







 本文介绍了一项研究,通过多中心、回顾性队列分析,利用人工智能和MCF框架改进了卵巢癌的实验室检测诊断,结果显示MCF模型在识别卵巢癌和预测早期病例方面优于传统生物标志物。研究强调了常规实验室检测在卵巢癌诊断中的潜力和成本效益。
本文介绍了一项研究,通过多中心、回顾性队列分析,利用人工智能和MCF框架改进了卵巢癌的实验室检测诊断,结果显示MCF模型在识别卵巢癌和预测早期病例方面优于传统生物标志物。研究强调了常规实验室检测在卵巢癌诊断中的潜力和成本效益。
小罗碎碎念
本文题为 “基于人工智能的模型使中国**利用实验室检测准确诊断卵巢癌成为可能:一项多中心、回顾性**队列研究”。
该论文探讨了**由于缺乏有效的生物标记物而难以及时诊断卵巢癌这一难题。作者旨在评估常规实验室检测在预测卵巢癌方面的价值**,并开发一种人工智能(AI)模型来协助识别卵巢癌患者。
研究收集了**中国三家医院的数据,并使用基于多标准决策的分类融合(MCF)框架**来开发人工智能模型。该模型识别卵巢癌的准确率很高,优于 CA125 和 HE4 等传统生物标志物。
MCF 模型被包装成卵巢癌预测工具,根据输入的实验室检测值提供卵巢癌的估计概率。这项研究强调了常规实验室检测作为低成本、易获得的卵巢癌诊断工具的潜力。这项研究得到了中国多家机构的资助。
一、研究背景
本研究在现有证据的基础上,通过开发一个基于多准则决策分类融合(MCF)的先进模型,增强了使用常规实验室检测对卵巢癌进行诊断的能力。先前的研究,如2022年11月11日对PubMed和Embase的搜索所揭示的,使用了基于人工智能算法的实验室检测来预测卵巢癌的诊断。这些研究表明,成本效益高且广泛应用于健康检查及各级医疗机构的实验室检测,具有成为卵巢癌诊断生物标志的潜力。

然而,这些研究均使用了缺乏独立外部验证集的基本机器学习算法,限制了实验室检测诊断能力的证据强度。这些研究中包含的**实验室检测项目数量不足32项**,可能排除了一些有意义的实验室检测项目。尽管文献中报道了机器学习辅助诊断的许多进展,但挖掘实验室检测在卵巢癌诊断价值的研究仍然罕见。
本多中心回顾性研究筛选了99个项目(98项常规实验室检测和年龄)中的52个特征,以构建MCF模型,该模型**集成了最佳的20个基础人工智能分类模型,以准确识别高风险卵巢癌患者**。MCF模型不仅在识别卵巢癌方面优于传统的生物标志物如CA125和HE4,而且在早期卵巢癌预测方面也超越了现有的最先进模型。此外,即使排除了排名较高的实验室检测,如CA125和其他肿瘤标志物,MCF模型也显示出可接受的预测准确性。
所有可用证据的含义:本研究构建了一个稳定、强大且易于获取的卵巢癌诊断工具,该工具已公开可用。模型中使用的所有特征都是常规实验室项目,它们**可以为卵巢癌的发现提供决策支持,特别是在缺乏妇科肿瘤学临床经验的常规健康检查或初级医疗机构中**。我们发现,一系列实验室检测与肿瘤生物标志物共同对卵巢癌患者的特征描述做出了贡献,表明这些检测可能在卵巢癌的发展中发挥积极作用,其潜在机制值得进一步探索。
二、引言
卵巢癌被认为是最致命的妇科癌症。卵巢癌的五年生存率与诊断时的阶段密切相关,从局部阶段的92.4%下降到转移阶段的31.5%。在中国,据报道**少于48%的患者在早期被诊断,卵巢癌的五年生存率约为40%**,这对医学科学家提出了挑战。由于卵巢癌的初步临床表现非特异性,且常存在于无卵巢癌的女性中,因此卵巢癌的及时诊断仍然是妇科肿瘤学医生的难题。
作为**卵巢癌的核心生物标志物,碳水化合物抗原125(CA125)在大约20%的卵巢癌患者中并未显示显著升高,而在生理或良性病理过程如月经、内异症和腹膜炎症性疾病中可能升高,导致其在医院环境中的特异性有限。CA125与经阴道超声检查或其他生物标志物如人附睾蛋白4(HE4)和壳多糖酶-3样蛋白1结合可以提高卵巢癌的检测率,但对灵敏度和特异性的提高有限,或未能提供生存益处。最近的研究关注了潜在的分子水平卵巢癌生物标志物,如循环肿瘤DNA、循环肿瘤细胞、无细胞RNA、肿瘤教育血小板和外泌体。然而,尽管对这些分子生物标志物进行了广泛研究,但它们在临床实践中并未普遍使用,这可能是由于缺乏大规模验证和高诊断成本所致。当前的生物标志物不足以满足临床需求,无法提供准确且经济的卵巢癌诊断**。
在常规健康检查中使用了广泛的实验室检测。通常在一次全面体检中涉及超过50项实验室检测,包括常规血液检查、生化检查、凝血检查和尿液检查。这些实验室检测中的一些,例如**血液白蛋白浓度和淋巴细胞比率,已显示出与卵巢癌的诊断和预后相关性**。实验已经证实,这些检测的相对成分(例如免疫细胞)直接或间接参与了肿瘤的发生、发展和免疫逃逸,突显了实验室检测作为肿瘤生物标志物的潜在用途。这些实验室检测作为卵巢癌生物标志物具有独特的优势,因为它们成本低廉、易于获取、一致性良好,并且在初级卫生保健中广泛应用。
尽管常规实验室检测有潜力成为卵巢癌的生物标志物,但单一检测还未能为个体预测卵巢癌提供足够的灵敏度和特异性。人工智能(AI)可以帮助整合来自多个测试的数据以辅助诊断。技术进步,如数据存储能力、计算能力和更优算法,意味着AI能够处理实验室检测数据中的临床有意义信息,当实验室检测结果与AI技术结合时,具有表征疾病的潜力。
尽管使用AI模型预测卵巢癌风险的研究数量较少,但现有研究为基于实验室检测的预测建模提供了有价值的信息。然而,鉴于各种病理类型缺失、样本量小和缺乏外部验证等局限性,报告的模型的泛化能力和稳定性仍需得到证实。一个具有竞争力的模型对于更准确地识别卵巢癌患者至关重要。在我们最近的工作中,我们开发了一个新颖的基于多准则决策分类融合(MCF)框架,用于诊断预测。类似于临床实践中结合不同专家意见以达成共识医疗决策的多学科治疗范式,MCF旨在通过整合多个基础分类模型的估计,提供更准确的诊断。该框架可以进一步提高基于实验室检测的卵巢癌预测性能。
在这项回顾性多中心研究中,我们的目标是系统地评估实验室检测预测卵巢癌的能力,并开发一个稳健且可泛化的MCF模型,以辅助识别卵巢癌患者。
三、方法
3-1:研究设计与参与者
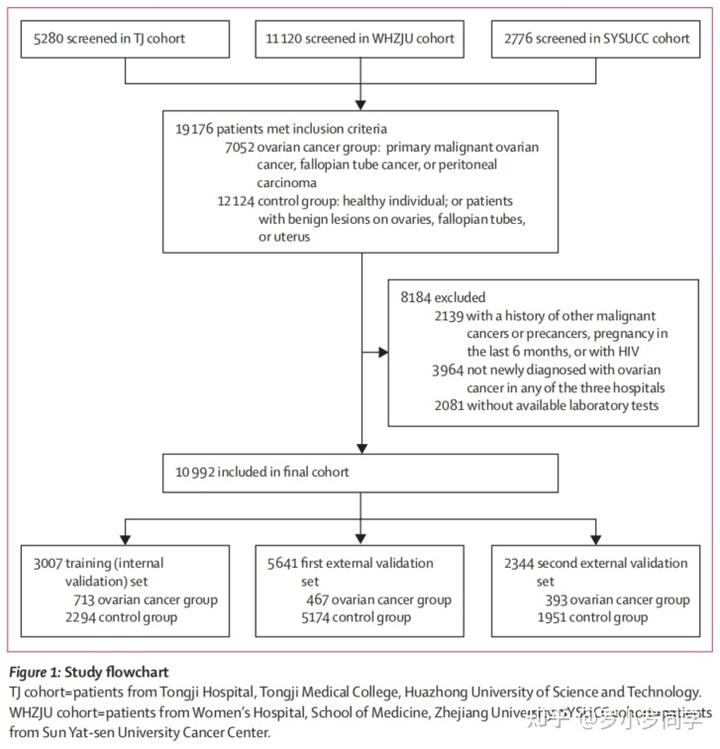
本研究是一项回顾性多中心研究,筛选了中国三家大型医院在**2012年1月1日至2021年4月4日间进行的6,778,762次实验室检查。基于妇科医生在常规临床使用中的普遍性,筛选了98项实验室检测项目(附录2,第10-12页)。华中科技大学同济医学院同济医院(中部中国)的参与者被选为训练集,并在该训练集上进行了五折交叉验证。两个外部验证集**分别来自浙江大学医学院妇女医院(东部中国)和中山大学肿瘤中心(南部中国)。
所有招募的参与者**都通过病理学确认是否存在卵巢癌。实验室检测的测量时间从诊断前1个月到任何治疗之前**。
- **卵巢癌组**纳入了原发性恶性卵巢癌、输卵管癌或腹膜癌的患者;
- **对照组**包括卵巢、输卵管或子宫无病变的健康个体,或卵巢、输卵管或子宫有良性病变的参与者。
为了减少对实验室检测的混杂因素,符合以下任一条件的个体被排除:
- 首先,有其他恶性肿瘤或癌前病变史、过去6个月内怀孕或HIV阳性者;
- 其次,不是在这三家医院新诊断的患者;
- 第三,排除没有任何可用实验室检测的个体,因为这些患者的检测结果不可靠。
3-2:数据预处理
- 98项实验室检测项目以及年龄被用作构建模型的候选输入特征。
- 对于**单位不同的实验室检测项目,进行了单位统一处理**。
- 缺失数据通过多元链式方程算法进行估算。
- 为了**减少机构间数据分布的差异,使用Box-Cox算法进行了数据调和,然后通过最小-最大方法进行了数据标准化**。
- 为了解决**数据不平衡问题**,采用了自适应综合采样方法,平衡比例为0.5。
详细的数据处理过程见附录2(第2-6页)。
3-3:预测建模
鉴于在实际操作中,通过尝试错误的方式遍历所有可用的分类器来构建预测模型是不切实际的,因此期望一个有效的分类器融合框架能够比经验选择的分类器产生更稳定和更优的预测性能。
本研究中构建的MCF(多准则决策分类融合)框架,是先前工作中提出的H-MCF(基于MCF的分层预测方案)的一个变体,用于卵巢癌的预测。

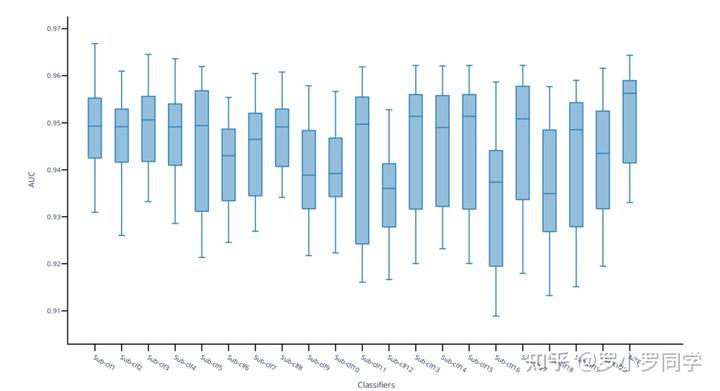
建立 176 个基础分类模型所采用的 16 种特征选择方法和 11 种分类器。通过五倍交叉验证,从 176 个模型中选出前 20 个基础分类模型。
16 种特征选择方法
- Alpha investing streaming feature selection (α-investing)
- ANOVA F-value selection (F score)
- ANOVA T-value selection (T score)
- Double Input Symmetrical Relevance (DISR)
- Fisher score
- Gini index
- Interaction Capping (ICAP)
- Joint Mutual Information (JMI)
- Laplacian score
- Logistic Loss based l_2,1-Norm Minimization (LL l21)
- Least Square loss based l_2,1-Norm Minimization (LS l21)
- Multi-Cluster Feature Selection (MCFS)
- Nonnegative Discriminative Feature Selection (NFDS)
- Relief-F algorithm (reliefF)
- Trace ratio criterion (Trace ratio)
- Unsupervised Discriminative Feature Selection (UDFS)
11 种分类器
- Adaptive Boosting classifier (AdaBoost)
- Categorical Boosting classifier (CatBoost)
- Decision Tree
- Extremely randomized trees (Extra Trees)
- Gradient Boosting Machine (Gradient Boosting)
- K-Nearest Neighboring classifier (KNN)
- Light Gradient Boosting Machine (LGBM)
- Logistic Regression (LR)
- Random Forest (RF)
- Support Vector Machine (SVM)
- eXtreme Gradient Boosting machine (XGBoost)
前 20 个基础分类模型
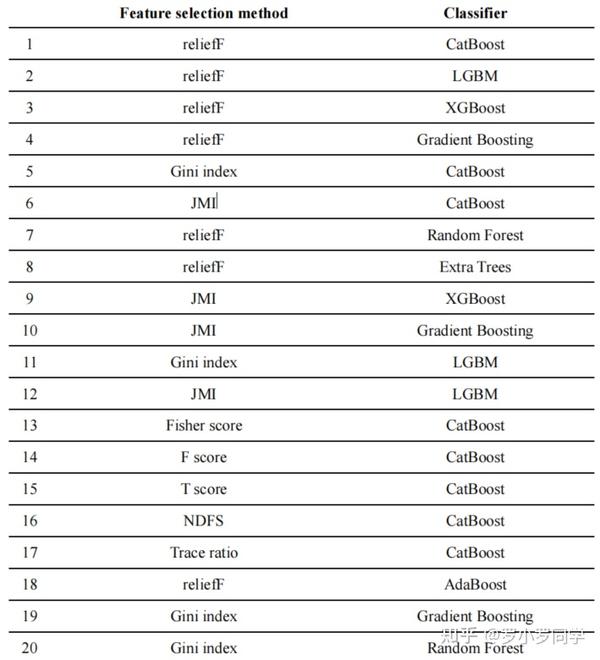
并**根据多准则决策理论估计每个模型的权重,最终融合它们的预测以达成共识分类**(附录2,第6-8页)。

3-4:性能评估
预测准确性通过**接收者操作特征曲线下的面积(AUC)、准确性、特异性、敏感性、阳性预测值、阴性预测值和F1分数**来量化。
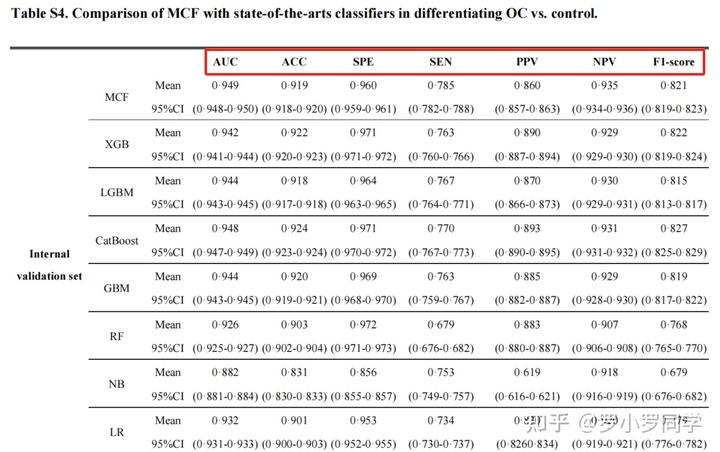
使用所有前20个选定特征的MCF模型(MCFall)与**四种不同场景**进行了比较:
1)使用前20个选定特征中的任何特征的MCF模型(MCFx),例如,如果只包括CA125的一个特征,则命名为MCFCA125;
2)使用所有前20个选定特征但不包括CA125测试的MCF模型(MCFno-CA125)或使用所有前20个选定特征但不包括所有肿瘤标志物(CEA、AFP、SCCA、HE4、CA125、CA19–9、CA15–3和CA72–4)(MCFno-TM);
3)使用CA125(LRCA125)或HE4(LRHE4)作为输入的逻辑回归,或CA125结合HE4(LRCA125+HE4)作为输入;
4)包括五种最先进的集成方法(XGBoost、LightGBM、CatBoost、梯度提升机和随机森林)和两种基线分类器(朴素贝叶斯(NB)和逻辑回归(LR))在内的七种已知比较器。
3-5:统计分析
对于连续变量,采用中位数(四分位距)和频率(%)进行评估。连续变量通过曼-惠特尼U检验在两个组间进行比较。
对于分类变量,根据适当性,使用卡方检验或费舍尔精确检验进行比较。显著性水平设定为双尾p值低于0.05。所有分析均使用R(版本4.0.1)和Python(版本3.7)进行。
四、讨论
本多中心回顾性研究中,我们**从98项常规实验室检测和年龄中筛选出52个特征,构建了新的多准则决策分类融合(MCF)模型,用于准确识别卵巢癌患者。通过整合20个最佳基础人工智能分类模型**,MCF在内部验证集和两个外部验证集中都表现出了一致且良好的性能,并在识别卵巢癌方面优于CA125和HE4,特别是在早期卵巢癌患者中。
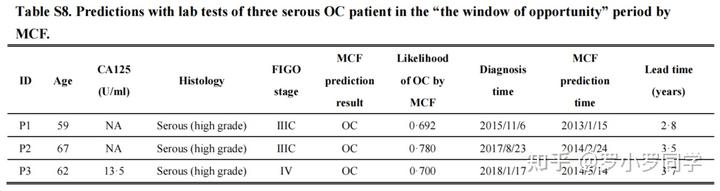
卵巢癌在人群中发病率低,缺乏典型的早期症状,且恶性程度高。在医疗系统中,初级医疗通常是患者的第一个接触点,但由于缺乏明确的症状,医生往往无法识别出早期疾病,导致卵巢癌治疗延误。MCF模型的一个优点是它为临床医生提供了一个工具,可以帮助确定可能患有卵巢癌的患者,尤其是在常规健康检查或具有有限妇科肿瘤经验的基层医疗机构中。MCF模型不仅在检测卵巢癌患者方面取得了满意的准确率,而且在从健康对照参与者中识别早期卵巢癌方面也优于CA125和HE4,并且正确识别了所有三个**浆液性肿瘤的窗口期患者**。
所包含的实验室检测和肿瘤标志物的组合为MCFall提供了比MCFCA125、MCFHE4和MCFCA125+HE4更优的预测性能,正如增加的AUC和敏感性所显示的那样,其成本低于常规肿瘤标志物面板测试加上超声、CT或MRI。这些实验室检测在卵巢癌诊断中的突出贡献也提供了对致癌机制和肿瘤进展的更好理解。
4-1:数据预处理
本预测模型的泛化性和稳定性的一个重要因素是代表性的数据和严格的数据清洗。本研究招募了中国三个不同地区的大量人群。三个队列中卵巢癌诊断的中位年龄为51-56岁,这**代表了中国人群和其他亚洲人群。然而,大规模数据也带来了一些问题。多中心数据是异质的,不利于构建稳健的人工智能模型,并且存在一些缺陷,包括卵巢癌患者和对照参与者数量之间存在显著不平衡,单位不一致,以及大量的缺失值**(内部验证集为48.5%;附录2第2-6页,第25页)。

进行了**大量的数据清洗工作**,以解决这些数据问题,确保模型的稳健性。数据预处理的成效通过比较经过清洗和未经过清洗的研究数据的结果得到了验证(附录2第26页)。
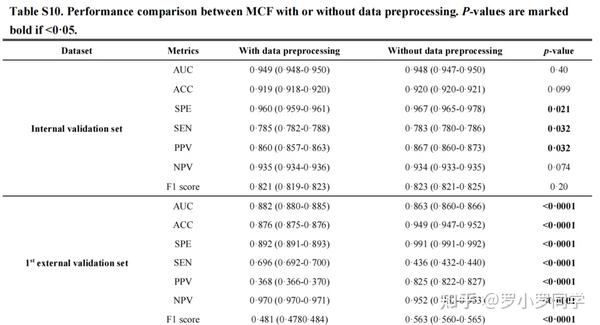
可以得出结论,严格的数据显示**预处理可能是构建稳定和可泛化的AI模型在真实世界临床环境中的第一步**。
4-2:MCF融合策略
提高模型预测性能的另一个重要因素是我们提出的MCF融合策略,它允许协调多个分类模型的预测。这可能解决了必须为建模选择一个合适的算法的问题,这个问题通常是特定于数据或特定于问题的,并且不简单。MCF还允许在融合中更好地分配模型权重;它被框定在多准则决策理论之外,其中**模型融合问题被分解为决策过程。在融合中给单个模型的贡献加权类似于根据它们的训练和验证性能对它们进行优先排序,这是通过几个指标来量化的**。与已知的预测模型相比,MCF为大型多中心数据提供了更可靠和一致的卵巢癌预测(附录2第17-20页,第36页)。
基于实验室检测的人工智能预测模型在许多疾病中都有所探索,包括一些关于卵巢癌诊断或预后预测的研究。Kawakami及其同事基于32项实验室检测参数和年龄构建了七个机器学习模型,以推导上皮卵巢癌的诊断信息。神经网络算法基于实验室检测在卵巢癌的早期检测和生存预测中已经被探索,声称优于传统的逻辑回归模型。然而,这些已发表的研究由于只包括单一病理类型、小样本量或缺乏外部验证而受到限制。相比之下,我们的研究是在大规模多中心数据集上进行的,包括各种卵巢癌病理类型,并且所提出的模型通过两个大型独立外部队列进行了全面验证,从而增强了我们模型的可信度。
4-3:模型可解释性
使决策过程透明增加了对临床中可解释人工智能模型使用的信心。在这项研究中,我们**试图通过两种方式增强MCF的可解释性**。
- 首先,MCF选择的排名靠前的特征与卵巢癌显著相关。在我们的研究中,D-二聚体(OR=7·753)、纤维蛋白原(2·669)、血小板计数(1·972)和血小板crit(1·890)等参与凝血过程的指标被MCF确定为卵巢癌预测的重要特征(附录2第28页),这**与之前关于癌症异常激活凝血系统的临床和基础研究一致。同样,与炎症相关的项目(例如,淋巴细胞百分比[0·453])被标记为对最终MCF模型有显著贡献的主要因素,为卵巢癌可能通过抑制淋巴细胞来抑制免疫系统并导致免疫逃逸提供了额外的证据**。由于所有可用的实验室检测作为输入,且不知道它们的优先顺序,MCF提供了一个解决方案,用于识别可能最终导致高诊断性能的特征的最优整合。
- 其次,可解释的人工智能方法SHAP表明所包含特征的贡献是可解释的,并与我们方法估计的重要性排名高度一致。开发新的算法来更好地解释黑盒AI模型的机制仍有很大的潜力,我们感兴趣在未来研究中朝着这个方向迈出我们的下一步。
4-4:模型的局限性
本研究存在一些局限性。
- 首先,MCF模型尚未在前瞻性队列中进行评估。
- 其次,由于本研究的回顾性真实世界性质,部分人群中的数据损失是不可避免的。
- 第三,受数据共享限制和数据注释成本的限制,招募的患者仅限于中国三家大型医院。模型在其他地区的泛化性仍需进一步调查。纳入更多来自基层医疗设施的患者将允许获得更多机会窗口期患者和晚期浆液性卵巢癌患者的配对记录,从而进一步证实MCF的优点。
- 第四,诸如成像特征、基因特征或来自自然语言文本的临床特征等多模态数据未包括在内。自然语言文本是指文本或语音中的自然语言数据。目前,医疗AI中最常用的自然语言文本是电子病历,即症状和医疗历史的描述。临床预约中的对话也可能是一种自然语言数据,并具有未来用于疾病预测的潜力。一些这些特征已经被报道有助于预测卵巢癌。
最后,我们必须认识到,开发模型的临床应用仍然面临挑战,这涉及到种族多样性、临床使用的归属责任,以及决策过程的充分透明度等实际考虑。为了保证MCF的更好应用,需要进行前瞻性研究、注释良好的多模态多民族数据集,以及更多合法的AI辅助工具法律法规。
综上所述,基于51项常规实验室项目和年龄的MCF在预测卵巢癌以及检测早期卵巢癌患者方面取得了令人满意和稳定的性能,并显著优于CA125和HE4以及另外七种已知方法。该模型提供了一种低成本、易于获取且准确的卵巢癌诊断工具。所有特征,包括CA125和其他肿瘤标志物,都对卵巢癌的预测做出了贡献。需要进行前瞻性研究和来自其他地区的数据集,以进一步证实所提出的MCF的可行性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









