






学习目标:
yolov8训练自己的数据集
学习内容:
查看python版本: python -V
下载yolov8
git clone https://github.com/ultralytics/ultralytics
更换为gitee国内镜像源
git clone https://gitee.com/monkeycc/ultralytics
安装必要的库
安装requirement.txt
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
安装ultralytics
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple/
数据集准备
在ultralytics文件下新建了一个MyData,路径一定注意!!
然后在MyData下新建images、xml,
images文件下放的是图片数据;
xml文件存放后缀为.xml的文件信息;
新建xml_to_txt.py文件,将.xml文件转换为.txt文件
代码为:
import xml.etree.ElementTree as ET
from tqdm import tqdm
import os
import shutil
# 1.指定标注后的img+xml文件夹路径
dataBasePath = "./MyData"
# 2.指定标注的类别字典
classes = ["closed_eye","closed_mouth","open_eye","open_mouth"] # 检测类别名字
def dealDatasetsTargetDir(labels_dir):
if os.path.exists(labels_dir):
shutil.rmtree(labels_dir)
os.makedirs(labels_dir)
dealDatasetsTargetDir(dataBasePath+'/txt')
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
# try:
in_file = open(dataBasePath+'/xml/%s.xml' % (image_id), encoding='utf-8')
# print(in_file)
out_file = open(dataBasePath+'/txt/%s.txt' % (image_id), 'w', encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
# print(xmlbox)
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " +
" ".join([str(a) for a in bb]) + '\n')
total_xmls = os.listdir(dataBasePath+'/xml')
print(total_xmls)
for xml_id in tqdm(total_xmls):
if xml_id.index('.') == 0:
continue
xml_name = xml_id.strip().split(".")[0]
convert_annotation(xml_name)
这里将labels改成txt上述.py文件已修改
新建split.py文件,划分数据集
# 将图片和标注数据按比例切分为 训练集和测试集
import shutil
import random
import os
import argparse
# 检查文件夹是否存在
def mkdir(path):
if not os.path.exists(path):
os.makedirs(path)
def main(image_dir, txt_dir, save_dir):
# 创建文件夹
mkdir(save_dir)
images_dir = os.path.join(save_dir, 'images')
labels_dir = os.path.join(save_dir, 'labels')
img_train_path = os.path.join(images_dir, 'train')
img_test_path = os.path.join(images_dir, 'test')
img_val_path = os.path.join(images_dir, 'val')
label_train_path = os.path.join(labels_dir, 'train')
label_test_path = os.path.join(labels_dir, 'test')
label_val_path = os.path.join(labels_dir, 'val')
mkdir(images_dir);
mkdir(labels_dir);
mkdir(img_train_path);
mkdir(img_test_path);
mkdir(img_val_path);
mkdir(label_train_path);
mkdir(label_test_path);
mkdir(label_val_path);
# 数据集划分比例,训练集75%,验证集15%,测试集15%,按需修改
train_percent = 0.8
val_percent = 0.1
test_percent = 0.1
total_txt = os.listdir(txt_dir)
num_txt = len(total_txt)
list_all_txt = range(num_txt) # 范围 range(0, num)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
# 在全部数据集中取出train
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
print("训练集数目:{}, 验证集数目:{},测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = os.path.join(image_dir, name + '.jpg')
srcLabel = os.path.join(txt_dir, name + '.txt')
if i in train:
dst_train_Image = os.path.join(img_train_path, name + '.jpg')
dst_train_Label = os.path.join(label_train_path, name + '.txt')
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
elif i in val:
dst_val_Image = os.path.join(img_val_path, name + '.jpg')
dst_val_Label = os.path.join(label_val_path, name + '.txt')
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
else:
dst_test_Image = os.path.join(img_test_path, name + '.jpg')
dst_test_Label = os.path.join(label_test_path, name + '.txt')
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
if __name__ == '__main__':
"""
python split_datasets.py --image-dir my_datasets/color_rings/imgs --txt-dir my_datasets/color_rings/txts --save-dir my_datasets/color_rings/train_data
"""
parser = argparse.ArgumentParser(description='split datasets to train,val,test params')
parser.add_argument('--image-dir', type=str,default='MyData/images', help='image path dir')
parser.add_argument('--txt-dir', type=str,default='MyData/txt' , help='txt path dir')
parser.add_argument('--save-dir', default='MyData/datasets',type=str, help='save dir')
args = parser.parse_args()
image_dir = args.image_dir
txt_dir = args.txt_dir
save_dir = args.save_dir
main(image_dir, txt_dir, save_dir)
运行结果为:

训练设置
新建mydata.yaml文件(本身填写的是绝对路径,但是一直有问题)
train: images/train # train images (relative to 'path') 128 images
val: images/val # val images (relative to 'path') 128 images
test: images/test # test images (optional)
# Classes
names:
0: closed_eye
1: closed_mouth
2: open_eye
3: open_mouth
新建yolov8n.yaml文件
# Ultralytics YOLO 🚀, GPL-3.0 license
# Parameters
nc: 4 # number of classes
depth_multiple: 0.33 # scales module repeats
width_multiple: 0.25 # scales convolution channels
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 17 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 20 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 23 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
开始训练
在开始训练时,因为yolov8是在命令行输入配置,所以首先进入到MyData文件下

命令端输入以下代码
yolo task=detect mode=train model=yolov8n.pt data=mydata.yaml batch=32 epochs=100 imgsz=640 workers=4 device=0
但是却报错了,显然是路径问题,这步在训练设置那一步已经进行修改了。
是因为运行结果会有以下错误:莫名出现datasets错误,为了改正问题,我就直接将原本存放train,val,test的文件夹split给改成datasets,并将mydata.yaml文件里面的路径给进行了修改。

修改后可以运行
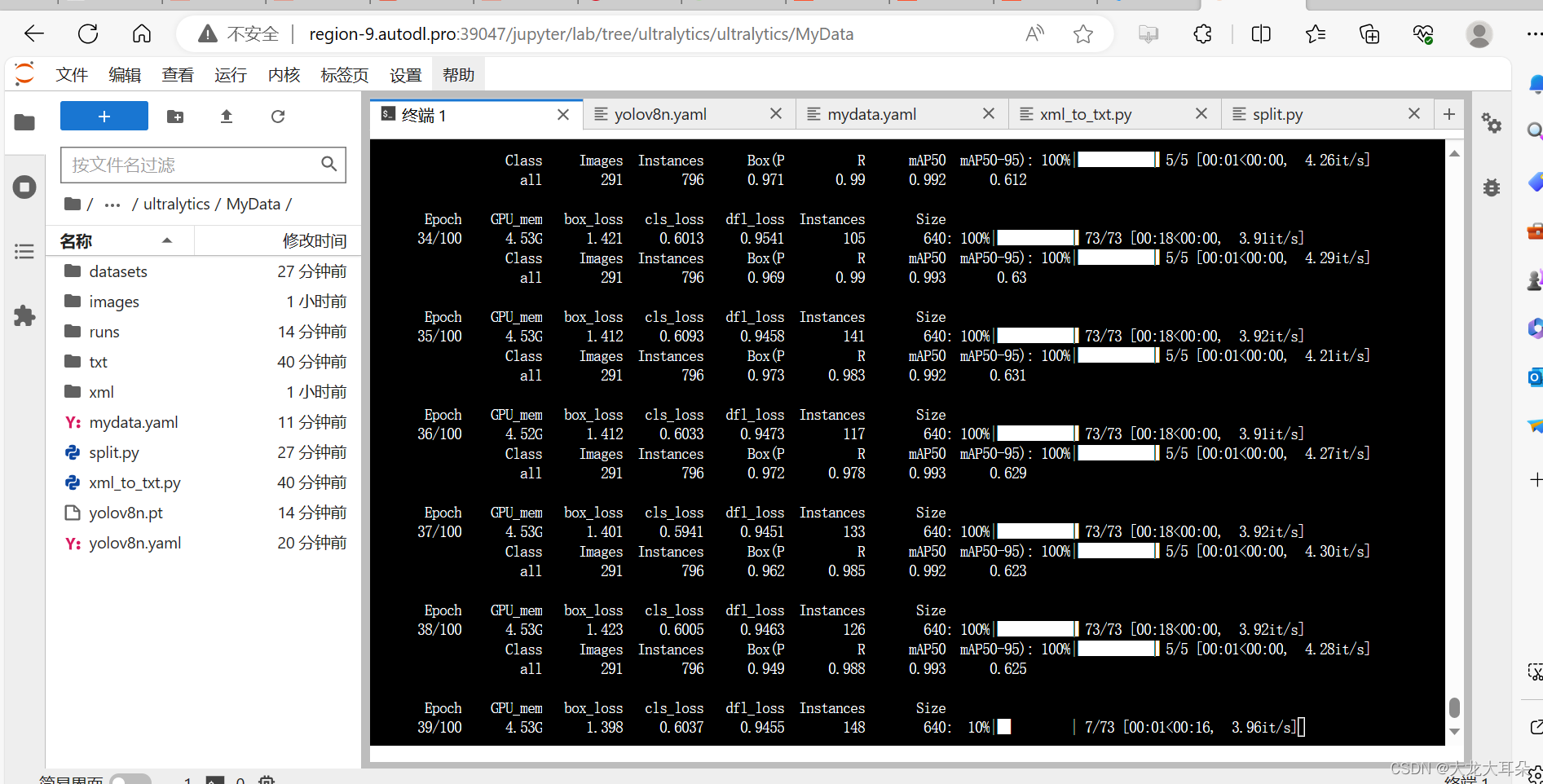
记录下右面这些文件
datasets里面存放两个文件分别是images和labels,这两个文件下又分别存放着train,val,test文件
images里面是未划分的所有照片
runs存放的是实验结果
txt和xml分别存放的是所有照片的不同格式的信息
mydata.yaml存放的是自己写的关于图片路径等信息的文件
split.py是划分数据集的代码即生成datasets
xml_to_txt.py是将xml信息格式转换为txt信息格式
yolov8n.yaml是模型文件
运行结果
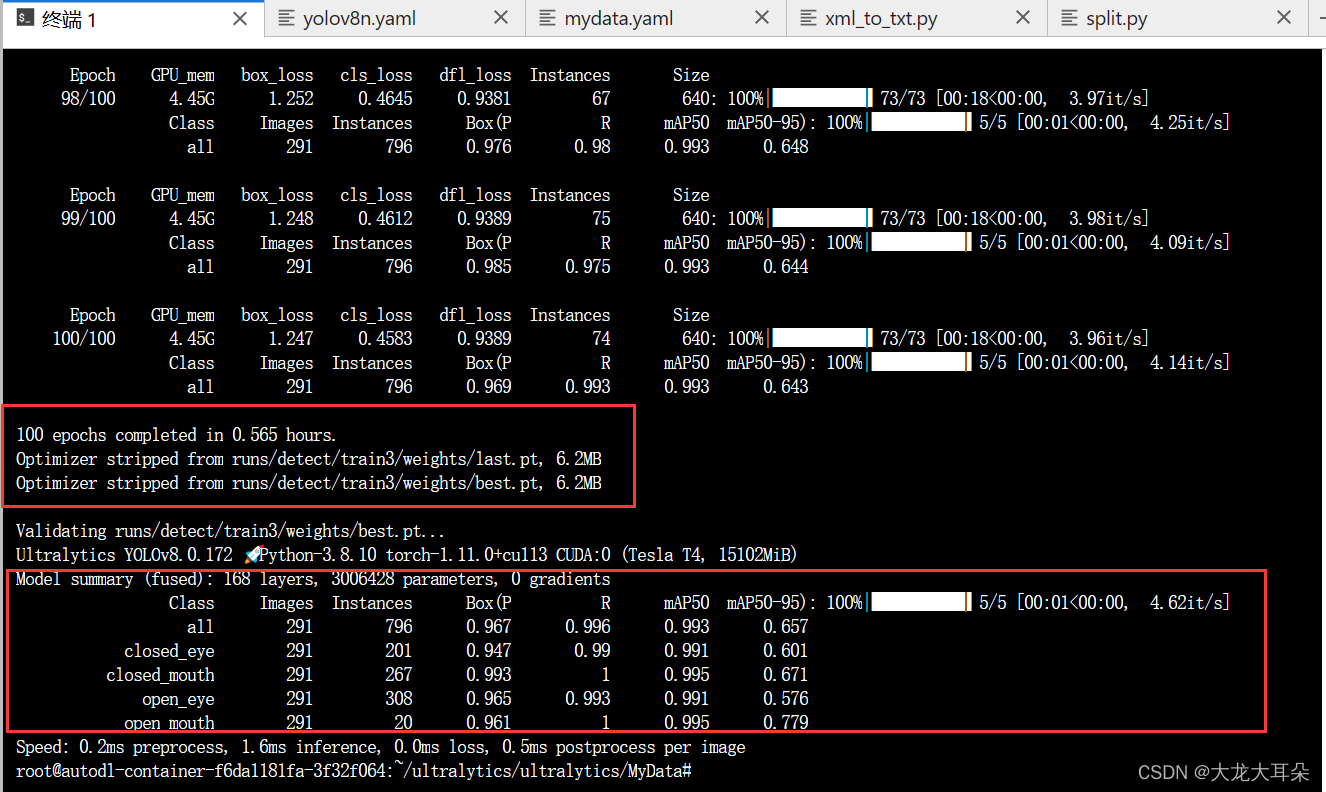
验证模型
训练结束以后相关的数据都放在runs/detect/train3/
具体的模型都存放在weights下了,具体如下:

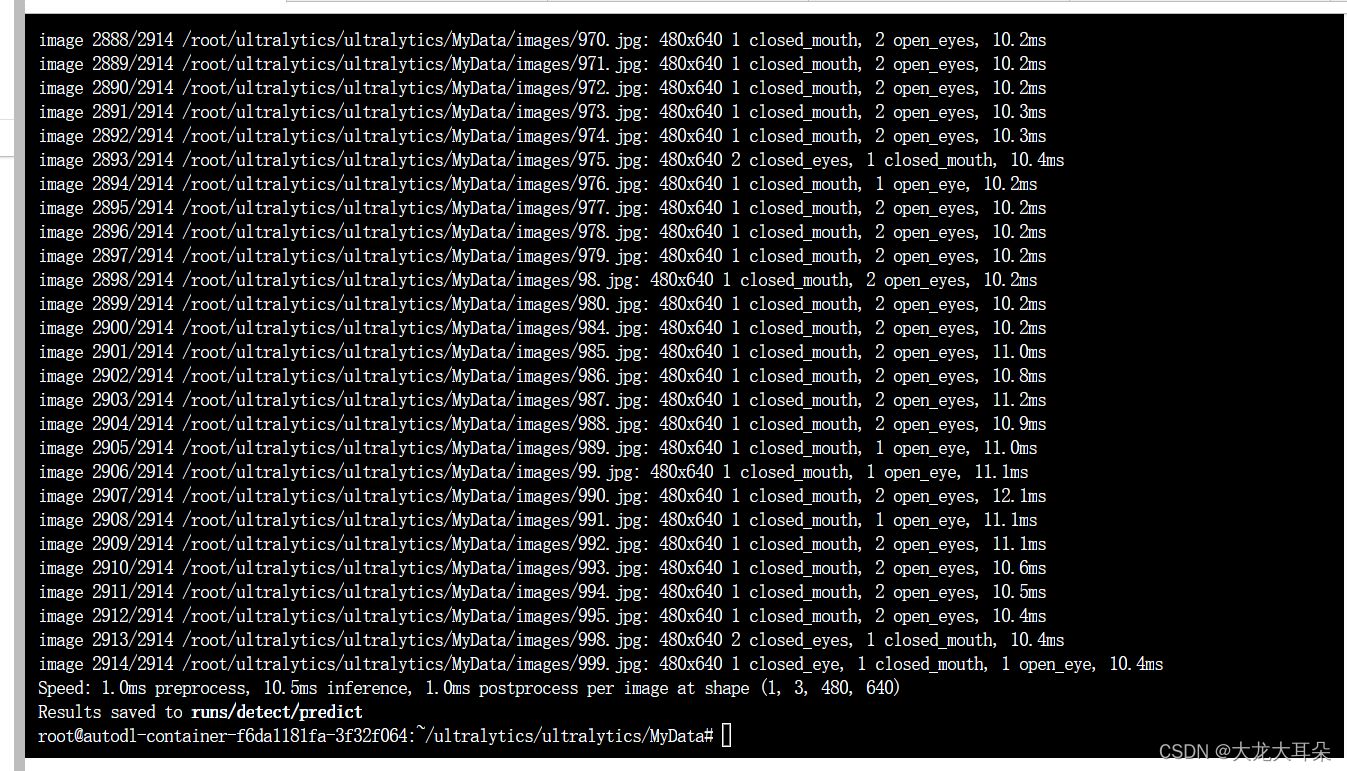
对模型进行测试
yolo task=detect mode=predict model=runs/detect/train3/weights/best.pt source=images device=0
学习时间:
2023.9.7















 1991
1991











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









