







SARSA(State-Action-Reward-State-Action)和Q-learning是两种经典的强化学习算法,它们都用于学习最优策略以使智能体在一个环境中获得最大的累积奖励。它们之间的主要区别在于它们更新动作值函数(Q值函数)的方式以及其适用的情况。
- 更新方式:
- SARSA: 在SARSA算法中,Q值函数的更新是基于当前状态下采取的动作、接下来的状态、以及接下来采取的动作所获得的奖励。具体来说,SARSA使用的更新规则是:
![[ Q(s, a) \leftarrow Q(s, a) + \alpha \left[ r + \gamma Q(s', a') - Q(s, a) \right] ]](https://img-blog.csdnimg.cn/direct/ac08a8e2e14e42ccb58ba2f659eaefd6.png)
其中, s s s是当前状态, a a a 是当前采取的动作, r r r 是在采取动作 a a a 后获得的奖励, s ′ s' s′是接下来的状态, a ′ a' a′ 是在状态 s ′ s' s′ 下采取的下一个动作, α \alpha α 是学习率, γ \gamma γ是折扣因子。 - Q-learning: 在Q-learning算法中,Q值函数的更新是基于当前状态下采取的动作后可能获得的最大Q值。具体来说,Q-learning使用的更新规则是:
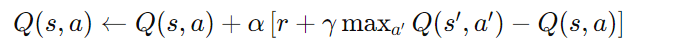
其中, s s s 是当前状态, a a a 是当前采取的动作, r r r 是在采取动作 a a a 后获得的奖励, s ′ s' s′是接下来的状态, α \alpha α是学习率, γ \gamma γ 是折扣因子。
- 适用情况:
- SARSA: SARSA是一个在线学习算法,它适用于需要连续地与环境进行交互的情况。由于它的更新是基于当前状态下采取的动作,因此它适用于实时决策的场景,比如机器人导航。
- Q-learning: Q-learning是一个离线学习算法,它适用于静态环境或者可以进行模拟的环境。由于它的更新是基于最大Q值的,因此它适用于离线学习和批处理更新的情况,比如从历史经验中学习。
总的来说,SARSA和Q-learning都是强化学习算法的经典代表,它们在更新方式和适用情况上有所不同,选择哪种算法取决于具体的问题和应用场景。
- 同策略与异策略:
SARSA 和 Q-learning 在更新策略时的一个重要区别在于它们是同策略(on-policy)和异策略(off-policy)学习算法。
1- SARSA是一个同策略学习算法:
-
在SARSA算法中,智能体使用的策略用于选择动作(即当前策略),同时也用于评估和更新动作值函数。具体来说,SARSA算法使用的是ε-贪婪策略或者柔性策略,以平衡探索和利用。
-
因为SARSA在更新Q值时使用的是当前策略选择的动作,所以它是一个同策略学习算法。
2- Q-learning是一个异策略学习算法:
- 在Q-learning算法中,智能体使用的策略用于选择动作(即当前策略),但在更新动作值函数时,它采用的是在状态 s s s下采取动作 a a a 后可能获得的最大Q值(即采取最大化动作值的动作),而不是采用当前策略选择的动作所导致的Q值。
- 因为Q-learning在更新Q值时使用的不是当前策略选择的动作,而是采取最大化动作值的动作,所以它是一个异策略学习算法。
异策略学习算法具有更广泛的适用性,因为它们可以从旧策略中学习,而不受新策略的影响。这使得Q-learning算法在某些情况下更加有效,尤其是当我们希望探索更多的动作空间时。但是,它们也更容易受到估计误差的影响,因为更新的目标是基于另一个策略的。与之相反,同策略学习算法更稳定,但可能会受到探索和利用之间的权衡的限制。
注:本文由chatgpt辅助撰写















 1167
1167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











