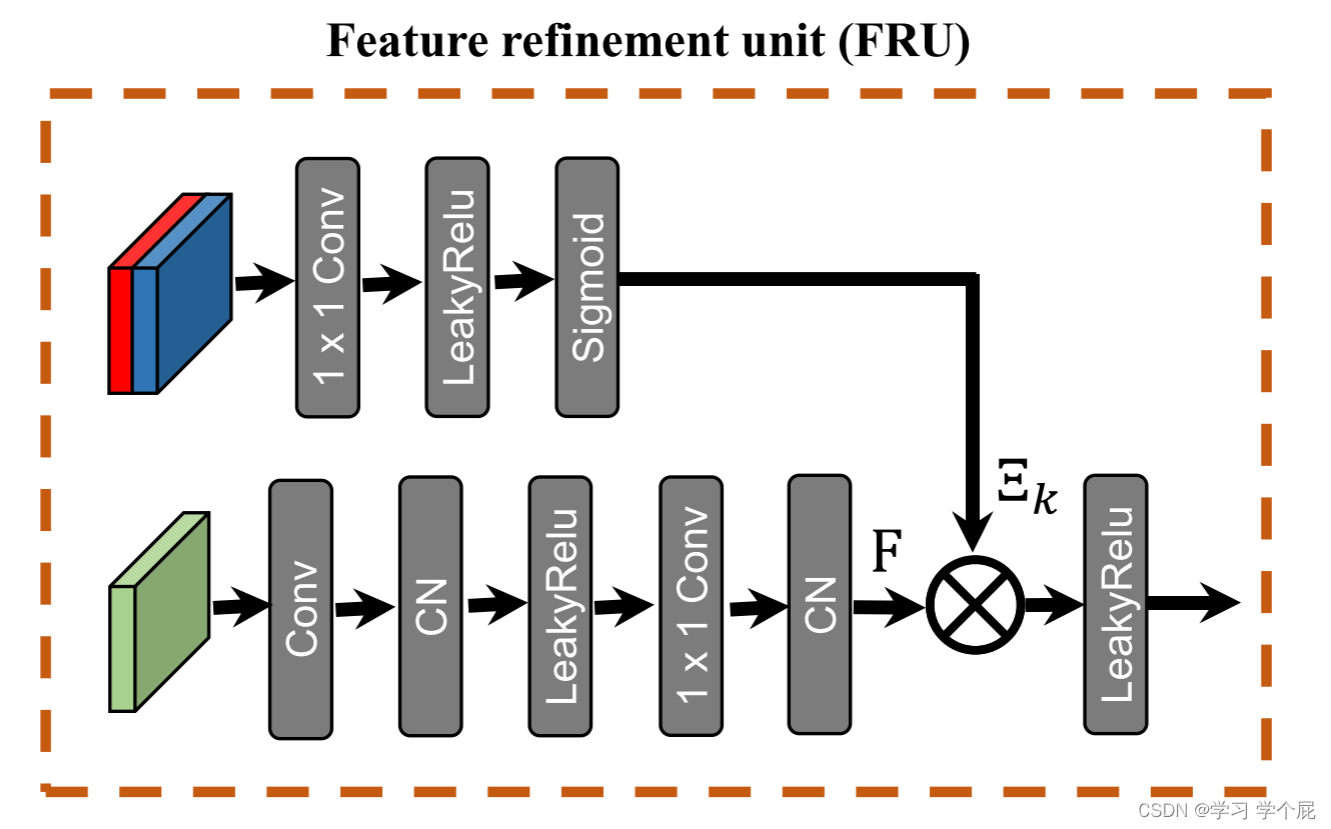
b. 特征细化单元(FRU)
同样通过Sigmoid门控,但与URU不同,FRU所要做的是语义对齐
四、损失函数
当融合RGB和HS图像时,损失函数通常被设计为保留HS图像的光谱信息,同时保留RGB图像的空间信息
损失函数公式如下,其中X tilde 代表代表高分辨率的高光谱图像,Y tilde 代表低分辨率的高光谱图像,G tilde 代表高分辨率的RGB图像,S是空间下采样,R是将光谱整合到R、G、B通道中的光谱响应函数。第一项代表空间下采样的X和Y之间的光谱相似性。第二项代表频谱下采样的X和G之间的空间相似性。μ是控制两项之间平衡的标量。
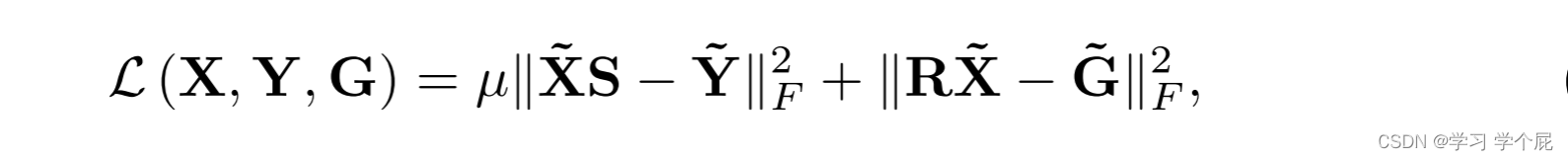

















 1028
1028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









