







Hyperspectral Image Super-Resolution via Deep Spatiospectral Attention Convolutional Neural Networks
简介
-
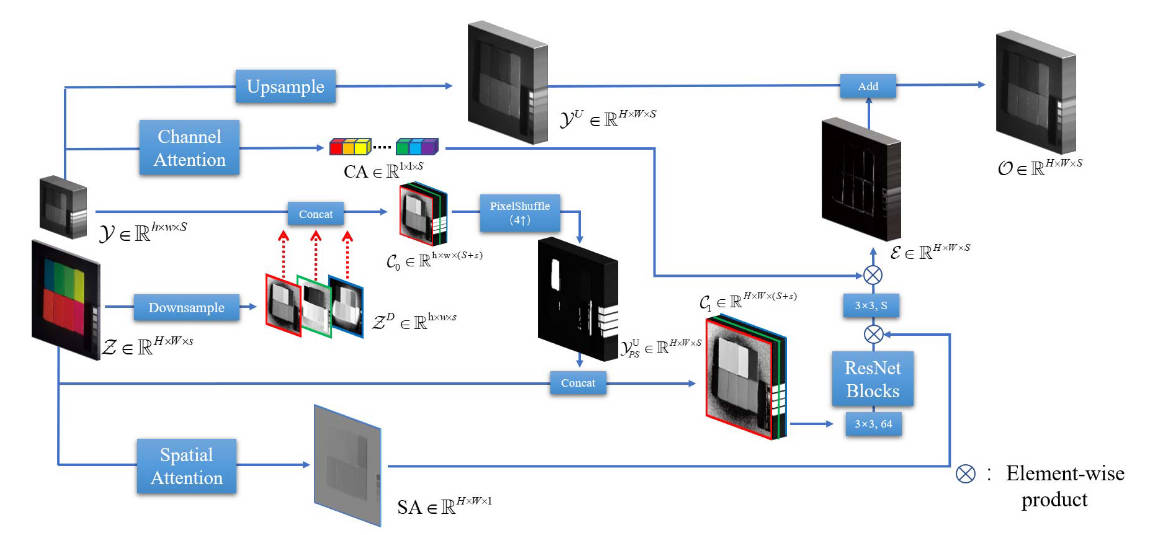
对于高分辨率多光谱(高分辨率意味空间信息更好)图像,采用spatial attention机制进行空间信息的保留,对于低分辨率高光谱(多频段也就是多channel)图像,采用channel attention对于通道数(频段数)进行通道信息保留。
-
引入PixelShuffle模块进行上采样操作
-
在concat阶段,对MS和HS进行交叉concat,使得信息融合更好
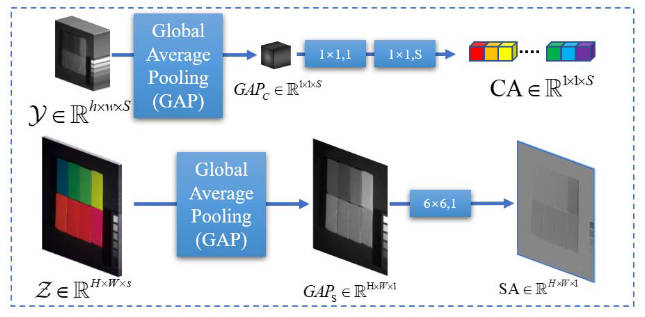
注意力module
首先对图像进行全局池化,输出一个特定维度的tensor,然后通过卷积进行相关操作用于计算注意力信息。
self.CA = nn.Sequential(
nn.Conv2d(num_spectral, 1, kernel_size=1, stride=1),
nn.LeakyReLU(),
nn.Conv2d(1, num_spectral, kernel_size=1, stride=1),
nn.Sigmoid()
)
self.SA = nn.Sequential(
nn.Conv2d(1, 1, kernel_size=6, stride=1, padding='same'), # 输入通道由3改为1
nn.Sigmoid(),
)
gap_ms_c = ms_hp.mean(dim=(2, 3), keepdim=True) # 每个通道平均
CA = self.CA(gap_ms_c)
gap_RGB_s = rgb_hp.mean(dim=1, keepdim=True)
SA = self.SA(gap_RGB_s)
交叉concat
在对ms图像进行下采样后,使得其空间分辨率从大小和高光谱一致,再将高分辨率图像分别插入彩色三通道之间,使得concat更加充分。这一步相当于获取高光谱图像的光谱信息,之后采用pixelshuffle模块,对其进行channel维度转为空间分辨率的上采样操作,与多光谱原始图像再次进行concat,保留原始的空间分辨率信息。
temp1 = ms_hp[:, :15]
temp2 = ms_hp[:, 15:]
rgb_temp1 = rgb[:, 0].unsqueeze(1)
rgb_temp2 = rgb[:, 1].unsqueeze(1)
rgb_temp3 = rgb[:, 2].unsqueeze(1)
temp1 = rs[:, :15]
temp2 = rs[:, 15:]
rgb_temp1 = rgb_hp[:, 0].unsqueeze(1)
rgb_temp2 = rgb_hp[:, 1].unsqueeze(1)
rgb_temp3 = rgb_hp[:, 2].unsqueeze(1)
上采样模块PixelShuffle
将尺寸为 ( ∗ , C × r 2 , H , W ) (*, C × r^2, H, W) (∗, C × r2, H, W) 的tensor转为 ( ∗ , C , H × r , W × r ) (*, C, H × r, W × r) (∗, C, H × r, W × r), 其中r是缩放因子。具体流程可参考python numpy实现PixelShuffle及其逆变换
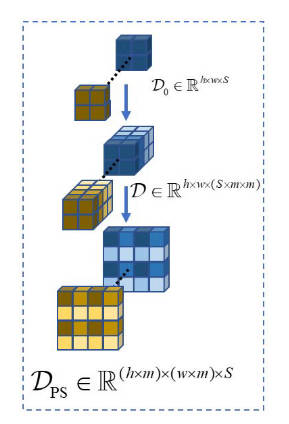
算法流程是:
- 将数组reshape成 ( r , r , n , n ) ( r , r, n , n ) (r,r,n,n)的形状
- 通过transpose将数组调整为$( r , 2 , r , 2 ) $的形式
- 再次通过reshape将数组调整为 ( 2 ∗ r , 2 ∗ r ) ( 2 ∗ r , 2 ∗ r) (2∗r,2∗r)的形状。
#pytorch实现代码
self.ps = nn.PixelShuffle(8)
class PixelShuffle(nn.Module):
def __init__(self, r):
super(PixelShuffle, self).__init__()
self.r = r
def forward(self, I):
bsize, c, w, h = I.size()
if c % (self.r * self.r) != 0:
raise ValueError('channel of tensor must be divisible by '
'(scale_factor * scale_factor).')
bsize = I.size(0)
X = I.reshape([bsize, c // (self.r * self.r), self.r, self.r, w, h])
X = X.permute(0, 1, 4, 2, 5, 3)
X = X.reshape(bsize, c // (self.r * self.r), self.r * w, self.r * h)
return X


















 657
657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











