







小罗碎碎念
一、箱线图定义
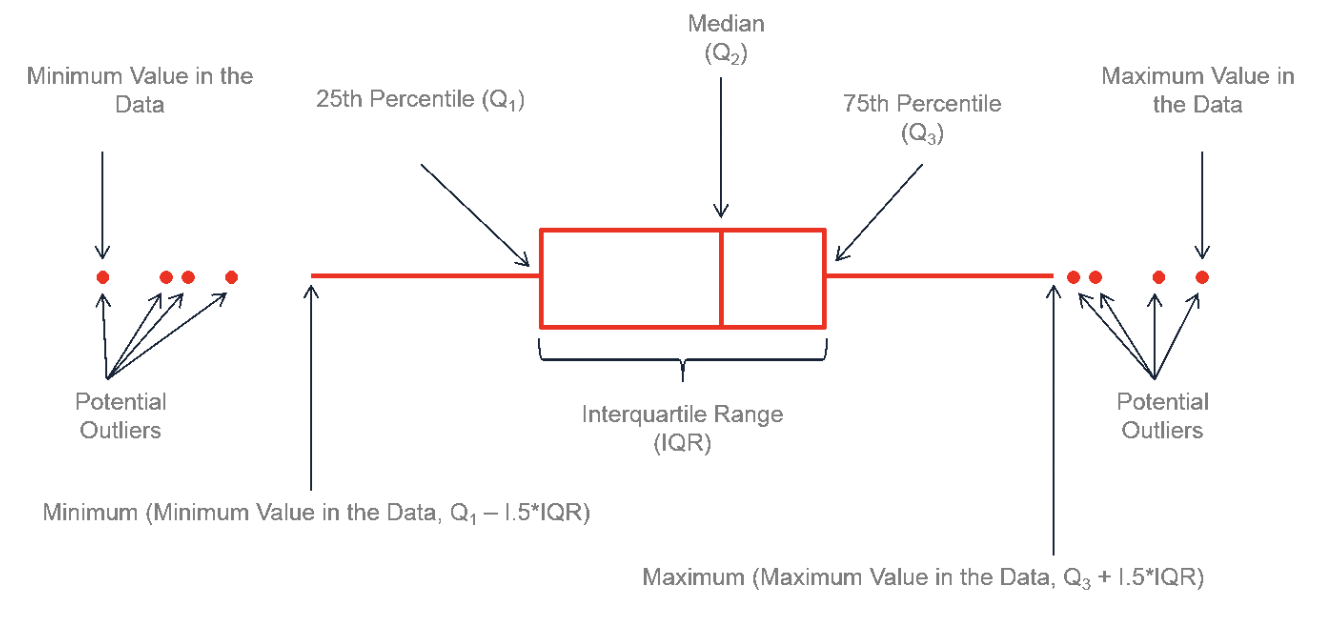
箱线图(Boxplot)为一种有效的数值变量总结工具,它由以下几个核心元素构成:
- 将箱体一分为二的线条代表数据的中位数。例如,中位数为10时,表明低于和高于10的数据点数量相等。
- 箱体的两端分别显示数据的上四分位数(Q3)和下四分位数(Q1)。若第三四分位数为15,则意味着75%的观测值低于15。
- 第一和第三四分位数之间的差值定义为四分位距(Interquartile Range, IQR)。
- 箱线图外的极端线展示Q3+1.5×IQR至Q1-1.5×IQR的范围(除去异常值的最小和最大值)。
- 位于极端线之外的点(或其他标记)表示潜在的异常值。
以下图表展示了箱线图的组成结构:
二、信息的丢失
箱线图能够对多个组别的数值变量分布进行总结。然而,总结的同时也意味着信息的丢失,这可能会成为分析的陷阱。
# Libraries
library(tidyverse)
library(hrbrthemes)
library(viridis)
library(plotly)
# create a dataset
data <- data.frame(
name=c( rep("A",500), rep("B",500), rep("B",500), rep("C",20), rep('D', 100) ),
value=c( rnorm(500, 10, 5), rnorm(500, 13, 1), rnorm(500, 18, 1), rnorm(20, 25, 4), rnorm(100, 12, 1) )
)
# Plot
data %>%
ggplot( aes(x=name, y=value, fill=name)) +
geom_boxplot() +
scale_fill_viridis(discrete = TRUE) +
theme_ipsum() +
theme(
legend.position="none",
plot.title = element_text(size=11)
) +
ggtitle("A somewhat misleading boxplot") +
xlab("")
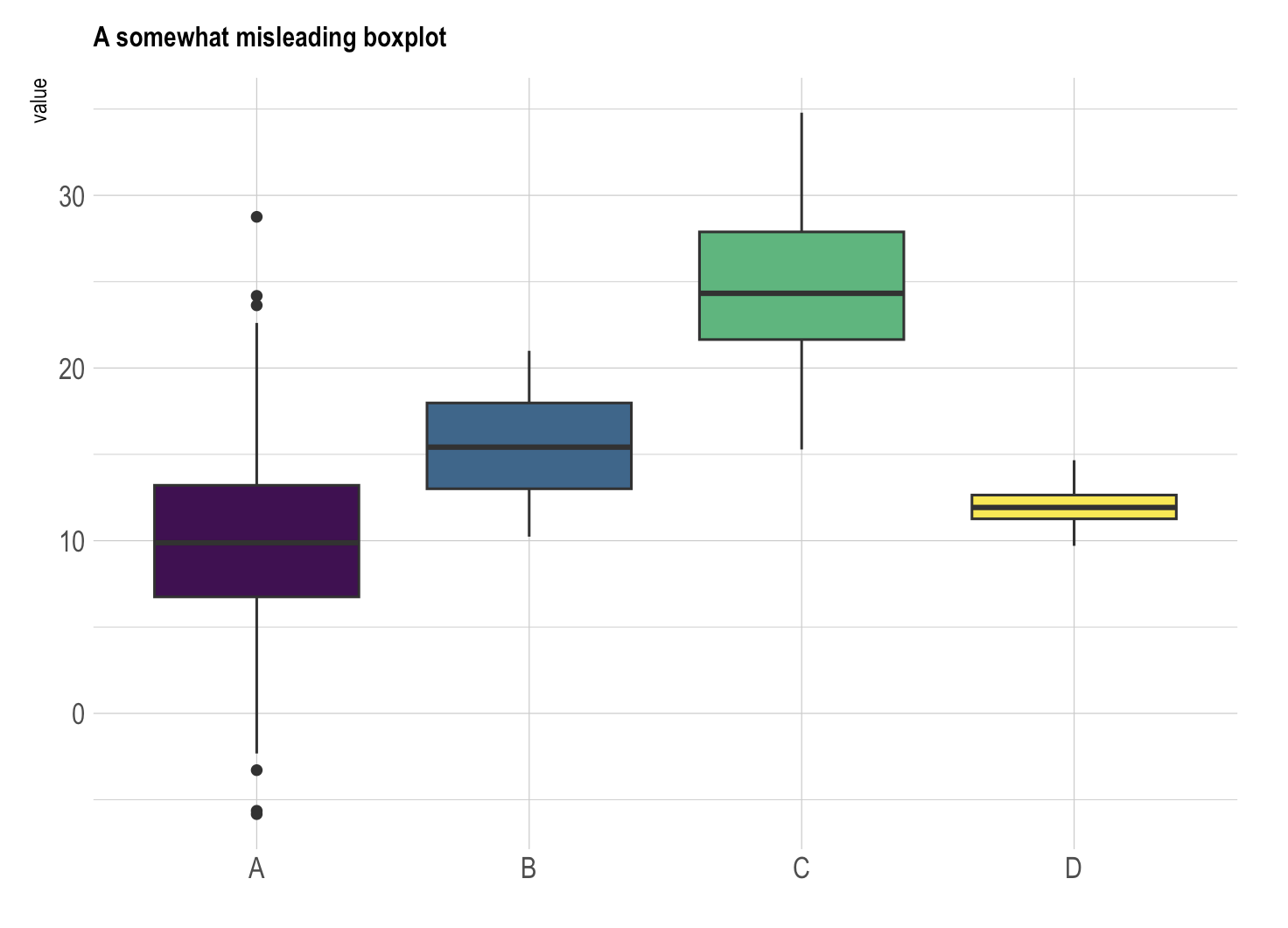
通过上面这个箱线图,我们可能会轻易得出结论:组别C的数值高于其他组别。但是,箱线图无法展示每个组别中数据点的具体分布情况,也无法显示各组别的观测数量。
因此,尽管箱线图在比较组间统计特性时具有直观优势,但它隐藏了数据的详细分布和样本大小,这可能导致对数据真实情况的不准确理解。在解读箱线图时,必须考虑到这些潜在的信息损失,并可能需要结合其他统计图表或方法来获取更全面的数据分析。
接下来,我们增加一些额外的元素,来探索一下还能从箱线图获取的信息。
三、添加抖动
在数据量不是非常大的情况下,在箱线图上添加抖动(jitter)可以使图形更具洞察力。
抖动通过在原有数据点上添加小的随机扰动,使得原本可能会重叠的数据点在视觉上分离,从而揭示出每个数据点的实际位置。这种方法可以在不丧失箱线图原有概括性的同时,提供以下额外信息:
- 数据点的密集程度:通过抖动点的分布,可以直观地观察到各组数据点的密集程度,进而对数据的分布形态有更深入的了解。
- 观测数量:抖动点数量的多少可以反映出各组别中观测值的数量,帮助观察者评估组间样本大小的差异。
- 异常值的识别:抖动有助于更清晰地识别出潜在的异常值,尤其是在数据点较为密集的区域。
因此,通过在箱线图上添加抖动,可以增强图表的信息量,使其在视觉上更加丰富,有助于进行更细致的数据分析。
# Plot
data %>%
ggplot( aes(x=name, y=value, fill=name)) +
geom_boxplot() +
scale_fill_viridis(discrete = TRUE) +
geom_jitter(color="grey", size=0.7, alpha=0.5) +
theme_minimal() +
theme(
legend.position="none",
plot.title = element_text(size=11)
) +
ggtitle("A boxplot with jitter") +
xlab("")
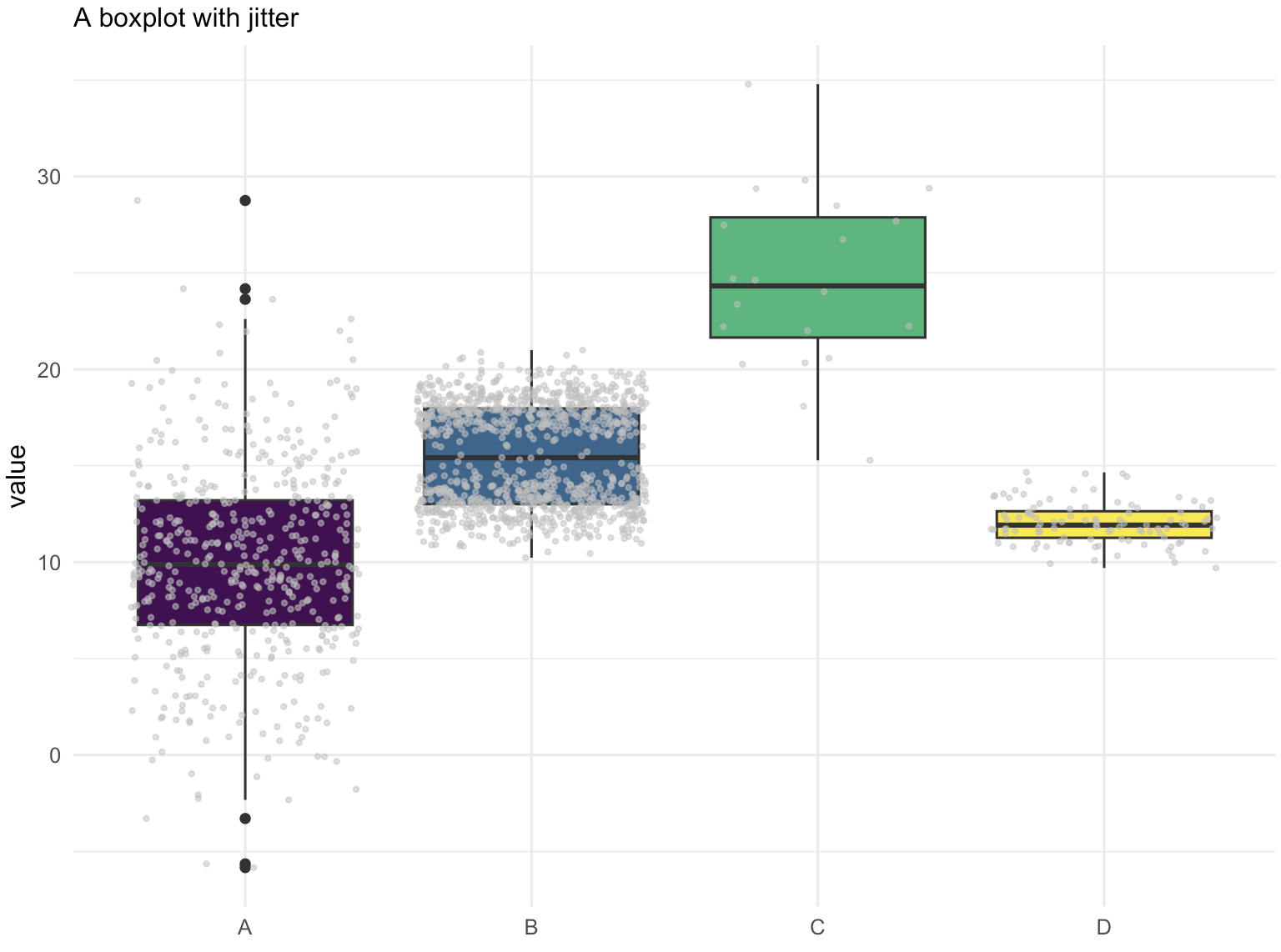
在添加抖动之后,一些新的模式变得清晰可见。
- 组别C的样本量相对较小:与其它组别相比,组别C的数据点数量较少。这是一个在断定组别C的数值高于其他组别之前需要了解的重要信息。样本量的大小可能会影响统计结果的可靠性,因此在进行组间比较时,样本量的差异是一个需要考虑的重要因素。
- 组别B呈现出双峰分布:数据点在y=18和y=13附近形成了两个明显的集群,表明组别B的数据可能具有双峰分布特征。这种分布模式意味着组别B可能包含两个不同的子群体,或者受到两种不同因素的影响。
这些观察结果强调了在数据分析时,除了考虑中心趋势和离散程度之外,还需要注意样本量和数据分布的形状。这些因素对于正确解释数据、避免误导性结论至关重要。在报告分析结果时,应当详细说明样本量的差异以及数据分布的特殊模式,以便于其他研究者或决策者能够全面理解数据背后的含义。
四、小提琴图
当样本量较大时,使用抖动将不再是一个可行的选项,因为数据点会相互重叠,使得图形变得无法解读。
在这种情况下,一种替代方案是使用小提琴图(violin plot)。小提琴图能够描述每个组别数据的分布情况,其特点如下:
- 小提琴图结合了箱线图和密度图的特点,通过展示数据密度来揭示组内数据的分布形态。
- 小提琴图的宽度代表数据在不同值上的密度,宽度越大,表明该值区域内的数据点越多。
- 与箱线图相似,小提琴图也展示了中位数、四分位数以及四分位距,但除此之外,它还提供了关于数据分布形状的更多信息。
- 小提琴图可以有效地展示多组数据的分布差异,尤其是在样本量较大时,它能够提供比箱线图更丰富的视觉信息。
因此,当样本量较大且需要详细展示数据分布时,小提琴图是一个更为合适的选择。通过小提琴图,研究者可以更加准确地理解各组数据的分布特征,包括是否存在多峰分布、偏态以及潜在的异常值等。
#load dplyr
library(dplyr)
# sample size
sample_size = data %>% group_by(name) %>% summarize(num=n())
# Plot
data %>%
left_join(sample_size) %>%
mutate(myaxis = paste0(name, "\n", "n=", num)) %>%
ggplot( aes(x=myaxis, y=value, fill=name)) +
geom_violin(width=1.4) +
geom_boxplot(width=0.1, color="grey", alpha=0.2) +
scale_fill_viridis(discrete = TRUE) +
theme_minimal() +
theme(
legend.position="none",
plot.title = element_text(size=11)
) +
ggtitle("A violin plot") +
xlab("")
通过小提琴图,可以非常清楚地看到不同组别的数据分布存在差异。
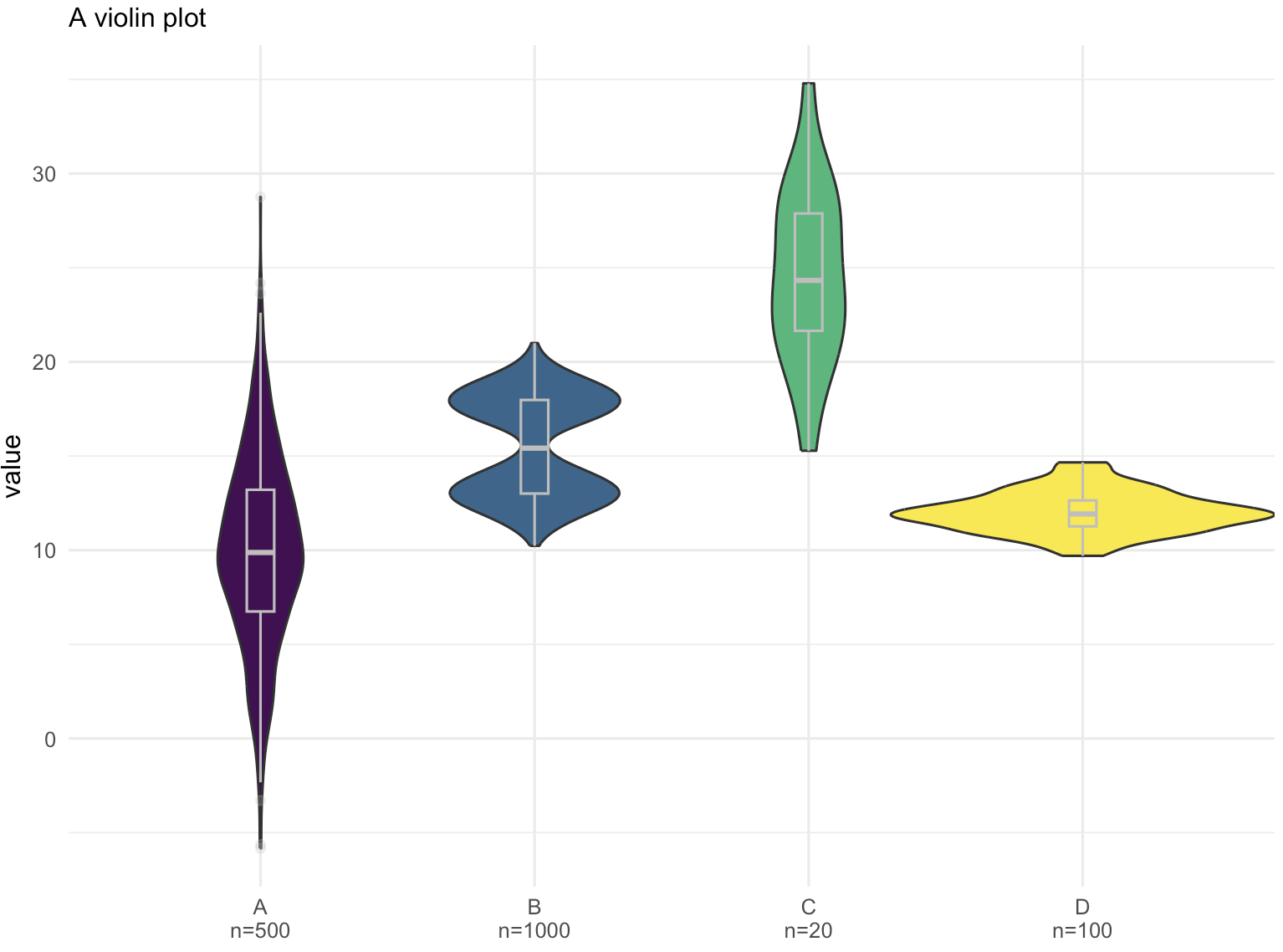
以下是关键观察结果:
- 组别B的双峰分布特征在小提琴图中变得非常明显,两个峰分别代表了数据中的两个主要集群。
- 小提琴图作为一种信息展示方式,其强大之处在于能够详细地描绘出数据的分布形态,包括峰度、偏度和密度等。
- 与箱线图相比,小提琴图可能在实际应用中的利用率较低,但实际上它们在展示数据分布方面具有更高的信息含量和视觉表现力。
综上所述,小提琴图是一种强大的数据可视化工具,它能够揭示组间分布的差异,尤其是在数据具有复杂分布特征时,小提琴图能够提供比箱线图更为深入和详尽的信息。因此,在适当的情况下,应当考虑使用小提琴图来替代或补充箱线图,以便更全面地理解和传达数据的分布情况。
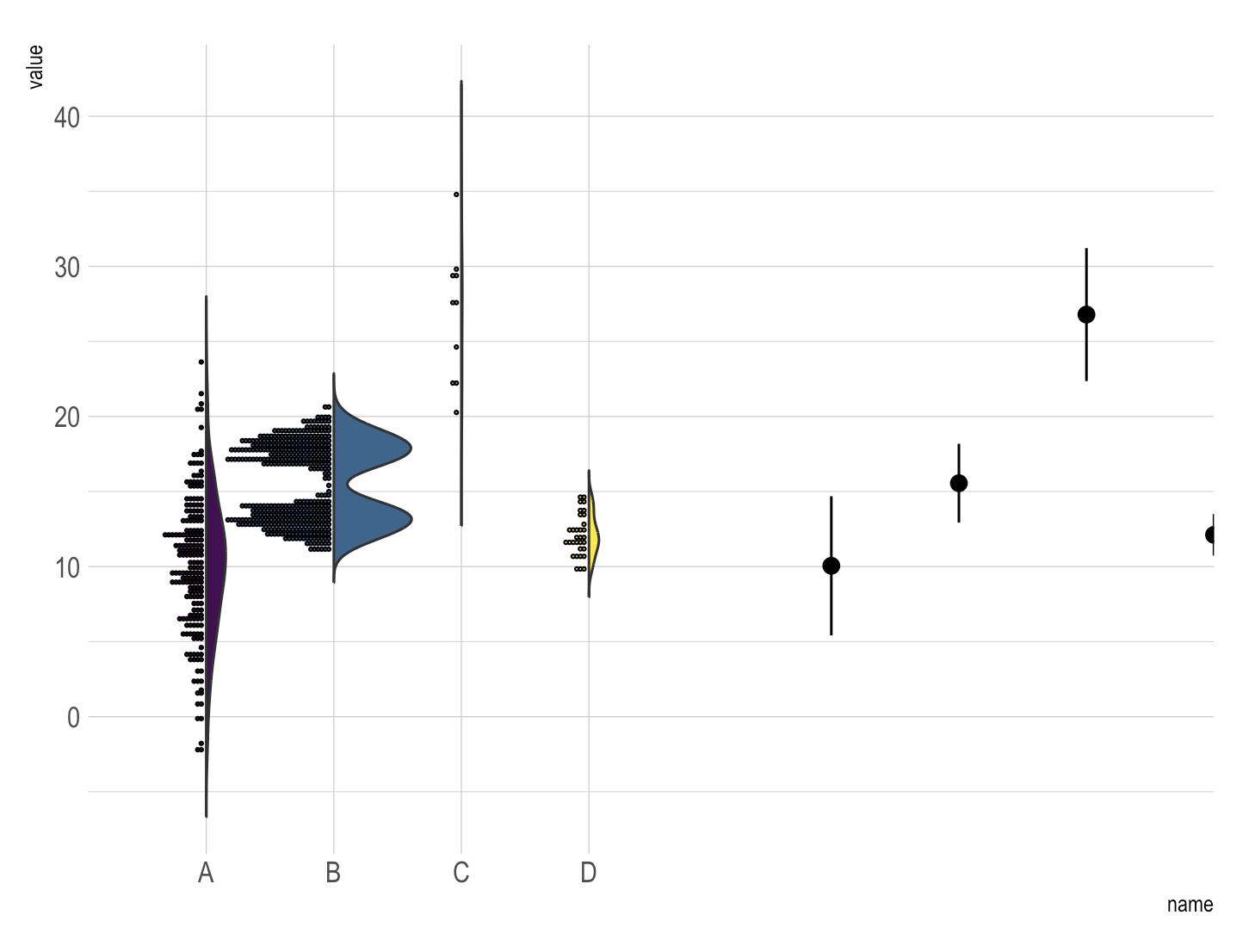
五、半小提琴图
在之前的图表中,每个组的样本量已经在x轴上,组名下方进行了标注。这是一种良好的实践,它表明组别C的样本量不足。然而,有时直接展示数据点本身会更为有效。因此,一种很好的替代方案是使用半小提琴图来展示原始数据。
半小提琴图的特点如下:
- 半小提琴图在小提琴图的基础上,只展示了一侧的密度分布,从而为展示原始数据点留出了空间。
- 在半小提琴图中,原始数据点通常以散点图的形式叠加在密度图的一侧,这样既保留了数据分布的密度信息,又能够直观地看到每个数据点的具体位置。
- 通过这种图表,观察者可以同时获取关于数据分布的概览以及单个数据点的详细信息。
- 样本量的标注有助于评估各组数据代表性的强弱,特别是在样本量不等的情况下,这种标注能够提醒分析者注意样本量可能对结果解释造成的影响。
使用半小提琴图结合原始数据点的展示方式,不仅能够提供数据的整体分布情况,还能够增强图表的信息传递效率,使得数据分析更加全面和深入。
# Code coming from @drob: https://gist.github.com/dgrtwo/eb7750e74997891d7c20#file-geom_flat_violin-r
"%||%" <- function(a, b) {
if (!is.null(a)) a else b
}
geom_flat_violin <- function(mapping = NULL, data = NULL, stat = "ydensity",
position = "dodge", trim = TRUE, scale = "area",
show.legend = NA, inherit.aes = TRUE, ...) {
layer(
data = data,
mapping = mapping,
stat = stat,
geom = GeomFlatViolin,
position = position,
show.legend = show.legend,
inherit.aes = inherit.aes,
params = list(
trim = trim,
scale = scale,
...
)
)
}
#' @rdname ggplot2-ggproto
#' @format NULL
#' @usage NULL
#' @export
GeomFlatViolin <-
ggproto("GeomFlatViolin", Geom,
setup_data = function(data, params) {
data$width <- data$width %||%
params$width %||% (resolution(data$x, FALSE) * 0.9)
# ymin, ymax, xmin, and xmax define the bounding rectangle for each group
data %>%
group_by(group) %>%
mutate(ymin = min(y),
ymax = max(y),
xmin = x,
xmax = x + width / 2)
},
draw_group = function(data, panel_scales, coord) {
# Find the points for the line to go all the way around
data <- transform(data, xminv = x,
xmaxv = x + violinwidth * (xmax - x))
# Make sure it's sorted properly to draw the outline
newdata <- rbind(plyr::arrange(transform(data, x = xminv), y),
plyr::arrange(transform(data, x = xmaxv), -y))
# Close the polygon: set first and last point the same
# Needed for coord_polar and such
newdata <- rbind(newdata, newdata[1,])
ggplot2:::ggname("geom_flat_violin", GeomPolygon$draw_panel(newdata, panel_scales, coord))
},
draw_key = draw_key_polygon,
default_aes = aes(weight = 1, colour = "grey20", fill = "white", size = 0.5,
alpha = NA, linetype = "solid"),
required_aes = c("x", "y")
)
# Final plot inspired from @jbburant: https://gist.github.com/jbburant/b3bd4961f3f5b03aeb542ed33a8fe062
data %>%
sample_frac(0.4) %>%
ggplot(aes(x = name, y = value, fill = name)) +
geom_flat_violin(scale = "count", trim = FALSE, width=2) +
scale_fill_viridis(discrete = TRUE) +
stat_summary(fun.data = mean_sdl, fun.args = list(mult = 1), geom = "pointrange", position = position_nudge(4.9)) +
geom_dotplot(binaxis = "y", dotsize = 0.8, stackdir = "down", binwidth = 0.3, position = position_nudge(-0.025)) +
theme_ipsum() +
theme(
legend.position = "none"
) +
ylab("value")
















 1805
1805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









