






YOLOV8是一种先进的目标检测算法,能够在图像和视频中快速准确地识别多个对象。随着计算机视觉和深度学习技术的不断发展,YOLOV8已成为许多领域中的重要工具,包括智能监控、自动驾驶、工业检测等。然而,由于不同应用场景的差异,通用的数据集往往无法满足特定需求,因此训练自己的数据集对于提高检测精度和适应特定场景至关重要。本教程将向各位介绍如何利用YOLOV8算法训练自己的数据集,以便更好地满足个性化的目标检测需求。
YOLOv8的基本原理介绍可以看我另一篇文章:YOLOv8原理详解,本文章包含了YOLOV8网络结构图的详解。
目录
环境配置
在运行yolov8前需要配置相关环境,环境如下:
torch==1.10.0+cu102
torchvision==0.11.0+cu102ultralytics==8.0.228
numpy==1.22.4
数据集准备
我这里的数据集是只有一个类,数据集名称叫target(根据自己的数据集自己命名),然后我把我的数据集放在了cfg/datasets文件下。目录形式如下:
其中Annotations存储的是xml形式的标签文件,images存储的所有的图像,labels存储的是将xml转为txt的标签文件(也是我们需要用的)。
$ tree
|-- Annotations
|-- images
|-- labels
然后我们需要将images和labels划分成训练集和验证集。如下图所示:
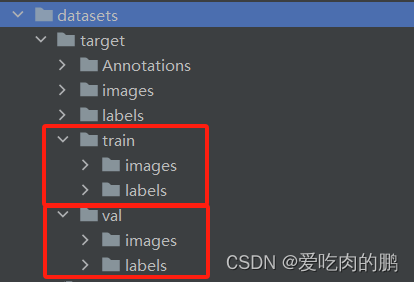
划分数据集脚本代码如下:
import os
import random
import shutil
from tqdm import tqdm
def split_datasets(datasets_path, data_dir, dataset_img_list, desc=''):
'''
:param datasets_path: 数据集根目录
:param data_dir: train or val 根目录,eg:datasets/target/train/ or datasets/target/val/
:param dataset_img_list:train or val images files list
:param desc:tqdm of str train or val
'''
for img_file in tqdm(dataset_img_list, desc=desc):
# 检查是否为图像
if img_file.endswith('.jpg') or img_file.endswith('.png'):
source_img = os.path.join(images_path, img_file) # 源图像路径
Dataset_path = os.path.join(data_dir, 'images', img_file) # 目标训练集路径
# 复制文件到训练到train_dataset
shutil.copy(source_img, Dataset_path)
# 操作对应label
# 获取label name
label_file_name = img_file.split('.')[0] + '.txt'
source_label_path = os.path.join(datasets_path, 'labels') # 获取label文件路径
source_label_file_path = os.path.join(source_label_path, label_file_name) # 获取对应label.txt路径
Label_path = os.path.join(data_dir, 'labels', label_file_name) # label目标文件路径
# 复制Label文件到train_label
shutil.copy(source_label_file_path, Label_path)
datasets_path = 'cfg/datasets/target' # root path
images_path = os.path.join(datasets_path, 'images')
train_dir = os.path.join(datasets_path, 'train') # train_root
val_dir = os.path.join(datasets_path, 'val') # val root
os.makedirs(train_dir, exist_ok=True)
os.makedirs(val_dir, exist_ok=True)
os.makedirs(train_dir + '/images', exist_ok=True)
os.makedirs(val_dir + '/images', exist_ok=True)
os.makedirs(train_dir + '/labels',exist_ok=True)
os.makedirs(val_dir + '/labels',exist_ok=True)
images_file_list = os.listdir(images_path) # 获取所有的图像文件,xxx.jpg
random.shuffle(images_file_list) # 打乱
# 划分train和val两个数据集
num_train = int(len(images_file_list) * 0.9)
train_img_files_list = images_file_list[:num_train]
val_img_files_list = images_file_list[num_train:]
# 划分train
split_datasets(datasets_path,train_dir,train_img_files_list,'train')
# 划分val
split_datasets(datasets_path, val_dir, val_img_files_list, 'val')
新建数据集yaml文件
我这里是在cfg/datasets/下新建了一个mydata.yaml文件,由于我这里只有一个类,而且类的name为"target",因此配置文件内容如下:(这里建议填写绝对路径,否则可能会出现问题)
path: F:/YOLOV8/cfg/datasets/target
train: F:/YOLOV8/cfg/datasets/target/train/images
val: F:/YOLOV8/cfg/datasets/target/val/images
test: #
# number of classes
nc: 1
# class names
names:
0: target训练
完成上述过程就可以开启我们的训练了,我这里同样也是写了一个脚本开启的训练(虽然官方有说可以在终端采用yolo命令开启训练,但我不喜欢这种方式),以yolov8s模型为例,训练代码如下:
这里也是建议在填写data的时候是绝对路径,
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO("yolov8n.pt")
res = model.train(model='yolov8n.yaml', data='F:/YOLOV8/cfg/datasets/mydata.yaml', epochs=5, batch=2,
device='cuda',
cache=True,
workers=4)进行训练。。。。
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/5 0.321G 1.159 2.346 1.435 7 640: 100%|██████████| 54/54 [00:20<00:00, 2.65it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 3/3 [00:00<00:00, 6.44it/s]
all 12 24 0.764 0.542 0.744 0.5
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
2/5 0.321G 1.35 2.419 1.619 4 640: 100%|██████████| 54/54 [00:17<00:00, 3.02it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 3/3 [00:00<00:00, 11.94it/s]
all 12 24 0.7 0.75 0.818 0.431和yolov5一样,训练完成后会将训练结果保存在runs/detect/train/下面,在runs/也会plot label或者batch等信息,这一点和v5没有区别。其中一个train_batch效果如下:

tensorboard也可以直接用tensorboard --logdir命令进行查看
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











