







名词解释:一个3分 总分30
简答题:一个5分 总分40
编程题:一个10分 总分30
高性能计算导论复习(根据复习范围)
第五章-重点:MPI并行编程
MPI
- 消息传递编程的模型
进程组
- 指MPI程序的全部进程集合的一个有序子集且进程组中每个进程被赋于一个在该组中唯一的序号(rank),用于在该组中标识该进程。序号的取值范围是[0, 进程数 - 1]
通信器
- 理解为一类进程的集合即一个进程组,且在该进程组,进程间可以相互通信
- 任何MPI通信函数均必须在某个通信器内发生
- MPI系统提供缺省的通信器MPI_COMM_WORLD,所有启动的MPI进程通过调用函数MPI_Init()包含在该通信器内;各进程通过函数MPI_Comm_size()获取通信器包含的(初始启动)的MPI进程个数
- 组内通信器和组间通信器
进程序号
- 用来在一个进程组或通信器中标识一个进程
- MPI程序中的进程由进程组或通信器序号唯一确定,序号相对于进程组或通信器而言(假设np个处理器,标号0…np-1)
- 同一个进程在不同的进程组或通信器中可以有不同的序号,进程的序号是在进程组或通信器被创建时赋予的
- MPI系统提供了一个特殊的进程序号MPI_PROC_NULL,它代表空进程(不存在的进程),与MPI_PROC_NULL间的通信实际上没有任何作用
消息
- 两部分
- 数据(data)
- 包含用户将要传递的内容
- 包装(envelope)
- 组成
- 接收进程序号/发送进程序号
- 消息标号
- 通信器
- 组成
- 数据(data)
MPI对象
- MPI系统定义的数据结构
- 包括
- 数据类型(如MPI_INT)
- 通信器(如MPI_Comm)
- 通信请求(MPI_Request)
- 等等
- 对用户不透明
以下四个要掌握,其余了解即可(可去看我的关于MPI的博客)
MPI_Init(&argc, &argv) 与 MPI_Finalize()
这其实就是一个程序的框架,我们这么来用,其中MPI_Init会在用户启动程序的时候,定义由用户启动的所有进程所组成的通信子MPI_COMM_WORLD
#include <mpi.h>
//...
int main(int argc, char* argv[]){
//...
MPI_Init(&argc, &argv); //初始化
//这里有放我们的mpi代码
MPI_Finalize(); //退出mpi系统
//...
}
MPI_Comm_size
//返回进程数
int MPI_Comm_size(
MPI_Comm comm, //通信子
int* comm_sz_p //返回值,表示进程数
)
MPI_Comm_rank
//返回正在调用的进程再通信子中的进程号
int MPI_Comm_rank(
MPI_Comm comm, //通信子
int* my_rank_p //返回值,表示进程号
)
阻塞式点对点通信(重点)
-
两个进程之间的通信
-
源进程发送消息到目标进程
-
目标进程接受消息
-
通信发生在同一个通信器内
-
进程通过其在通信器内的标号表示
MPI系统的通信方式都建立在点对点通信之上
MPI_Send
//阻塞式消息发送
int MPI_Send(
void* msg_buf_p, //指向消息内容的指针,比如a[10]的话就是a
int msg_size, //消息长度,比如a[10]的话就是11
MPI_Datatype msg_type, //MPI数据类型
int dest, //指定要接收消息的进程的进程号
int tag, //区分消息用,比如同一种消息0代表用于打印,1代表用于计算
MPI_Comm communicator //通信子,如MPI_COMM_WORLD
)
MPI_Recv
0号进程一般用于接收数据
//阻塞式消息接收
int MPI_Recv(
void* msg_buf_p, //指向消息内容的指针,比如a[10]的话就是a
int buf_size, //消息长度,比如a[10]的话就是11
MPI_Datatype buf_type, //MPI数据类型
int source, //指定接收的消息从哪个进程发送过来
int tag, //区分消息用,比如同一种消息0代表用于打印,1代表用于计算
MPI_Comm communicator, //与发送相匹配的通信子,如MPI_COMM_WORLD
MPI_Status* status_p //大多数情况下不使用,赋予其MPI_STATUS_IGNORE即可
)
消息



- status
- 是一个数据结构为MPI_Status的参数
- MPI_Get_Count
- 查询接受到的消息长度
MPI_Status
typedef struct{ int count; //不能直接被访问 int cancelled; //不能直接被访问 int MPI_SOURCE; //消息源地址 int MPI_TAG; //消息标号 int MPI_ERROR; //接收操作的错误码 }MPI_Status;MPI_Get_count
//返回count参数接收到的元素数量 int MPI_Get_count( MPI_Status* status_p, //接受消息时返回的状态 MPI_Datatype type, //MPI数据类型 int* count_p //返回值,返回元素数量 )
消息传递成功
- 发送进程需指定一个有效的目标接收进程
- 接收进程需指定一个有效的源发送进程
- 接收和发送消息的进程要在同一个通信器内
- 接收和发送消息的 tag 要相同
- 接收缓存区要足够大
区别
-

MPI_SEND有两层含义- 第一种
- 发送的消息将被拷贝给MPI系统,一旦MPI系统成功地缓存了该消息,函数就可以返回,而该消息在网络中的传递将由MPI系统来完成
- 隐含
MPI_SEND是局部函数
- 第二种
- MPI系统将不提供对消息的缓存,只有当接收该消息的进程执行相匹配的消息接收操作时,该消息才由MPI系统通过网络写入消息接收缓存区中,且直到消息被全部写入,函数
MPI_SEND才返回 - 隐含
MPI+SEND是非局部函数
- MPI系统将不提供对消息的缓存,只有当接收该消息的进程执行相匹配的消息接收操作时,该消息才由MPI系统通过网络写入消息接收缓存区中,且直到消息被全部写入,函数
- 应用场景
- 具体并行机
- 需要用户自己通过一些程序例子来测试MPI系统采用哪种语义的
MPI_SEND
- 需要用户自己通过一些程序例子来测试MPI系统采用哪种语义的
- 微机机群和分布式存储并行机
- 一般第一种
- 共享存储并行机
- 短消息:第一种
- 长消息:第二种
- 具体并行机
- 第一种
MPI_RECV- 语义
- 如果接收的消息在MPI系统中已经存在,则立即接收该消息,并将其写入消息接收缓存区之后,函数返回;
- 如果接收的消息还没有提交给MPI系统,也就是相匹配的消息发送操作还没有被执行,则必须阻塞等待该消息的发送,直到接收到该消息之后,函数返回
- 消息接收缓存区长度
count大于消息的实际长度- 消息接收后,缓存区中多余的内存空间不会被覆盖。
- 如果消息的实际长度大于
count- 消息将被截断,产生溢出错误。
- 语义
数据环状传送(一定要看,可能会考第一个编程题)
各进程向环状内下一个进程传送数组A[n]
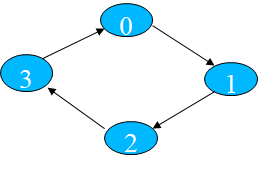
#include <stdio.h>
#include <mpi.h>
#define n 1024
int main(int argc, char *argv[])
{
int myrank, nprocs, namelen, i;
double a[n], b[n];
MPI_Status status;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
MPI_Comm_size(MPI_COMM_WORLD, &nprocs);
for (i = 0; i < n; ++i)
{
a[i] = myrank;
b[i] = 0;
}
MPI_Send(a, n, MPI_DOUBLE, (myrank + 1) % nprocs, 99, MPI_COMM_WORLD);
MPI_Recv(b, n, MPI_DOUBLE, (myrank - 1 + nprocs) % nprocs, 99, MPI_COMM_WORLD, &status);
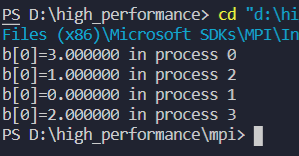
printf("b[0]=%f in process %d\n", b[0], myrank);
MPI_Finalize();
return 0;
}
运行结果:
捆绑发送接收(了解即可,不考察)
- 将一次发送调用和一次接收调用合并在一起,执行无先后
- 发送缓冲区和接收缓冲区须分开
- 发送与接收使用同一个通信域
- 由捆绑发送接收调用发出的消息可被普通接收操作接收;
- 一个捆绑发送接收调用可以接受一个普通的发送操作所发送的消息
阻塞式消息发送模式(要掌握-简答题-选两个问有啥区别)
| 通信模式 | 发送 | 接收 |
|---|---|---|
| 标准通信模式 | MPI_SEND | MPI_RECV |
| 缓存通信模式 | MPI_BSEND | |
| 同步通信模式 | MPI_SSEND | |
| 就绪通信模式 | MPI_RSEND |
标准模式(standard mode)
- 由MPI系统来决定是否将消息拷贝至一个缓冲区然后立即返回(此时消息的发送由MPI系统在后台进行),还是等待将数据发送出去后再返回。大部分MPI系统预留了一定大小的缓冲区,当发送的消息长度小于缓冲区大小时会将消息缓冲然后立即返回,否则,当部分或全部消息发送完成后才返回。
- 标准模式发送被称为是非局部的,因为它的完成可能需要与接收方联络。
- 标准模式的阻塞发送函数为MPI_Send。
缓冲模式(buffered mode)
- MPI系统将消息拷贝至一个用户提供的缓冲区然后立即返回,消息的发送由MPI系统在后台进行。用户必须确保所提供的缓冲区大小足以容下采用缓冲模式发送的消息。
- 缓冲模式发送操作被称为是局部的,因为它不需要与接收方联络即可立即完成(返回)。
- 缓冲模式的阻塞发送函数为 MPI_Bsend。
同步模式(synchronous mode)
- 实际上就是在标准模式的基础上还要求确认接收方已经开始接收数据后函数调用才返回。
- 显然,同步模式的发送是非局部的。
- 同步模式的阻塞发送函数为MPI_Ssend。
就绪模式(ready mode)
- 调用就绪模式发送时必须确保接收方已经处于就绪状态(正在等待接收该消息),否则该调用将产生一个错误。该模式设立的目的是在一些以同步方式工作的并行系统上,由于发送时可以假设接收方已经在接收而减少一些消息发送的开销。如果一个使用就绪模式的MPI程序是正确的,则将其中所有就绪模式的消息发送改为标准模式后也应该是正确的。
- 就绪模式的阻塞发送函数为 MPI_ Rsend。
阻塞式与非阻塞式通信区别
| 通信类型 | 函数返回 | 对数据操作 | 特性 |
|---|---|---|---|
| 阻塞式通信 | 1. 阻塞型函数需要等待指定操作完成返回 2. 或所涉及操作的数据要被MPI系统缓存安全备份后返回 | 函数返回后,对数据区操作是安全的 | 1. 程序设计相对简单 2. 使用不当容易造成死锁 |
| 非阻塞式通信 | 1. 调用后立刻返回,实际操作在MPI后台执行 2. 需调用函数等待或查询操作的完成情况 | 函数返回后,即操作数据区不安全,可能与后台正进行的操作冲突 | 1. 可以实现计算与通信的重叠 2. 程序设计相对复杂 |
MPI_Wait(其余了解)、MPI_Test
-
MPI_Wait阻塞等待通信函数完成后返回;
-
MPI_Test检测某通信,不论其是否完成,都立刻返回。如果通信完成,则flag=true
-
当等待或检测的通信完成时,通信请求request被设置成MPI_REQUEST_NULL
-
int MPI_Wait( MPI_Request *request, MPI_Status *status ) -
int MPI_Test( MPI_Request *request, int *flag, MPI_Status *status )
数据类型的定义(很重要,必考一题)
| MPI数据类型 | 对应的C数据类型 |
|---|---|
| MPI_INT | int |
| MPI_FLOAT | float |
| MPI_DOUBLE | double |
| MPI_SHORT | short |
| MPI_LONG | long |
| MPI_CHAR | char |
| MPI_UNSIGNED_CHAR | unsigned char |
| MPI_UNSIGNED_SHORT | unsigned short |
| MPI_UNSIGNED | unsigned |
| MPI_UNSIGNED_LONG | unsigned long |
| MPI_LONG_DOUBLE | long double |
| MPI_BYTE | |
| MPI_PACKED |
数据类型:
- 类型序列:一组数据类型
- Typesig = {type0 , type1 , … , typen-1}
- 位移序列:一组整数位移
- Typedisp = {disp0 , disp1 , … , dispn-1}
- 类型图:类型序列和位移序列的元素一一配对构成的序列
- Typemap = {(type0 , disp0) , (type1 , disp1) , … , (typen-1 , dispn-1)}
- 假设数据缓冲区起始地址为buff,则上面这个类型图定义的数据类型包含n块数据,第i块数据地址为buff + dispi ,类型为typei 。
-

-

- Typemap = {(type0 , disp0) , (type1 , disp1) , … , (typen-1 , dispn-1)}
- 下界:数据的最小位移
- 上界:数据的最大位移+1+地址对界修正量 ε
- 域:上界与下界的差
-


-

- 伪数据类型
- MPI_LB和MPI_UB
- 大小是 0
- 让用户可以人工指定一个数据类型的上下界。
- 如果一个数据类型的基本类型中含有 MPI_LB,则它的下界定义为
-
- 如果一个数据类型的基本类型中含有 MPI_UB,则它的上界定义为
-
-



MPI_Type(比较简单一点都不,例子好好看看,代码写写,可能考压轴题)
-
数据类型查询函数
int MPI_Type_size(MPI_Datatype datatype, int *size)- 返回数据类型大小
int MPI_Type_extent(MPI_Datatype datatype, MPI_Aint extent)- 返回数据类型的域
int MPI_Type_ub(MPI_Datatype datatype, MPI_Aint *displacement)- 返回数据类型上界
int MPI_Type_lb(MPI_Datatype datatype, MPI_Aint *displacement)- 返回数据型下界
-
数据类型创建函数
-
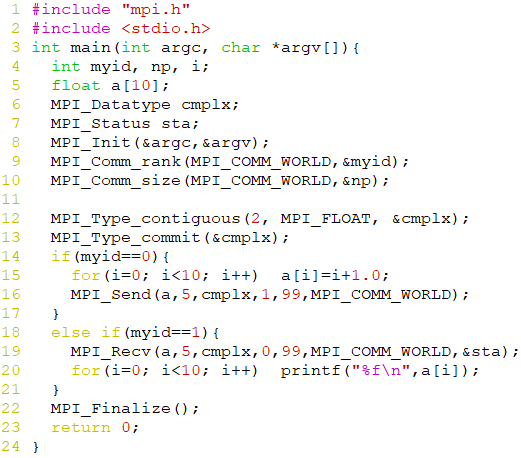
MPI_Type_contiguous
-
int MPI_Type_contiguous(int count, MPI_Datatype oldtype, MPI_Datatype *newtype)newtype由count个oldtype按域连续存放构成
-
CALL MPI_SEND(BUFF, COUNT, TYPE, ...) //等效于 CALL MPI_TYPE_CONTIGUOUS(COUNT, TYPE, NEWTYPE, IERR) CALL MPI_TYPE_COMMIT(NEWTYPE, TERR) CALL MPI_SEND(BUFF, 1, NEWTYPE, ...) -
-
-
-
MPI_Type_vector
int MPI_Type_vector(int count, int blocklength, int stride, MPI_Datatype oldtype, MPI_Datatype *newtype)- 新数据类型
newtype由count个数据块构成,每个数据块由blocklength个连续存放的oldtype构成,相邻两个数据块头的位移相差stride x extent(oldtype)个字节
-
MPI_Type_hvector
int MPI_Type_hvector(int count, int blocklength, MPI_Aint stride, MPI_Datatype oldtype, MPI_Datatype *newtype)- 新数据类型
newtype由count个数据块构成,每个数据块由blocklength个连续存放的oldtype构成, 邻两个数据块的位移相差stride个字节 - 与
MPI_Type_vector唯一区别:stride在MPI_Type_vector中以oldtype的域为单位,而在MPI_Type_hvector中以字节为单位
-
MPI_Type_indexed
int MPI_Type_indexed(int count, int *array_of_blocklengths, MPI_Aint *array_of_displacements, MPI_Datatype oldtype, MPI_Datatype *newtype)- 新数据类型
newtype由count个数据块构成, 第i个数据块包含了array_of_blocklengths[i]个连续存放的oldtype, 字节位移为array_of_displacements[i] x extent(oldtype)
-
MPI_Type_hindexed
int MPI_Type_hindexed(int count, int *array_of_blocklengths, MPI_Aint *array_of_displacements, MPI_Datatype oldtype, MPI_Datatype *newtype)- 新数据类型
newtype由count个数据块构成, 第i个数据块包含了array_of_blocklengths[i]个连续存放的oldtype, 字节位移为array_of_displacements[i] - 与
MPI_Type_indexed唯一区别:MPI_Type_indexed中array_of_displacements以字节为单位
-
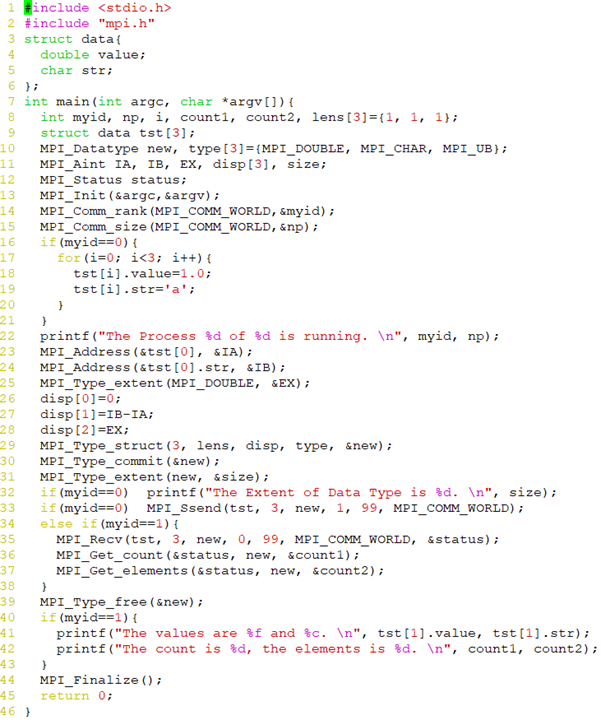
MPI_Type_struct
int MPI_Type_struct(int count, int *array_of_blocklengths, MPI_Aint *array_of_displacements, MPI_Datatype *array_of_types, MPI_Datatype *newtype)- 新数据类型
newtype由count个数据块构成, 第i个数据块包含了array_of_blocklengths[i]个连续存放, 类型为array_of_types[i]的数据, 字节位移为array_of_displacements[i] - 与
MPI_Type_hindexed区别:各数据块可以由不同的数据类型构成
-
地址函数MPI_Address
MPI_Address(void *buff, MPI_Aint *address)- 调用后,
MPI_BOTTOM(ADDRESS)与BUFF代表同一个内存地址
数据类型的使用(压轴题)
-

-
数据类型的提交
int MPI_Type_commit(MPI_Datatype *datatype)- 一个数据类型在被提交之后就可以和MPI原始数据类型完全一样地在消息传递中使用
- 如果一个数据类型仅仅用于创建其他数据类型的中间步骤而不直接在消息传递中使用,则不必将它提交,一旦基于它的其他数据类型创建完毕即可立即将它释放
-
数据类型的释放
int MPI_Type_free(MPI_Datatype *datatype)MPI_Type_free释放指定的数据类型。- 函数返回后,
datatype将会被置成MPI_DATATYPE_NULL - 正在进行的使用该数据类型的通信将会正常完成。
- 一个数据类型的释放对在它基础上创建的其他数据类型不产生影响
-
例子

-
MPI_Get_elements
int MPI_Get_elements(MPI_Status *status, MPI_Datatype datatype, int *count)- 与
MPI_Get_count相似, 但是返回的是消息中所包含的MPI原始数据类型的个数,
其返回的如果不等于MPI_UNDEFINED的话, 则必然是MPI_Get_count的整数倍
-
数据的打包拆包(重要,去年的压轴题)

-
数据的打包
int MPI_Pack(void *inbuf, int incount, MPI_Datatype datatype, void *outbuf, int outsize, int *position, MPI_Comm comm)- 将缓冲区
inbuf中的incount个数据类型为datatype的数据进行打包,打包后的数据放在缓冲区outbuf中 outsize给出的是outbuf的总长度(字节数,供函数检查打包缓冲区是否越界使用)comm是发送打包数据将使用的通信器position是打包缓冲区中的位移,第一次使用MPI_Pack前用户程序将position设为0,随后MPI_Pack将自动修改它,使它宋史指向打包缓冲区中尚未使用部分的起始位置,每次调用MPI_Pack后的position实际上就是已打包数据的总长度
-
数据的拆包
int MPI_Unpack(void *inbuf, int insize, int *position, void *outbuf, int outcount, MPI_Datatype datatype, MPI_Comm comm)- 打包的逆操作
- 从
inbuf中解析outcount个datatype数据到outbuf中
-
获得打包后的数据大小
int MPI_Pack_size(int incount, MPI_Datatype datatype, MPI_Comm comm , int *size)- 主要用于预测打包后的数据大小, 以设定
outbuf的大小
-
例子

聚合通信
-
多个进程之间的通信
-
三种方式
- 一对多
- 多对一
- 多对多
-
同步
- int MPI_Barrier(MPI_Comm comm)
- 用于进程间的同步,即一个进程调用该函数后需等待通信器内所有进程调用该函数后返回
-
广播(掌握,可能考编程题)
-
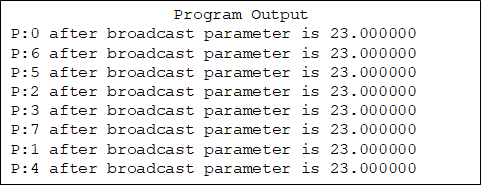
int MPI_Bcast(void *buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm) -
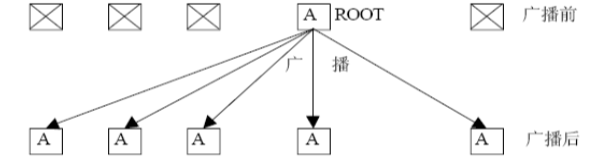
-
通信器中root进程将自己buffer内的数据发给通信器内所有进程
-
非root进程用自己的buffer接收数据
-

-
-
散发(掌握,可能考编程题)
-
MPI_Scatter( void* sendbuf , int sendcount , MPI_Datatype sendtype , void* recvbuf , int recvcount , MPI_Datatype recvtype , int root , MPI_Comm comm); -
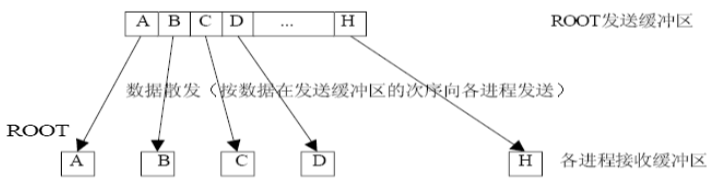
-
流程
- 根进程有np个数据块,每块包含sendcount个类型为sendtype的数据;
- 根进程将这些数据块按着进程号顺序依次散发到各个进程(包含根进程)的recvbuf
-
要求
- 发送与接收的数据类型相同;
- sendcount和recvcount相同
- 非根进程发送消息缓冲区被忽略,但需要提供
-
数据散发是数据收集的逆操作
-
不同的散发
- MPI_Scatter
- 连续
- MPI_Scatterv
- 不一定连续
- MPI_Scatter
-
根进程向所有进程次序分发一个数组元素
-
-

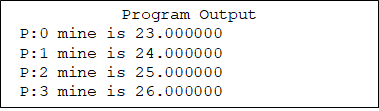
归约(重点)
- MPI_Reduce(掌握,简答或者编程题)
- 各进程提供数据(sendbuf, count, datatype)
- 归约结果存放在root进程的缓冲区recvbuf
- MPI_Allreduce
- 全归约
- MPI_Reduce_scatter
- 归约散发
MPI_Reduce
全局求和函数,分担0号进程的压力,比如说,让3号进程接收一部分消息,然后再发送给0号进程。而实现这种任务的最优分配就是MPI_Reduce的工作。
MPI_Send与MPI_Recv是点对点通信,而MPI_Reduce实现了集合通信。
int MPI_Reduce(
void* input_data_p,
void* outut_data_p,
int count,
MPI_Datatype datatype, //MPI数据类型
MPI_Op operator //MPI操作数类型
int dest_process,
MPI_Comm comm //通信子,如MPI_COMM_WORLD
)


求 π \pi π的串行代码改MPI版本(一定要会写,大概率考编程题我感觉必考)
串行版本
#inclue <stdio.h>
#define N 1000000
int main(){
double local, pi=0.0, w;
long i;
w = 1.0/N;
for(i=0; i<N; ++i){
local = (i+0.5)*w;
pi += 4.0/(1.0+local*local);
}
printf("pi is %f\n", pi*w);
}
MPI版本
#include <stdio.h>
#include <mpi.h>
const int n = 1000000;
int main(int argc, char *argv[])
{
int my_rank, num_procs;
long i;
double w, local, mypi = 0.0, pi;
double start = 0.0, stop = 0.0;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
if (my_rank == 0)
start = MPI_Wtime();
w = 1.0 / n;
for (i = my_rank; i < n; i += num_procs)
{
local = (i + 0.5) * w;
mypi += 4.0 / (1.0 + local * local);
}
mypi *= w;
MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
if (my_rank == 0)
{
printf("PI is %f\n", pi);
stop = MPI_Wtime();
printf("Time:%f\n", stop - start);
fflush(stdout); //清空缓冲区
}
MPI_Finalize();
return 0;
}
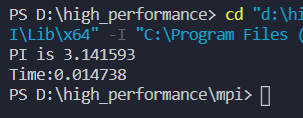
运行结果:















 520
520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









