



PyTorch深度学习实战笔记
05. Linear Regression with PyTorch
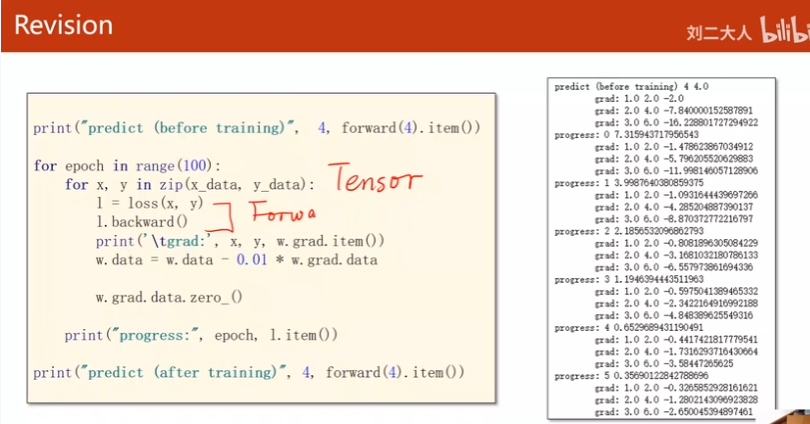
上一节课
自己写的用梯度手动更新
这节课将用PyTorch框架
用PyTorch实现线性回归
1. Prepare dataset
将x, y向量化、广播机制
Mini-Batch

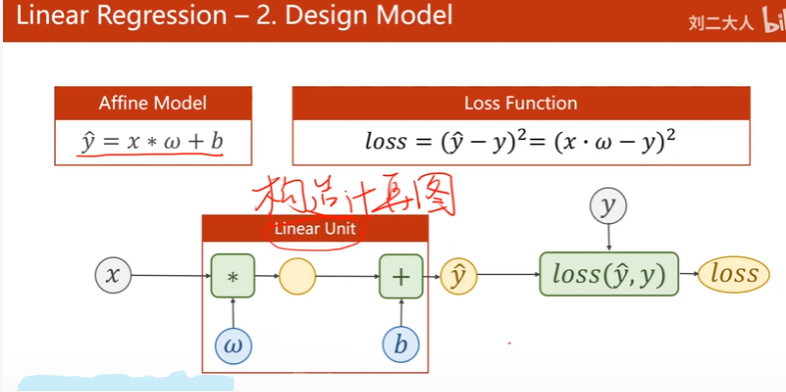
2. Design Model
人工计算 -> 构造出PyTorch计算图,梯度自动算出来
loss也是矩阵,但最后要变成标量
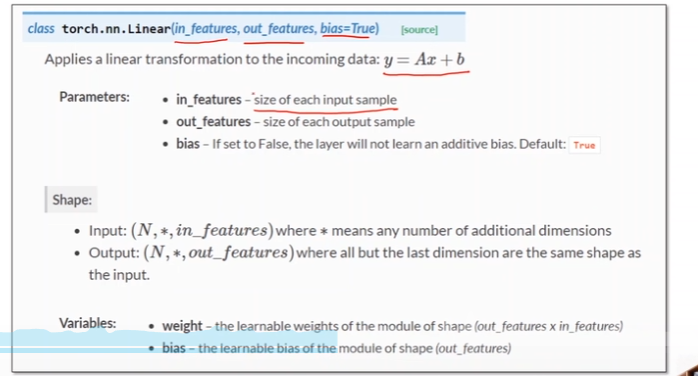
继承torch.nn.Module
将模型定义成类
至少实现__init__() 和 forwad()。会根据计算图自动构建backward()。
super()调用父类构造,必须写
self.linear = torch.nn.Linear(1, 1):构造Linear对象(继承自Module)y_pred = self.linear(x)
为什么对象能够像函数一样调用?
因为Linear实现了__call__(),call调用forward()

3. Construct Loss and Optimizer
- criterion
继承自Module(使用MSE损失函数,输入y and y^,也要构建计算图)
size_average:是否最后求均值
reduce:是否需要求和降维- optimizer
实例化optim.SGD
parameters:用类似递归的方式把所有权重加入到训练参数集
lr:一般设置固定学习率

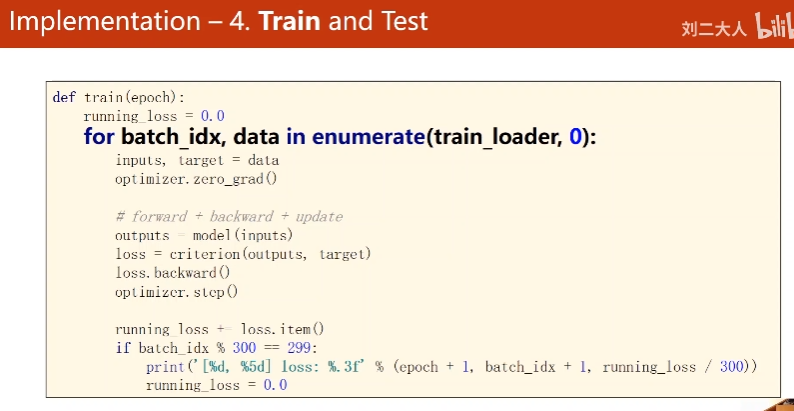
4. Traing Cycle
- 前馈
算y^
算loss- 反馈
权重归零
backward- 更新
update

测试集上Loss下降再升上去:过拟合了
5.1 作业

import torch
import matplotlib.pyplot as plt
# 1. Prepare Dataset
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
# 2. Design Model
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = torch.nn.Linear(1, 1, bias=True)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
models = {
'SGD': LinearModel(),
'Adam': LinearModel(),
'Adagrad': LinearModel(),
'Adamax': LinearModel(),
'ASGD': LinearModel(),
'RMSprop': LinearModel(),
'Rprop': LinearModel(),
}
# 3. Construct Loss and Optimizer
# ==size_average=False(deprecated)
criterion = torch.nn.MSELoss(reduction='sum')
optimizer = {
'SGD': torch.optim.SGD(models['SGD'].parameters(), lr=0.01),
'Adam': torch.optim.Adam(models['Adam'].parameters(), lr=0.01),
'Adagrad': torch.optim.Adagrad(models['Adagrad'].parameters(), lr=0.01),
'Adamax': torch.optim.Adamax(models['Adamax'].parameters(), lr=0.01),
'ASGD': torch.optim.ASGD(models['ASGD'].parameters(), lr=0.01),
'RMSprop': torch.optim.RMSprop(models['RMSprop'].parameters(), lr=0.01),
'Rprop': torch.optim.Rprop(models['RMSprop'].parameters(), lr=0.01),
}
loss_values = {k: [] for k in optimizer.keys()}
x_test = torch.Tensor([[4.0]])
# 4. Training Cycle
for optimizer_name, optimizer in optimizer.items():
model = models[optimizer_name]
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_values[optimizer_name].append(loss.item())
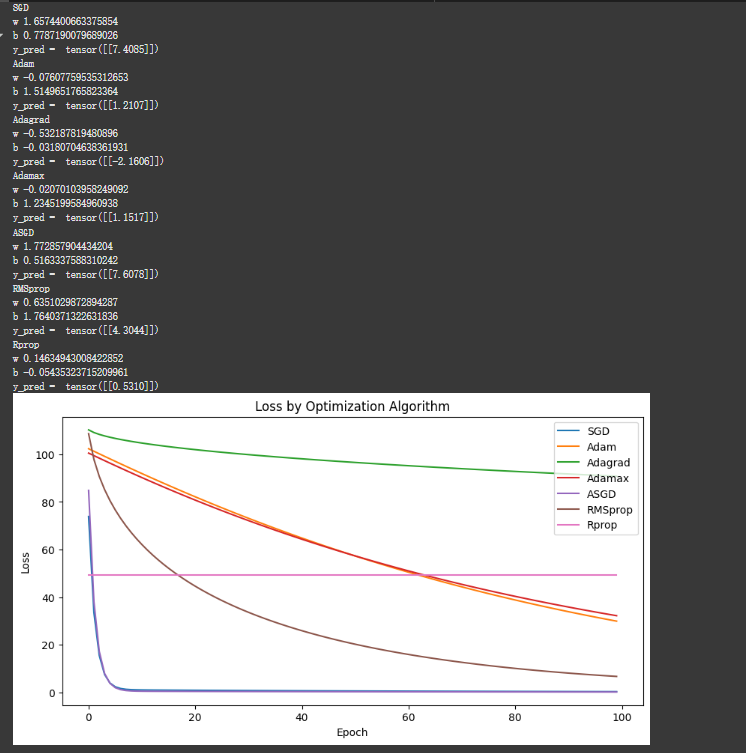
print(optimizer_name)
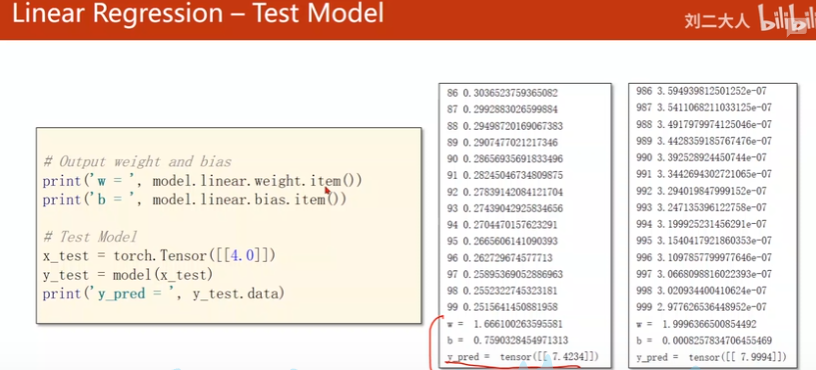
print("w", model.linear.weight.item())
print("b", model.linear.bias.item())
y_test = model(x_test)
print("y_pred = ", y_test.data)
plt.figure(figsize=(10, 5))
for optimizer_name, losses in loss_values.items():
plt.plot(losses, label = optimizer_name)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.title("Loss by Optimization Algorithm")
plt.show()
06 Logistic Regression
上节课的Linear Regression(回归问题)
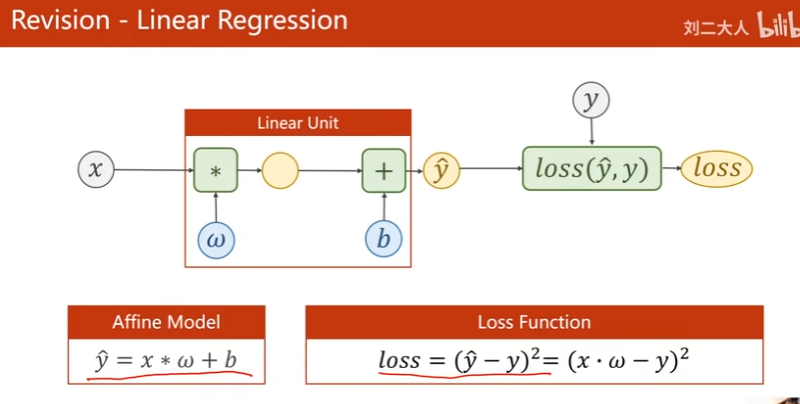
分类问题
输出每个分类的概率(概率最大的是预测结果)。分布符合规律。不能用上述回归方法解决。

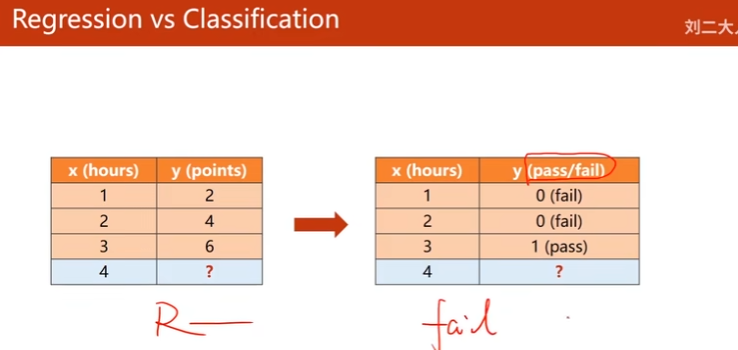
1. Regression vs Classification
回归 vs 二分类(只输出1个实数表示1个分类的概率)
2. Logistic Function
将线性模型输出值从实数 --> [0, 1]范围
饱和函数
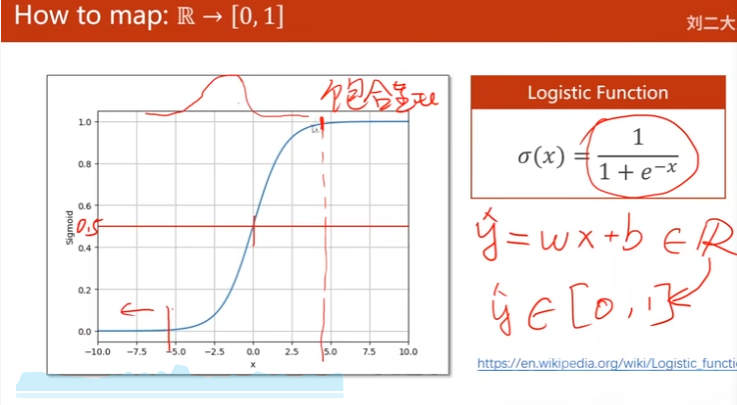
一般将logistic function称为sigmoid function
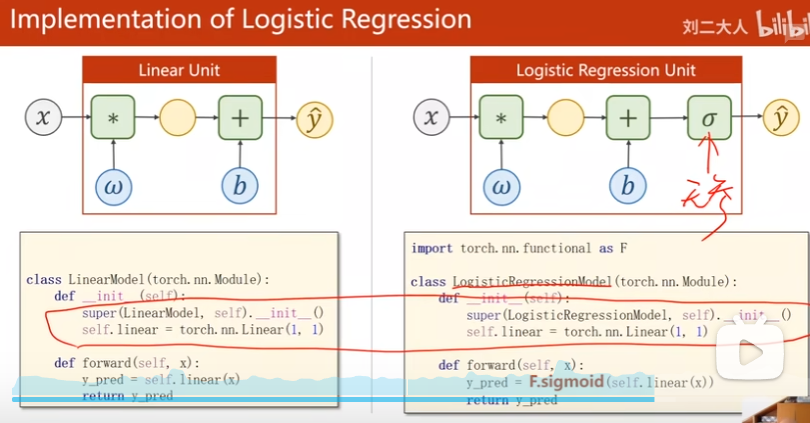
Linear Model vs Logistic Regression Model
Model变化

Loss函数变化
MSE --> Binary Cross Entropy(计算分布的差异)
Mini-batch就改为为求均值


Implementation
sigmoid函数没参数,所以
Loss
size_average是否求均值都可以。将来会影响学习率选择。


07. 处理多维度特征
之前x都是一维,这节课处理多维
结构化数据:
Diabests Dataset,分类
非结构化数据
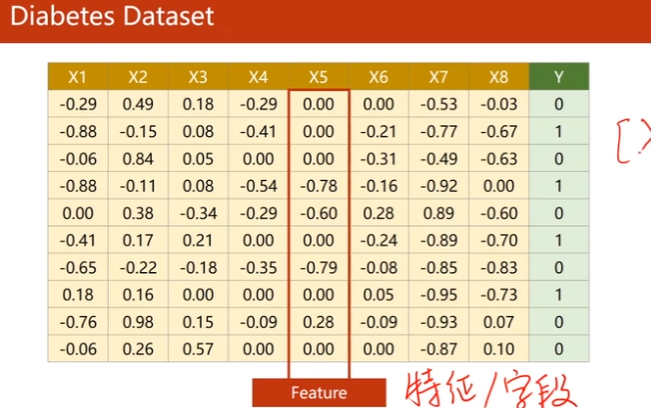
这里是logistic function
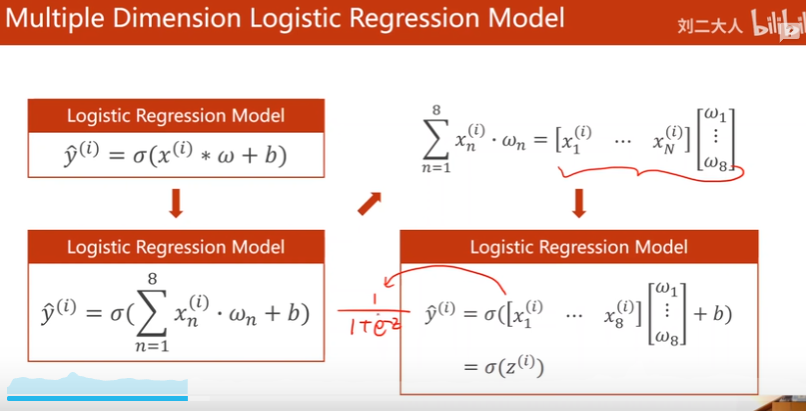
矩阵运算
可以使用并行计算

寻找非线性维度变换
- 寻找8到1维的变换,加入激活函数引入非线性
- 隐藏层越多,学习能力越强。但还需要关注泛化能力,以免学习噪声。
超参数搜索确定维度多少…
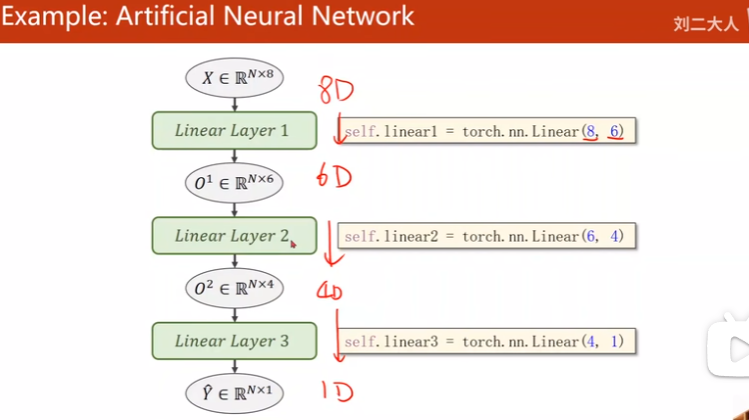
Implementation
有些显卡只支持float,神经网络也够用了


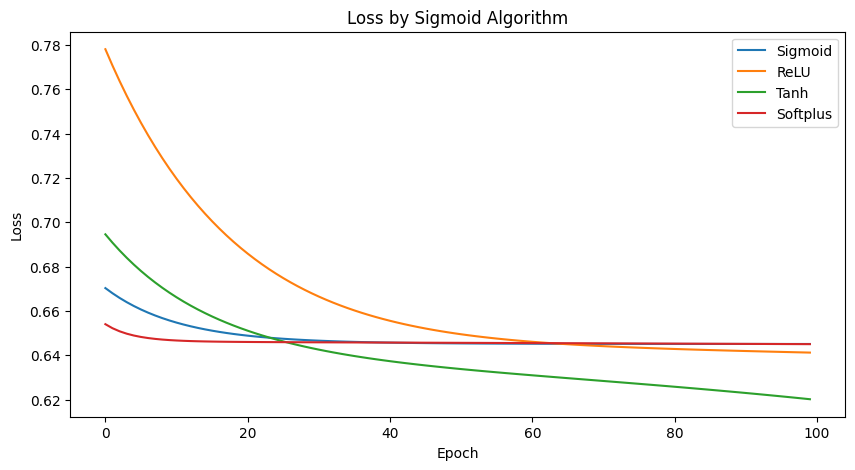
作业7 Try different activate function
最后一层激活函数用sigmoid,保证输出在[0, 1]

import torch
import numpy as np
import matplotlib.pyplot as plt
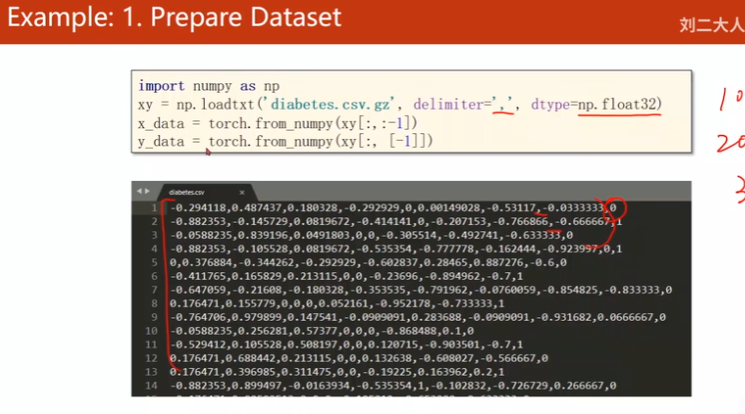
# 读取压缩包 np.loadtxt, delimier:分隔符
xy = np.loadtxt('diabetes.csv.gz', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1])
y_data = torch.from_numpy(xy[:, [-1]])
class Model(torch.nn.Module):
def __init__(self, activation_function=torch.nn.Sigmoid()):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.activation_function = activation_function
def forward(self, x):
x = self.activation_function(self.linear1(x))
x = self.activation_function(self.linear2(x))
x = torch.sigmoid(self.linear3(x))
return x
activation_function = {
'Sigmoid': torch.nn.Sigmoid(),
'ReLU': torch.nn.ReLU(),
'Tanh': torch.nn.Tanh(),
'Softplus': torch.nn.Softplus(),
}
criterion = torch.nn.BCELoss(reduction='mean')
loss_values = {k: [] for k in activation_function.keys()}
for activation_name, function in activation_function.items():
model = Model(activation_function=function)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_values[activation_name].append(loss.item())
plt.figure(figsize=(10, 5))
for activation_name, losses in loss_values.items():
plt.plot(losses, label=activation_name)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Loss by Sigmoid Algorithm')
plt.legend()
plt.show()
08. DataSet and DataLoader
DataSet:
构造数据集,支持索引操作
DataLoader:
支持mini-batch
Batch:
使用全部样本更新。最大化利用向量计算优势提高训练速度。
单个样本计算:
性能好,训练时间长
Mini-Batch:
均衡性能和训练时间
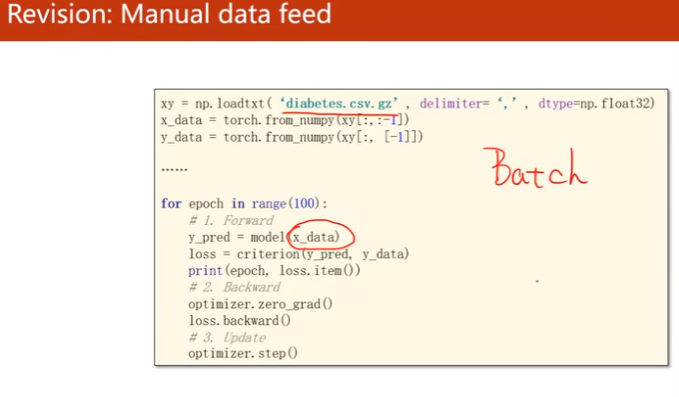
Terminology:Epoch, Batch Size, Iterations
samples = 10000,batch size = 1000, Iterations = 10

DataLoader
DataSet支持索引,长度操作,DataLoader就能shuffle
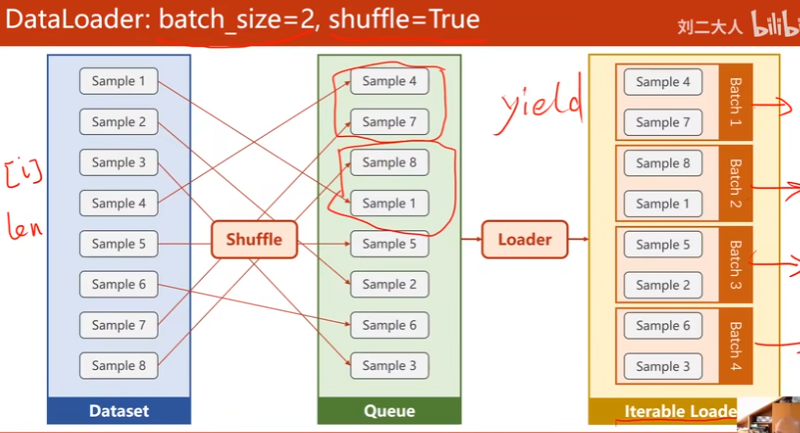
DataSet是抽象类,DataLoader可以实例化
- 结构化数据:在__init__里所有data都读入
- 图像数据:在__init__里仅做初始化(文件名)
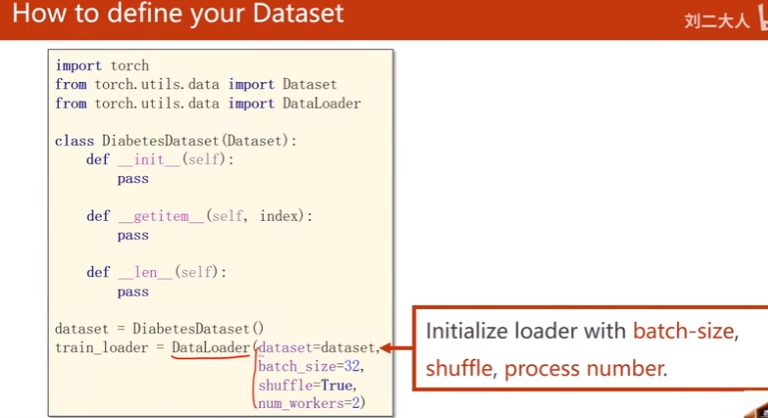
改变:准备数据
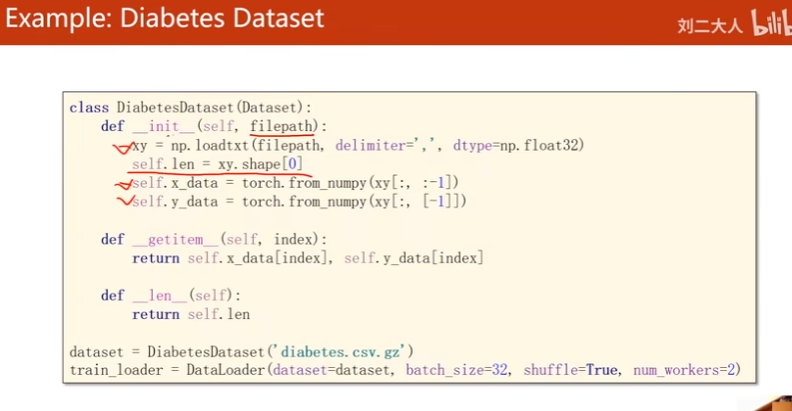
改变:嵌套循环

作业 08-1
# 作业8:titanic
import pandas as pd
import torch
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from sklearn.preprocessing import LabelEncoder, StandardScaler
import matplotlib.pyplot as plt
# 一、DataLoader
class Titantic(Dataset):
def __init__(self, filepath, scaler=None, is_train=True):
super(Titantic, self).__init__()
self.dataframe = pd.read_csv(filepath)
self.scaler = scaler
self.preprocess(self.dataframe, is_train)
def preprocess(self, df, is_train):
# 移除不需要的类别
df.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
# 处理缺失值
df['Age'].fillna(df['Age'].mean(), inplace=True) # Age 缺失的值用平均值来填充
df['Fare'].fillna(df['Fare'].mean(), inplace=True) # Fare 缺失的值用平均值来填充
df['Embarked'].fillna(df['Embarked'].mode()[0], inplace=True) # Embarked 缺失的值用众值来填充
# 使用 LabelEncoder 来转换性别和登船口为数值形式
# LabelEncoder 适用于将文本标签转换为一个范围从 0 到 n_classes-1 的数值。这种方法适用于转换具有顺序性的分类特征。例如“低”,“中”,“高”。
label_encoder = LabelEncoder()
df['Sex'] = label_encoder.fit_transform(df['Sex'])
df['Embarked'] = label_encoder.fit_transform(df['Embarked'])
# 与 LabelEncoder 不同,One-Hot 编码 创建了一个二进制列来表示每个类别,没有数值的大小意义。当分类特征的不同类别之间没有顺序或等级的概念时,通常使用独热编码。
# 注意:要使用 One-Hot的话,input_features=10
# df = pd.get_dummies(df, columns=['Sex', 'Embarked'])
if is_train:
# 如果是训练集,创建新的 StandardScaler,并进行 fit_transform, 来标准化 'Age' 和 'Fare' 列的数值
# 如果特征的数值范围差异很大,那么算法可能会因为较大范围的特征而受到偏向,导致模型性能不佳。
self.scaler = StandardScaler()
df[['Age', 'Fare']] = self.scaler.fit_transform(df[['Age', 'Fare']])
# 如果是训练数据,将 'Survived' 列作为标签
self.labels = df['Survived'].values
self.features = df.drop('Survived', axis=1).values
else:
# 如果是测试集,使用传入的 scaler 进行 transform
df[['Age', 'Fare']] = self.scaler.transform(df[['Age', 'Fare']])
# 对于测试数据,可能没有 'Survived' 列,因此特征就是整个 DataFrame
self.features = df.values
self.labels = None # 标签设置为 None
def __len__(self):
return len(self.dataframe)
def __getitem__(self, index):
# 获取单个样本,包括特征和标签(如果有的话)
# 如果有标签,同时返回特征和标签
if self.labels is not None:
return torch.tensor(self.features[index], dtype=torch.float), torch.tensor(self.labels[index], dtype=torch.float)
# 对于没有标签的测试数据,返回一个占位符张量,例如大小为 1 的零张量
else:
return torch.tensor(self.features[index], dtype=torch.float), torch.zeros(1, dtype=torch.float)
class BinaryClassificationModel(torch.nn.Module):
def __init__(self, input_features):
super(BinaryClassificationModel, self).__init__()
self.linear1 = torch.nn.Linear(input_features, 64)
self.linear2 = torch.nn.Linear(64, 64)
self.linear3 = torch.nn.Linear(64, 1)
def forward(self, x):
x = F.relu(self.linear1(x)) # 第一层激活函数为 ReLU
x = F.relu(self.linear2(x)) # 第二层激活函数为 ReLU
x = self.linear3(x) # 输出层
return torch.sigmoid(x) # 应用 sigmoid 激活函数
# 训练过程
def train(model, train_loader, criterion, optimizer, num_epochs):
epoch_losses = []
print('start training')
for epoch in range(num_epochs):
running_loss = 0.0
# 1. prepare dataset
for i, (inputs, labels) in enumerate(train_loader):
# 2. forward
outputs = model(inputs) # 前向传播
loss = criterion(outputs.squeeze(), labels) # 使用 squeeze 调整输出形状
# 3. backward
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
# 4. update
optimizer.step() # 更新权重
# 乘以 inputs.size(0) 的目的是为了累积整个批次的总损失,而不仅仅是单个数据点的平均损失。
# 调用 loss = criterion(outputs, labels) 时,计算的是当前批次中所有样本的平均损失。
# 为了得到整个训练集上的总损失,我们需要将每个批次的平均损失乘以该批次中的样本数(inputs.size(0))。
# 这样做可以确保每个样本,无论它们属于哪个批次,对总损失的贡献都是平等的。
running_loss += loss.item() * inputs.size(0)
epoch_loss = running_loss / len(train_loader.dataset)
print(f'Epoch {epoch+1}/{num_epochs} Loss: {epoch_loss:.4f}')
epoch_losses.append(epoch_loss)
return epoch_losses
# 测试
def test(model, test_loader, optimizers):
results = []
predictions = []
with torch.no_grad(): # 不计算梯度,减少计算和内存消耗
for inputs, _ in test_loader:
outputs = model(inputs)
# test没有标签,只输出结果
predicted = (outputs > 0.5).float().squeeze()
predictions.extend(predicted.tolist()) # 使用 extend 和 tolist 将 predicted 中的每个元素添加到 predictions
print("Predict result: ", predictions)
results = predictions
return results
# 加载数据
# 训练数据集,没有传入 scaler,因此会创建一个新的
train_dataset = Titantic('train.csv', scaler=None, is_train=True)
train_loader = DataLoader(dataset=train_dataset, batch_size=32, shuffle=True, num_workers=0)
# 测试数据集,传入从训练数据集得到的 scaler
test_dataset = Titantic('test.csv', scaler=train_dataset.scaler, is_train=False)
test_loader = DataLoader(dataset=test_dataset, batch_size=32, shuffle=False, num_workers=0)
# 10个特征PassengerId Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
# 预处理之后7个: Pclass Sex Age SibSp Parch Fare Embarked
model = BinaryClassificationModel(input_features=7)
# 定义损失函数,优化器
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练模型
num_epochs = 100
losses = train(model, train_loader, criterion, optimizer, num_epochs)
# 测试模型
# 已知test的结果保存在 gender_submission.csv 文件中,获取准确的 labels 和 predicted 结果算精度
labels_path = 'gender_submission.csv'
data_frame = pd.read_csv(labels_path)
data_frame.drop(['PassengerId'], axis=1, inplace=True)
labels = data_frame['Survived'].values
print('Test Dataset 正确结果: ', labels)
# 模型预测结果
results = test(model, test_loader, optimizer)
print('Test Dataset 预测结果: ', results)
# 精度计算
# for predicted in results:
accuracy = 100 * (results == labels).sum() / len(results)
print(f'Accuracy: {accuracy:.2f}%')
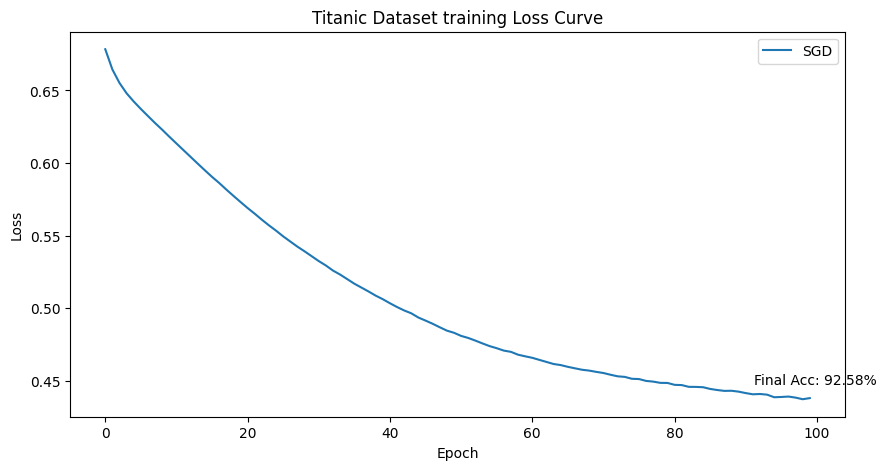
plt.figure(figsize=(10, 5))
plt.plot(losses, label="SGD")
final_accuracy = 100 * (results == labels).sum() / len(results)
plt.annotate(f'Final Acc: {final_accuracy:.2f}%', xy=(num_epochs - 1, losses[-1]), xytext=(-40, 10), textcoords='offset points', fontsize=10)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Titanic Dataset training Loss Curve')
plt.legend()
plt.show()
09. 多分类问题
每个分类输出>=0
和=1
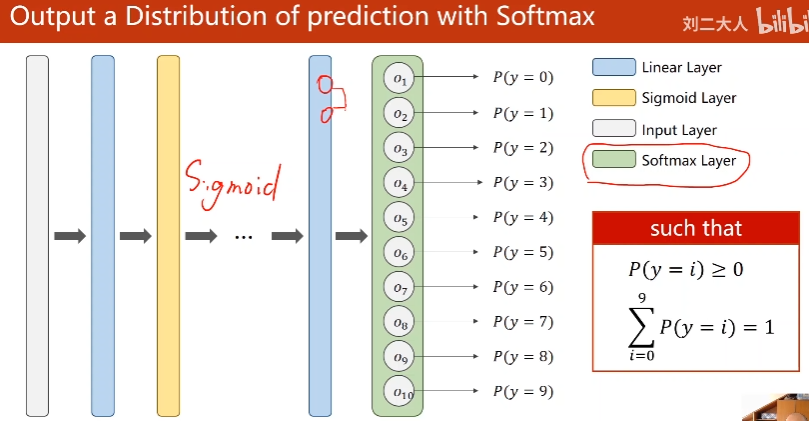
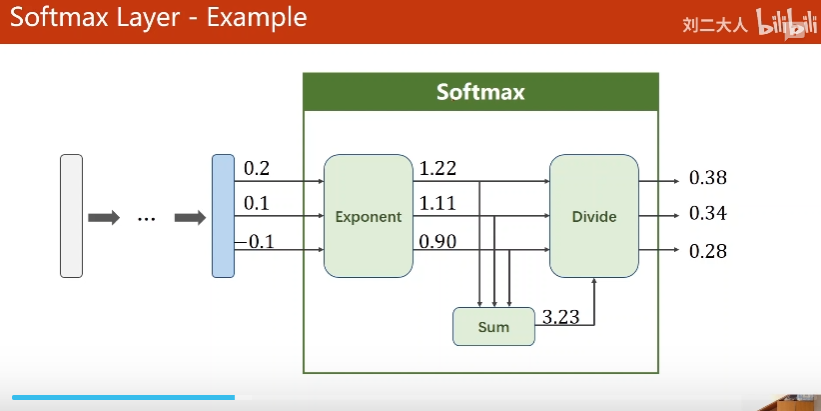
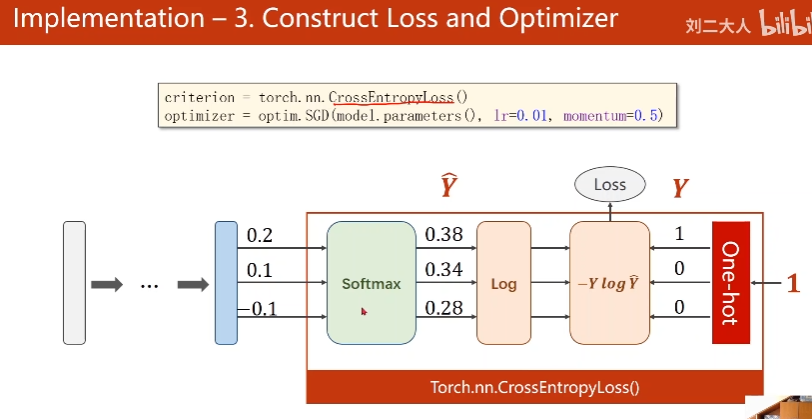
1. Softmax Layer

2. Cross Entropy, NLLLoss
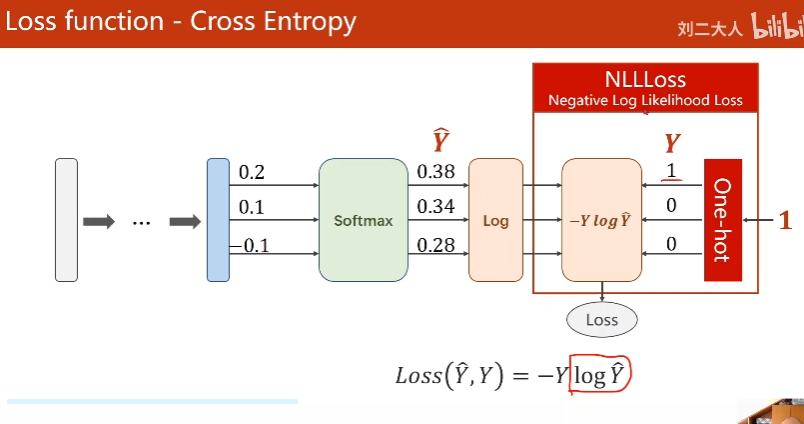
Cross Entropy = LogSoftmax + NLLLoss
最后一层不要用softmax
y是long类型

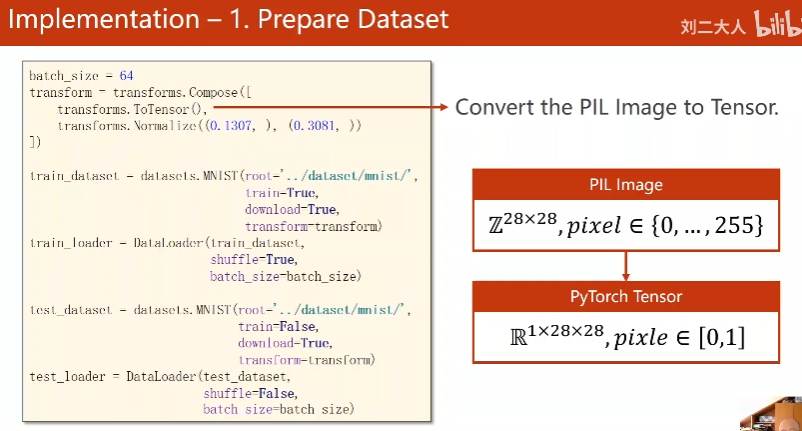
Implementation

transform:
使用Pillow读入图像
希望服从01分布(normalize)
转换为图像张量



9-2作业
# 9
import torch
import pandas as pd
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
class OttoDataset(Dataset):
def __init__(self, filepath, label_filepath, scaler=None, is_train=True):
super(OttoDataset, self).__init__()
self.dataframe = pd.read_csv(filepath)
self.df_label=None
if label_filepath:
self.df_label = pd.read_csv(label_filepath)
self.scaler = scaler
self.check(self.dataframe, is_train)
self.preprocess(self.dataframe, self.df_label, is_train)
def check(self, df, is_train):
if is_train:
print('实验数据大小:',df.shape)
else:
print('预测数据大小:',df.shape)
# print(df.describe())
# print(df.info())
# print(df.isnull().sum())
def preprocess(self, df, df_label, is_train):
if is_train:
self.scaler = StandardScaler()
self.labels = torch.tensor(df['target'].apply(lambda x: int(x.split('_')[-1]) - 1).values, dtype=torch.long)
self.features = torch.tensor(self.scaler.fit_transform(df.drop(['id','target'], axis=1).values), dtype=torch.float32)
else:
self.features = torch.tensor(self.scaler.transform(df.drop(['id'], axis=1).values), dtype=torch.float32)
self.labels = torch.tensor(df_label.iloc[:, 1:].values.argmax(axis=1), dtype=torch.long)
def __len__(self):
return len(self.dataframe)
def __getitem__(self, index):
return torch.tensor(self.features[index], dtype=torch.float), torch.tensor(self.labels[index], dtype=torch.long)
batch_size = 64
train_dataset = OttoDataset(filepath='train.csv', label_filepath=None, scaler=None, is_train=True)
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
print(len(train_dataset))
test_dataset = OttoDataset(filepath='test.csv', label_filepath='otto_correct_submission.csv' ,scaler=train_dataset.scaler, is_train=False)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
# design model
class Net(torch.nn.Module):
def __init__(self, input_features, output_features):
super(Net, self).__init__()
self.linear1 = torch.nn.Linear(input_features, 64)
self.linear2 = torch.nn.Linear(64, 32)
self.linear3 = torch.nn.Linear(32, 16)
self.linear4 = torch.nn.Linear(16, output_features)
# 定义 batchnorm 层,帮助稳定学习过程
self.batchnorm1 = torch.nn.BatchNorm1d(64)
self.batchnorm2 = torch.nn.BatchNorm1d(32)
self.batchnorm3 = torch.nn.BatchNorm1d(16)
# 定义 dropout 层,可以减少过拟合
self.dropout = torch.nn.Dropout(p=0.3)
def forward(self, x):
x = F.relu(self.batchnorm1(self.linear1(x)))
x = self.dropout(x)
x = F.relu(self.batchnorm2(self.linear2(x)))
x = self.dropout(x)
x = F.relu(self.batchnorm3(self.linear3(x)))
x = self.dropout(x)
x = self.linear4(x) # 不用激活函数,因为 torch.nn.CrossEntropyLoss = softmax + nllloss
return x
model = Net(input_features=93, output_features=9)
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# training
'''epoch=100
batch_size=64
sample_size=49502
773
'''
def train(epoch):
model.train()
running_loss = 0.0
correct = 0
total = 0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
_, predicted = torch.max(outputs.data, dim=1)
correct += (predicted == target).sum().item()
total += target.size(0)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
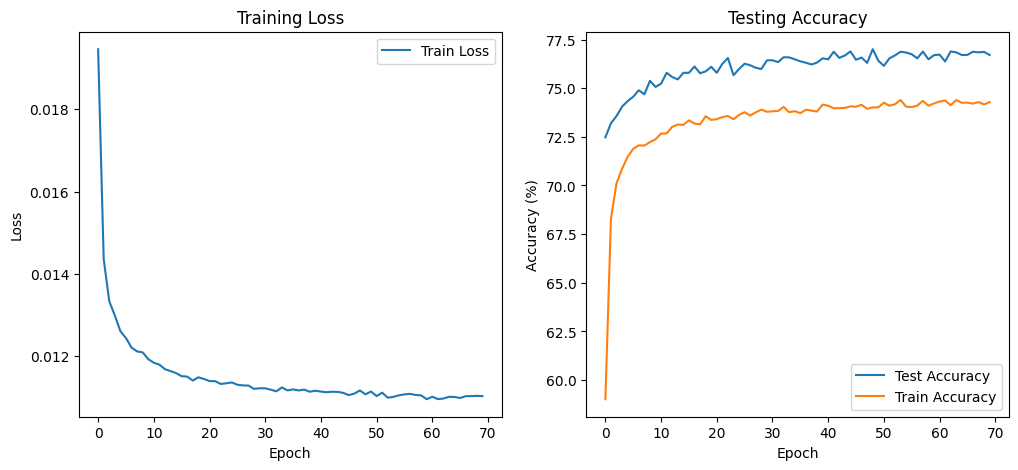
average_loss = running_loss / total
accuracy = 100 * (correct / total)
return average_loss, accuracy
# test
def test():
model.eval()
'''
简介:
model.eval()是PyTorch中的一个方法,用于将模型设置为评估模式(evaluation mode)。一般情况下,当我们完成模型的训练并准备对其进行评估、测试或推断时,会调用该方法。
作用:
调用model.eval()的作用是将模型中的某些特定层或部分切换到评估模式。在评估模式下,一些层的行为会发生变化,例如Dropout层和BatchNorm层等。这些层在训练和推断过程中的行为是不同的,因此在评估模式下需要将它们关闭。调用model.eval()会自动关闭这些层,确保在评估模型时得到正确的结果。
在进行模型评估或验证时,常见的做法是将model.eval()与torch.no_grad()结合使用,以关闭梯度计算。这样可以提高评估的效率,因为在评估阶段不需要进行梯度更新。
'''
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, labels = data
outputs = model(inputs)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * (correct / total)
print("Accuracy on test data is {:.2f}".format(accuracy))
return accuracy
# print('Accuracy on test set: %d %%' %(100*correct/total))
if __name__ == '__main__':
train_losses = []
test_accuracies = []
train_accuracies = []
for epoch in range(70):
train_loss, acc = train(epoch)
train_losses.append(train_loss)
train_accuracies.append(acc)
# if epoch % 10 == 0:
test_accuracy = test()
test_accuracies.append(test_accuracy)
# test()
# Visualize
plt.figure(figsize=(12, 5))
# Loss Curve
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='Train Loss')
plt.title('Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
# Accuracy Curve
plt.subplot(1, 2, 2)
plt.plot( test_accuracies, label='Test Accuracy') # Adjust x-axis for test accuracy
plt.plot( train_accuracies, label='Train Accuracy') # Adjust x-axis for test accuracy
plt.title('Testing Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.show()
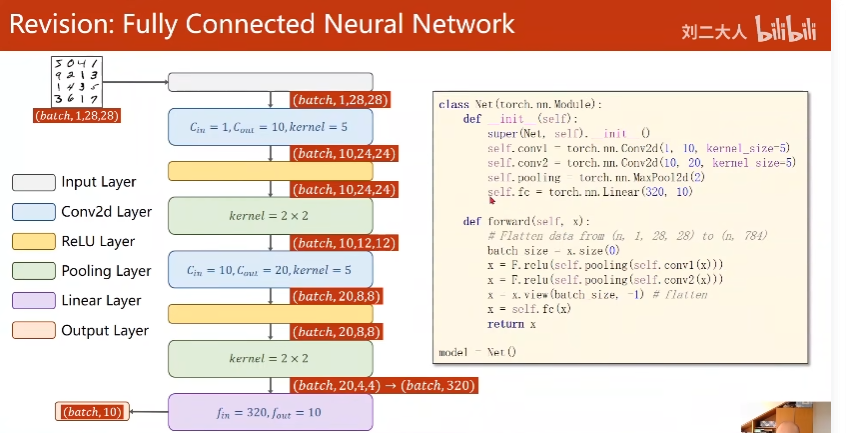
10. Basic CNN
上一讲全连接神经网络:
由线性层连起来
每个节点之间都有权重

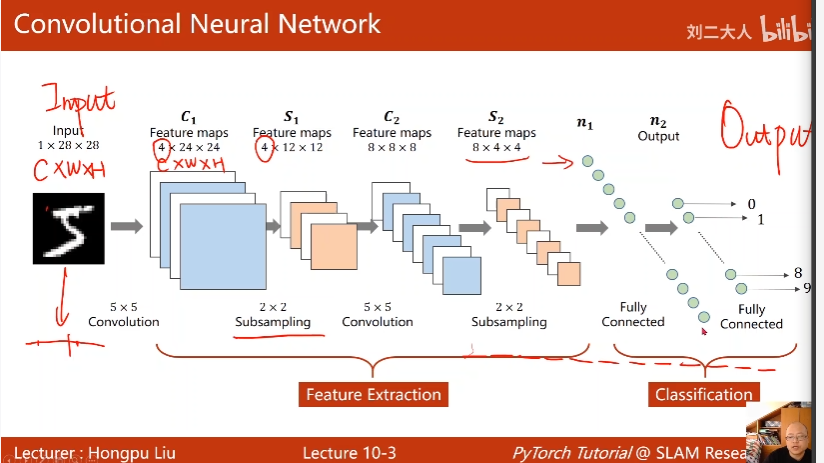
1. Convolutional Neural Network总览
全连接神经网络变成一维
CNN保留空间维度信息
先Feature Extraction再Classification
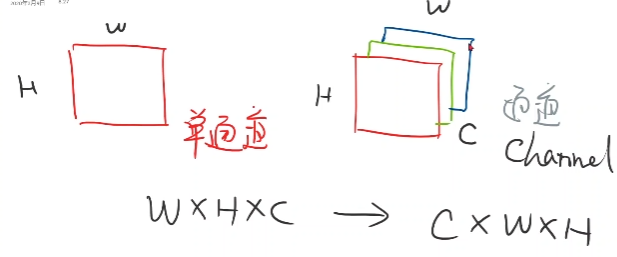
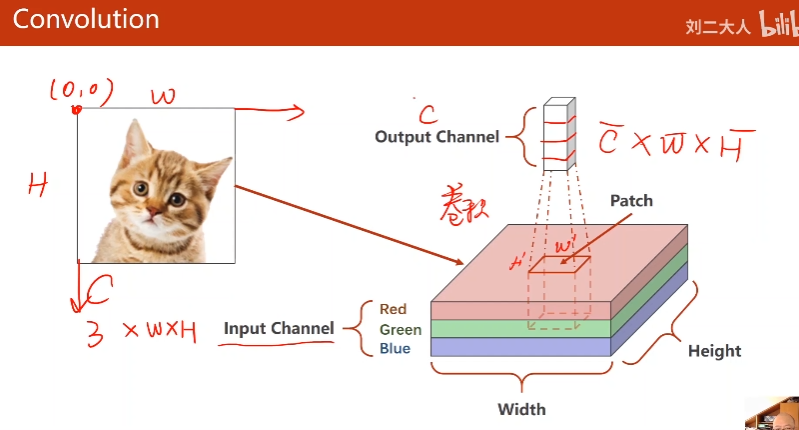
2. 图像
- 栅格图像:
电阻值到灰度数据的转变
RGB通道- 矢量图像:
现画的
input channel 不一定等于output channel
w,h不一定等于w’,h’
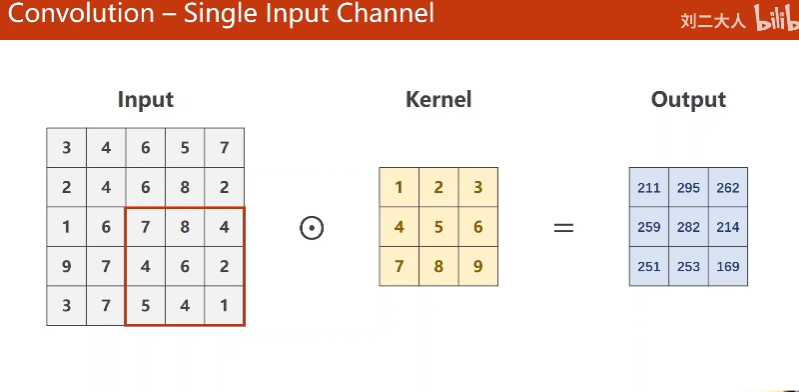
4.Convolution - Single Input Channel
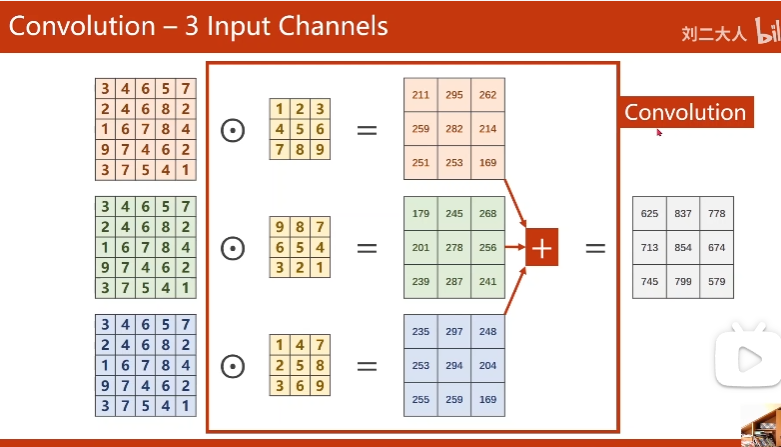
5. Convolution - 3 Input Channels
中间过程可能有多channel
一个channel, 一个核
图像里patch和核数乘,再求和
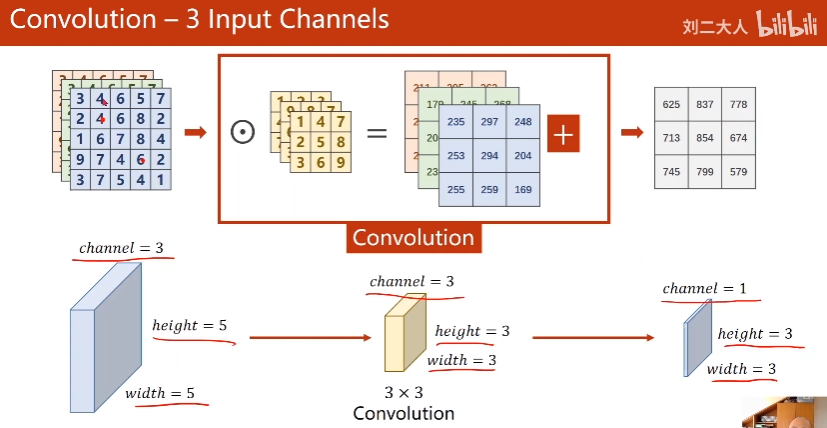
6. Convolution - N Input Channels
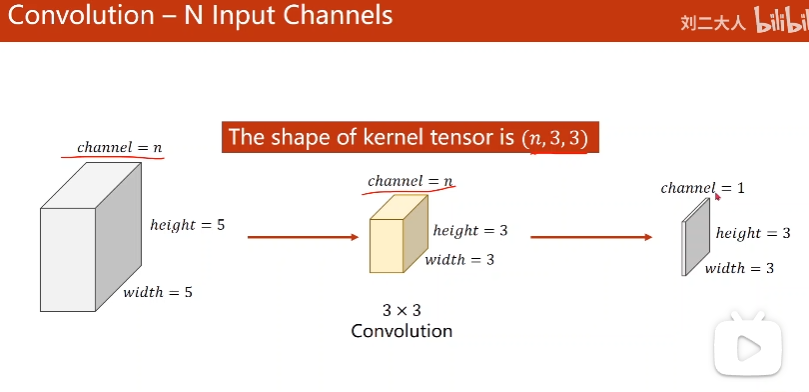
7. Convolution - N Input Channels and M Output Channels
一个核一个output
核数量 = # Output Channels
每个核的channel数 = # Input Channels
核维度自己定义

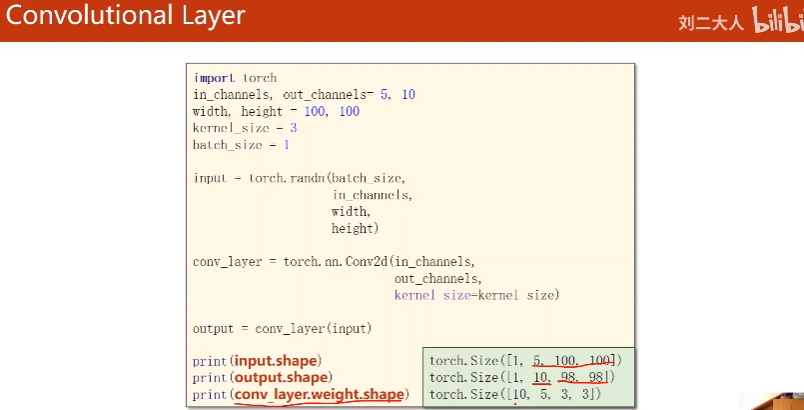
8. Implementation
randn:
取正态分布的随机数
kernal_size:
一般正方形,边长奇数。也可输入元组卷积层对输入图像大小没要求
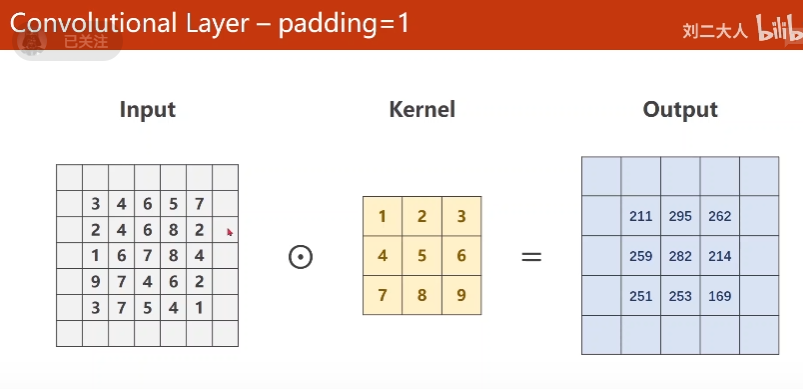
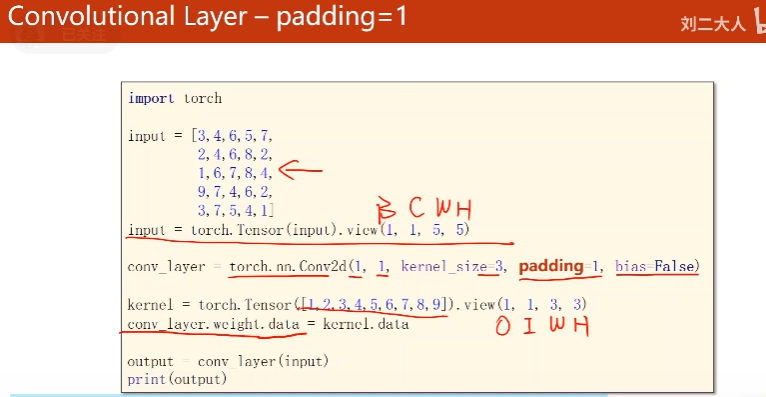
10.1 Convolutional Layer - Padding
根据输入大小和输出大小进行Padding
3 * 3 ,1圈
5 * 5 , 2圈
一般padding 0
10.2 Convolutional Layer - Stride
可以减少输出的w, h
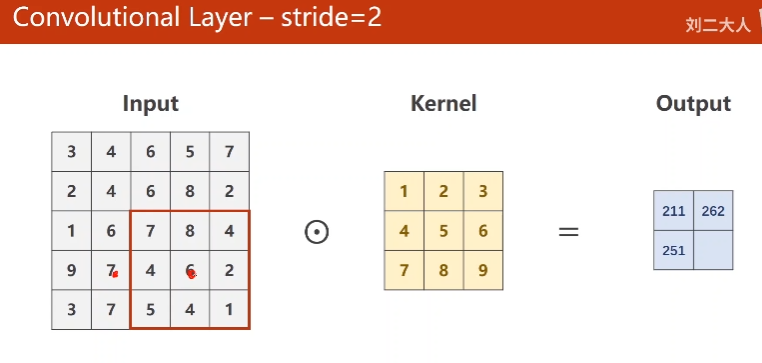
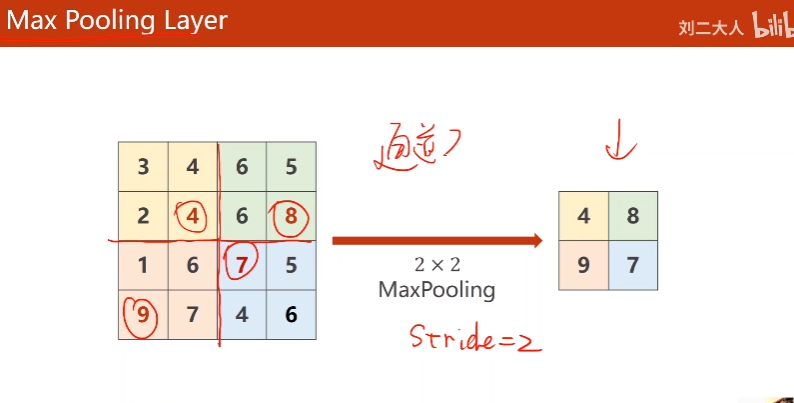
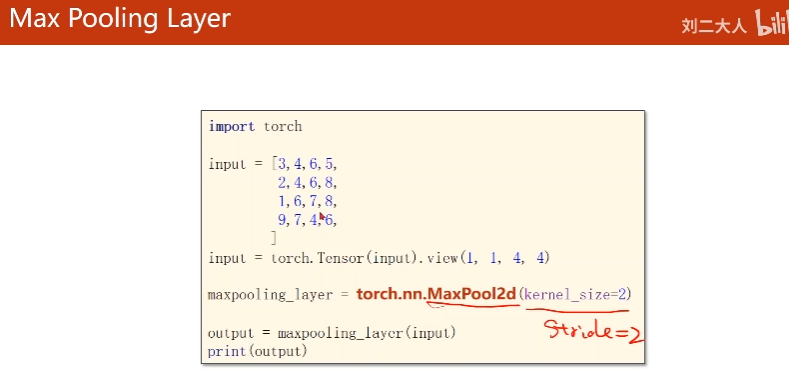
11. Max Pooling Layer(Downsampleing)
这里maxpooling(2 * 2)默认stride=2
channel数不变
12. A Simple Convolutional Nerual Network
关键是全连接神经网络之前的维度是多少
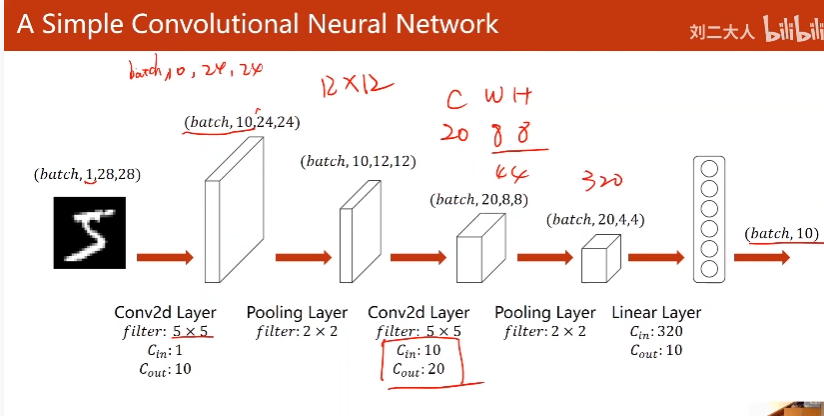
图中先Relu再MaxPooling
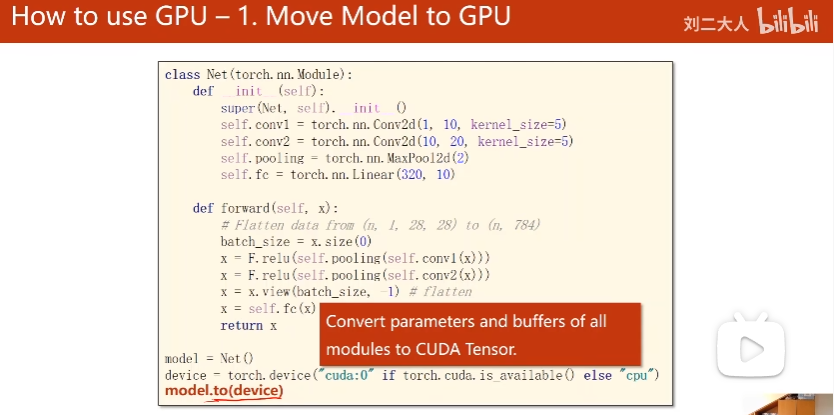
GPU
cpu的模型迁移到gpu
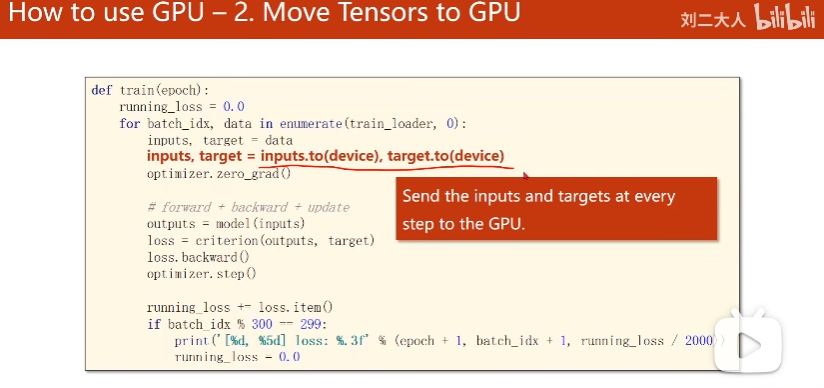
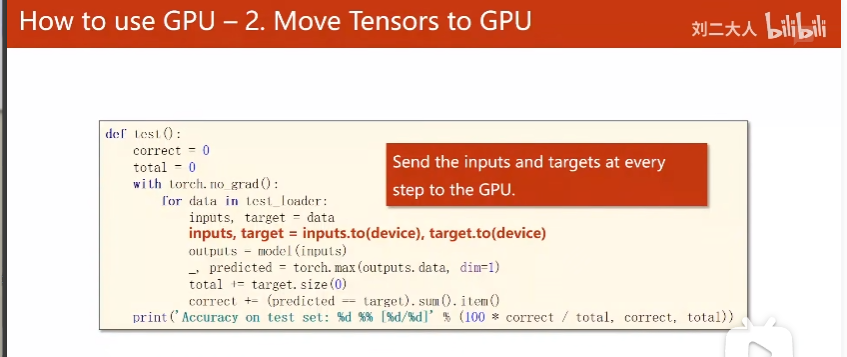
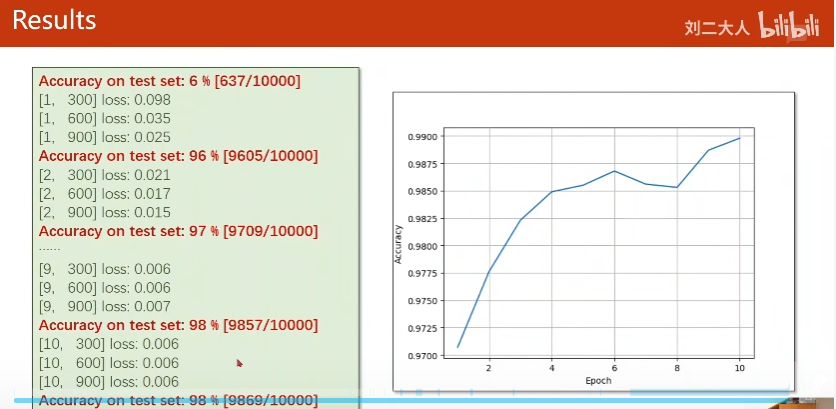
10-1作业

# 10-1
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
# prepare dataset
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST('data/MNIST/', train=True, transform=transform, download=True)
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_dataset = datasets.MNIST('data/MNIST/', train=False, transform=transform, download=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
# design model using class
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=3)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=3)
self.conv3 = torch.nn.Conv2d(20, 30, kernel_size=3)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(30, 10)
def forward(self, x):
# flatten data from (n,1,28,28) to (n, 784)
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = F.relu(self.pooling(self.conv3(x)))
x = x.view(batch_size, -1) # -1 此处自动算出的是320
# print("x.shape",x.shape)
x = self.fc(x)
return x
model = Net()
#使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def hehe():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100 * correct / total))
return correct / total
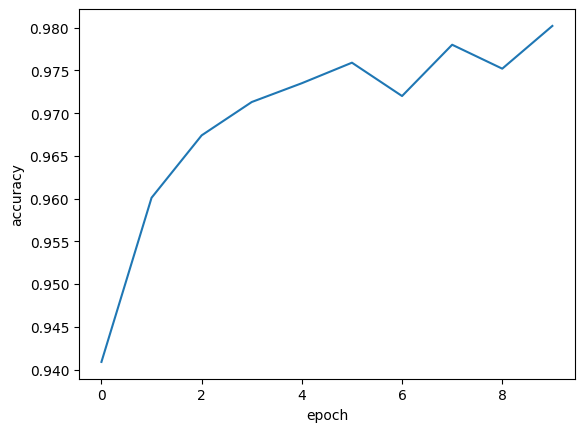
if __name__ == '__main__':
epoch_list = []
acc_list = []
for epoch in range(10):
train(epoch)
acc = hehe()
epoch_list.append(epoch)
acc_list.append(acc)
plt.plot(epoch_list, acc_list)
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.show()
11. Advanced CNN
1. GoogleNet
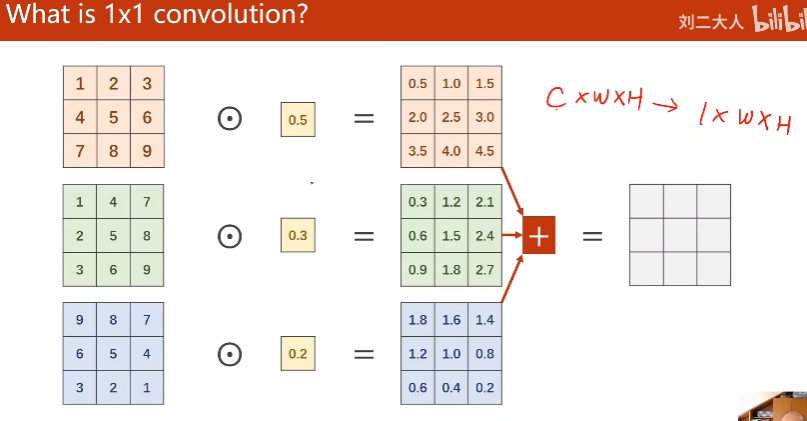
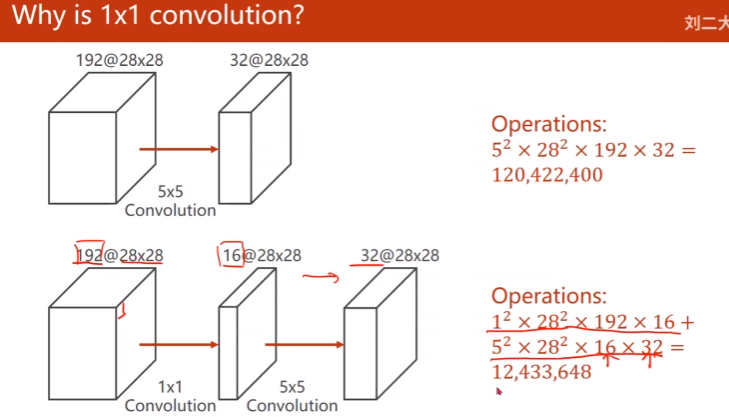
1 * 1卷积核
每一个点包含了所有输入图像那个点的信息
作用:改变通道数量
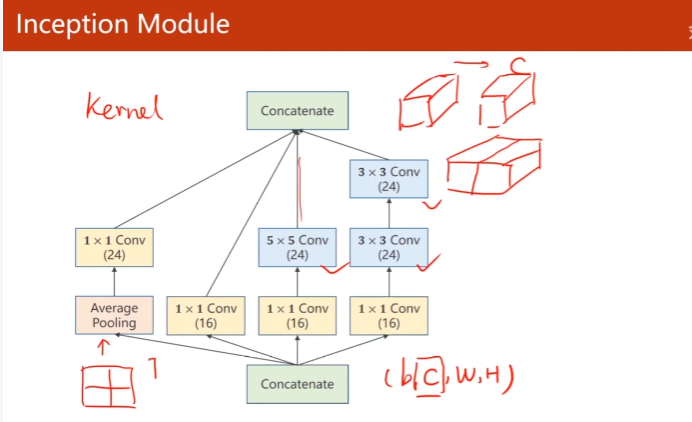
减少训练计算次数
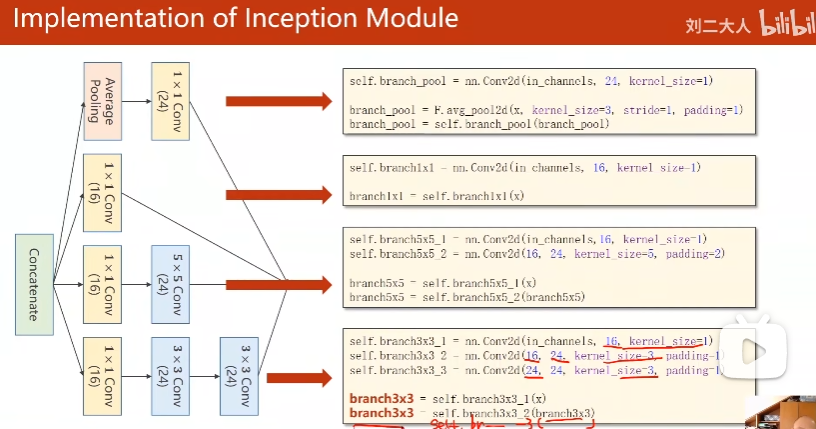
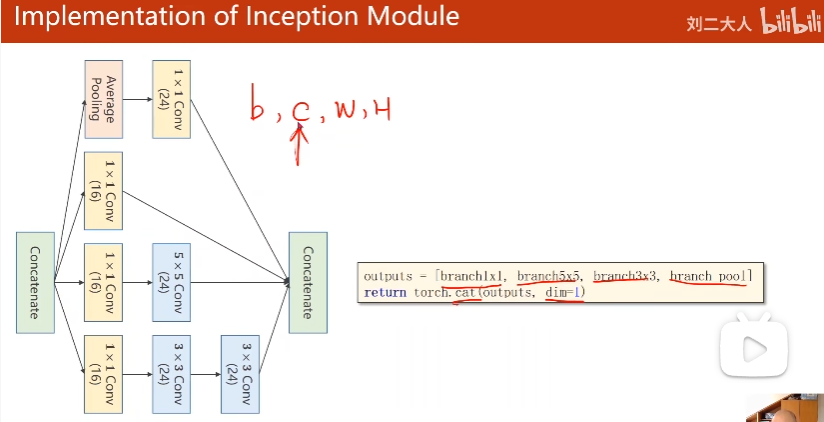
沿着通道拼接
(b, c, w, h)
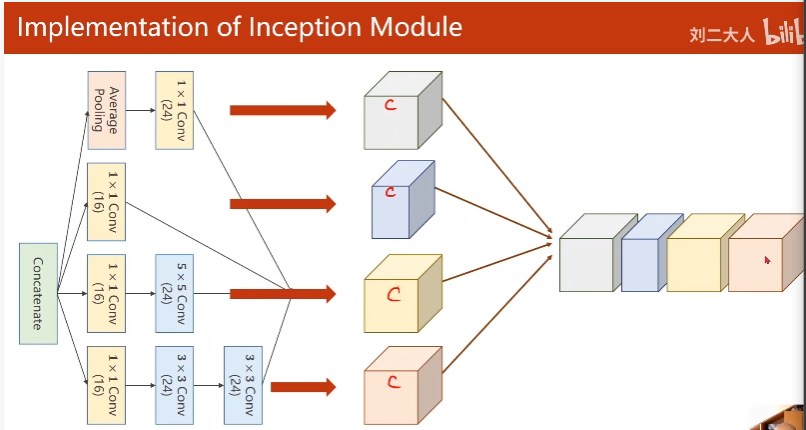
输出通道88

准确率提高不多,可能在于全连接层设计不多
test准确率上升再下降。将test准确率最高时的模型存盘。
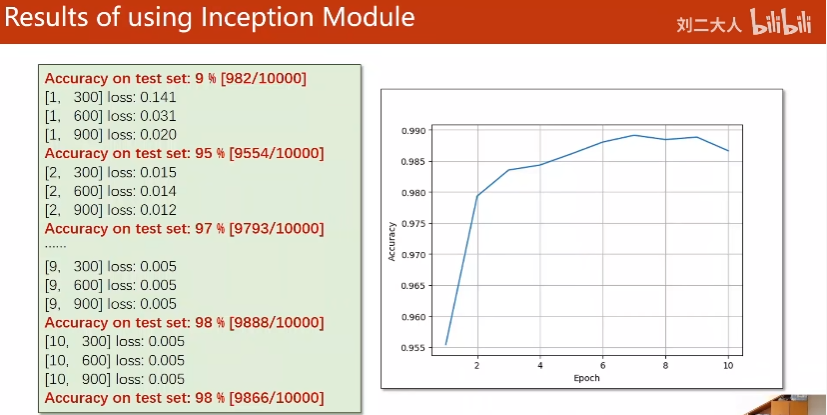
2. Stack layers
梯度消失:
假如梯度<1,链式法则会导致梯度趋近于0,导致无法更新
解决方案:逐层训练
3. Residual Network
为了解决梯度下降问题
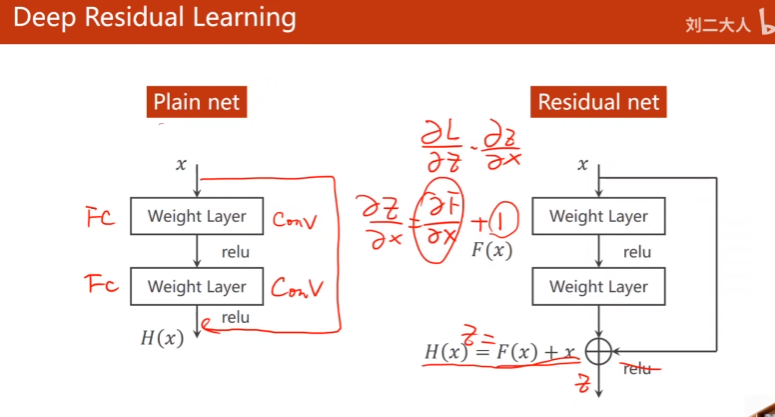
residual block输入和输出维度相同
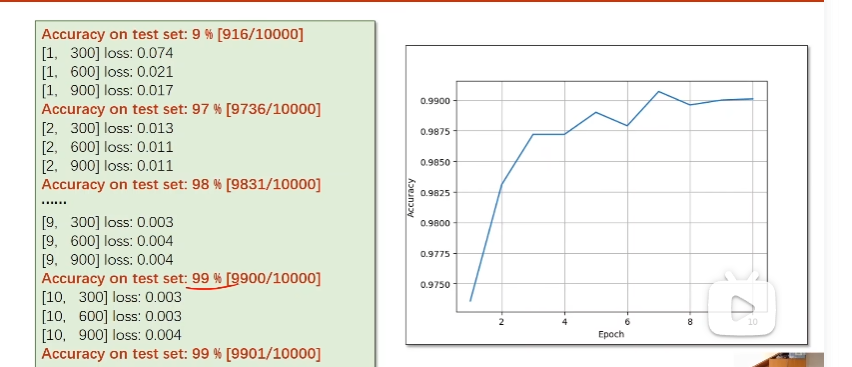
11-1作业
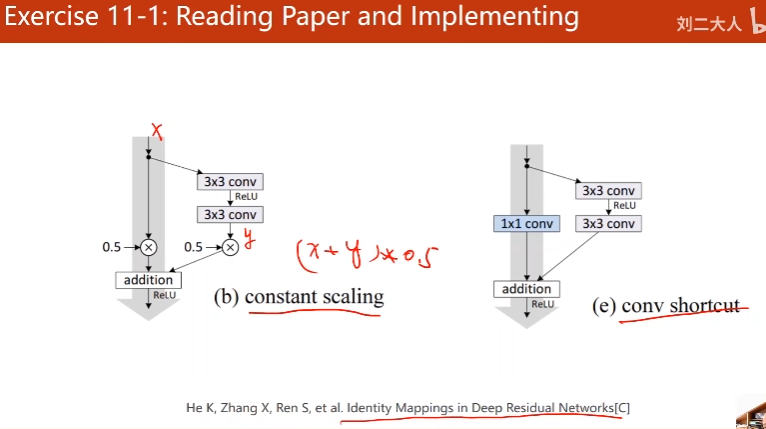
11.2作业
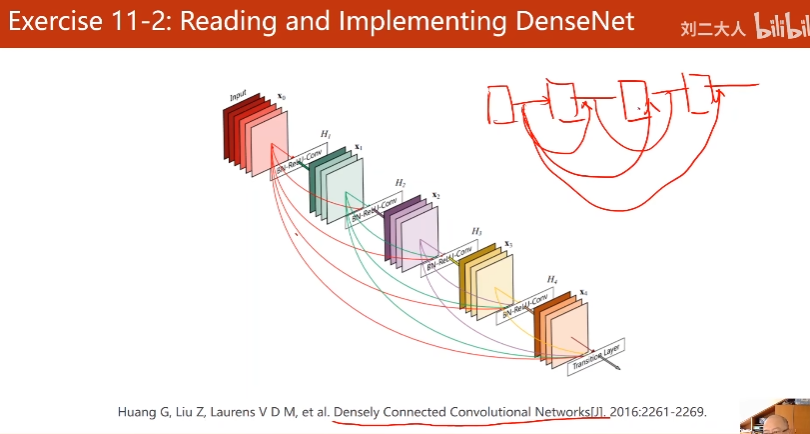
12. Basic RNN
DNN:全连接神经网络
权重最多
RNN:
处理有序列关系的数据
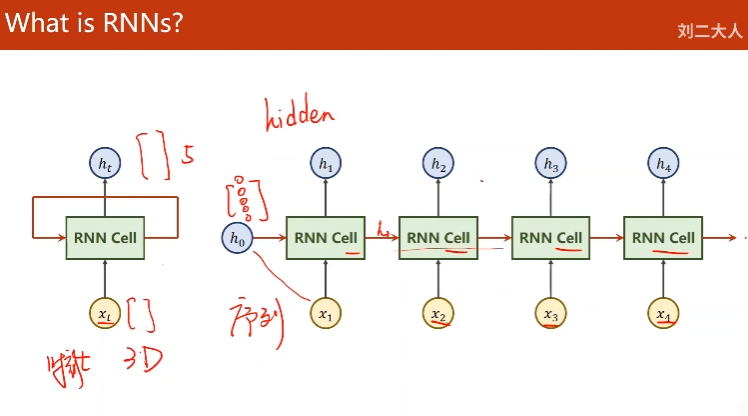
tanh [-1, 1]
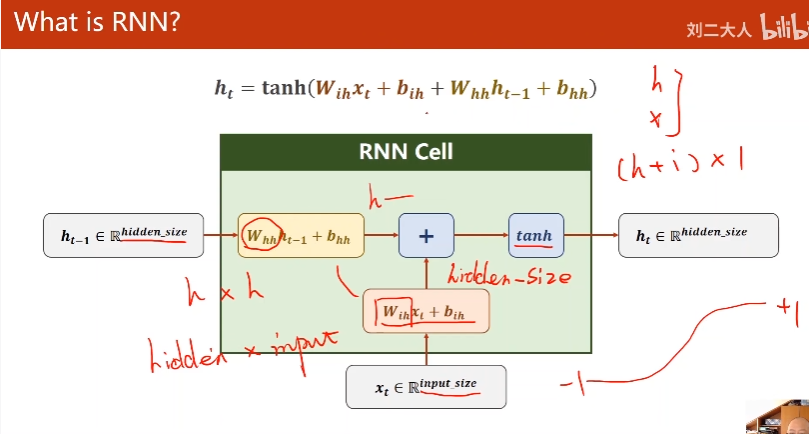
确定一个RNN cell 需要两个维度input, hidden size

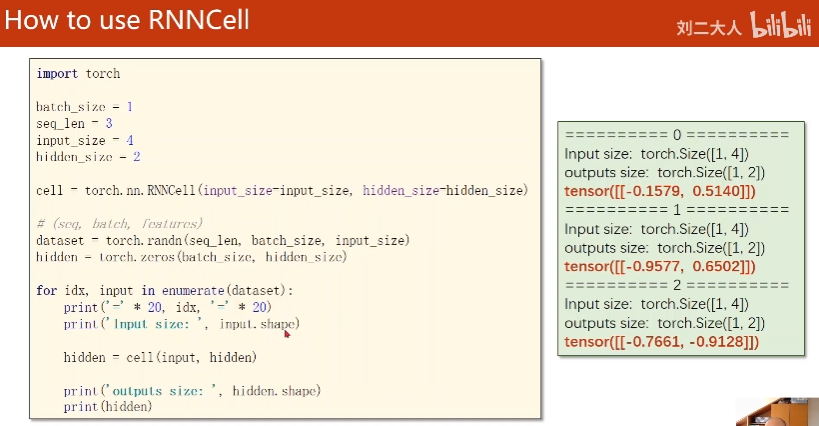

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









