







一、相关性热图的定义
相关性热图(Correlation Heatmap)是一种数据可视化技术,用于展示多个变量之间的相关性强度和方向。这种图表通常用于探索数据集中不同变量之间的关系,尤其是在多元数据分析中。
-
矩阵格式:相关性热图以矩阵的形式呈现,其中行和列都代表数据集中的变量。
-
相关性系数:矩阵中的每个单元格显示两个变量之间的相关性系数,通常使用皮尔逊相关系数(Pearson correlation coefficient)来衡量。这个系数的值范围在-1到1之间,其中-1表示完全负相关,1表示完全正相关,而0表示没有线性相关。
-
颜色编码:热图使用颜色来表示相关性的强度。通常,暖色调(如红色)表示强正相关,冷色调(如蓝色)表示强负相关,而白色或灰色可能表示相关性较弱或接近零。
-
数据洞察:通过观察热图中的颜色分布,可以快速识别哪些变量之间存在较强的线性关系,哪些变量之间的关系较弱或没有明显关系。
-
应用领域:相关性热图广泛应用于统计学、数据科学、金融分析、生物信息学等领域,帮助研究者和分析师理解变量之间的关系,并为进一步的数据分析提供指导。
-
工具和库:在Python中,可以使用
seaborn和matplotlib库来创建相关性热图,而在R语言中,可以使用ggplot2和corrplot包。
相关性热图是一种非常直观的工具,可以揭示数据中的模式和趋势,但它也有局限性,比如它只能展示线性关系的强度,对于非线性关系可能不够敏感。因此,在分析数据时,它通常与其他统计方法和可视化技术结合使用。
二、用Python举一个简单的例子
假设我们有一个简单的数据集,包含两个变量:温度(Temperature)和湿度(Humidity),我们想要分析这两个变量之间的相关性。我们将使用Python语言中的pandas库来处理数据,以及seaborn和matplotlib库来创建相关性热图。
首先,我们需要安装这些库(如果你还没有安装的话):
pip install pandas seaborn matplotlib
然后,我们可以编写以下Python代码来创建相关性热图:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 创建一个简单的数据集
data = {
'Temperature': [22, 24, 19, 21, 20, 23, 25, 26],
'Humidity': [60, 65, 55, 50, 58, 62, 70, 68]
}
# 将数据转换为pandas DataFrame
df = pd.DataFrame(data)
# 计算相关性矩阵
corr = df.corr()
# 使用seaborn创建热图
plt.figure(figsize=(8, 6)) # 设置图形大小
sns.heatmap(corr, annot=True, fmt=".2f", cmap='coolwarm', cbar=True) # annot=True表示在每个单元格中显示相关系数
# 添加标题和标签
plt.title('Correlation Heatmap of Temperature and Humidity')
plt.xlabel('Variables')
plt.ylabel('Variables')
# 显示图形
plt.show()
这段代码首先创建了一个包含温度和湿度数据的字典,然后将其转换为pandas的DataFrame。接着,我们计算了这两个变量之间的相关性矩阵,并使用seaborn的heatmap函数来创建热图。
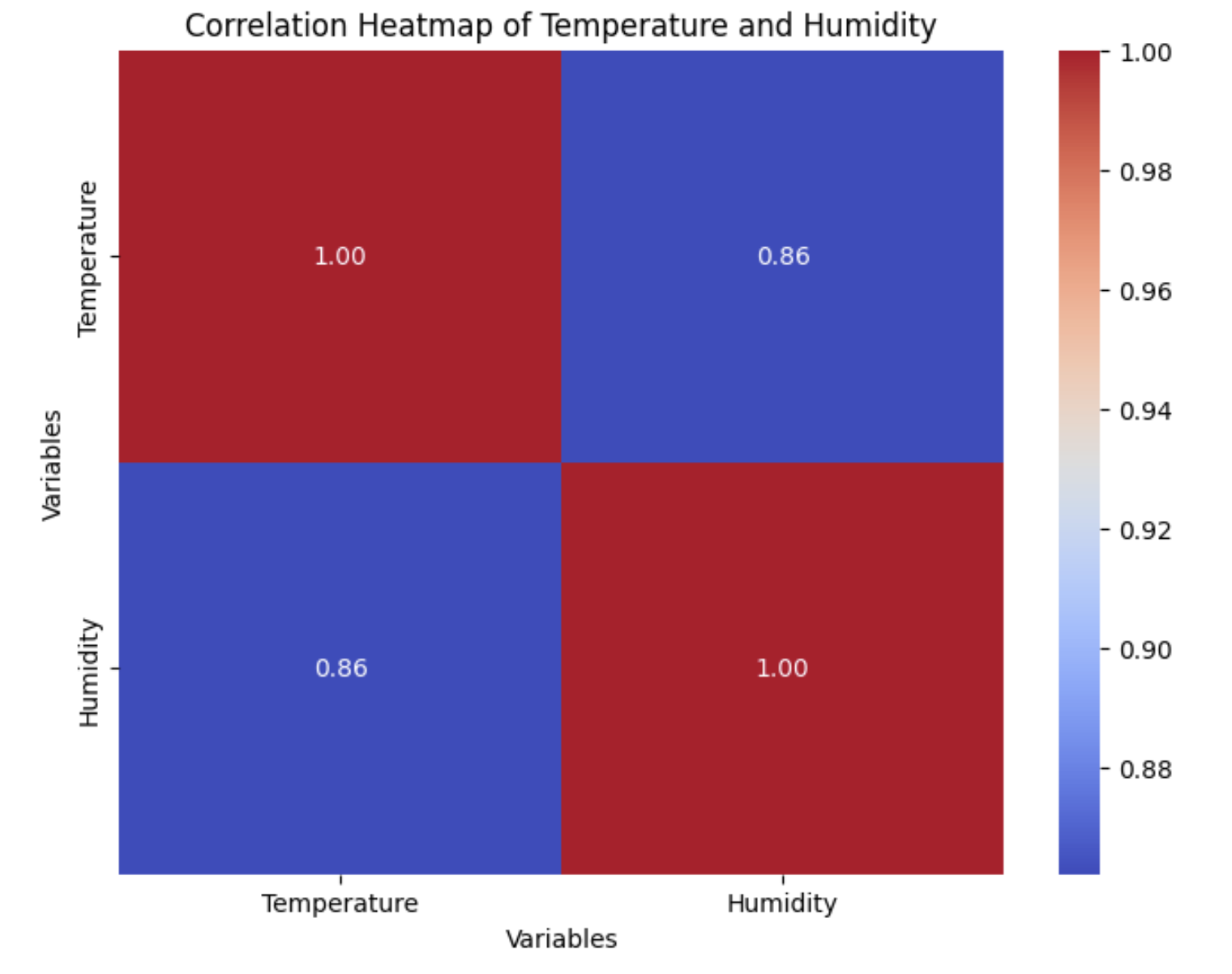
annot=True参数表示在热图的每个单元格中显示相关系数的值,fmt=".2f"指定了小数点后两位的显示格式,cmap='coolwarm'指定了颜色映射,cbar=True表示显示颜色条。
运行上述代码后,你将得到一个热图,其中颜色的深浅表示温度和湿度之间的相关性强度。在这个例子中,由于数据是随机生成的,可能显示为弱相关或无相关性。
三、用R语言绘图
R语言和Python有很多功能交叉的地方,但是论绘图方面,R语言会更简洁,也更容易绘制住精美的图,所以接下来的图均由R语言绘制。
相关包及数据导入
#安装包和依赖项
install.packages(c("corrplot", "RColorBrewer"))
install.packages("ISLR2")
# 加载安装的包
library(corrplot) #可视化
library(RColorBrewer) # 配色
data("Boston",package = "ISLR2")
colnames(Boston) = stringr::str_to_title(colnames(Boston))
cor(Boston) -> corr_data
这段R代码执行了一系列操作,用于准备数据和安装必要的包,以便进行数据可视化。
install.packages(c("corrplot", "RColorBrewer"))
这行代码使用install.packages()函数来安装名为corrplot和RColorBrewer的两个R包。c()函数创建了一个字符向量,包含这两个包的名称。如果这些包之前没有安装,这行代码会下载并安装它们以及它们的依赖项。install.packages("ISLR2")
这行代码尝试安装名为ISLR2的R包。如果之前没有安装,它会被下载并安装。library(corrplot)
这行代码使用library()函数加载corrplot包,这样你就可以使用这个包中的函数和数据。library(RColorBrewer)
这行代码加载RColorBrewer包,该包提供了多种配色方案,可以用于数据可视化中的颜色选择。data("Boston", package = "ISLR2")
这行代码使用data()函数从ISLR2包中加载名为Boston的数据集。Boston数据集是经典的统计数据集,通常用于演示和教学。colnames(Boston) = stringr::str_to_title(colnames(Boston))
这行代码使用stringr包中的str_to_title()函数将Boston数据集的列名转换为标题格式,即每个单词的首字母大写。这里假设stringr包已经安装并加载,如果没有,需要先安装并加载stringr包。cor(Boston) -> corr_data
这行代码使用cor()函数计算Boston数据集的相关性矩阵,并将结果赋值给变量corr_data。这个相关性矩阵可以用于后续的相关性分析或可视化。
3-1:常规热力图
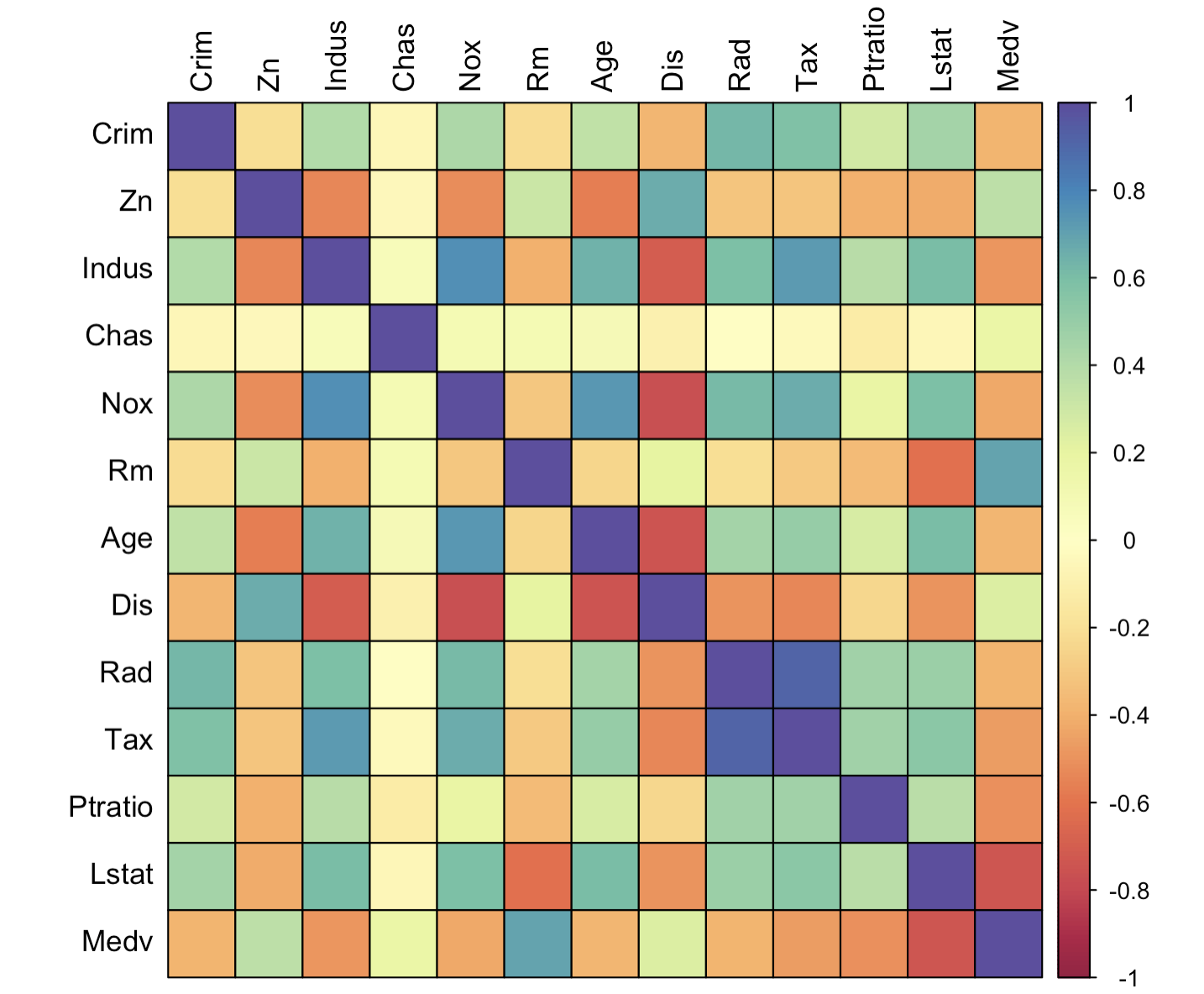
corrplot(corr = corr_data,
method = 'color',
col = colorRampPalette(colors = brewer.pal(11, "Spectral"))(200),
outline = TRUE,
tl.col = "black")
这段R代码使用了corrplot包中的corrplot函数来创建一个相关性热图。
-
corr = corr_data
这是相关性矩阵的输入,corr_data变量包含了之前通过cor(Boston)计算得到的相关性矩阵。 -
method = 'color'
这个参数指定了热图的显示方式。'color'方法意味着热图的颜色深浅将表示变量之间的相关性强度。 -
col = colorRampPalette(colors = brewer.pal(11, "Spectral"))(200)
这个参数定义了热图中使用的颜色渐变。colorRampPalette函数创建了一个颜色渐变的向量,brewer.pal(11, "Spectral")从RColorBrewer包中选取了一种名为"Spectral"的配色方案,该方案有11种颜色。(200)表示生成200个颜色的渐变,用于热图中不同相关性强度的表示。 -
outline = TRUE
这个参数指定是否在热图的单元格周围绘制轮廓线。TRUE表示绘制轮廓线,这有助于更清晰地区分不同的单元格。 -
tl.col = "black"
这个参数定义了热图单元格中文本标签(通常是相关系数的值)的颜色。在这里,文本颜色被设置为黑色。
将这些参数组合起来,corrplot函数会生成一个颜色编码的相关性热图,其中单元格的颜色深浅表示变量之间的相关性强度,单元格周围有黑色轮廓线,并且每个单元格中显示了黑色文本的相关系数值。
这个热图是数据科学家和统计学家用来快速识别数据集中变量之间关系的强大工具。通过颜色的直观表示,可以很容易地看出哪些变量之间存在强相关性,以及它们是正相关还是负相关。
3-2:圆形热力图
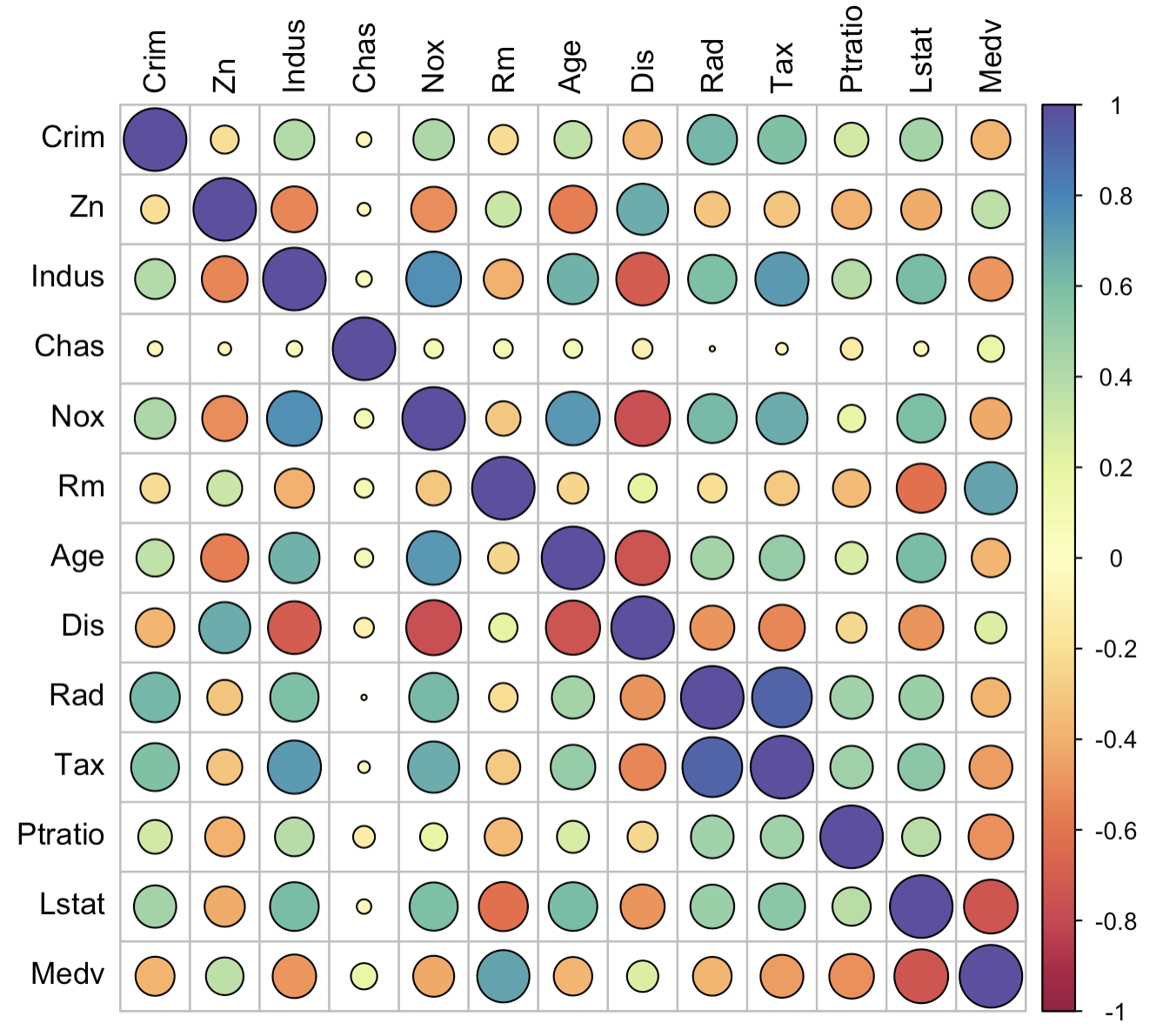
corrplot(corr = corr_data,
col = colorRampPalette(colors = brewer.pal(11, "Spectral"))(200),
outline = TRUE,
tl.col = "black")
3-3:椭圆热力图
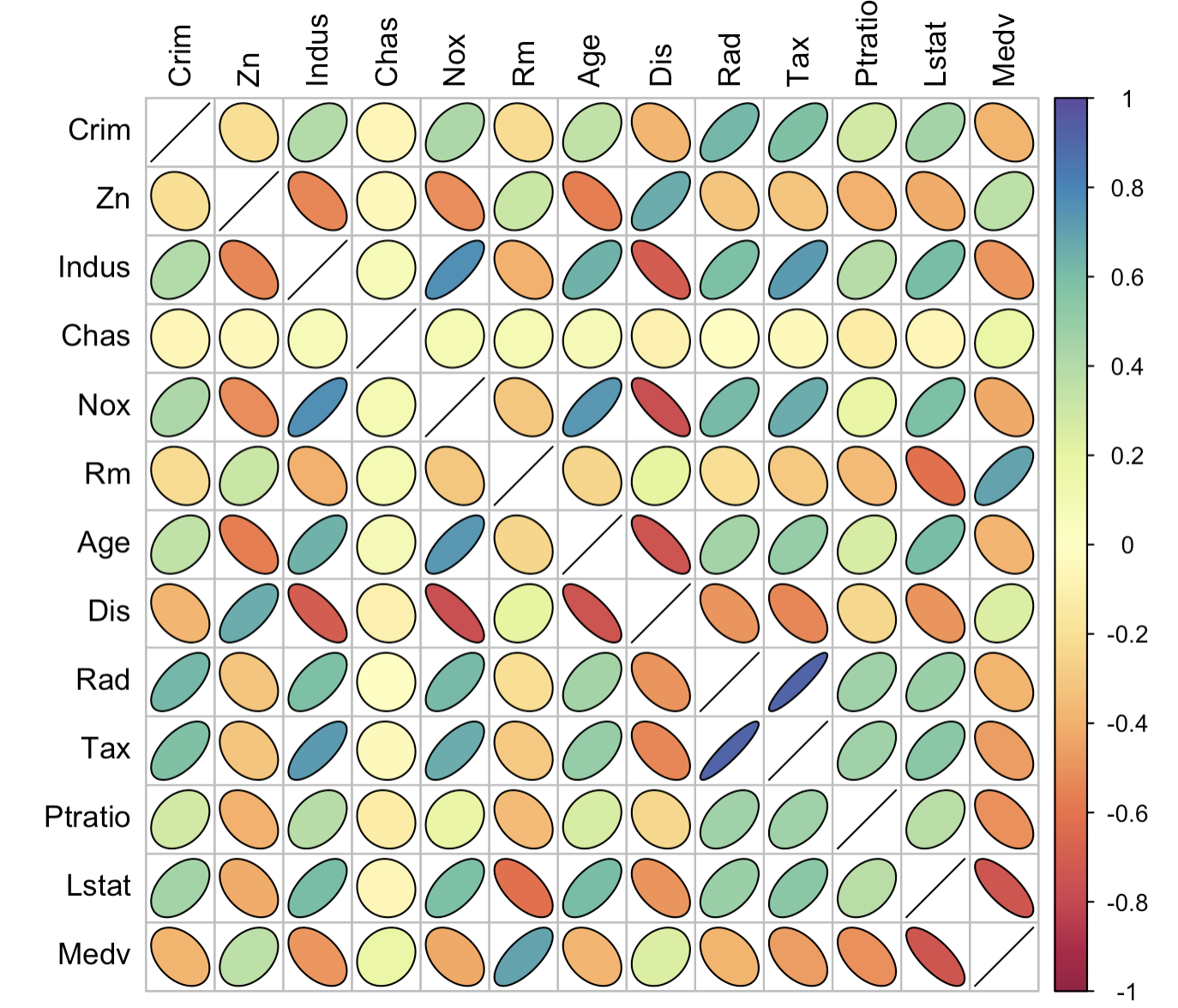
corrplot(corr = corr_data,
method = 'ellipse',
col = colorRampPalette(colors = brewer.pal(11, "Spectral"))(200),
outline = TRUE,
tl.col = "black")
3-4:方块热力图
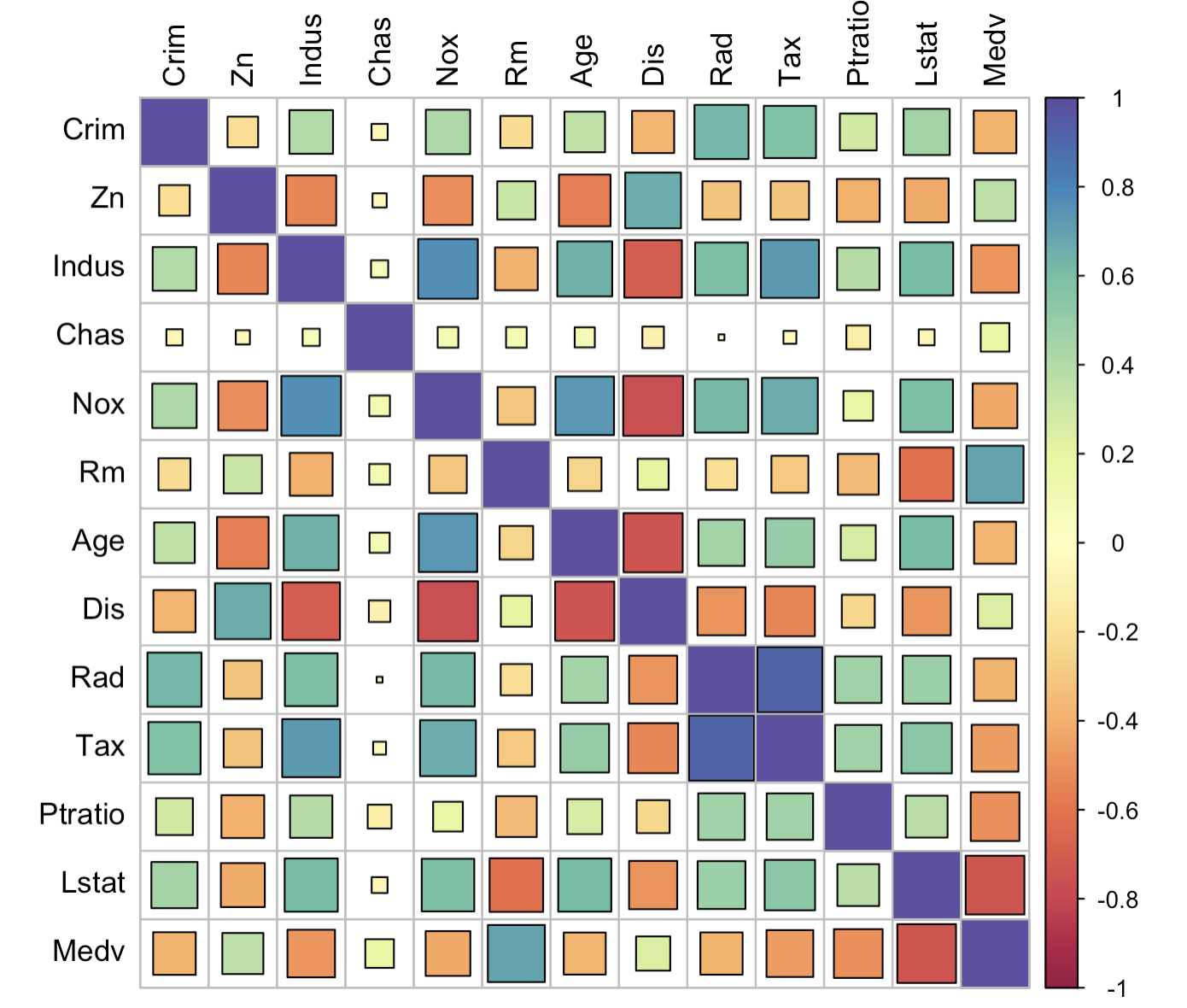
corrplot(corr = corr_data,
method = 'square',
col = colorRampPalette(colors = brewer.pal(11, "Spectral"))(200),
outline = TRUE,
tl.col = "black")
3-5:文字相关性热力图
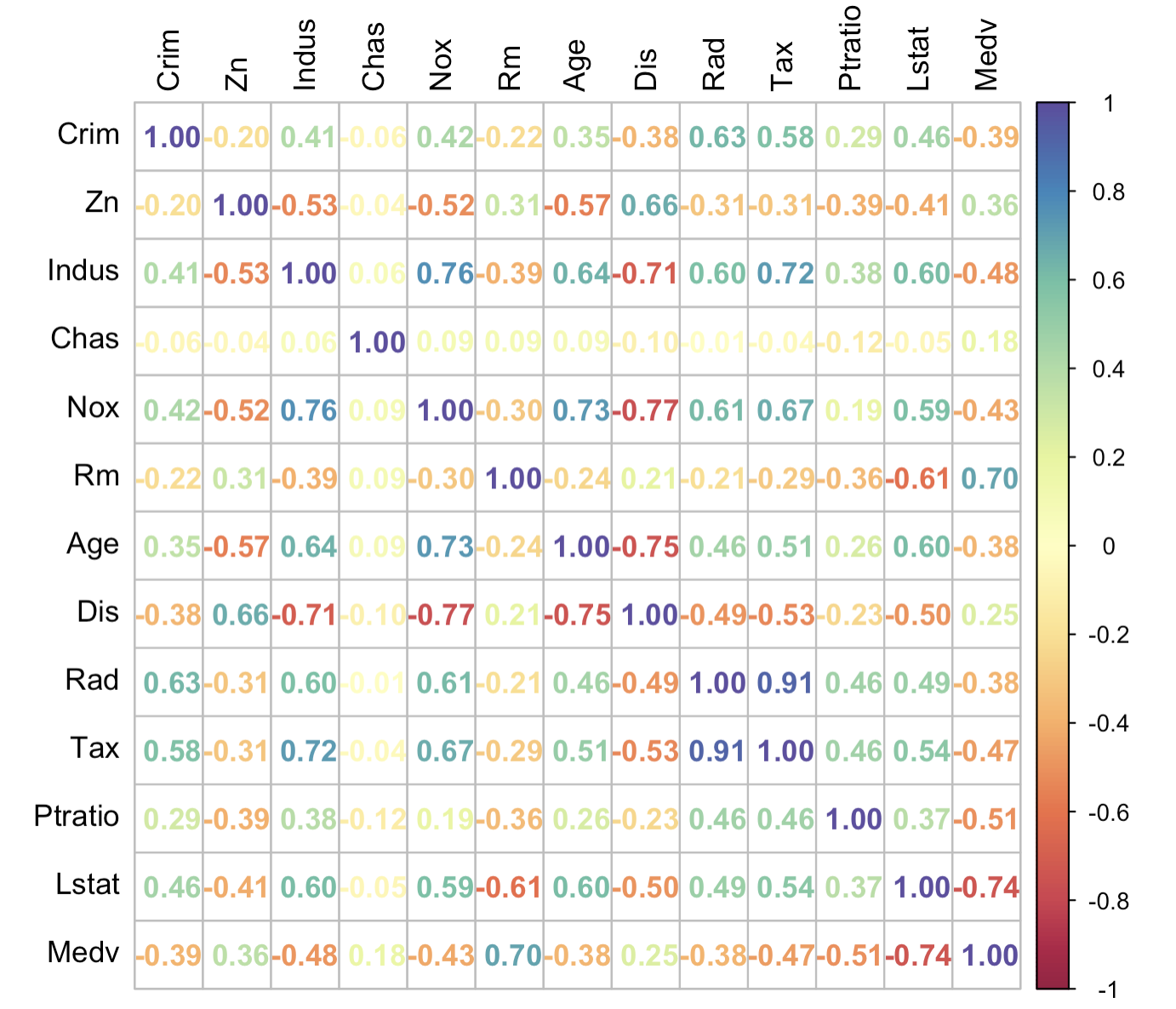
corrplot(corr = corr_data,
method = 'number',
col = colorRampPalette(colors = brewer.pal(11, "Spectral"))(200),
outline = TRUE,
tl.col = "black")
3-6:饼图相关性热力图
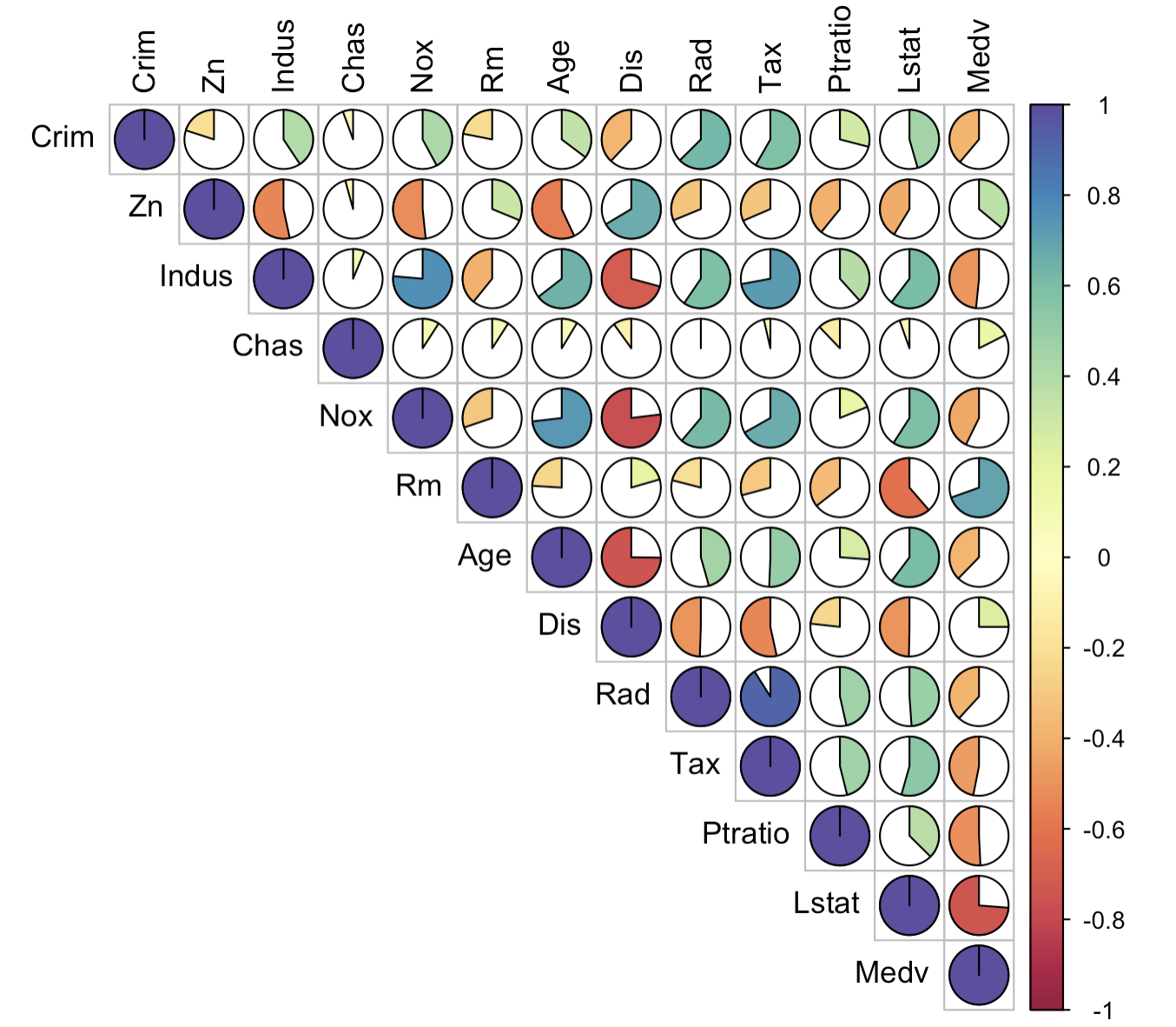
corrplot(corr = corr_data,
type = "upper",
method = 'pie',
col = colorRampPalette(colors = brewer.pal(11, "Spectral"))(200),
outline = TRUE,
tl.col = "black")
3-7:右上角带阴影相关性热力图
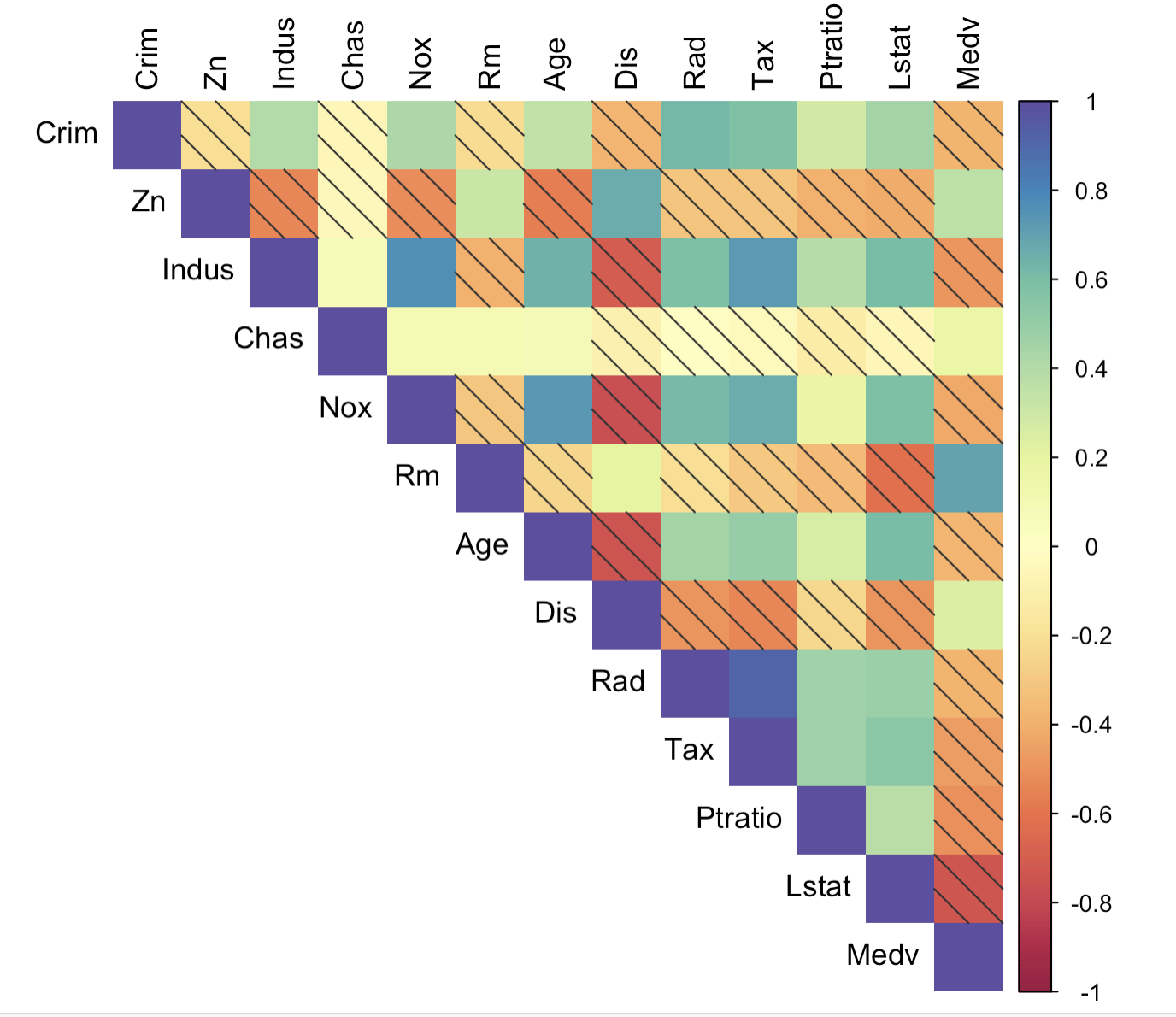
corrplot(corr = corr_data,
type = "upper",
method = 'shade',
col = colorRampPalette(colors = brewer.pal(11, "Spectral"))(200),
outline = TRUE,
tl.col = "black",
shade.col = "grey20")
3-8:阴影+饼图组合相关性热力图
这个比较粗糙,要想更美观,还需要再微调
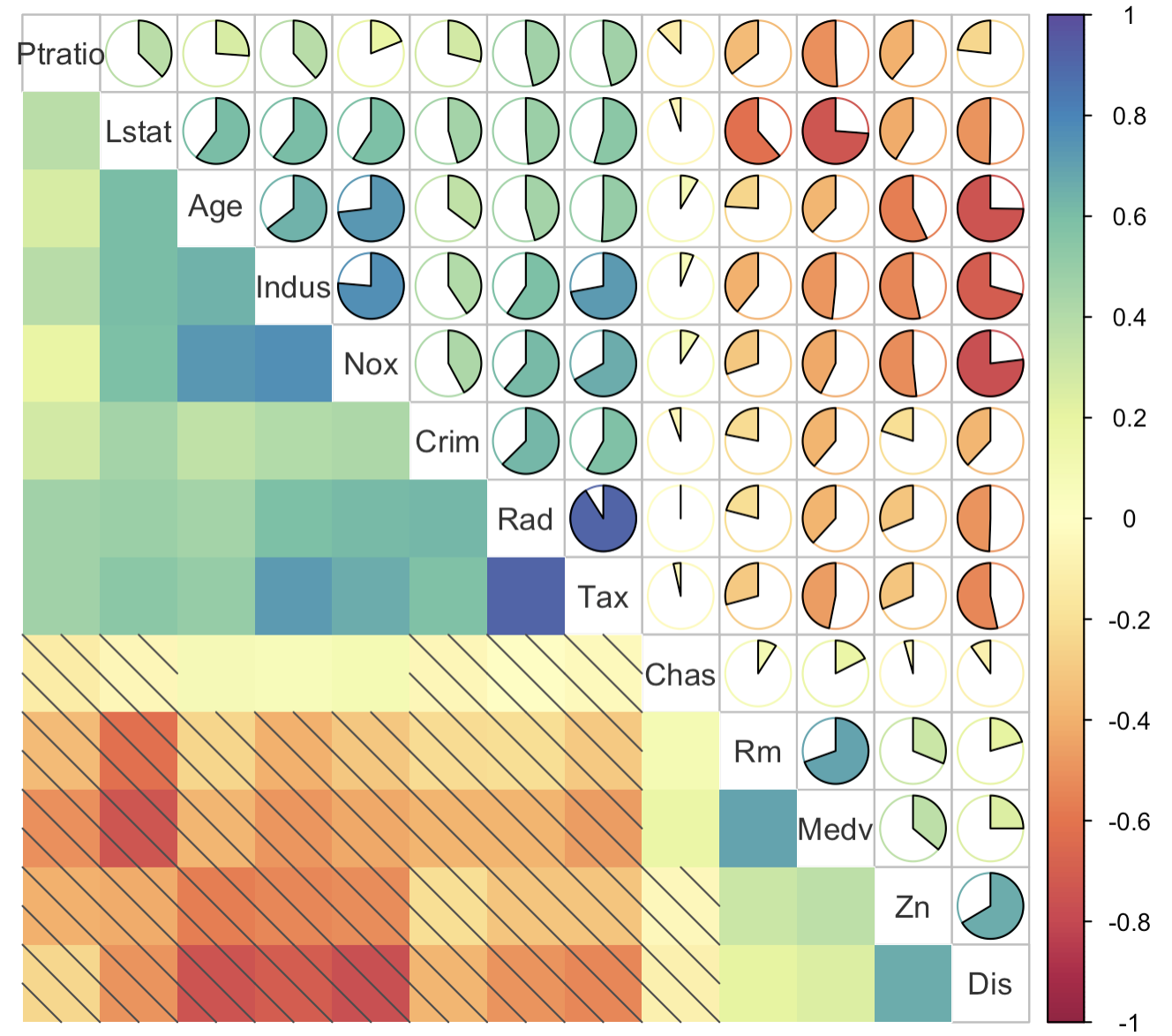
corrplot.mixed(corr = corr_data,
lower = 'shade',
upper = 'pie',
order = 'hclust',
lower.col = colorRampPalette(colors = brewer.pal(11, "Spectral"))(200),
upper.col = colorRampPalette(colors = brewer.pal(11, "Spectral"))(200),
tl.col = "grey20",
shade.col = "grey30")
3-9:圆形+方块组合相关性热力图
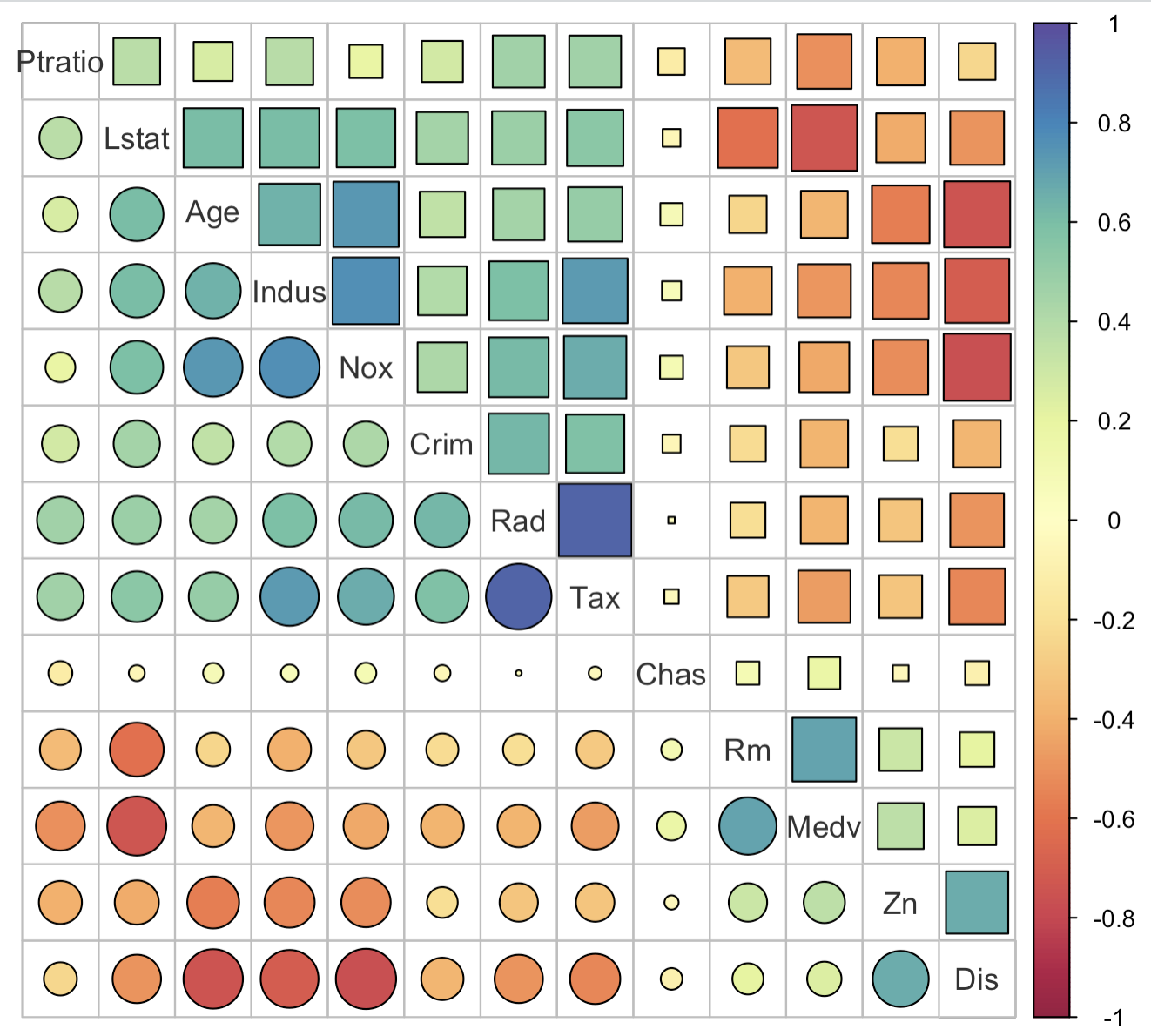
corrplot.mixed(corr = corr_data,
lower = 'circle',
upper = 'square',
order = 'hclust',
lower.col = colorRampPalette(colors = brewer.pal(11, "Spectral"))(200),
upper.col = colorRampPalette(colors = brewer.pal(11, "Spectral"))(200),
tl.col = "grey20",
outline = TRUE)
3-10:文字+椭圆组合相关性热力图
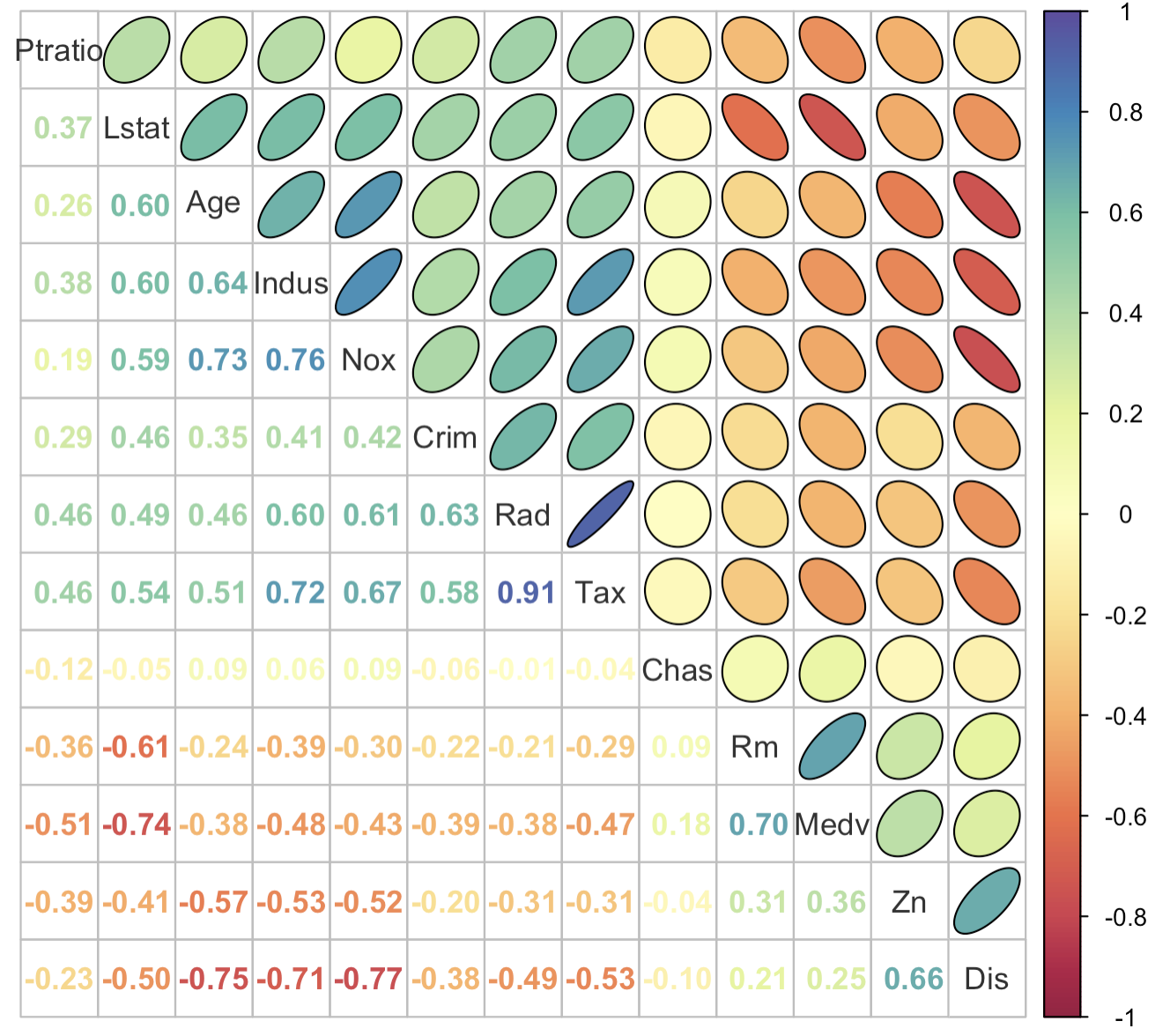
corrplot.mixed(corr = corr_data,
lower = 'number',
upper = 'ellipse',
order = 'hclust',
lower.col = colorRampPalette(colors = brewer.pal(11, "Spectral"))(200),
upper.col = colorRampPalette(colors = brewer.pal(11, "Spectral"))(200),
tl.col = "grey20",
outline = TRUE)
四、显著性分析
4-1:显著性分析的定义
显著性分析是一种统计方法,用于确定研究结果是否具有统计学意义,即结果是否不太可能仅仅是由随机变化引起的。这通常涉及到对数据进行假设检验(hypothesis testing),以确定观察到的效果或差异是否显著,超出了随机误差的范围。
显著性分析是科学研究中不可或缺的一部分,它帮助研究者判断他们的发现是否可信,以及是否可以推广到更大的群体。
然而,它也受到了一些批评,比如过分依赖P值可能导致对研究结果的误解。因此,研究者也被鼓励报告效应量和置信区间,以提供更全面的统计分析。
4-2:绘制带有显著性标记的相关性热图
在第三部分,小罗介绍了如何使用corrplot包来绘制带有显著性标记的相关性热图。在这一节,我们可以通过设置p.mat参数来指定显著性矩阵,从而在热图中标记显著性差异。
加载包
library(corrplot)
加载数据集
data(mtcars)
head(mtcars)
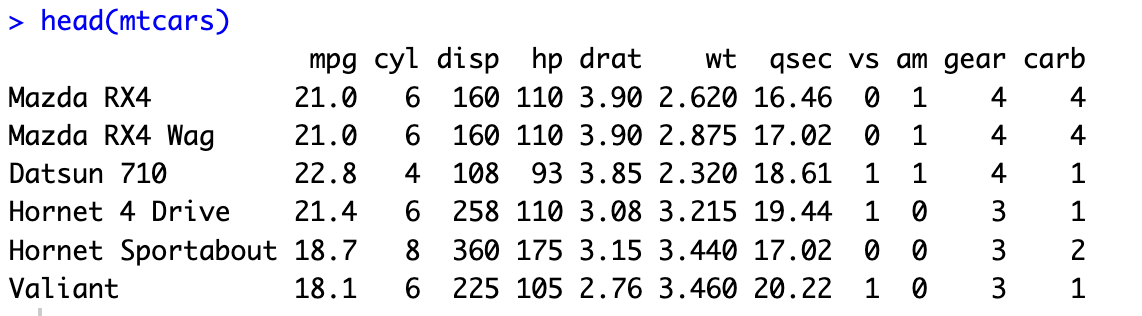
计算相关系数
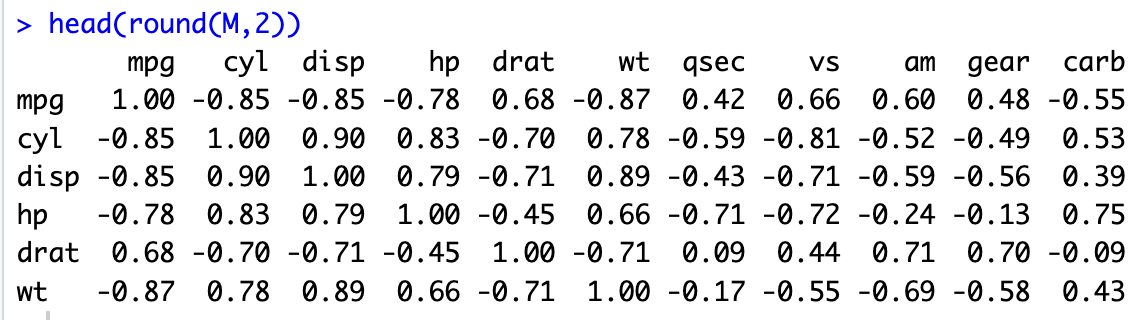
M<-cor(mtcars)
head(round(M,2))
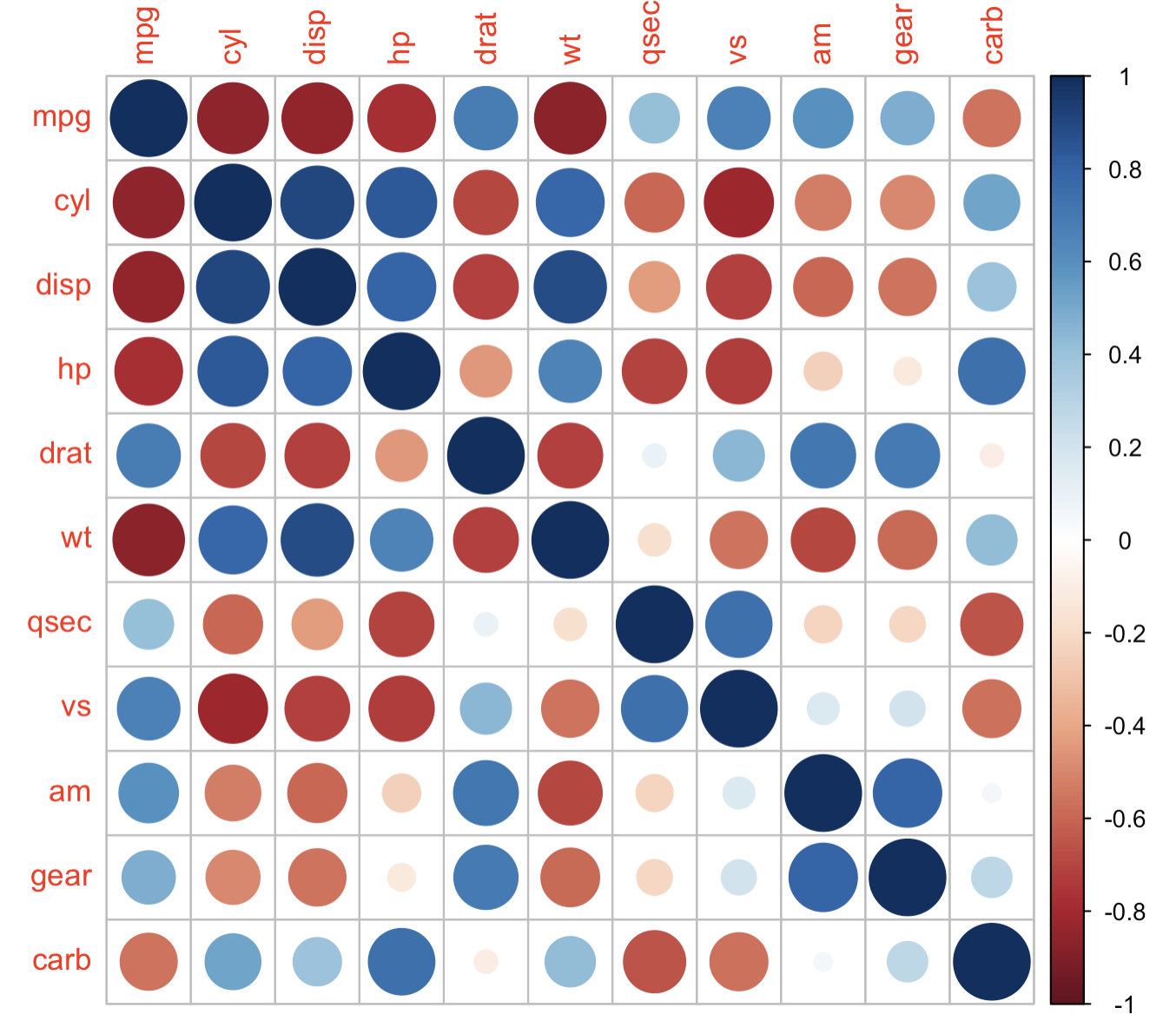
基础可视化
我们第三部分介绍了10种不同的方式,这里选择最基础的一种。
corrplot(M, method="circle")
计算显著性差异
# mat : is a matrix of data
# ... : further arguments to pass to the native R cor.test function
cor.mtest <- function(mat, ...) {
mat <- as.matrix(mat)
n <- ncol(mat)
p.mat<- matrix(NA, n, n)
diag(p.mat) <- 0
for (i in 1:(n - 1)) {
for (j in (i + 1):n) {
tmp <- cor.test(mat[, i], mat[, j], ...)
p.mat[i, j] <- p.mat[j, i] <- tmp$p.value
}
}
colnames(p.mat) <- rownames(p.mat) <- colnames(mat)
p.mat
}
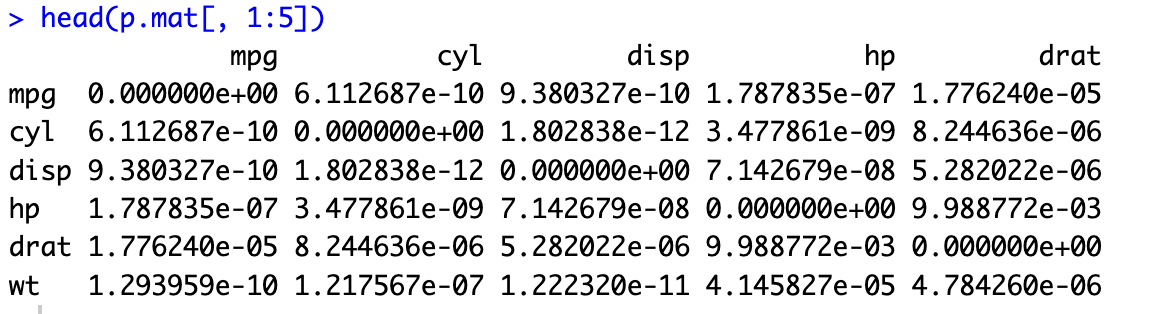
# matrix of the p-value of the correlation
p.mat <- cor.mtest(mtcars)
head(p.mat[, 1:5])
添加显著性标记
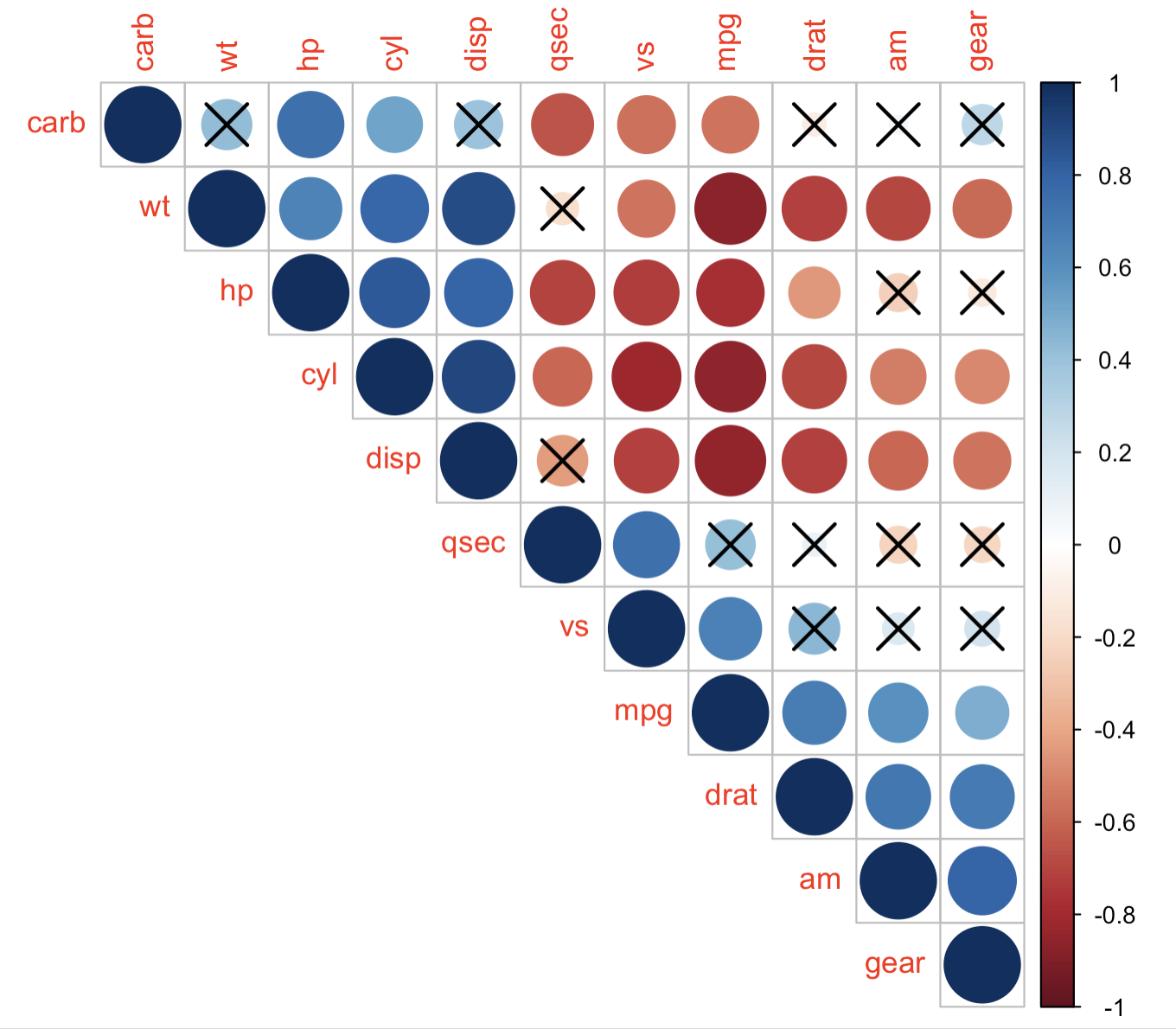
# 对不显著的结果打叉
corrplot(M, type="upper", order="hclust",
p.mat = p.mat, sig.level = 0.01)

# 不显示不显著的结果,也就是对非显著性结果不标记颜色
corrplot(M, type="upper", order="hclust",
p.mat = p.mat, sig.level = 0.01, insig = "blank")
个性化设置
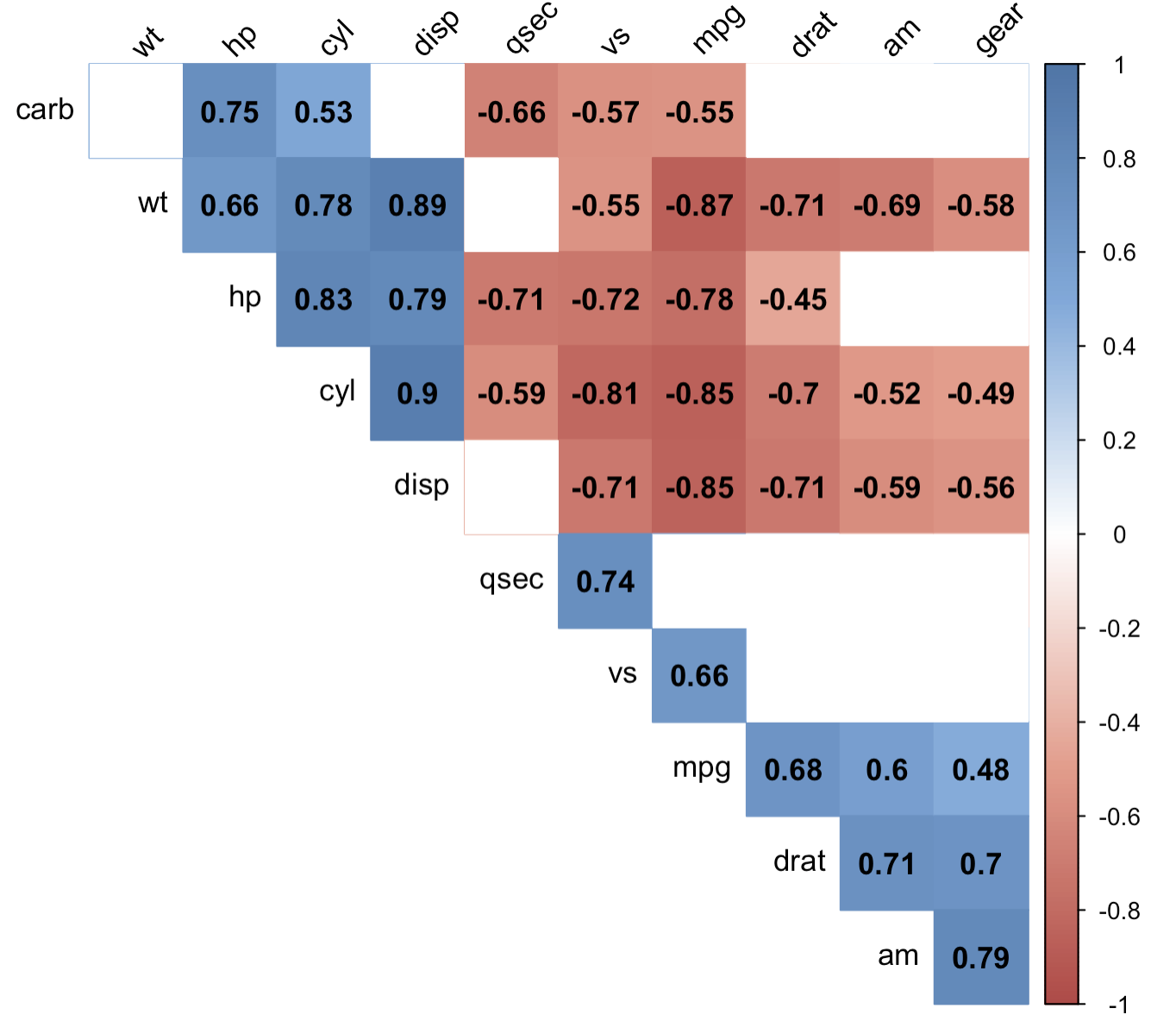
col <- colorRampPalette(c("#BB4444", "#EE9988", "#FFFFFF", "#77AADD", "#4477AA"))
corrplot(M, method="color", col=col(200),
type="upper", order="hclust",
addCoef.col = "black", # Add coefficient of correlation
tl.col="black", tl.srt=45, #Text label color and rotation
# Combine with significance
p.mat = p.mat, sig.level = 0.01, insig = "blank",
# hide correlation coefficient on the principal diagonal
diag=FALSE
)
参考资料
https://mp.weixin.qq.com/s/ybrSR3trhoUxMNUjHACgeg
https://mp.weixin.qq.com/s/ca5s3cNYeM4iC6o1iZSG0A

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









