






import requests
from bs4 import BeautifulSoup
import re
import time
from random import choice
# 创建headers字段
def createUA():
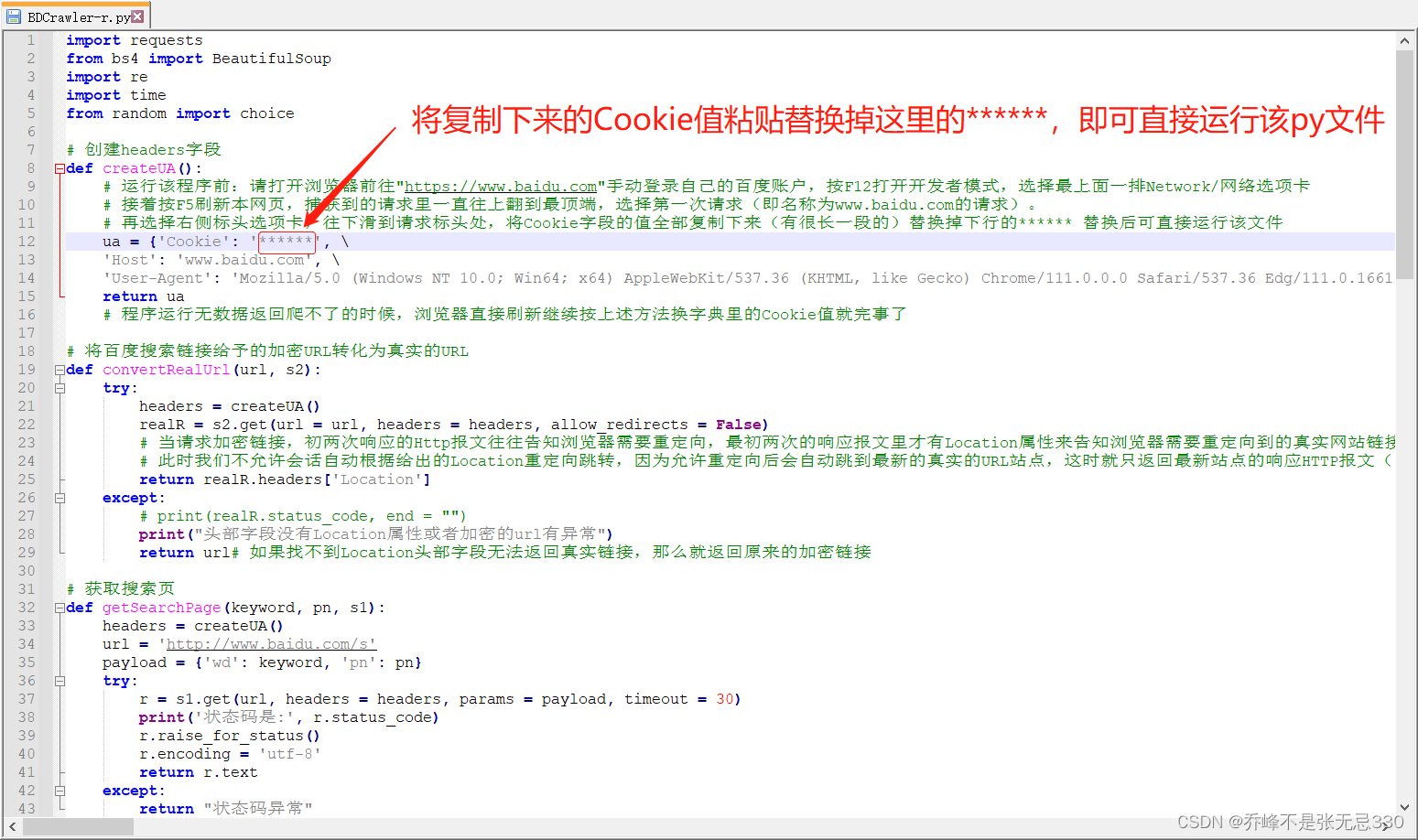
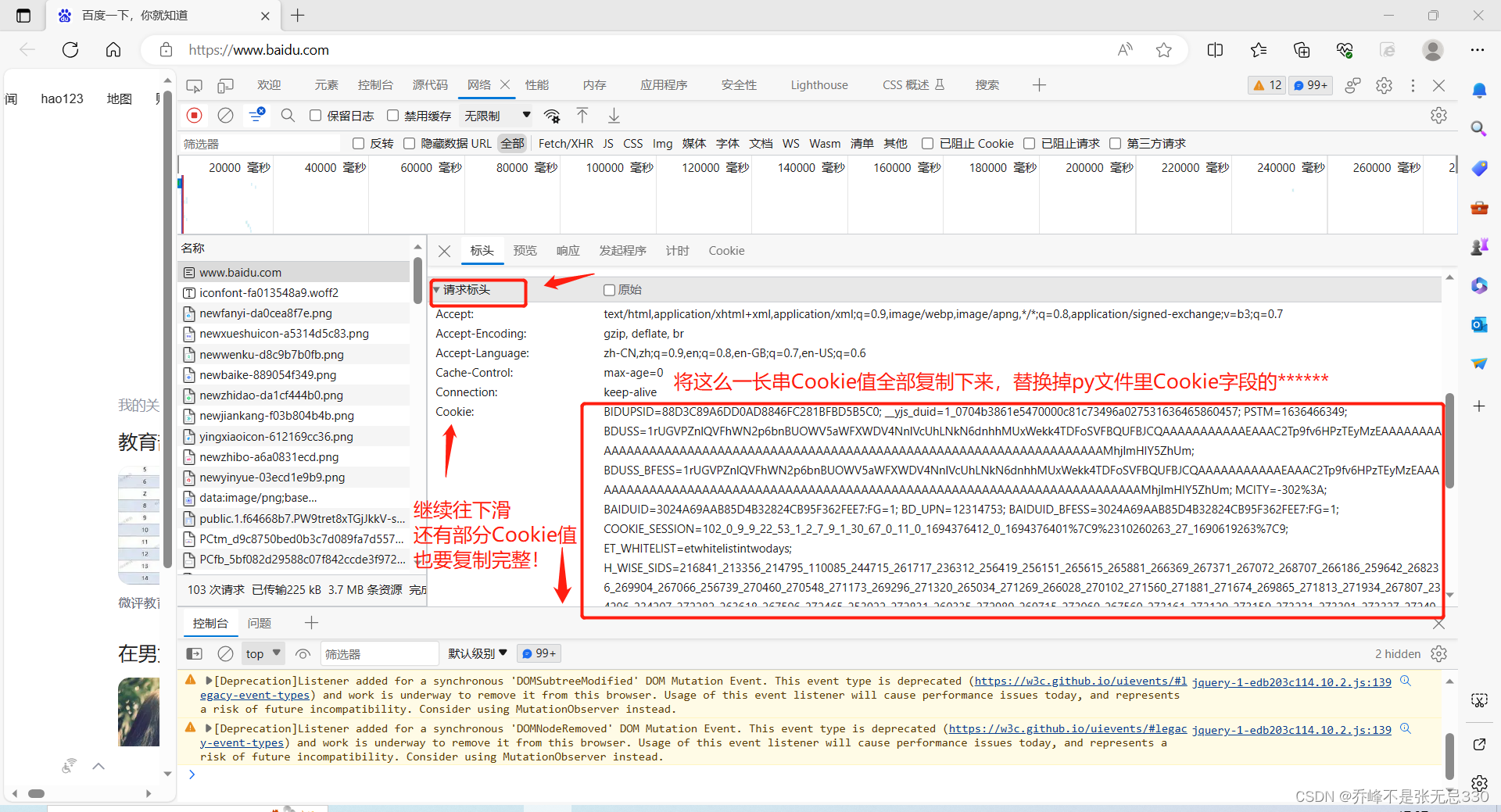
# 运行该程序前:请打开浏览器前往"https://www.baidu.com"手动登录自己的百度账户,按F12打开开发者模式,选择最上面一排Network/网络选项卡
# 接着按F5刷新本网页,捕获到的请求里一直往上翻到最顶端,选择第一次请求(即名称为www.baidu.com的请求)。
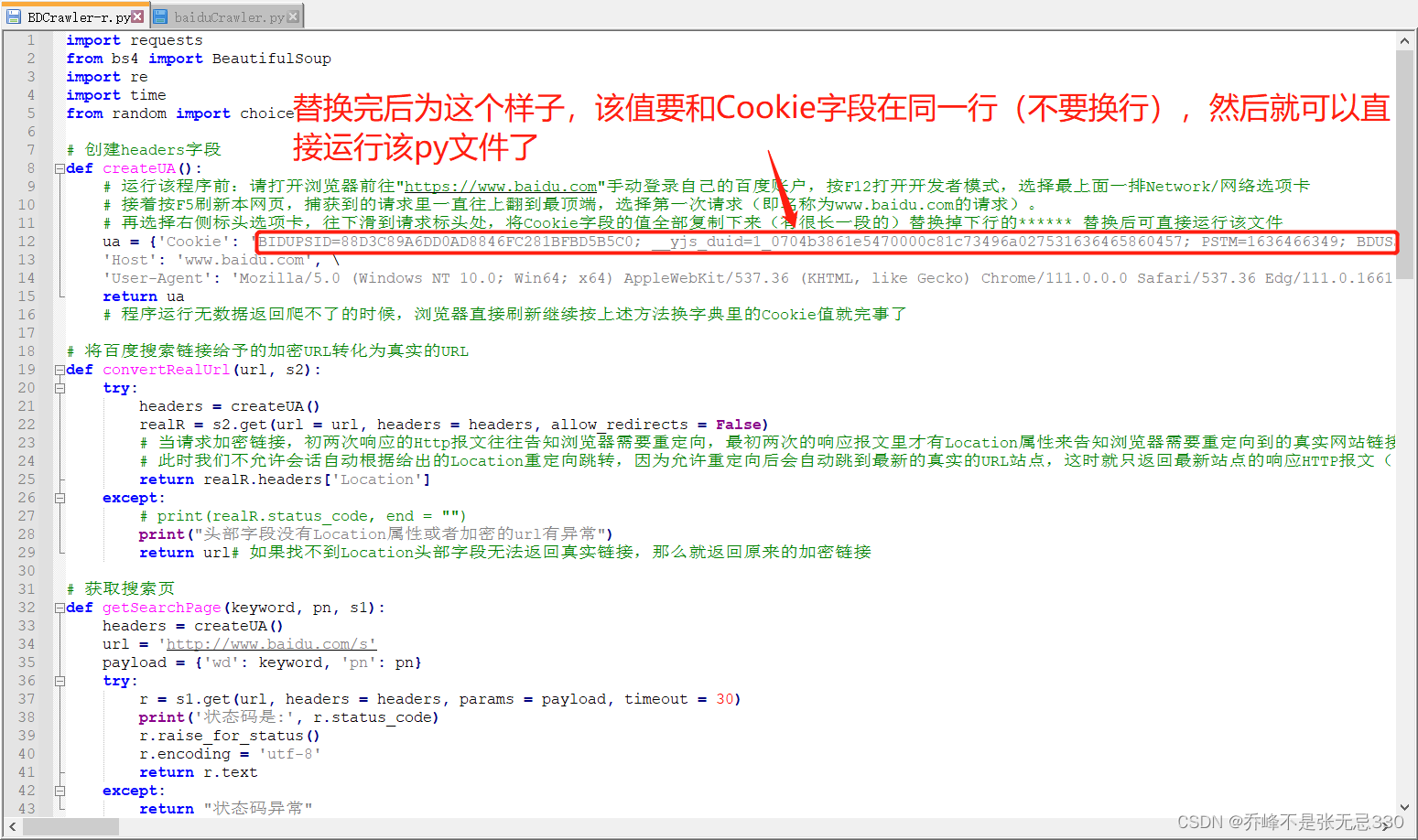
# 再选择右侧标头选项卡,往下滑到请求标头处,将Cookie字段的值全部复制下来(有很长一段的)替换掉下行的****** 替换后可直接运行该文件
ua = {'Cookie': 'BIDUPSID=AA1A39F756D4D0E2B83B6E1A38639146; PSTM=1716785788; BAIDUID=AA1A39F756D4D0E214B3565351B70FC4:FG=1; BAIDUID_BFESS=AA1A39F756D4D0E214B3565351B70FC4:FG=1; BD_UPN=12314753; BA_HECTOR=a1ala1ah8g2ga4a50h0g2g2l7qi0q11j584ju1v; ZFY=g:AC:BGYpTRw7Bm3hsLiEJdWgigibvSPJNMZd82LKKy2k:C; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598',
'Host': 'www.baidu.com', \
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'}
return ua
# 程序运行无数据返回爬不了的时候,浏览器直接刷新继续按上述方法换字典里的Cookie值就完事了
# 将百度搜索链接给予的加密URL转化为真实的URL
def convertRealUrl(url, s2):
try:
headers = createUA()
realR = s2.get(url = url, headers = headers, allow_redirects = False)
# 当请求加密链接,初两次响应的Http报文往往告知浏览器需要重定向,最初两次的响应报文里才有Location属性来告知浏览器需要重定向到的真实网站链接。
# 此时我们不允许会话自动根据给出的Location重定向跳转,因为允许重定向后会自动跳到最新的真实的URL站点,这时就只返回最新站点的响应HTTP报文(已完成重定向后),此时响应标头里不再有指示重定向url的Location字段。此方法就会失效!
return realR.headers['Location']
except:
# print(realR.status_code, end = "")
print("头部字段没有Location属性或者加密的url有异常")
return url# 如果找不到Location头部字段无法返回真实链接,那么就返回原来的加密链接
# 获取搜索页
def getSearchPage(keyword, pn, s1):
headers = createUA()
url = 'http://www.baidu.com/s'
payload = {'wd': keyword, 'pn': pn}
try:
r = s1.get(url, headers = headers, params = payload, timeout = 30)
print('状态码是:', r.status_code)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return "状态码异常"
# 升级!爬取一页的标题和真实链接
def upgradeCrawler(html, s2):
soup = BeautifulSoup(html, 'lxml')
titles = []
links = []
for h3 in soup.find_all('h3', {'class': re.compile('c-title t')}):
# a.text为获取该路径下所有子孙字符串吧。可能刚好a元素和em元素间没有换行符,所以抓取的字符串里没有\n换行符
g_title = h3.a.text.replace('\n', '').replace(',', ' ').strip()# 去掉换行和空格,部分标题中还有逗号会影响CSV格式存储,也要去除。
g_url = h3.a.attrs['href']
g_url = convertRealUrl(g_url, s2)
print("{}\t{}\t".format(g_title, g_url))
titles.append(g_title)
links.append(g_url)
return titles, links
# 将二维列表数据写入CSV文件
def writeCSV(titles, links):
infos = list(zip(titles, links))
# fo = open('./BDlinks.csv', 'at', encoding='utf-8')# 需要锁定用utf-8编码打开,不然该文件很可能会以gbk中文编码存储,这导致部分url中的西文字符存储到本文件时无法通过gbk模式编码存储。
for row in infos:
# fo.write(",".join(row) + "\n")
print(row+'\n')
# fo.close()
# print("CSV文件已保存!")
# 顶层设计
def main():
while True: # 循环
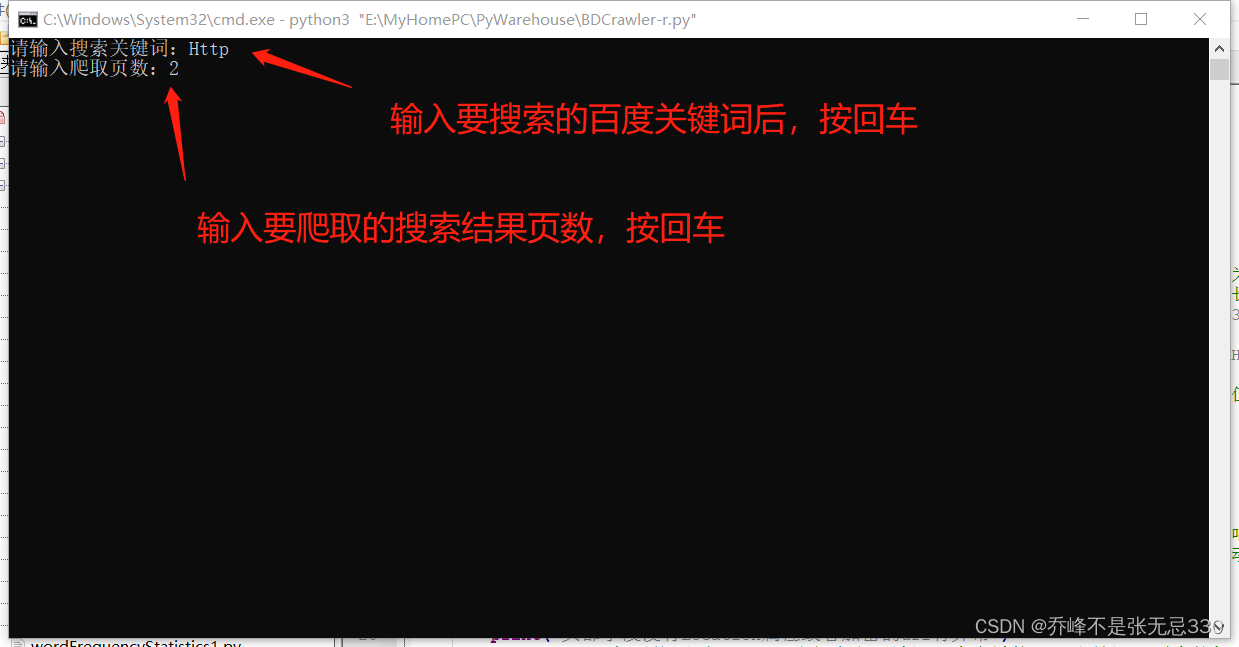
keyword = input("请输入搜索关键词:")
num = int(input("请输入爬取页数:"))
titles = []
links = []
# s1会话用于获取搜索结果页
s1 = requests.session()
# s2会话用于转真实URL
s2 = requests.session()
# 第1页为0,第2页为10,第3页为20,依次类推
num = num * 10
for pn in range(0, num, 10):
html = getSearchPage(keyword, pn, s1)
print('标题\tURL\t')
ti, li = upgradeCrawler(html, s2)
titles += ti
links += li
print("{0:->41}{1:-<36.0f}".format("当前页码为:", pn / 10 + 1))
time.sleep(30)
print('爬取完成!')
writeCSV(titles, links)
# 代码不要强求都封装成函数,这样会让传参(变量作用域)变得十分复杂和麻烦!也会增加代码行数!而且有些部分从整体意义上就是不好分的!
if __name__ == '__main__':
main()



攻心的销售文案短句 让客户一辈子只认你 https://mp.weixin.qq.com/s?__biz=MzUzNzM4NjkxNw==&mid=2247490795&idx=1&sn=dc224466e1c92420c2c363dcaf4d95d8&chksm=fae69621cd911f37715391c07584b3771c6f4d64346fa19be65d4587c50e070d88ef0f7f65d8&scene=27
营销文案短句 - 百度文库 https://wenku.baidu.com/view/d2f1ded66b0203d8ce2f0066f5335a8102d26624.html
🎀适合各行各业销售发的朋友圈文案|文案 https://mbd.baidu.com/newspage/data/dtlandingsuper?nid=dt_4444046255974402353
经典广告营销文案 离不开的7大类型⭐️ https://www.xiaohongshu.com/explore/63e8be4c0000000013013e3c
「营销文案」100句走心文案……句句扎心! http://baijiahao.baidu.com/s?id=1648145262697117969&wfr=spider&for=pc
直击灵魂的营销文案 句句不离人性❕🍷 https://mbd.baidu.com/newspage/data/dtlandingsuper?nid=dt_4784180538761099663
营销文案策划范文(精选5篇) - 百度文库 https://wenku.baidu.com/view/328a93051dd9ad51f01dc281e53a580217fc504e.html
营销的文案310句 http://m.oh100.com/meiwen/6237576.html
-----------------------------------当前页码为:1-----------------------------------
状态码是: 200
标题 URL
最实用的朋友圈销售文案 拿走不谢! - 知乎 https://zhuanlan.zhihu.com/p/611607921
38份营销创意方案经典推荐~ - 知乎 https://zhuanlan.zhihu.com/p/666549387
六一借势营销不知道怎么写?10大行业营销文案模板|速来抄作... https://zhuanlan.zhihu.com/p/631891974
营销型文案怎么写 营销推广文案写作技巧? - 知乎 https://www.zhihu.com/question/319637136/answer/2281495982?utm_id=0
100句2021年值得收藏的广告文案! - 知乎 https://zhuanlan.zhihu.com/p/449378333
最全618促销海报文案合集 100+有灵魂的文案 - 知乎 https://zhuanlan.zhihu.com/p/632285678
100句的经典商业文案(值得收藏) - 知乎 https://zhuanlan.zhihu.com/p/613364181
盘点丨2017年10大最佳营销文案 月薪3万文案的秘诀是... - ... https://zhuanlan.zhihu.com/p/32453405
掌握618年中大促必备的营销文案技巧!本文分享14个行业的13... https://zhuanlan.zhihu.com/p/631196598
销售高情商朋友圈 20句经典文案! - 知乎 https://zhuanlan.zhihu.com/p/647319831
-----------------------------------当前页码为:2-----------------------------------
状态码是: 200
标题 URL
100句的经典商业文案(值得收藏) - 知乎 https://zhuanlan.zhihu.com/p/613364181
38份营销创意方案经典推荐~ - 知乎 https://zhuanlan.zhihu.com/p/666549387
六一借势营销不知道怎么写?10大行业营销文案模板|速来抄作... https://zhuanlan.zhihu.com/p/631891974
100条最新男装文案②(值得收藏) - 知乎 https://zhuanlan.zhihu.com/p/638160311
100条男装最新文案 - 知乎 https://zhuanlan.zhihu.com/p/628292200
营销型文案怎么写 营销推广文案写作技巧? - 知乎 https://www.zhihu.com/question/319637136/answer/2281495982?utm_id=0
【朋友圈】各类销售营业通用文案 - 知乎 https://zhuanlan.zhihu.com/p/633263149
-----------------------------------当前页码为:3-----------------------------------
状态码是: 200
标题 URL
100句的经典商业文案(值得收藏) - 知乎 https://zhuanlan.zhihu.com/p/613364181
38份营销创意方案经典推荐~ - 知乎 https://zhuanlan.zhihu.com/p/666549387
六一借势营销不知道怎么写?10大行业营销文案模板|速来抄作... https://zhuanlan.zhihu.com/p/631891974
100条最新男装文案②(值得收藏) - 知乎 https://zhuanlan.zhihu.com/p/638160311
100条男装最新文案 - 知乎 https://zhuanlan.zhihu.com/p/628292200
营销型文案怎么写 营销推广文案写作技巧? - 知乎 https://www.zhihu.com/question/319637136/answer/2281495982?utm_id=0
【朋友圈】各类销售营业通用文案 - 知乎 https://zhuanlan.zhihu.com/p/633263149
-----------------------------------当前页码为:4-----------------------------------
状态码是: 200
标题 URL
100句的经典商业文案(值得收藏) - 知乎 https://zhuanlan.zhihu.com/p/613364181
38份营销创意方案经典推荐~ - 知乎 https://zhuanlan.zhihu.com/p/666549387
六一借势营销不知道怎么写?10大行业营销文案模板|速来抄作... https://zhuanlan.zhihu.com/p/631891974
100条最新男装文案②(值得收藏) - 知乎 https://zhuanlan.zhihu.com/p/638160311
100条男装最新文案 - 知乎 https://zhuanlan.zhihu.com/p/628292200
营销型文案怎么写 营销推广文案写作技巧? - 知乎 https://www.zhihu.com/question/319637136/answer/2281495982?utm_id=0
【朋友圈】各类销售营业通用文案 - 知乎 https://zhuanlan.zhihu.com/p/633263149


















 146
146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









