







小罗碎碎念
文献日推主题:人工智能在医学图像分割中的最新研究进展
今天这期文章信息量很大,并且不同的人看,获取的信息量也会差距很大。为了缩小这个差距,请在正式阅读前,记住小罗的一句话——模型学会了如何分割图像,就意味着这个模型极大概率学会了如何生成图像。
今天的文献不局限于肿瘤,例如第三篇文献是眼科相关的,第四篇是与肺病相关的;之前一直看小罗推文的,对病理切片的虚拟染色和虚拟生成(HE 2 IHC)还有点印象的话,那么你看到今天的第二、三篇文献就会很亲切,虽然讲的是影像,但是处处都能联系到病理。
还有第六篇文献,准确的说算是一个大佬的评价,提到了两种关于AI模型可解释性的方法。这六篇文章都挺有意思的,不多剧透了,哈哈。

一、EfficientQ:深度学习模型量化的新方法

一作&通讯
| 角色 | 姓名 | 单位(中文) |
|---|---|---|
| 第一作者 | 张荣昭 (Rongzhao Zhang) | 香港科技大学计算机科学与工程系 |
| 通讯作者 | 钟Albert C.S. Chung | 香港科技大学计算机科学与工程系 |
文献概述
EfficientQ:一种高效的后训练量化方法,用于加速和压缩医学图像分割的深度神经网络,同时保持高准确性。
研究背景
深度神经网络已成为医学图像分析领域的关键技术,尤其在智能医疗保健系统中扮演着重要角色。
然而,这些网络模型往往计算量大、模型庞大,限制了它们在资源受限的环境中的部署。模型量化技术通过降低模型的计算位宽,能够在不显著损失性能的情况下,显著减少模型大小和加速推理过程,对于推动深度学习模型在医疗设备和边缘计算设备上的应用具有重要意义。
研究方法
文章提出了EfficientQ,一种新颖的后训练量化方法,专门针对医学图像分割任务。
EfficientQ采用了层间优化策略,并结合了交替方向乘子法(ADMM)算法来快速收敛。
此外,研究者还引入了权重正则化和自适应注意力机制,以提高量化模型的性能和解决医学图像分割中的类别不平衡问题。
实验设计
实验使用了两个公开的医学图像分割数据集:LiTS(肝脏肿瘤分割)和BraTS2020(多模态脑肿瘤分割)。
研究者构建了基于3D UNet的高性能分割模型作为全精度(FP)基线,并在这些数据集上对EfficientQ进行了评估。
实验包括与现有后训练量化方法的比较,以及对不同量化位宽(包括2位权重量化和4位量化)下的性能评估。
结果与分析
EfficientQ在不同量化位宽下均展现出优越的性能,特别是在2位量化情况下,其分割性能显著优于现有的后训练量化方法。
此外,EfficientQ在量化过程中展现出极高的效率,只需不到5分钟的时间即可完成量化,显著快于基于梯度下降的量化方法。
消融实验进一步证明了权重正则化和自适应注意力机制在提升量化模型性能方面的作用。
总体结论
EfficientQ是一种高效、准确的神经网络量化方法,适用于医学图像分割任务。
它通过创新的优化策略和算法改进,实现了在保持高性能的同时显著减少量化时间,为医学图像分析领域提供了一种实用的模型压缩和加速解决方案。
这项工作不仅推动了量化技术在医学图像分析中的应用,也为未来在资源受限环境下部署深度学习模型提供了新的可能性。
重点关注
Fig. 1 展示了整体的量化流程图。
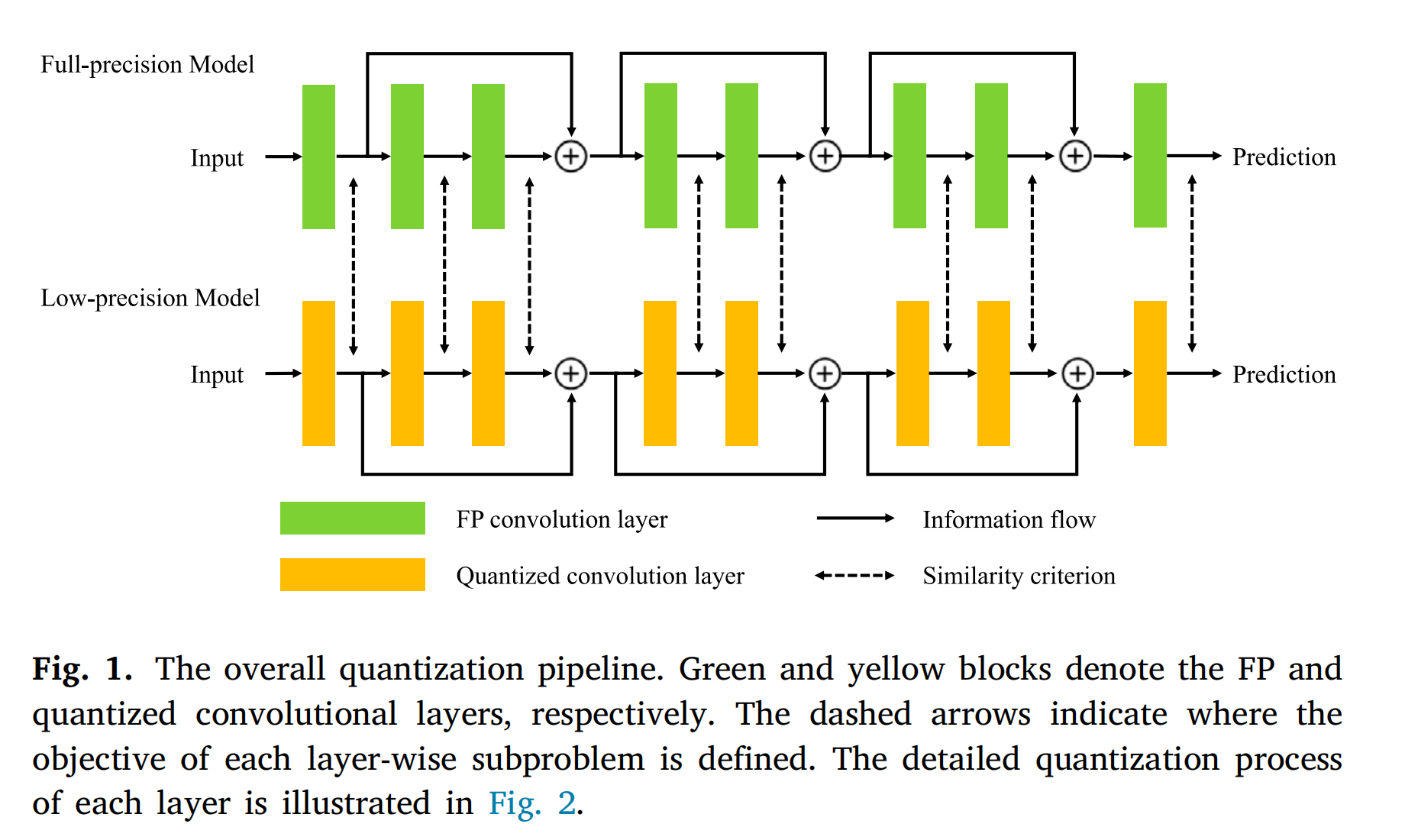
其中绿色和黄色块分别代表全精度(Floating Point, FP)和量化后的卷积层。虚线箭头指示了每一层量化子问题目标的定义位置。每一层的详细量化过程则在Fig. 2中展示。
- 量化流程图的组成:图中的绿色块代表原始的全精度模型中的层,而黄色块则代表经过量化处理后的层。量化是将全精度参数转换为低精度表示的过程,旨在减少模型的内存占用和加速计算。
- 层间关系:图中的层状结构表明量化是逐层进行的,每一层的量化都是独立处理的。这种层间优化策略简化了量化问题,因为它将整个复杂网络的量化分解为多个更小的、更易于管理的子问题。
- 目标定义:虚线箭头可能表示数据流或控制流,指向量化子问题目标被定义的位置。这意味着在量化流程中,每一层的输出都与原始全精度模型的输出有一个目标函数,用于指导量化过程,确保量化后的层能够尽可能地保持原始层的功能。
- 量化的目的:整个量化流程的目的是为了在保持模型性能的同时减少模型大小和提高推理速度,这对于在资源受限的设备上部署深度学习模型尤为重要。
- 量化方法:EfficientQ方法利用了交替方向乘子法(ADMM)来解决量化问题,这通常意味着量化过程中会有快速的收敛和较少的迭代次数。
- 量化的挑战:量化过程需要平衡模型的压缩率和模型性能,尤其是在医学图像分割这样对准确性要求极高的应用中。
综上所述,Fig. 1 提供了EfficientQ量化方法的整体视图,揭示了量化过程中的关键步骤和组件,以及量化的目标和方法。
二、MoDATTS:一种用于改善跨模态肿瘤分割的图像级监督与自我训练框架

一作&通讯
| 角色 | 姓名 | 单位名称(中文) | 单位名称(英文) |
|---|---|---|---|
| 第一作者 | Malo Alefsen de Boisredon d’Assier | 蒙特利尔综合理工学院 | Polytechnique Montreal |
| 第一作者(共同) | Aloys Portafaix | 蒙特利尔大学附属医院研究中心 | Centre de Recherche du Centre Hospitalier de l’Université de Montréal |
| 通讯作者 | Samuel Kadoury | 蒙特利尔综合理工学院 | Polytechnique Montreal |
文献概述
这篇文章提出了一种新的半监督学习方法MoDATTS,通过跨模态图像翻译和自我训练策略,显著提高了医学图像中肿瘤分割的准确性和泛化能力。
研究背景
医学图像分割是疾病诊断和治疗规划中的关键步骤。
深度神经网络在自动化医学图像分割方面表现出色,但现有模型在不同成像模态间泛化时常常表现不佳。
这一问题因目标模态上标注数据的有限性而变得更加突出,特别是在源模态和目标模态上都缺乏数据时,这限制了模型在更广泛场景中的部署。
研究方法
为了克服这一挑战,研究提出了MoDATTS,一种新的半监督训练策略,专门设计用于处理未配对的双模态数据集上的准确跨模态3D肿瘤分割。
该方法包括两个主要阶段:
- 图像到图像的翻译策略:在不同模态之间生成合成但带有标注的图像和标签,以改善对未标注目标模态的泛化。
- 迭代自我训练过程:通过在分割任务中引入半监督目标,进一步缩小模态间的域差距,并在目标模态的未标注图像上进行训练。
此外,MoDATTS利用强大的视觉变换器架构来增强图像翻译和分割任务,并引入了图像级标签的半监督目标,以鼓励模型从背景中分离出肿瘤。
实验设计
研究使用了两个公共挑战的数据集进行评估:BraTS 2020和CrossMoDA 2022。
实验设计包括数据预处理、肿瘤感知的跨模态翻译、半监督目标模态分割以及迭代自我训练。
使用了多种评估指标,包括Dice分数和平均对称表面距离(ASSD),来定量评估跨模态分割任务的性能。
结果与分析
MoDATTS在CrossMoDA 2022的前庭神经鞘瘤(VS)分割挑战赛中取得了优异的性能,报告的Dice分数为0.87±0.04。
在BraTS 2020数据集上,MoDATTS在不同模态对的实验中均优于基线方法,平均达到了目标全监督模型性能的95%。
此外,即使在源模态上只有1%的像素级标注可用时,半监督变体的MoDATTS仍能保持与全监督模型相当的性能。
总体结论
MoDATTS证明了其作为一种强大的跨模态医学图像分割工具的有效性,特别是在目标模态缺乏标注样本的情况下。
该方法通过半监督学习和自我训练策略显著减少了对大量标注数据的依赖,同时保持了高分割性能。研究还展示了通过添加目标模态的标注可以进一步提高性能,同时减轻了对源模态标注的负担。
这些发现表明,MoDATTS有潜力在减少人工标注需求的同时,提高医学图像分割的准确性和效率。
重点关注
图1提供了MoDATTS方法的概览,展示了其两个主要阶段:
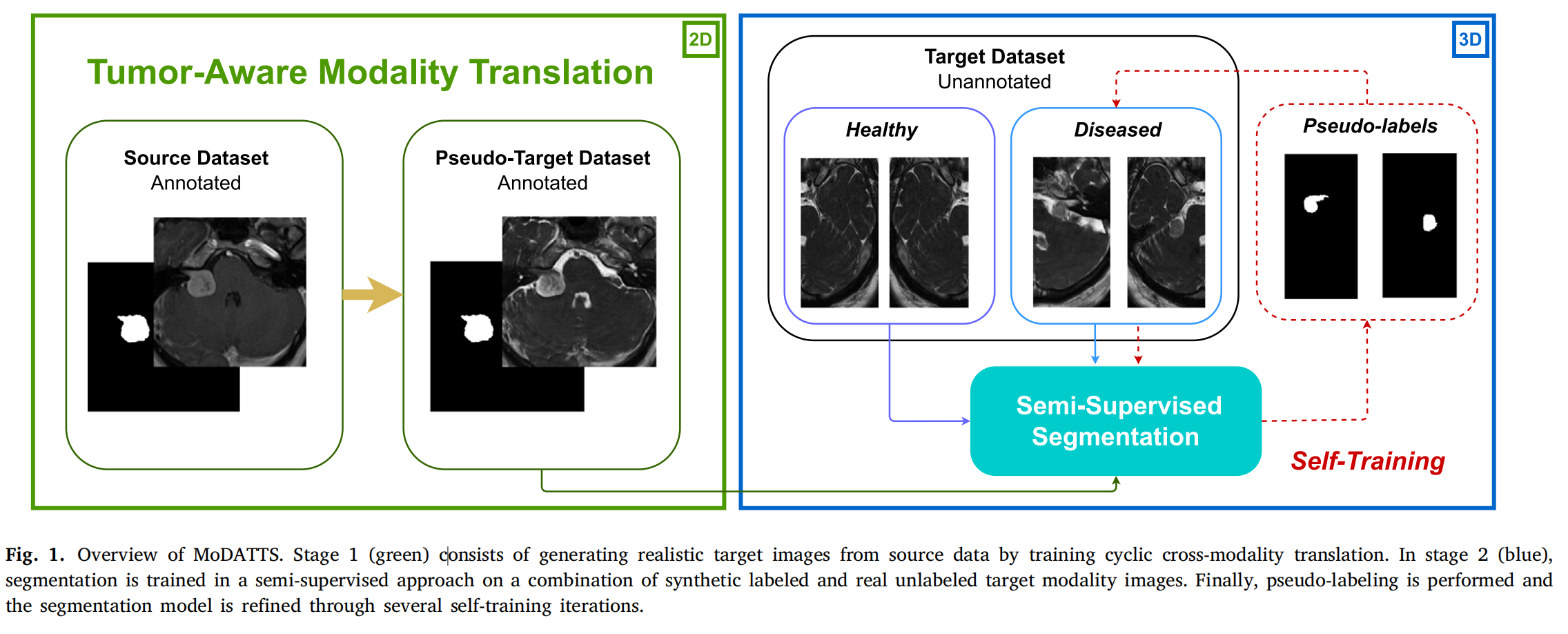
第一阶段:跨模态图像翻译(绿色部分)
在第一阶段,目标是利用源数据生成逼真的目标模态图像。这一过程通过训练循环的跨模态翻译来实现,具体步骤包括:
- 使用源模态数据(例如,一种类型的医学图像)。
- 训练一个循环一致的翻译模型,该模型能够在不同成像模态间转换图像,同时保持内容的一致性。
- 通过这种方式,可以在没有实际目标模态图像的情况下,生成合成的目标模态图像。
第二阶段:半监督分割训练(蓝色部分)
在第二阶段,进行的是半监督学习方法下的分割训练,具体步骤包括:
- 利用第一阶段生成的合成标注图像以及实际未标注的目标模态图像,训练分割模型。
- 这种方法结合了有标注的合成数据和无标注的实际数据,以提高模型对目标模态图像的分割性能。
- 通过半监督学习,模型能够从有限的标注数据中学习,并利用大量未标注数据进行知识扩展。
自我训练迭代(最后步骤)
在半监督训练之后,进行的是伪标签生成和自我训练迭代过程:
- 分割模型对未标注的目标模态图像进行预测,生成伪标签。
- 这些伪标签被用作额外的训练数据,进一步微调分割模型。
- 通过迭代的自我训练,模型的预测精度逐渐提高,最终达到更高的分割性能。
总体而言,MoDATTS方法通过这两个阶段和自我训练迭代,有效地利用了有限的标注数据和丰富的未标注数据,提高了模型在目标模态上的泛化能力和分割精度。
三、视网膜血管病变诊断革新:基于生物物理原理的深度生成模型
一作&通讯
| 角色 | 姓名 | 单位(中文) |
|---|---|---|
| 第一作者 | Emmeline E. Brown | 伦敦大学学院计算医学中心 |
| 通讯作者 | Simon Walker-Samuel | 伦敦大学学院计算医学中心及眼科研究所(伦敦大学学院) |
文献概述
这篇文章报道了一种基于物理信息生成对抗网络的新型算法,能够自动生成逼真的人类视网膜血管模型,并在无需人工标记的情况下实现血管网络的高精度分割和疾病模拟。
研究背景
视网膜血管的破坏与多种视力丧失疾病有关,如糖尿病视网膜病变和黄斑变性。
早期检测这些疾病对于预防视力丧失至关重要。然而,现有的手动图像分析方法在精确性和效率上存在限制。
因此,开发自动化的视网膜血管分析方法对于提高疾病检测和监测的效率具有重要意义。
研究方法
本研究提出了一种基于物理信息生成对抗网络(PI-GAN)的新算法,用于生成逼真的人类视网膜血管数字模型。
这种方法结合了生物物理原理和深度学习技术,特别是利用了Murray定律和流体动力学原理来模拟血管结构和血液流动。
实验设计
研究团队使用了两个公开的视网膜图像数据集(DRIVE和STARE)来训练和验证PI-GAN算法。
他们设计了一个小型模拟数据集(n=100),并在此基础上训练PI-GAN,以实现对视网膜血管网络的无人工输入分割和重建。
结果与分析
PI-GAN在分割视网膜血管方面表现出色,其性能接近或超越了现有的人工标记方法。
算法能够准确地模拟血管造影(FA)数据,并且能够模拟糖尿病视网膜病变和视网膜静脉阻塞等常见血管病理。
此外,PI-GAN还能够从临床图像中自动分割血管,且在高分辨率图像中识别小血管的能力超过了人工标记。
总体结论
PI-GAN作为一种新型的深度生成学习工具,在自动化视网膜血管分析方面展现出巨大的潜力。
它不仅能够提高血管分割的准确性和效率,还能够在无需大量手动标记数据的情况下进行训练。
这项技术的发展有望为早期疾病检测、疾病进展监测和改善患者护理提供重要的支持。
重点关注
Fig. 1 展示了本研究开发的物理信息生成对抗学习(PI-GAN)框架的示意图。
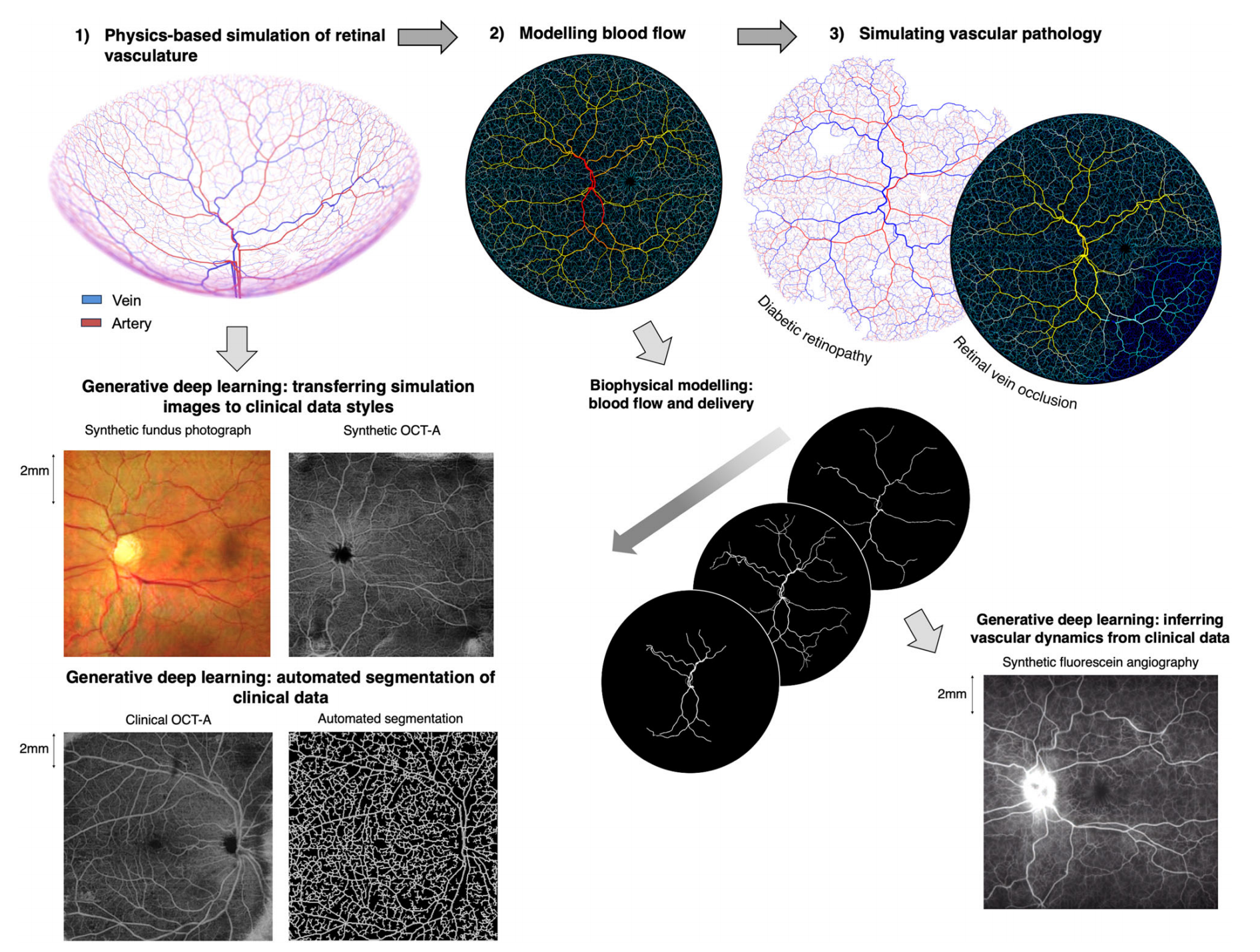
该框架模拟了具有动脉和静脉树的视网膜血管网络,这些血管树通过毛细血管床相连,并针对黄斑和视盘特征进行了特殊处理。
模拟使用的是基于Murray定律的空间填充生长算法。在合成血管网络中,使用一维泊肃叶流动模拟了血流和荧光素输送。
通过结合循环一致的物理信息深度生成学习,将血管模拟转换为合成医学图像数据(眼底摄影、光学相干断层扫描血管造影(OCT-A)和荧光素血管造影(FA)),并且使用相同训练过的网络在临床图像中检测血管。图像的比例尺以毫米(mm)给出。
四、新型图神经网络提升慢性阻塞性肺病气道分割的自动化精度

一作&通讯
| 角色 | 姓名 | 单位名称(中文) | 单位英文名称 |
|---|---|---|---|
| 第一作者 | 谢伟艺(Weiyi Xie) | 荷兰Radboudumc医学影像分析组,放射学与核医学科 | The Diagnostic Image Analysis Group, Department of Radiology and Nuclear Medicine, Radboudumc, Nijmegen, The Netherlands |
| 通讯作者 | 谢伟艺(Weiyi Xie) | 同上 | 同上 |
文献概述
这篇文章介绍了一种结构和位置感知的图神经网络方法,用于提高慢性阻塞性肺病(COPD)患者气道树分割的自动解剖标记精度。
研究背景
- 疾病重要性: 慢性阻塞性肺病(COPD)是全球主要的肺部疾病之一,也是导致慢性疾病和死亡的主要原因。
- 疾病特征: COPD的特征包括气道狭窄和重塑,评估这些特征对于评价疾病的严重程度和进展至关重要。
- 现有挑战: 传统的气道标记方法在处理不同患者间气道树结构的变异性、成像噪声和病理变化时存在局限性。
研究方法
- 方法创新: 提出了一种基于图的新型神经网络方法,用于自动标记气道树的解剖分支。
- 技术细节:
- 使用卷积神经网络(CNN)提取分支特征。
- 利用图神经网络(GNN)丰富特征,考虑局部邻居信息和节点在图中的位置信息。
- 引入了结构感知和位置感知的概念,增强了模型对气道树拓扑结构的理解。
实验设计
- 数据来源: 从COPDGene研究中获取了220个不同COPD严重程度患者的胸部CT扫描数据。
- 评估方法: 通过5折交叉验证来评估所提出方法的性能。
- 基线对比: 与标准CNN方法和现有方法进行比较。
- 阅读者研究: 进行了额外的阅读者研究,将算法结果与人类专家的标记进行比较。
结果与分析
- 性能提升: 所提出的SPGNN方法在分支分类准确率上显著优于基线方法,达到了91.18%。
- 计算效率: 方法在计算上高效,能够在平均17秒内处理一个案例。
- 消融研究: 通过消融研究验证了不同组件对性能的影响,包括GNN架构、层数、输入补丁大小和CNN架构。
- 可视化分析: 使用t-SNE可视化展示了学习到的特征和位置编码,分析了它们在特征空间中的分布。
总体结论
- 技术贡献: 提出的SPGNN方法在气道标记任务中表现出色,接近人类专家的性能水平。
- 临床意义: 该方法有助于自动化气道重塑的量化分析,对手术规划、患者分型和COPD进展监测具有潜在的应用价值。
- 未来方向: 尽管模型在性能上取得了成功,但在模型可解释性方面仍有改进空间,未来的工作可以进一步探索这一领域。
这篇文章展示了医学图像分析领域中深度学习技术的重要进展,特别是在处理具有复杂结构的医学数据方面。
重点关注
Fig. 1 提供了所提出的气道标记框架的概览。
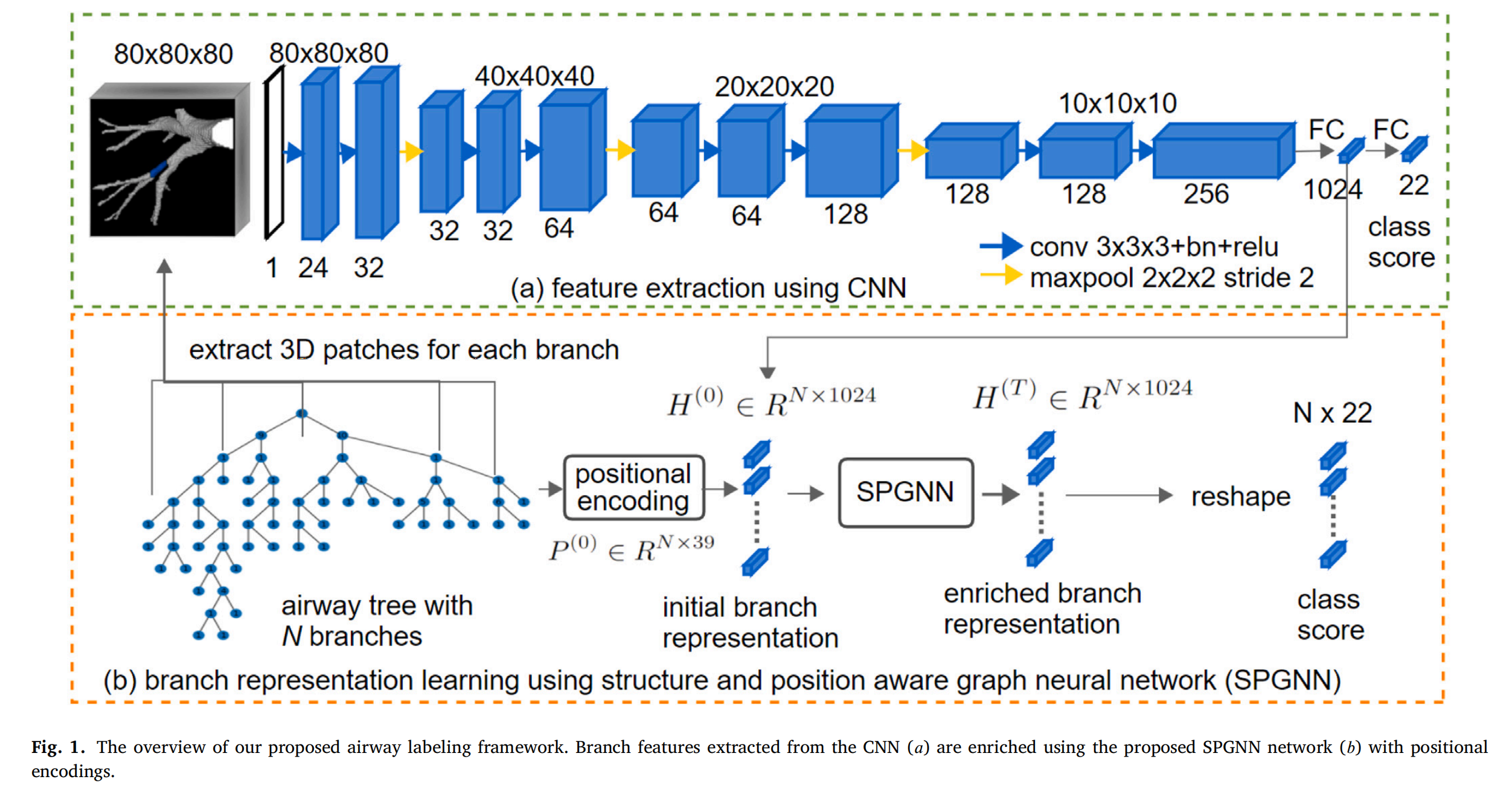
这个框架的核心思想是将气道标记问题转化为气道树图中分支的分类问题。
-
分支特征提取(𝑎): 初始步骤涉及使用卷积神经网络(CNN)从气道分割图中提取每个分支的特征。这些特征捕获了分支的形状和连接性信息,但不包括任何基于纹理的信息。CNN通过查看以分支中心为中心的3D补丁来实现这一点,其中分支中心是通过骨架化过程确定的。
-
SPGNN网络(𝑏): 提出的图神经网络(SPGNN)用于丰富CNN提取的分支特征。SPGNN是结构感知的,因为它让每个节点聚合来自其局部邻居的信息;同时它也是位置感知的,因为它在图中编码了节点的位置。
-
位置编码: SPGNN中的位置编码是每个节点到一组锚点(在气道树中定义的特定分支)的最短路径长度。这些编码提供了关于分支在气道树中相对位置的重要线索,有助于区分具有相似局部结构但位于树不同部分的分支。
-
特征丰富: SPGNN通过迭代地交换和收集来自相邻分支的信息来丰富分支特征。这允许每个分支的表示不仅包含其自身的特征,还包括其邻居的特征。
-
分支分类: 经过SPGNN处理后的特征被送入分类头,以产生最终的类概率,从而实现分支的分类。
-
框架优势: 该框架的优势在于它能够在保持计算效率的同时,利用气道树的全局结构信息来提高标记的准确性。
-
应用场景: 这种自动化的气道标记方法对于评估COPD等疾病的严重程度和进展至关重要,因为它可以提供对气道重塑的定量分析。
Fig. 1 中的框架图可能还包含了数据流、网络架构的详细视图以及关键步骤的可视化表示,以帮助读者更好地理解所提出方法的工作流程。
五、TransUNet:一种基于变换器优化的U-Net医学图像分割框架

一作&通讯
| 角色 | 姓名 | 单位名称(中文) |
|---|---|---|
| 第一作者 | Jieneng Chen | 约翰霍普金斯大学计算机科学系,巴尔的摩,MD,美国 |
| 通讯作者 | Yuyin Zhou | 加州大学圣克鲁斯分校计算机科学与工程系,CA,美国 |
文献概述
这篇文章提出了一种新的医学图像分割框架TransUNet,通过整合变换器架构优化了U-Net设计,显著提升了多器官分割和微小肿瘤检测的准确性。
研究背景
医学图像分割对于精准医疗至关重要,尤其是在癌症诊断和治疗规划中。
尽管现有的基于卷积神经网络(CNN)的U-Net架构在许多应用中表现出色,但它们在处理图像中的长距离依赖性方面存在局限性。
为了克服这一问题,研究者们开始探索将变换器(Transformer)集成到医学图像分割任务中,以利用其在捕捉全局上下文方面的能力。
研究方法
文章提出了TransUNet,这是一个新颖的框架,它将Transformer的自注意力机制整合到U-Net架构中。
TransUNet包含两个关键组件:
- Transformer编码器用于从CNN特征图中提取全局上下文
- Transformer解码器用于细化候选区域,通过交叉注意力机制与U-Net特征协同工作。
研究者们还引入了粗到细的注意力细化策略,以提高小目标(如肿瘤)的分割精度,并提供了2D和3D的实现,以适应不同的应用需求。
实验设计
研究者们在多个数据集上评估了TransUNet的性能,包括BTCV多器官分割数据集、BraTS2021脑肿瘤分割挑战、医学分割十年挑战(MSD)肝脏血管数据集,以及一个大规模的胰腺肿瘤数据集。
实验包括了与现有最先进方法的比较、不同配置的TransUNet的比较,以及对小目标分割能力的评估。
实验采用了严格的5折交叉验证方法,以确保结果的公正性和可靠性。
结果与分析
实验结果表明,TransUNet在多器官分割和胰腺肿瘤分割任务中取得了显著的性能提升。
特别是,与高度竞争的nn-UNet相比,TransUNet在多器官分割任务中实现了1.06%的平均Dice提升,在胰腺肿瘤分割任务中实现了4.30%的提升。此外,TransUNet在BraTS2021挑战中超越了第一名的解决方案。
分析表明,Transformer编码器在处理多器官交互方面表现出色,而Transformer解码器则在小目标分割方面显示出强大的能力。
总体结论
TransUNet通过整合Transformer的自注意力机制,有效地克服了传统CNN在医学图像分割中的局限性。
其灵活的框架设计和粗到细的注意力细化策略,使其在多种医学图像分割任务中表现出卓越的性能。这项研究不仅提供了一种新的医学图像分割方法,而且为未来在这一领域的研究提供了宝贵的见解和工具。
研究者们还公开了代码和模型,以鼓励进一步探索和应用Transformer在医学图像分析中的潜力。
重点关注
Fig. 1 展示了 TransUNet 的整体架构,它由两个主要部分组成:
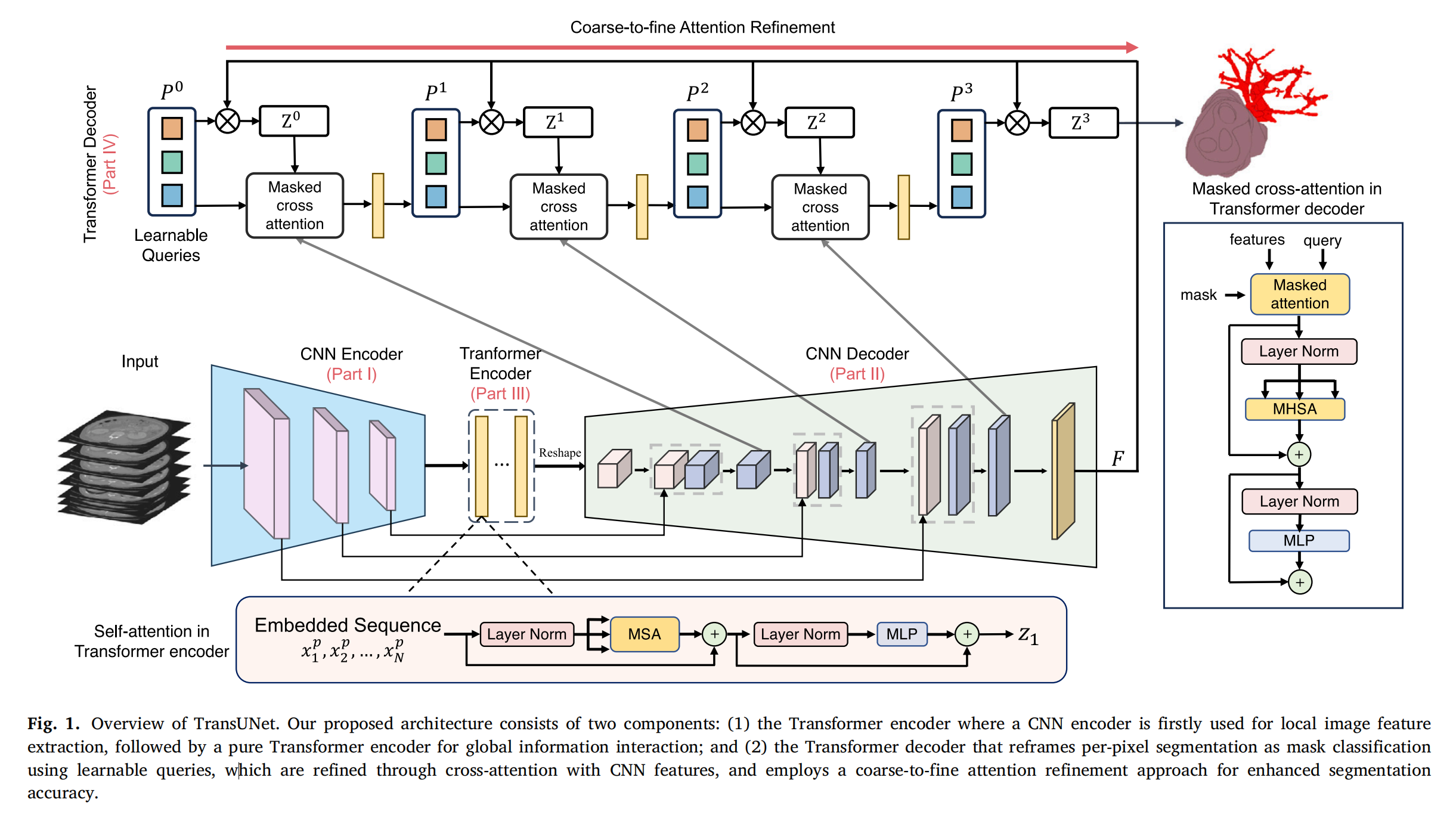
-
变换器编码器(Transformer Encoder):这一部分首先使用卷积神经网络(CNN)编码器对图像进行局部特征提取,然后采用纯变换器编码器对这些特征进行全局信息交互。在局部特征提取阶段,CNN 编码器专注于捕捉图像的细节和局部特征,而变换器编码器则进一步处理这些特征,通过其自注意力机制来捕捉全局上下文信息,从而实现对图像全局结构和关系的编码。
-
变换器解码器(Transformer Decoder):这一部分将传统的逐像素分割任务重新定义为掩码分类问题,使用可学习的查询(queries)来表示每个感兴趣的区域或对象。这些查询通过与CNN特征的交叉注意力机制进行细化,从而提高分割的精度。交叉注意力允许解码器专注于与每个查询最相关的CNN特征,从而实现更准确的区域定位。此外,变换器解码器采用了由粗到细(coarse-to-fine)的注意力细化方法,这意味着初始的粗略分割结果将用于引导后续的细化过程,逐步提高分割的精度和准确性,特别是在处理小目标或复杂结构时。
整体来看,TransUNet 的设计将 CNN 的局部特征提取能力和变换器的全局上下文建模能力相结合,通过精心设计的编码器-解码器框架,实现了对医学图像中细微结构的精确分割。这种设计特别适合于需要同时考虑局部细节和全局信息的复杂医学图像分割任务。
六、从黑箱到透明:生物成像中的深度学习模型解释性研究

一作&通讯
| 作者角色 | 作者姓名 | 单位(英文) | 单位(中文) |
|---|---|---|---|
| 第一作者 | Oded Rotem | Department of Software and Information Systems Engineering | 软件与信息系统工程系 |
| 通讯作者 | Assaf Zaritsky | Ben-Gurion University of the Negev, Be’er-Sheva, Israel | 以色列内盖夫本-古里安大学,贝尔谢巴 |
文献概述
这篇文章探讨了生物成像深度学习模型的可解释性,强调了在生物医学领域中提高模型透明度和促进科学发现的重要性。
研究背景
深度学习(DL)在生物成像分析中取得了巨大成功,但其模型的“黑箱”特性使得生物学家难以理解模型的决策过程。
这种依赖于复杂参数空间的模型在某些情况下超越了人类标准,但同时也带来了对模型透明度和可解释性的需求。
因此,可解释人工智能(XAI)领域应运而生,旨在提高模型的透明度,促进生物学的假设生成和数据驱动发现。
研究方法
文章通过文献综述的方法,探讨了XAI在生物成像中的应用现状和潜力。
作者分析了解释性和可解释性的概念差异,并强调了在生物成像中将模型解释转化为生物学上有意义的洞察的重要性。
此外,文章还讨论了信任建立、表型测量和细微表型的发现作为视觉解释深度学习模型的主要动机。
实验设计
文章没有进行实验设计,而是通过分析现有的XAI技术和方法,讨论了它们在生物成像中的应用。
作者重点讨论了基于显著性图和基于反事实的解释方法,以及它们如何帮助理解模型的决策过程和发现新的生物学现象。
结果与分析
文章分析了XAI在生物成像中的当前应用,包括局部和全局可解释性的重要性,以及如何通过解释模型的决策来提高模型的可信度和发现新的生物学机制。
作者指出,尽管XAI在生物成像中仍处于早期阶段,但其潜力巨大,能够通过提供对模型决策的深入理解来推动科学发现。
总体结论
文章得出的总体结论是,推进生物成像的XAI对于提高DL模型的可信度和促进新的生物学发现至关重要。
作者强调了发展更健壮、用户友好的视觉可解释性方法的必要性,并提出了未来研究的方向,包括图像到图像转换的可解释性、验证和测量视觉可解释性的方法、以及提高高维图像数据可解释性的挑战和机遇。
通过这些努力,XAI有望成为推动细胞生物学发展的有力工具。
重点关注
Fig. 2 展示了两种不同的深度学习模型解释方法:基于显著性图(Saliency map-based)的方法和基于反事实(Counterfactual-based)的方法。
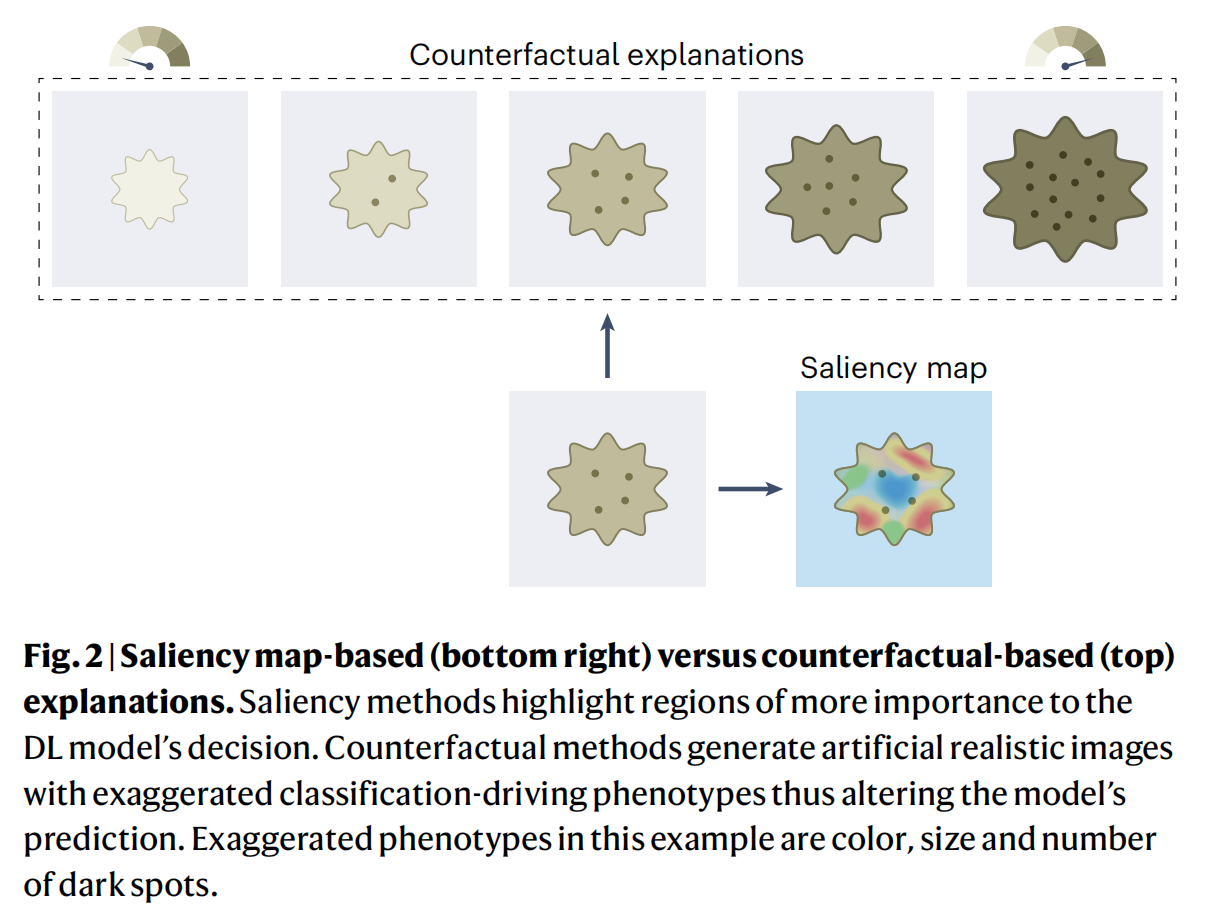
-
基于显著性图的方法(Saliency map-based):
- 这种方法通过生成“注意力图”来突出显示对深度学习(DL)模型决策最为重要的图像区域。
- 它通过为每个像素分配网络内部层的激活或梯度的累积来实现,从而识别出对单个预测贡献最大的区域。
- 显著性图方法适用于局部(实例)解释,因为它能够将视觉解释定位在图像中,并且不需要进一步的训练。
-
基于反事实的方法(Counterfactual-based):
- 这种方法使用生成模型人为地改变图像,同时保持图像的真实性,并改变模型的预测。
- 它通过优化低维潜在表示空间来生成图像,这个空间可以用来生成感兴趣的实体的图像。
- 通过在潜在空间中的遍历,可以生成沿着特定方向的视觉反事实解释,这些方向在图像空间中转化为表型的改变。
- 反事实解释特别适合于识别非局部的视觉解释,例如形状或颜色的变化,并能够通过夸张分类驱动的表型来帮助理解细微的表型差异。
在给出的例子中,夸张的表型特征包括颜色、大小和暗斑的数量。基于反事实的方法通过生成具有夸张特征的人工真实图像,改变了模型的预测,这有助于揭示模型是如何根据这些特征进行分类的。
这种夸张可以帮助研究者理解模型预测背后的逻辑,以及这些特征对模型决策的影响。通过这种方式,研究者可以更好地解释模型的行为,提高模型的透明度,并可能发现新的生物学见解。


















 1533
1533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









