







小罗碎碎念
本期文献主题:R语言一键绘制临床基线表
我们在阅读文献的时候,应该对患者特征这个名词很熟悉,有的文献会直接列出临床基线表(我之前整理过影像组学和病理组学的,详情看07-09和07-10这两天的推送),有的只是在分析数据集的时候提一嘴。
作为多模态/多组学的研究来讲,有一个模态是容易被我们忽略的——临床基线特征。这个资料是跟着我们获取切片的时候,一起获取的,这份表格其实暗含了很多信息值得我们发掘,例如不同指标的分布情况(例如不同中心患者的TNM分期情况)有可能就决定了我们训练的模型是否有指向性,直接影响了模型的泛化性。
另外我还做了一些尝试——相关性热图分析(08-13的推文),我们在自己的基线数据中根据自己的经验选取几个指标,也可以简略的看一看不同数据之间的相关性,初步验证一下自己的想法!!
这一期推文主要是介绍临床基线表的基础概念,在第五部分还会介绍如何通过R语言一键生成基线表(.xlsx格式),想要word的,直接复制,然后重新排版就可以。
一、什么是临床资料基线表?
临床资料基线表是临床研究中非常重要的一部分,它记录了研究开始时参与者的健康状况和特征。
根据Segen医学词典的解释,“基线是研究人群在前瞻性研究中最开始时的健康状况,是研究对象在接受试验组或对照组干预措施前的‘0’时刻”。基线数据可以用来评估药物的安全性和有效性,通过比较研究开始和结束时的数据变化来观察干预措施的影响。
基线信息通常包括两方面的内容:
- 首先是研究人群的入选排除过程,这涉及到使用入选标准和排除标准来确定最终的分析人群;
- 其次是研究人群基线特征的描述与比较,这些特征可能包括社会人口学特征、临床特征、实验室检查指标、疾病史和用药史等。
详细包含的信息:
- **人口学特征:**参与者的年龄、性别、种族等基本特征;
- **临床特征:**包括参与者的疾病状态、症状和既往病史等;
- **生活方式和行为习惯:**如吸烟史、饮酒习惯、运动频率等;
- **生理测量值:**如身高、体重、血压、生化指标等;
- **疾病评估量表:**用于评估研究参与者的疾病严重程度和症状;
在展示形式上,基线信息可以通过研究人群流程图来展示入选排除情况,而基线特征的描述与比较则常用基线表格来展示。例如,在干预性研究中,可以根据实验组和对照组分组展示基线特征,而在观察性研究中,则可能根据不同的暴露因素分组展示。
统计方法方面,描述和比较基线特征时,需要根据变量的不同特性(连续变量、分类变量,正态、非正态)和组别数(两组、三组及以上)选择相应的描述形式和检验方法。
例如,连续变量可以用“均数±标准差”或“中位数(四分位数间距)”描述,而分类变量则用“频数(百分比)”描述。在比较组间均衡性时,可以使用t检验、Wilcoxon秩和检验、方差分析或Kruskal-Wallis检验等方法。对于大样本研究,有时直接报告均数和百分比,而不是P值,以避免假阳性并提供量化的差异。
在实际应用中,例如在R语言中,可以使用不同的包如table1来创建基线表格(待会儿就会介绍)。这些表格可以详细展示不同组别在基线时的特征,如年龄、性别、吸烟状态、血压、胆固醇水平等。通过这种方式,研究人员可以快速把握研究人群在研究开始时的健康状况,为后续的数据分析和结果解释提供基础。
二、绘制临床资料基线表时,需要注意的关键点
-
准确性:确保所有数据准确无误,反映了参与者在研究开始时的状态。
-
完整性:基线表应包含所有重要的基线特征,如年龄、性别、体重、疾病史、既往治疗史、重要的生命体征和实验室检查结果等。
-
可比性:如果研究涉及多个组别,需要确保各组间的基线特征具有可比性,以便后续分析时可以准确评估干预效果。
-
清晰性:表格应该设计得清晰易懂,避免过多的信息堆砌,使得读者可以快速抓住关键信息。
-
一致性:数据的呈现格式(如小数点位数、日期格式等)在整张表中应保持一致。
-
适当的统计描述:对于连续变量,可以使用均值±标准差或中位数(四分位数间距)来描述;分类变量则用频数(百分比)来描述。
-
适当的表格格式:使用三线表(顶线、栏目线、底线)来增强表格的可读性。
-
数据的标准化:确保所有的数据都是以标准化的方式收集和记录的,以便于比较和分析。
-
注释和说明:对于缩写、特殊符号或不常见的指标,应在表格下方或附录中提供清晰的注释和说明。
-
数据的隐私保护:确保在基线表中不包含任何可以识别个人身份的信息,遵守相关的隐私保护法规。
-
适应性:基线表应适应研究目的和设计,不同的研究可能需要不同的基线数据。
-
审慎使用统计测试:在比较不同组别的基线特征时,适当使用统计测试来评估组间差异的统计学意义,但要避免过度依赖P值。
-
图表辅助:如果适用,可以使用图表来辅助展示基线数据的分布特征,如箱线图、直方图等。
-
更新和维护:在研究过程中,基线表可能需要根据新的数据或信息进行更新和维护。
-
同行评审:在最终确定基线表之前,可以让同行或专家进行评审,以确保没有遗漏或错误。
通过注意这些要点,可以确保临床资料基线表既全面又准确,为后续的数据分析和解释提供坚实的基础。
三、总结不同的类型变量
在绘制临床资料基线表时,可以使用不同的描述性统计方法来总结不同类型的变量。
3-1:连续型变量
连续型变量是那些可以在某个区间内取任意值的变量(如年龄、体重、血压等),它们是定量的并且经常是比定性变量更细致和精确的测量结果。
以下是针对常见变量类型的描述性统计推荐方法:
- 平均值(Mean):这是一个中心趋势的度量,表示所有观测值的总和除以观测数量。它是数据集中最常用的中心位置度量,尤其适用于正态分布或近似正态分布的数据。
- 标准差(Standard Deviation, SD):这是衡量数据点偏离平均值的指标,即数据的离散程度。一个较小的标准差意味着数据点更紧密地围绕平均值聚集,而一个较大的标准差则意味着数据点更加分散。
- 中位数(Median):这是将数据集分为两个相等部分的值,其中一半的数据项低于中位数,另一半高于中位数。当数据分布不对称或包含异常值时,中位数比平均值更稳健。
- 最小值(Minimum)和最大值(Maximum):这两个统计量描述了观测值的范围,即数据集中的最小可能值和最大可能值。它们可以用来识别数据的极端情况。
- 四分位数(Quartiles):这些是将数据集分为四等份的值,包括第一四分位数(Q1,25%)、第二四分位数(Q2,即中位数,50%)和第三四分位数(Q3,75%)。四分位数帮助我们了解数据的分布情况,特别是数据的离散程度和偏态。
- 箱线图(Boxplot):这是一种图形工具,用于展示数据的中位数、四分位数、异常值和潜在的偏态或峰态。箱线图是识别数据分布特征的有用方法。
- 直方图(Histogram):这是一种图形表示方法,显示数据在不同区间的频率分布。直方图可以用来观察数据的分布形状和识别任何异常值或模式。
3-2:分类型变量
分类型变量,也常被称为名义变量或定性变量,是那些只能取有限个离散值的变量(如性别、种族、病情等级等),这些值通常是互不相容的分类标签。
对于分类型变量,通常使用以下描述性统计:
- 计数(Count):这是最基本的描述性统计量,表示每个类别出现的频次。计数帮助我们了解每个类别在数据集中的实例数量。
- 百分比(Percentage):这是将计数转换为比例形式,表示每个类别在总样本量中所占的份额。百分比使得不同样本量的分类数据之间可以进行比较。
- 众数(Mode):众数是数据集中出现次数最多的类别。在分类型变量中,可能存在多个众数,即多模态数据集。
3-3:有序型变量
有序型变量,又称为序数量变量,它们不仅具有分类的特征,还包含了一定的顺序或等级关系,但这种顺序并不像连续型变量那样具有实际的数值差值意义(如疼痛程度等级、教育水平等)。
对于有序型变量,可以使用以下描述性统计:
- 中位数(Median):中位数是将数据集从小到大排序后位于中间位置的值,或者是中间两个值的平均数。对于有序型变量,中位数有实际意义,因为它代表了类别分布的中心位置。
- 百分位数(Percentiles):百分位数将数据分成100个等份,每一份对应一个百分比。例如,第50百分位数即为中位数。百分位数反映了数据在有序序列中的位置,可以用来描述数据的分布和离散程度。
- 范围(Range):有序型变量的范围是最高类别和最低类别之间的差异。尽管有序型变量的类别间没有确切的数值差异,范围仍可提供类别分布的概览。
- 四分位数(Quartiles):四分位数将数据分为四等份,包括第一四分位数(Q1,25%)、第二四分位数(Q2,即中位数,50%)和第三四分位数(Q3,75%)。四分位数有助于识别数据的分布特征,尤其是在数据不满足正态分布时。
- 众数(Mode):众数是数据集中出现次数最多的类别。在有序型变量中,众数提供了最常见的类别信息。
有序型变量的描述性统计分析有助于我们理解数据的分布特征和潜在的模式,这些方法在社会科学、健康研究、教育评估等领域中具有重要应用。
3-4:二分类变量
二分类变量是最简单的分类型变量,仅包含两个互斥的类别,通常用于表示存在或不存在、是或否、通过或未通过等对立情况(如是否患病、是否接受治疗等)。
对于二分类变量,可以使用以下描述性统计:
- 计数(Count):这是二分类变量的基本统计量,表示每个类别在数据集中出现的实际频次。例如,在医学研究中,计数可以用来表示患病和未患病的人数。
- 百分比(Percentage):百分比表示每个类别的计数占总样本量的比率。例如,如果总样本量是100,患病的人数是30,那么患病的百分比是30%。
- 比率(Ratio):比率是两个类别计数的比值,通常用来表示某种事件发生的频率与不发生事件的频率之间的关系。
- 相对频率(Relative Frequency):相对频率是某个类别的计数除以样本总量,与百分比类似,但通常用于更专业的统计分析中。
- 众数(Mode):虽然在二分类变量中,众数的概念不像在多分类变量中那样有用,但众数仍然是数据集中出现次数最多的类别。
二分类变量的描述性统计分析有助于我们理解数据的基本分布特征,评估分类结果的准确性,以及识别可能的关联和趋势。这些方法在医学、心理学、市场研究等领域中具有重要应用。
四、组间p值的比较
在展示组间比较的p值时,需要根据数据的类型和分布特征来选择最合适的统计方法。
以下是一些针对不同数据类型的建议:
4-1:连续性变量且符合正态分布、方差齐性:
- 使用Student’s t-test(独立样本t检验)来比较两组间的均值差异。
- 当涉及多组比较时,采用ANOVA(方差分析),随后可通过Tukey’s HSD test(Tukey的诚实显著性差异检验)等事后比较方法来确定哪些组间存在显著差异。
4-2:连续性变量但不符合正态分布、方差齐性:
- 利用非参数检验,例如Mann-Whitney U检验(Wilcoxon秩和检验)来比较两组数据。
- 对于三组或以上的数据,使用Kruskal-Wallis H检验,之后可结合如Dunn’s test等多重比较方法来识别具体组间差异。
4-3:有序变量:
- 如果数据是有序的分类变量,可以使用Jonckheere-Terpstra test或Kendall’s tau-b等非参数方法来检测趋势。
4-4:分类变量:
- 对于二分类变量的比例差异,使用卡方检验(χ²检验)或Fisher’s精确检验。
- 对于多分类无序变量,可采用Pearson卡方检验或多维卡方检验。
4-5:多个连续性变量:
- 当需要同时分析多个连续性变量时,可采用多元回归分析或MANOVA(多变量方差分析)。
- 展示结果时,可以为每个变量提供p值,同时使用Bonferroni校正或Šidák校正来控制家族错误率。
4-6:相关性分析:
- 如果目的是评估两组连续变量之间的线性关系,可以使用Pearson相关系数或Spearman等级相关。
通过这些细致的方法选择和结果展示,可以确保临床资料基线表中的组间比较既科学又准确,同时为读者提供全面的结果解释。
五、R语言绘制基线表
5-1:tableone包
tableone 是一个在R语言中用于快速生成医学研究论文中基线特征表(通常为表一)的包。这个包特别适合处理临床数据,能够同时处理连续变量和分类变量,并支持p值和标准化均值差异的计算。此外,tableone 还支持加权数据,可以通过 survey 包来实现 。
使用 tableone 包可以大大简化从数据集创建基线表的过程。例如,CreateTableOne 函数可以对整个数据集或按分组变量进行汇总,提供描述性统计,并在必要时计算标准化均值差异和p值 。这个函数非常灵活,允许用户指定想要包括的变量(vars 参数),并且可以指出哪些变量应当被视为分类变量(factorVars 参数)。此外,还可以通过 strata 参数来指定分组变量,进行分层描述和统计检验 。
tableone 包还提供了其他辅助函数,例如 CreateCatTable 和 CreateContTable,分别用于生成分类变量和连续变量的汇总表。这些函数可以帮助用户更细致地控制表的输出格式和内容 。
此外,tableone 支持非正态分布数据的描述,用户可以通过设置 nonnormal 参数来指定哪些连续变量应当以中位数和四分位数的形式展示,而不是均值和标准差。对于分类变量,如果需要进行Fisher精确检验,可以通过设置 exact 参数来指定 。
最后,tableone 包支持将生成的表导出为CSV文件,方便用户将其复制粘贴到论文或其他文档中,提高工作效率 。总的来说,tableone 是一个功能强大且灵活的工具,非常适合临床研究人员在撰写论文时快速生成基线特征表。
5-2:安装并加载"tableone"包
# R语言绘制人口基线表
# 清除变量
rm(list = ls())
# 得到当前路径
getwd()
# 设置工作路径
setwd("/Users/luoxiaoluotongxue/Desktop/硕士课题进展记录/科研绘图/每日科研绘图/24-08")
# 安装包
install.packages("tableone")
# 加载包
library(tableone)
5-3:"tableone"包核心函数CreateTableOne()
tableone 包中的 CreateTableOne() 函数是一个核心函数,用于创建一个包含数据集中所有基线变量的汇总表,这个表通常用于描述医学研究中的患者基线特征。
以下是 CreateTableOne() 函数的一些关键特性和参数:
CreateTableOne(vars, strata, data, factorVars, includeNA = FALSE, test = TRUE,
testApprox = chisq.test, argsApprox = list(correct = TRUE),
testExact = fisher.test, argsExact = list(workspace = 2 * 10^5),
testNormal = oneway.test, argsNormal = list(var.equal = TRUE),
testNonNormal = kruskal.test, argsNonNormal = list(),
smd = TRUE, addOverall = FALSE)
参数说明
vars: 需要包含在表中的变量名称的向量。如果为空,则使用数据框中所有的变量。strata: 分层变量的名称向量,用于创建按组别分层的汇总表。data: 包含所需变量的数据框。factorVars: 需要被当作分类变量处理的数值编码变量的名称向量。includeNA: 是否将NA视为常规因素级别。test: 是否执行组间比较的统计测试。testApprox和argsApprox: 用于执行基于大样本近似的统计测试的函数和参数。testExact和argsExact: 用于执行精确测试的函数和参数。testNormal和argsNormal: 用于基于正态假设的统计测试的函数和参数。testNonNormal和argsNonNormal: 用于非参数统计测试的函数和参数。smd: 是否计算所有可能的成对比较的标准化均值差异。addOverall: 当提供分层变量时,是否在表中添加总体列。
功能描述
CreateTableOne()函数自动处理连续变量和分类变量,为它们提供合适的描述性统计量(例如,均值和标准差,或者频数和百分比)。- 函数可以根据
strata参数对数据进行分层,并为每个层级生成汇总统计。 - 可以计算并显示组间比较的p值,以评估不同组别在基线特征上的显著性差异。
- 支持加权数据,能够与
survey包结合使用,以处理复杂的样本设计。 - 可以输出标准化均值差异,这是一种衡量效应大小的指标。
5-4:示例1
#加载必要的库
install.packages("forcats")
library(tableone)
library(survival) # 用于Mayo Clinic的PBC数据
#准备数据集
data(pbc)
#创建基线表
tableOne <- CreateTableOne(data = pbc)
#自定义基线表
vars <- c("time", "status", "age", "sex", "ascites", "hepato", "spiders", "edema", "bili", "chol", "albumin", "copper", "alk.phos", "ast", "trig", "platelet", "protime", "stage")
tableOne <- CreateTableOne(vars = vars, strata = c("trt"), data = pbc, factorVars = c("status", "stage"))
#打印&自定义输出
print(tableOne, nonnormal = c("bili", "chol", "copper", "alk.phos", "trig"), exact = c("status", "stage"), smd = TRUE)
控制栏直接输出的结果如下。

5-5:示例2
加载数据集
## 加载梅奥诊所原发性胆汁性肝硬化数据
library(survival)
data(pbc)
## 检查变量
head(pbc)
将分类变量转换为因子变量
## 将分类变量转换为因子变量
varsToFactor <- c("status", "trt", "ascites", "hepato", "spiders", "edema", "stage")
pbc[varsToFactor] <- lapply(pbc[varsToFactor], factor)
创建变量列表
## 创建变量列表
dput(names(pbc))
vars <- c("time", "status", "age", "sex", "ascites", "hepato",
"spiders", "edema", "bili", "chol", "albumin",
"copper", "alk.phos", "ast", "trig", "platelet",
"protime", "stage")
根据治疗组(trt)创建Table 1
## 根据治疗组(trt)创建Table 1
tableOne <- CreateTableOne(vars = vars, strata = c("trt"), data = pbc)
## 调用print.TableOne方法
tableOne
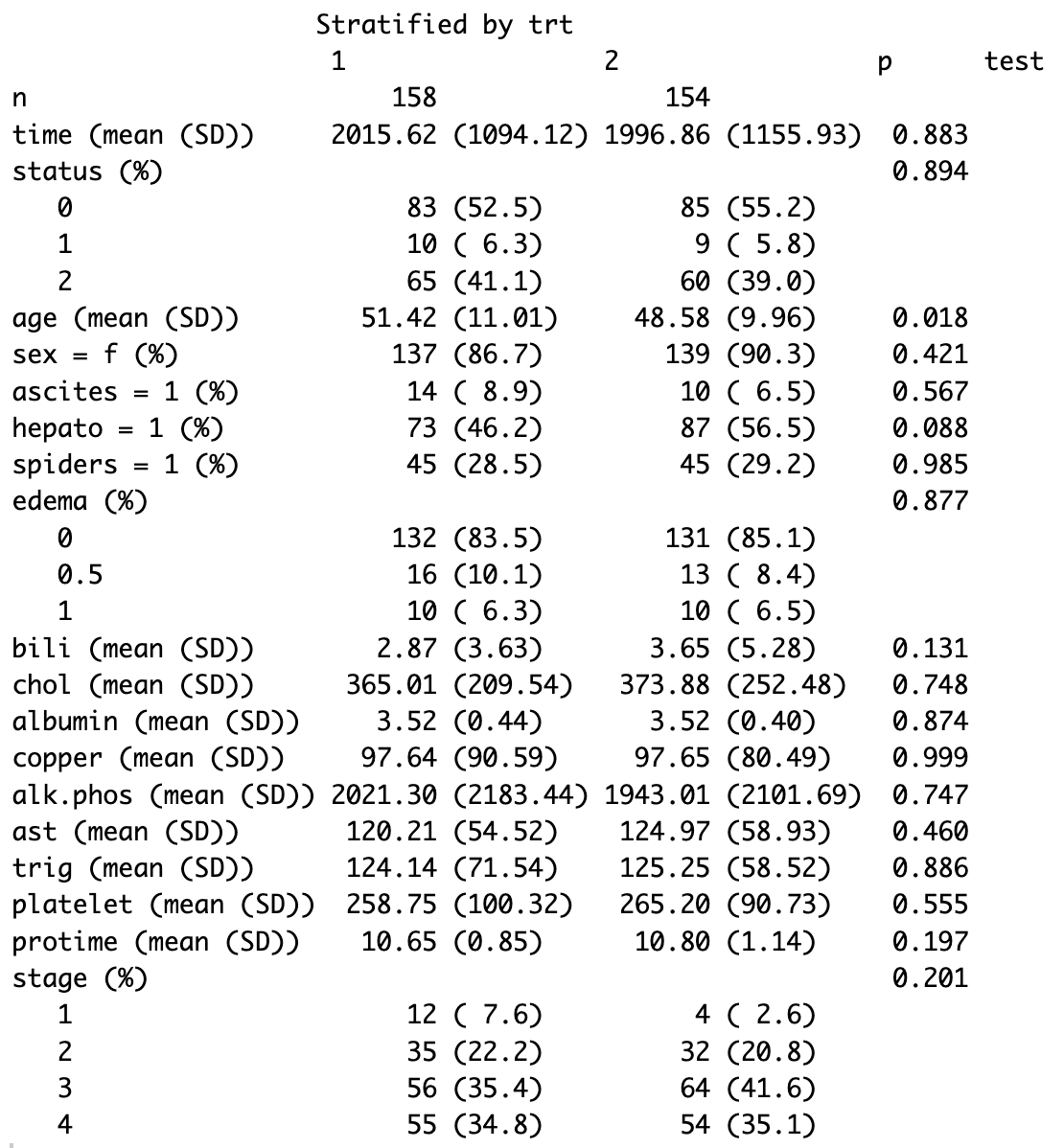
指定非正态变量
## 指定非正态变量将适当地显示变量,并显示非参数检验的p值。在exact参数中指定变量以获取精确的检验p值。cramVars可用于显示二级分类变量的两个水平。
print(tableOne, nonnormal = c("bili", "chol", "copper", "alk.phos", "trig"),
exact = c("status", "stage"), cramVars = "hepato", smd = TRUE)
这个图就是示例1的图。
详细总结
## 使用summary.TableOne方法进行详细总结
summary(tableOne)
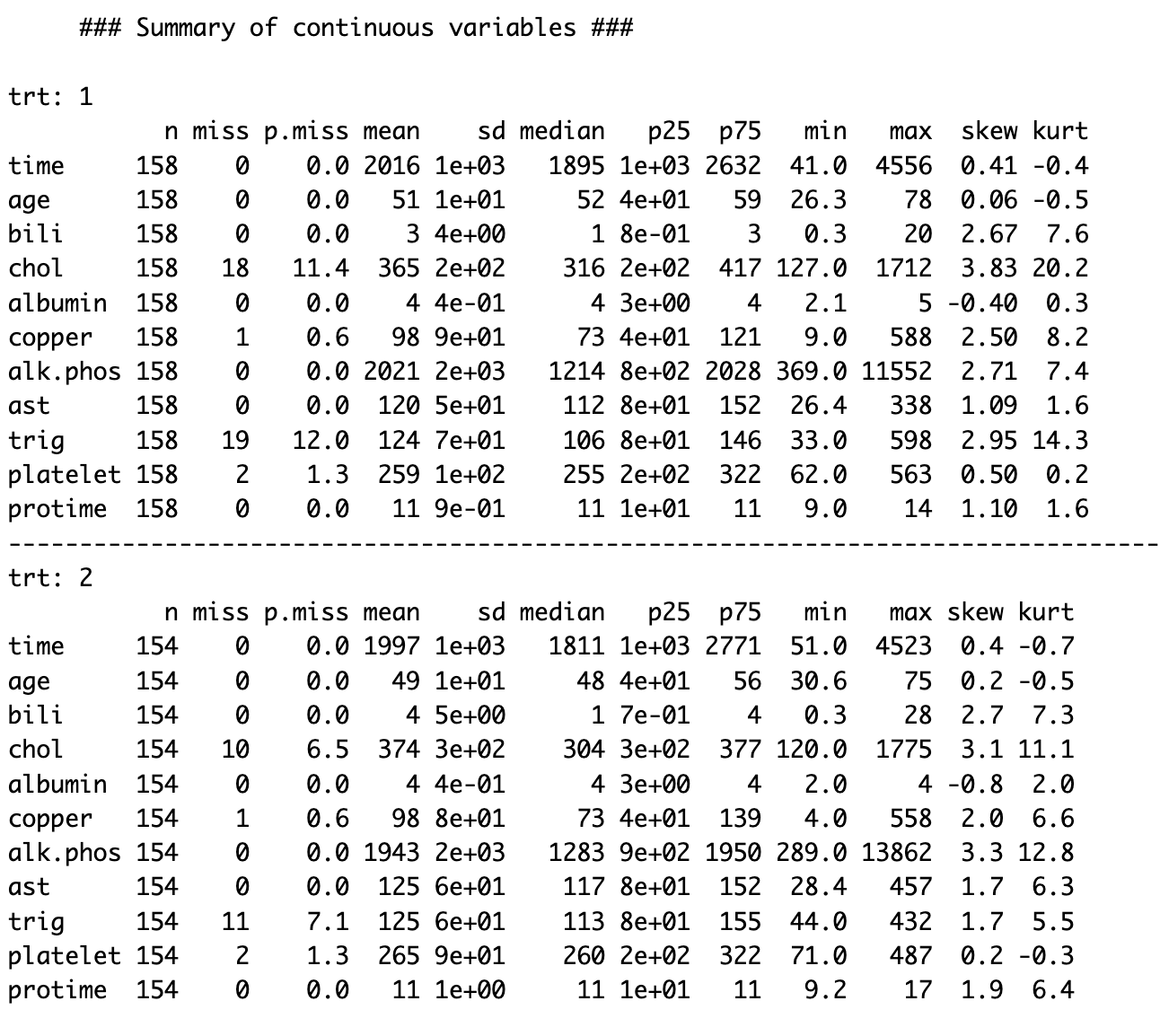
查看分类部分
## 只使用$操作符查看分类部分
tableOne$CatTable
summary(tableOne$CatTable)
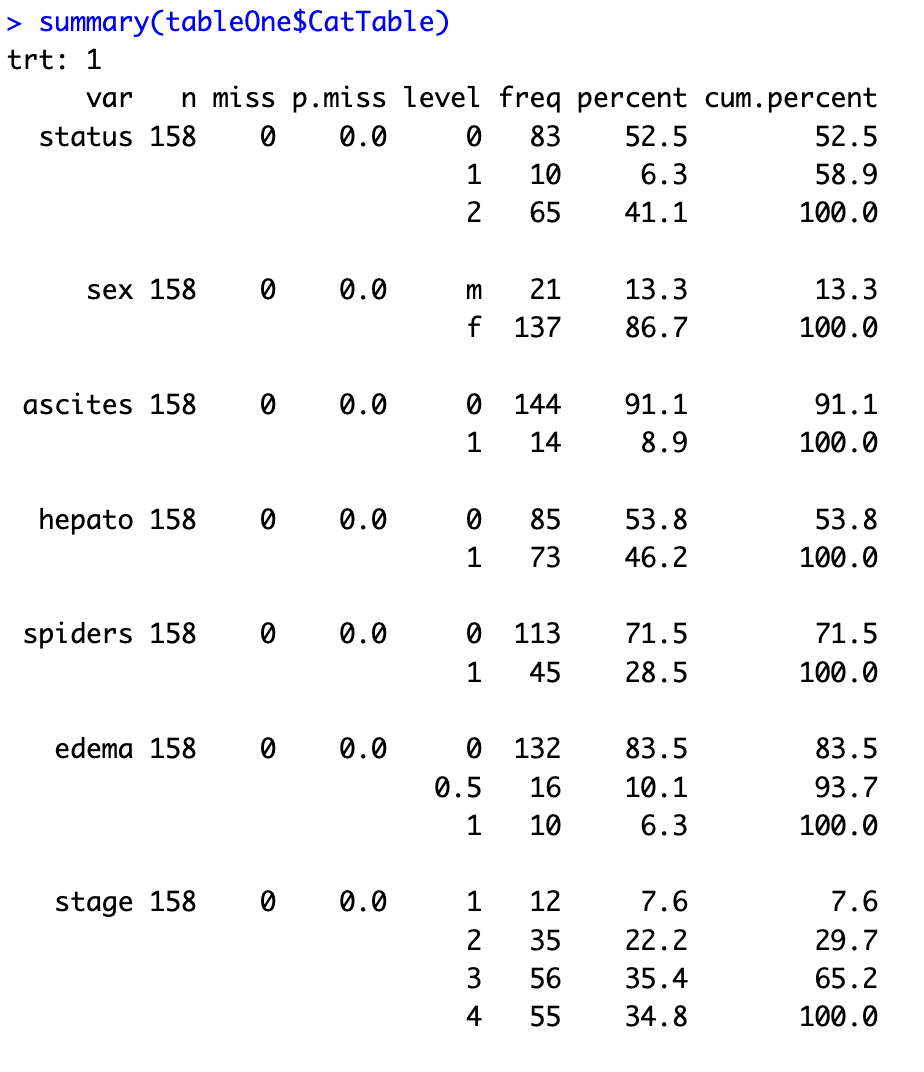
查看连续部分
## 只使用$操作符查看连续部分
tableOne$ContTable
summary(tableOne$ContTable)

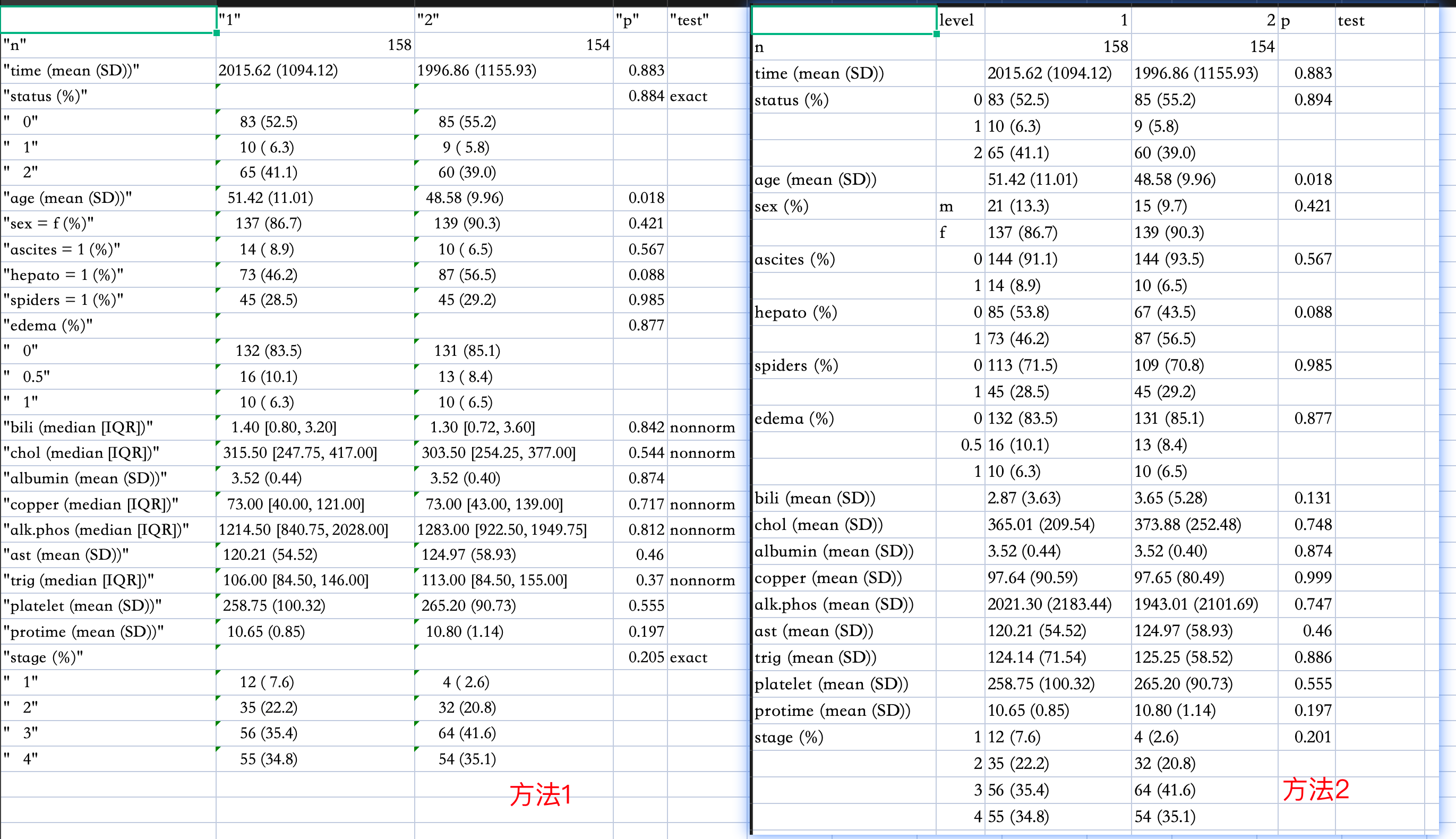
导出到excel
# 方法1
tab1Mat <- print(tableOne, nonnormal = c("bili", "chol", "copper", "alk.phos", "trig"),
exact = c("status", "stage"), quote = TRUE)
write.csv(tab1Mat, file = "Result1_Table1.csv")
# 方法2
print(tableOne, formatOptions = list(big.mark = ","))
tab1Mat2 <- print(tableOne, showAllLevels = TRUE, quote = FALSE, noSpaces = TRUE, printToggle = FALSE)
write.csv(tab1Mat2, file = "Result2_Table1.csv")
方法2的效果明显好于1。
















 1104
1104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









