







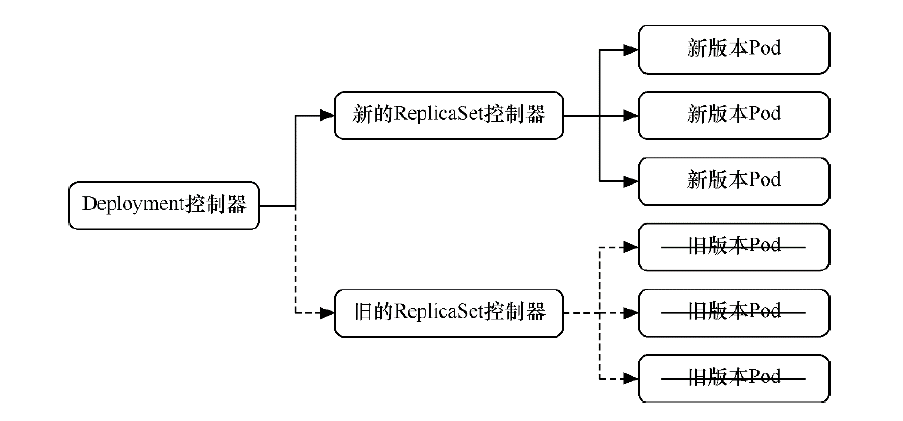
控制器
一般来说用户不会直接创建pod,而是创建控制器。控制器通过标签选择器来管理pod。控制器会创建出满足条件的Pod,并确保每一个Pod资源处于用户期望的目标状态。如果Pod资源在运行中出现故障,它会基于指定策略重新编排Pod。按照pod的创建方式可以将其分为两类:
自主式pod:kubernetes直接创建出来的pod,不被控制器管理,创建后一旦死亡或被删除不会被重新创建。
控制器管理的pod:kubernetes通过控制器创建的pod,被控制器管理,用来控制pod的具体状态和行为,在控制器的生命周期里,始终维持pod的副本数。
Pod控制器循环监控集群中运行着的Pod资源对象,来确保受其管控的资源对象严格符合用户期望的状态,使当前状态不断地向期望状态和解(reconciliation)来完成容器应用管理。每个控制器均通过API Server提供的接口持续监控相关资源对象的当前状态,并在因故障、更新或其他原因导致系统状态发生变化时,尝试让资源的当前状态向期望状态迁移和逼近。
for {
desired := getDesiredState() // 期望的状态
current := getCurrentState() // 当前实际状态
if current == desired { // 如果状态一致则什么都不做
// nothing to do
} else { // 如果状态不一致则调整编排,到一致为止
// change current to desired status
}
}
期望状态一般来自于用户提交的 YAML 文件。比如Deployment 控制器从 Etcd 中获取到所有携带了app: nginx标签的 Pod,然后统计它们的数量,这就是实际状态。Deployment 对象的 Replicas 字段的值就是期望状态,Deployment 控制器将两个状态做比较,然后根据比较结果,确定是创建 Pod,还是删除已有的 Pod
像 Deployment 这种控制器的设计原理,就是用一种对象管理另一种对象的艺术。由上半部分的控制器定义(包括期望状态),加上下半部分的被控制对象的模板组成的。其中,这个控制器对象本身,负责定义被管理对象的期望状态。比如,Deployment 里的 replicas=2 这个字段。而被控制对象的定义,则来自于一个模板PodTemplate。Deployment 这个 template 字段里的内容,跟一个标准的 Pod 对象的 API 定义丝毫不差。而所有被这个 Deployment 管理的 Pod 实例,其实都是根据这个 template 字段的内容创建出来的。

控制器的工作原理
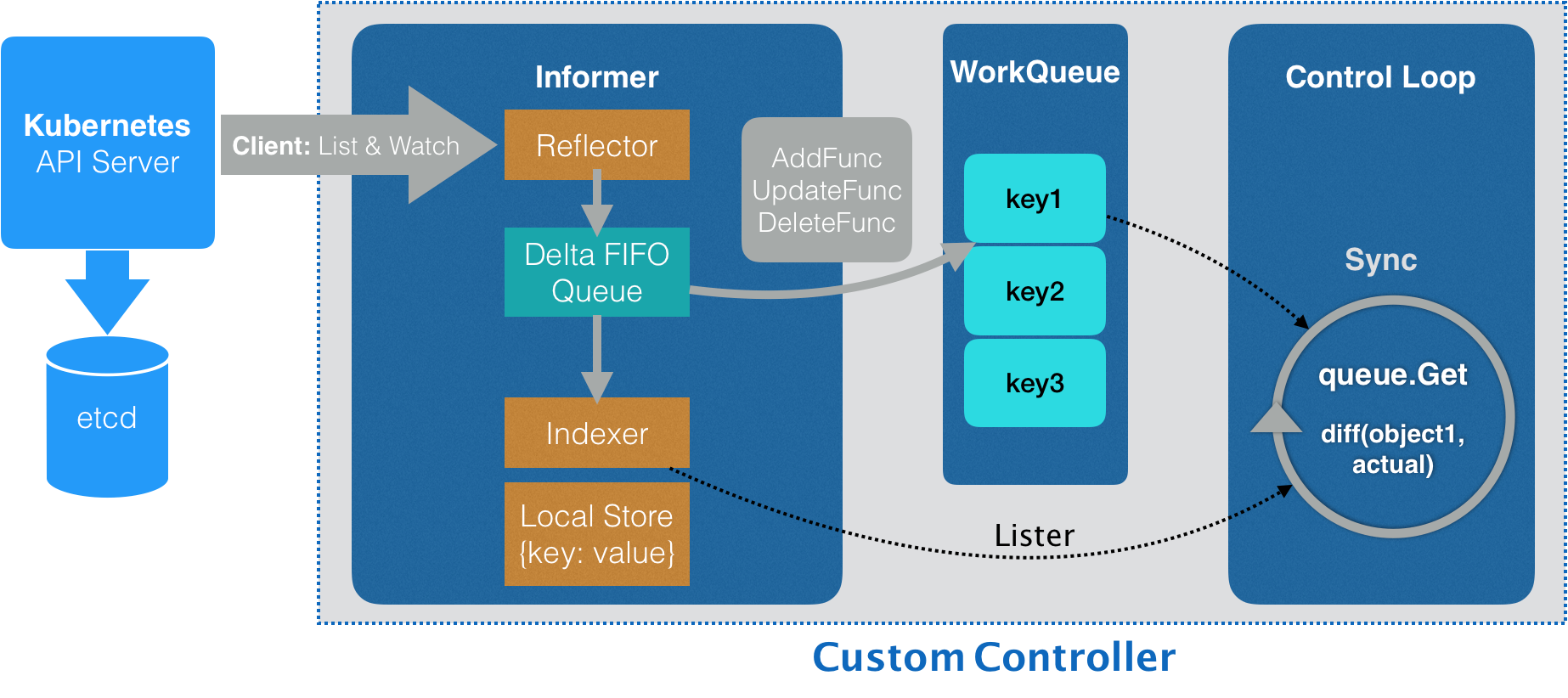
ReplicaSet
ReplicaSet的核心任务是保持Pod应用的副本数与用户定义的数量一致。如果副本数不足,ReplicaSet会自动创建新的Pod,而如果超出了定义的数量,它会负责自动回收多余的Pod。在Pod发生故障时,ReplicaSet会主动监测运行状态,并自动进行重启或重建,确保应用的稳定性。此外,ReplicaSet还支持对Pod自动扩缩容和镜像版本的升降级。ReplicaSet是ReplicationController的升级版
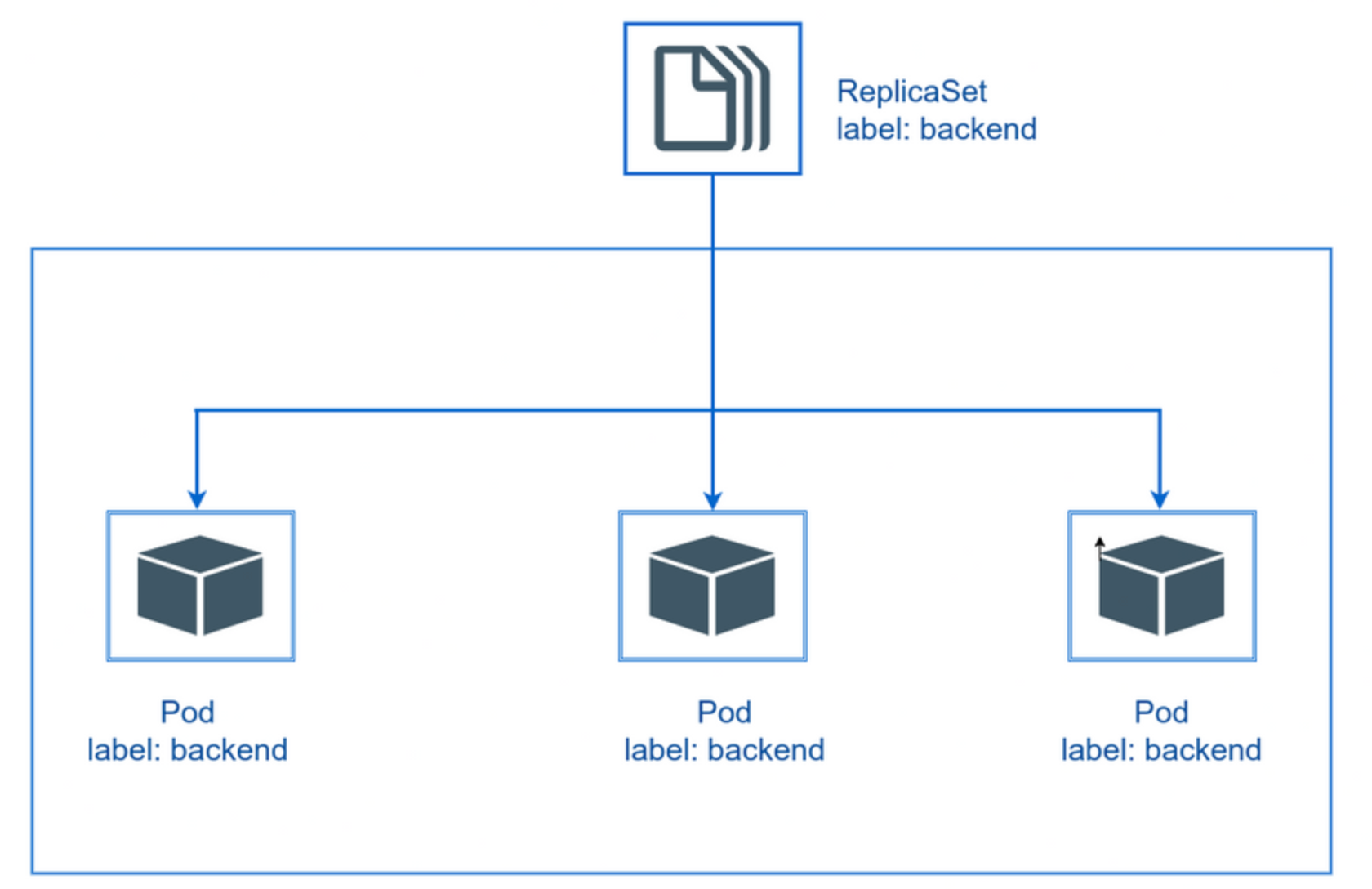
ReplicaSet创建
创建一个ReplicaSet示例
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1 #版本号
kind: ReplicaSet #类型
metadata: #元数据信息
name: replica-set #RS的名称
namespace: default #名称空间,默认default
#labels: #控制器标签
# key: value
spec: #详细信息
replicas: 3 #期望的pod副本数,这里是3个副本
selector: #标签选择器,通过它指定该控制器管理哪些pod
matchLabels: #Labels匹配规则
app: bakend #k:v,通过这个标签来确定这些pod被控制器所管理,pod创建将以此标签命名,管理的是具有 app=bakend 的pod
template: #模板,当副本数量不足时,会根据下面的模板创建pod副本
#template模板下面的内容其实就是自主式pod的模板,嵌套在控制器内,所以apiVersion、kind;name、namespace都可以省略不写
#apiVersion: v1
#kind: Pod
metadata:
#name: #pod名称会根据rs名称自动生成,pod的名称是在控制器名称后面拼接了-xxxxx随机码
#namespace:
labels:
app: bakend #此处的标签一定要跟上面的 metchLables 保持一致,通过标签进行管理
spec:
containers: #容器
- name: nginx #容器名
image: nginx #镜像
ports:
- containerPort: 80 #容器端口
EOF
从我们上面的清单文件中可以看到,我们有带标签的 Pod app:backend,并且在 ReplicaSet 中有一个带 matchLabels 的选项app:backend。这意味着借助 Kubernetes 功能之一 与之pods关联。带标签的 Pod仅与我们使用清单文件创建的副本集相关联。
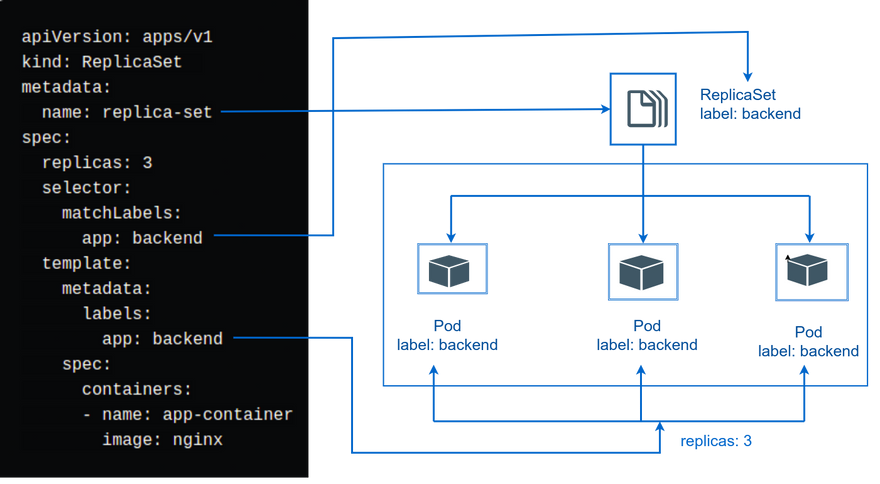
查看创建好的ReplicaSet,可以看到当前资源对象的描述信息
[root@master ~]# kubectl get rs replica-set -owide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
replica-set 3 3 3 22s nginx nginx app=bakend
# DESIRED:用户期望的副本数量
# CURRENT:当前处于running状态的pod个数
# READY:已经准备好提供服务的副本数量
查看当前控制器创建出来的pod,控制器创建出来的pod的名称是在控制器名称后面拼接了 -xxxxx 随机码
[root@master ~]# kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
replica-set-f9dxx 1/1 Running 0 58s 10.244.104.57 node2 <none> <none>
replica-set-f9gfj 1/1 Running 0 58s 10.244.166.179 node1 <none> <none>
replica-set-fmr9l 1/1 Running 0 58s 10.244.104.56 node2 <none> <none>
查看标签信息,控制器通过使用标签选择器来关联和管理一组 Pod
[root@master ~]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
replica-set-f9dxx 1/1 Running 0 90s app=bakend
replica-set-f9gfj 1/1 Running 0 90s app=bakend
replica-set-fmr9l 1/1 Running 0 90s app=bakend
修改其中一个pod的标签,该 Pod 将不再匹配 ReplicaSet 的选择器,ReplicaSet 就会认为它不再是它所管理的 Pod 之一,然后ReplicaSet会尝试通过创建新的Pod来满足用户定义的副本数,以确保符合期望的状态
[root@master ~]# kubectl label pod replica-set-f9dxx app=nginx --overwrite=True
[root@master ~]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
replica-set-f9dxx 1/1 Running 0 4m55s app=nginx
replica-set-f9gfj 1/1 Running 0 4m55s app=bakend
replica-set-fmr9l 1/1 Running 0 4m55s app=bakend
replica-set-gwhmc 1/1 Running 0 19s app=bakend
扩缩容
在Kubernetes中,通过kubectl edit修改副本数之后,Kubernetes会尝试根据你的更改逐渐更新Pod的实例数,以确保平滑的滚动更新而不会导致服务中断
[root@localhost ~]# kubectl edit rs replica-set #修改副本数,比如改成5个副本。修改 spec:replicas: 5 即可
[root@localhost ~]# kubectl get pods #pod变成5个,达到扩容
NAME READY STATUS RESTARTS AGE
replica-set-f9gfj 1/1 Running 0 7m22s
replica-set-fmr9l 1/1 Running 0 7m22s
replica-set-gn6b9 1/1 Running 0 34s
replica-set-gwhmc 1/1 Running 0 2m46s
replica-set-lnbdh 1/1 Running 0 34s
也可以直接使用scale命令实现扩缩容,后面 --replicas=n 直接指定目标数量即可
[root@localhost ~]# kubectl scale rs replica-set --replicas=2
[root@localhost ~]# kubectl get pod #命令执行完毕立即查看,发现已经有3个开始准备退出了
NAME READY STATUS RESTARTS AGE
replica-set-f9gfj 1/1 Running 0 10m
replica-set-fmr9l 1/1 Running 0 10m
replica-set-f9dxx 0/1 Terminating 0 28m
replica-set-gn6b9 0/1 Terminating 0 28m
replica-set-lnbdh 0/1 Terminating 0 34s
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
replica-set-f9gfj 1/1 Running 0 10m
replica-set-fmr9l 1/1 Running 0 10m
镜像升级
使用edit命令编辑Pod的镜像时,则不会立即生效,Kubernetes不会自动更改正在运行的容器的镜像,因为这可能会影响正在运行的应用程序。您需要手动更新Pod的镜像版本,并重启Pod中的容器以应用更改,可以使用delete命令,使其自动创建
kubectl edit rs replica-set #修改镜像使其更新,编辑rs的容器镜像 - image: nginx:1.17.2
查看镜像版本是否修改成功
[root@master ~]# kubectl get rs replica-set -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
replica-set 2 2 2 18m nginx nginx:1.17.2 app=bakend
查看当前pod镜像版本
[root@master ~]# kubectl describe pod replica-set-f9gfj | grep 'Image:'
Image: nginx
edit编辑更新镜像需要手动删除pod才会生效
kubectl scale rs replica-set --replicas=0
kubectl scale rs replica-set --replicas=2
再次查看pod的镜像版本发现已经完成更新
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
replica-set-jkdnq 1/1 Running 0 66s
replica-set-zqtjx 1/1 Running 0 66s
[root@master ~]# kubectl describe pod replica-set-jkdnq | grep 'Image:'
Image: nginx:1.17.2
通过使用kubectl set image命令来更新Pod的镜像版本
#kubectl set image rs rs名称 容器=镜像版本 -n namespace
kubectl set image rs replica-set nginx=nginx:1.17.1
发现pod版本没有发生变化,只有重建版本才能更新
[root@master ~]# kubectl get rs -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
replica-set 2 2 2 25m nginx nginx:1.17.1 app=bakend
[root@master ~]# kubectl describe pod replica-set-jkdnq | grep 'Image:'
Image: nginx:1.17.2
[root@master ~]# kubectl delete pod replica-set-jkdnq replica-set-zqtjx
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
replica-set-cwjr5 1/1 Running 0 36s
replica-set-j25z9 1/1 Running 0 36s
[root@master ~]# kubectl describe pod replica-set-cwjr5 | grep 'Image:'
Image: nginx:1.17.1
在Kubernetes中,使用edit命令编辑Pod的副本数时,更改将立即生效并且自动更新Pod的副本数。这是因为Pod的副本数是由ReplicaSet控制器管理的,当副本数被更改时,ReplicaSet会自动根据最新的配置调整Pod的副本数。而编辑Pod的镜像时,则不会立即生效,需要手动更新Pod的镜像版本。在编辑Pod的配置时,Kubernetes不会自动更改正在运行的容器的镜像,因为这可能会影响正在运行的应用程序。相反,您需要手动更新Pod的镜像版本,并重启Pod中的容器以应用更改。您可以通过使用kubectl set image命令来更新Pod的镜像版本
删除
被控制器管理的pod删除后,控制器会自动创建新的Pod以确保所需的副本数仍然满足。这个就是上面我们所说的 ReplicaSet 控制器为我们做的工作,现在pod是2个副本,将pod删除,这个时候 ReplicaSet 控制器监控到控制的 Pod 数量和期望的 2 不一致,所以就需要启动新的 Pod 来保持 2 个副本,这个过程上面我们说了就是调谐的过程。
[root@master ~]# kubectl delete pod --all #--all删除所有default名称空间下的pod
pod "replica-set-jkdnq" deleted
pod "replica-set-j25z9" deleted
[root@master ~]# kubectl get pod
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
replica-set-5wrzb 1/1 Running 0 7s
replica-set-tvpk5 1/1 Running 0 7s
我们可以随便查看一个 Pod 所属的控制器
[root@master ~]# kubectl describe pod replica-set-5wrzb | grep Controlled
Controlled By: ReplicaSet/replica-set
#查看metadata.ownerReferences下面的内容
[root@master ~]# kubectl get pod replica-set-5wrzb -o yaml | grep -A6 ownerReferences
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: replica-set
uid: 414fbe0e-433f-413c-9f95-ed36d14bc6cc
owner主要是被集群中的垃圾收集器使用,在删除所有者对象时,它所拥有的子对象也会被自动删除。删除ReplicaSet,会以ReplicaSet为资源者的对象给删除掉,也就是删除rs会附带删除这个pod。
ownerReferences用于建立对象之间的所有权关系,即用来表示一个Kubernetes对象是否拥有另一个对象。当一个对象被标记为另一个对象的所有者(owner)时,它将被认为是该对象的子对象(child),并且在删除该父对象时,它的子对象也会被自动删除。这种所有权关系通常用于管理一组相关对象的生命周期,例如当您使用Deployment或StatefulSet控制器创建Pod时,这些控制器将作为父对象,并且所创建的Pod将被标记为其子对象。这样,当您要更新或删除父对象时,控制器将自动更新或删除与之相关的Pod。例如,一个Deployment可能会创建多个Pod,并且这些Pod需要与一个Service关联起来。但是,当您删除一个Deployment时,如果没有处理这些关联关系,那么它所创建的Pod和Service就会继续存在,可能会导致一些问题。
要想删除pod需要删除对应的控制器,在kubernetes删除ReplicaSet前,会将ReplicaSet的replicasclear调整为0,等待所有的Pod被删除后,在执行ReplicaSet对象的删除
# 也可以使用yaml直接删除 kubectl delete -f xxx.yaml
kubectl delete rs replica-set
如果希望仅仅删除RS对象(保留Pod),可以使用kubectl delete命令时添加--cascade=false选项(不推荐)
Deployment
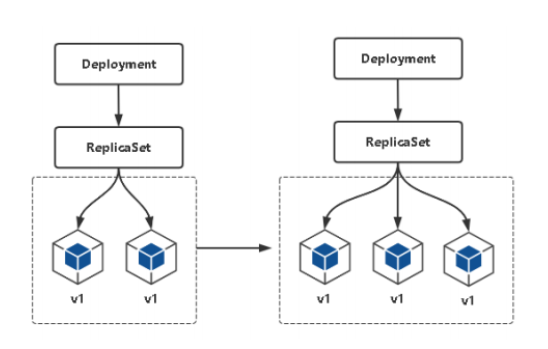
为了更好的管理服务编排,Kubernetes引入了Deployment控制器。值得一提的是,Deployment控制器并不是直接管理pod,而是通过管理ReplicaSet来间接管理Pod,Deployment可以控制ReplicaSet的创建、升级、回滚等操作,从而管理Pod的数量和版本。即Deployment管理ReplicaSet,ReplicaSet管理Pod。相比之下,Deployment比ReplicaSet功能更加强大,能够支持服务发布的停止、继续、滚动更新、回滚和水平扩缩容等功能,使得服务编排更加方便和灵活。
Deployment 控制器的实现流程主要包括以下几个步骤:
获取实际状态: Deployment 控制器从 Etcd 中获取所有携带了指定标签的 Pod,并统计它们的数量
获取期望状态: 通过 Deployment 对象的 Replicas 字段,获取期望的 Pod 数量
对比状态: 对比实际状态和期望状态的数量。如果它们不一致,就需要进行调谐,确定是创建新的 Pod 还是删除现有的 Pod
可以看到,一个 Kubernetes 对象的主要编排逻辑,实际上是在第三步的“对比”阶段完成的。这个操作,通常被叫作调谐(Reconcile)。这个调谐的过程,则被称作“Reconcile Loop”(调谐循环)或者“Sync Loop”(同步循环)。我们社区交流也称为“控制循环”
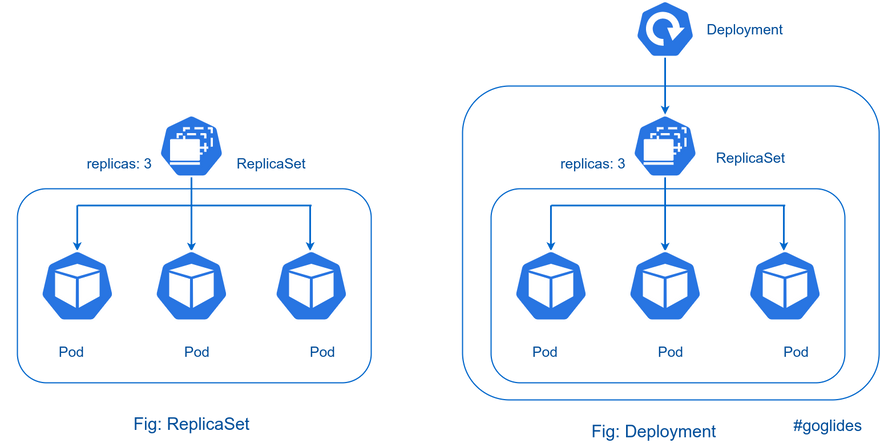
Deployment资源清单
apiVersion: apps/v1 # 版本号
kind: Deployment # 类型
metadata: # 元数据
name: string # deployment控制器名称
namespace: string # 所属命名空间
labels: # 标签列表
key: value # 定义标签的键值对
annotations: # 自定义注解列表
key: value # 定义注解的键值对
spec: # 详情描述
replicas: int # 期望的副本数量,默认为1
revisionHistoryLimit: 3 # 保留历史版本
paused: false # 暂停部署,默认是false
progressDeadlineSeconds: 600 # 部署超时时间(s),默认是600,超过这个时间就会变为失败
strategy: # 更新时替换旧pod的策略
type: RollingUpdate # 滚动更新策略
# RollingUpdate 以滚动更新的方式更新pod,并可以通过设置maxSurge、maxUnavailable来控制滚动更新的过程
# Recreate 所有现有的pod都会在创建新的pod之前被终止
rollingUpdate: # 滚动更新
maxSurge: 30% # 最大额外可以存在的副本数,可以为百分比,也可以为整数
maxUnavailable: 30% # 最大不可用状态的 Pod 的最大值,可以为百分比,也可以为整数
selector: # 选择器,通过它指定该控制器管理哪些pod
matchLabels: # Labels匹配规则
app: nginx-pod
matchExpressions: # Expressions匹配规则
- {key: app, operator: In, values: [nginx-pod]}
template: # 模板,当副本数量不足时,会根据下面的模板创建pod副本
metadata:
labels:
app: nginx-pod #Pod 标签
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
Deployment创建
创建一个deploy控制器示例
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1 # 资源群组
kind: Deployment # 资源类型
metadata: # 元数据
name: deployment-nginx # deploy名称
namespace: dev # Pod所在的名称空间
spec:
replicas: 2 # Pod的副本数
selector: # 标签选择器
matchLabels:
app: nginx-deployment #
template: # 定义Pod的模板
metadata: #
labels: #
app: nginx-deployment
spec:
containers:
- name: nginx # 容器名称
image: nginx:1.16.1 # 容器镜像
imagePullPolicy: IfNotPresent # 容器拉取策略
ports: # 定义容器的端口
- name: http
containerPort: 80 # 容器端口为80
EOF
查看创建的deploy
[root@master ~]# kubectl get deployment -n dev
NAME READY UP-TO-DATE AVAILABLE AGE
deployment-nginx 2/2 2 2 6s
# NAME 列出了集群中 Deployment 的名称
# READY 显示应用程序的可用的副本数。显示的模式是 就绪个数/期望个数
# UP-TO-DATE 当前处于最新版本的 Pod 的个数,所谓最新版本指的是 Pod 的 Spec 部分与 Deployment 里 Pod 模板里定义的完全一致
# AVAILABLE 当前可用的pod的数量,既是running状态又是最新版本,并且处于ready状态。AVAILABLE 字段,描述的才是用户所期望的最终状态
# AGE 显示应用程序运行的时间
创建deployment同时也会自动创建出对应的ReplicaSet,ReplicaSet 的名称被格式化为[Deployment名称]-[随机字符串]。 其中的随机字符串是使用 pod-template-hash 随机生成的。Deployment 控制器将 pod-template-hash 标签添加到 Deployment 所创建或收留的每个 ReplicaSet。此标签可确保 Deployment 的子 ReplicaSets 不重叠,从而避免这些pod与其它pod混淆。
[root@master ~]# kubectl get rs -n dev
NAME DESIRED CURRENT READY AGE
deployment-nginx-dcbd8844d 2 2 2 25s
# NAME 列出名字空间中 ReplicaSet 的名称;
# DESIRED 显示应用的期望副本个数,即在创建 Deployment 时所定义的值。 此为期望状态;
# CURRENT 显示当前运行状态中的副本个数;
# READY 显示应用中有多少副本可以为用户提供服务;
# AGE 显示应用已经运行的时间长度。
注意下面示例输出中的 pod label 里的 pod-template-hash label。当 Deployment 创建或者接管 ReplicaSet 时,Deployment controller 会自动为 Pod 添加 pod-template-hash label。这样做的目的是防止 Deployment 的子 ReplicaSet 的 pod 名字重复。通过将 ReplicaSet 的 PodTemplate 进行哈希散列,使用生成的哈希值作为 label 的值,并添加到 ReplicaSet selector 里、 pod template label 和 ReplicaSet 管理中的 Pod 上。
[root@master ~]# kubectl get pods -n dev --show-labels -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
deployment-nginx-dcbd8844d-67vkh 1/1 Running 0 38s 10.244.1.79 node1 <none> <none> app=nginx-deployment,pod-template-hash=dcbd8844d
deployment-nginx-dcbd8844d-cp8mn 1/1 Running 0 38s 10.244.2.95 node2 <none> <none> app=nginx-deployment,pod-template-hash=dcbd8844d
发现该pod被rs控制,deployment会去创建一个rs,rs去创建对应的pod
[root@master ~]# kubectl describe pod deployment-nginx-dcbd8844d-67vkh -n dev | grep "Controlled By"
Controlled By: ReplicaSet/deployment-nginx-dcbd8844d
[root@master ~]# kubectl get pod deployment-nginx-dcbd8844d-67vkh -n dev -oyaml
………
name: deployment-nginx-dcbd8844d-67vkh #pod名
namespace: dev
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: deployment-nginx-dcbd8844d #rs名
uid: d4909347-afd6-463d-b5ce-978052c58ed5
………
[root@master ~]# kubectl get rs deployment-nginx-dcbd8844d -n dev -o yaml #查看rs
………
name: deployment-nginx-dcbd8844d #rs名
namespace: dev
ownerReferences: - apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: Deployment
name: deployment-nginx #dm名
uid: 30903400-3dc6-4605-9171-46b46cdae26a
………
水平扩缩容
水平扩缩容非常容易实现,deployment只需要修改它所控制的ReplicaSet的pod副本个数就可以了
通过scale命令进行扩缩容,给名叫deployment-nginx的deployment pod副本数量为5个
kubectl scale deployment deployment-nginx --replicas=5 -n dev
查看deployment
[root@master ~]# kubectl get deploy deployment-nginx -n dev
NAME READY UP-TO-DATE AVAILABLE AGE
deployment-nginx 5/5 5 5 4m47s
查看pod
[root@master ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
deployment-nginx-dcbd8844d-67vkh 1/1 Running 0 5m2s
deployment-nginx-dcbd8844d-cp8mn 1/1 Running 0 5m2s
deployment-nginx-dcbd8844d-h7xvv 1/1 Running 0 83s
deployment-nginx-dcbd8844d-p86mk 1/1 Running 0 83s
deployment-nginx-dcbd8844d-thkdp 1/1 Running 0 83s
通过edit命令进行扩缩容,编辑deployment的副本数量,修改spec:replicas: 3即可
kubectl edit deploy deployment-nginx -n dev
查看pod
[root@master ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
deployment-nginx-dcbd8844d-67vkh 1/1 Running 0 7m7s
deployment-nginx-dcbd8844d-cp8mn 1/1 Running 0 7m7s
deployment-nginx-dcbd8844d-h7xvv 1/1 Running 0 3m28s
kubectl edit 命令只是把 API 对象的内容下载到了本地文件,修改完成后再提交上去。Kubernetes 就会立刻触发滚动更新的过程。你还可以通过 kubectl rollout status 指令查看 deployment-nginx 的状态变化,也可以通过查看 Deployment 的 Events,看到这个滚动更新的流程
[root@master ~]# kubectl rollout status deploy deployment-nginx -n dev
deployment "deployment-nginx" successfully rolled out
[root@master ~]# kubectl describe deploy deployment-nginx -n dev
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 8m20s deployment-controller Scaled up replica set deployment-nginx-dcbd8844d to 2
Normal ScalingReplicaSet 4m41s deployment-controller Scaled up replica set deployment-nginx-dcbd8844d to 5
Normal ScalingReplicaSet 88s deployment-controller Scaled down replica set deployment-nginx-dcbd8844d to 3
滚动更新
仅当 Deployment Pod 模板(即 .spec.template)发生改变时,例如模板的标签或容器镜像被更新,才会触发Deployment 上线。 其他更新(如对 Deployment 执行扩缩容的操作)不会触发上线动作,当你修改 Deployment 的副本数量(spec.replicas)时,只是调整 Pod 的数量,而不涉及 Pod 模板的变更。这不会触发新的 Pod 模板创建,也不会引发滚动更新。例如,你把 replicas 从 3 调整到 5,Kubernetes 只会再创建两个 Pod 来满足新的副本数量要求,而不会重新创建已有的 Pod。
先来更新 nginx Pod 以使用 nginx:1.17.1 镜像
kubectl set image deployment deployment-nginx nginx=nginx:1.17.1 -n dev --record
或者 edit Deployment 并将 .spec.template.spec.containers[0].image 更改至 nginx:1.17.1。edit 指令会直接打开deployment-nginx的 API 对象。然后,你就可以修改这里的 Pod 模板部分了。
kubectl edit deployment deployment-nginx -n dev
kubectl set 指令编辑完成后,Kubernetes 就会立刻触发 滚动更新 的过程。通过 kubectl rollout status 指令查看 deployment-nginx 的状态变化:
kubectl rollout status deployment deployment-nginx -n dev
可以通过查看 Deployment 的 Events,看到这个 滚动更新 的流程
[root@master ~]# kubectl describe deployment deployment-nginx -n dev
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 10m deployment-controller Scaled up replica set deployment-nginx-dcbd8844d to 2
Normal ScalingReplicaSet 7m9s deployment-controller Scaled up replica set deployment-nginx-dcbd8844d to 5
Normal ScalingReplicaSet 3m56s deployment-controller Scaled down replica set deployment-nginx-dcbd8844d to 3
Normal ScalingReplicaSet 19s deployment-controller Scaled up replica set deployment-nginx-9588fc68c to 1
Normal ScalingReplicaSet 18s deployment-controller Scaled down replica set deployment-nginx-dcbd8844d to 2
Normal ScalingReplicaSet 18s deployment-controller Scaled up replica set deployment-nginx-9588fc68c to 2
Normal ScalingReplicaSet 17s deployment-controller Scaled down replica set deployment-nginx-dcbd8844d to 1
Normal ScalingReplicaSet 17s deployment-controller Scaled up replica set deployment-nginx-9588fc68c to 3
Normal ScalingReplicaSet 16s deployment-controller Scaled down replica set deployment-nginx-dcbd8844d to 0
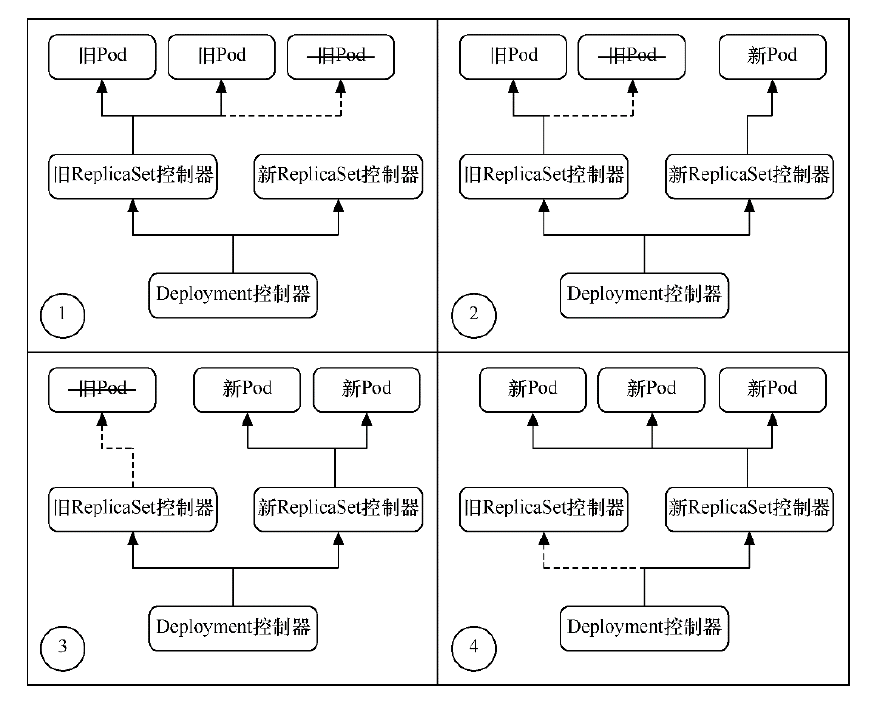
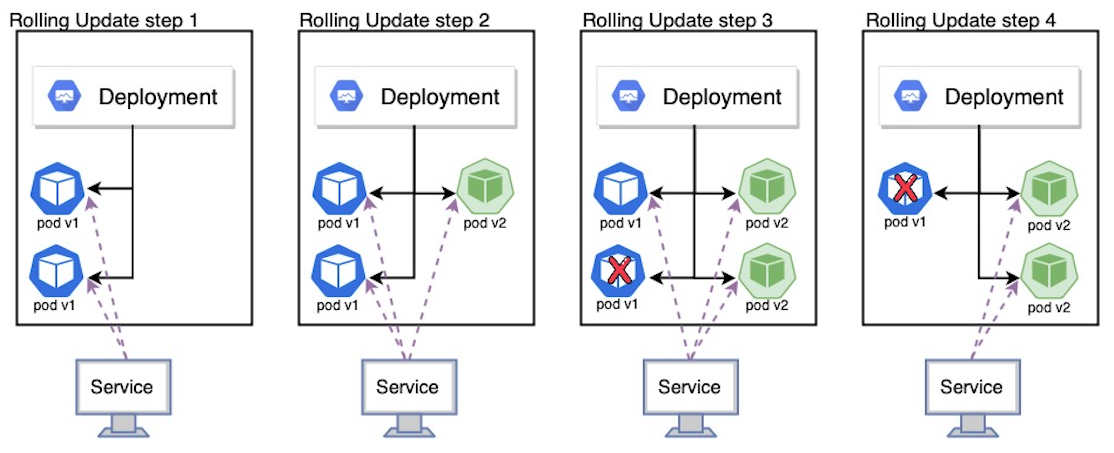
可以看到,首先,当你修改了 Deployment 里的 Pod 定义之后,Deployment Controller 会使用这个修改后的 Pod 模板,创建一个新的 ReplicaSet(hash=9588fc68c),这个新的 ReplicaSet 的初始 Pod 副本数是:0。然后在 Age=19 s 的位置,Deployment Controller 开始将这个新的 ReplicaSet 所控制的 Pod 副本数从 0 个变成 1 个,即水平扩展出一个副本。紧接着,在 Age=18 s 的位置,Deployment Controller 又将旧的 ReplicaSet(hash=dcbd8844d)所控制的旧 Pod 副本数减少一个,即水平收缩成一个副本。
如此交替进行,新 ReplicaSet 管理的 Pod 副本数,从 0 个变成 1 个,再变成 2 个,最后变成 3 个。而旧的 ReplicaSet 管理的 Pod 副本数则从 3 个变成 2 个,再变成 1 个,最后变成 0 个。这样,就完成了这一组 Pod 的版本升级过程。像这样,将一个集群中正在运行的多个 Pod 版本,交替地逐一升级的过程,就是 滚动更新 。
在这个 滚动更新 过程完成之后,你可以查看一下新、旧两个 ReplicaSet 的最终状态。当第一次创建 Deployment 时,它创建了一个 ReplicaSet(deployment-nginx-dcbd8844d) 并将其直接扩容至 3 个副本。更新 Deployment 时,它创建了一个新的 ReplicaSet (deployment-nginx-9588fc68c),并将其扩容为 1,然后将旧 ReplicaSet(deployment-nginx-dcbd8844d) 缩容到 2, 以便至少有 2 个 Pod 可用且最多创建 4 个 Pod。 然后,它使用相同的滚动更新策略继续对新的 ReplicaSet 扩容并对旧的 ReplicaSet 缩容。 最后,你将有 3 个可用的副本在新的 ReplicaSet 中,旧 ReplicaSet(hash=dcbd8844d)已经被 水平收缩 成了 0 个副本。
[root@master ~]# kubectl get rs -n dev
NAME DESIRED CURRENT READY AGE
deployment-nginx-9588fc68c 3 3 3 4m30s
deployment-nginx-dcbd8844d 0 0 0 14m
滚动更新不会中断整个pod集群提供的服务,是一种比较平滑的升级方式。比如,在升级刚开始的时候,集群里只有 1 个新版本的 Pod。如果这时,新版本 Pod 有问题启动不起来,那么 滚动更新 就会停止,从而允许开发和运维人员介入。而在这个过程中,由于应用本身还有两个旧版本的 Pod 在线,所以服务并不会受到太大的影响。当然,这也就要求你一定要使用 Pod 的 Health Check 机制检查应用的运行状态,而不是简单地依赖于容器的 Running 状态。要不然的话,虽然容器已经变成 Running 了,但服务很有可能尚未启动,滚动更新的效果也就达不到了。
Deployment 可确保在更新时仅关闭一定数量的 Pod。默认情况下,它确保至少所需 Pods 75% 处于运行状态(最大不可用比例为 25%); Pod 个数比期望个数最多多出 25%(最大峰值 25%)。所以,在上面这个 Deployment 的例子中,它有 3 个 Pod 副本,那么控制器在 滚动更新 的过程中永远都会确保至少有 2 个 Pod 处于可用状态,至多只有 4 个 Pod 同时存在于集群中。这个策略是 Deployment 对象的一个字段,名叫 RollingUpdateStrategy,如下所示:
[root@master ~]# kubectl describe deployment deployment-nginx -n dev |grep RollingUpdateStrategy
RollingUpdateStrategy: 25% max unavailable, 25% max surge
[root@master ~]# kubectl get deployment deployment-nginx -n dev -o yaml
………
strategy: # 更新策略
rollingUpdate:
maxSurge: 25% #能够额外创建的pod数或相对于总副本数的百分比
maxUnavailable: 25% #更新过程中能够进入不可用状态pod的最大值或相对于总副本数的最大百分比
type: RollingUpdate # 滚动更新策略,不写默认为该策略
maxSurge 指定的是除了 DESIRED 数量之外,在一次滚动中,Deployment 控制器还可以创建多少个新 Pod;而 maxUnavailable 指的是,在一次滚动中,Deployment 控制器可以删除多少个旧 Pod。
下面我们将更新策略改成如下内容,同时修改镜像版本为nginx:1.8
[root@master ~]# vim nginx-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-nginx
namespace: dev
spec:
replicas: 3
selector:
matchLabels:
app: nginx-deployment
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 0
maxUnavailable: 1
template:
metadata:
labels:
app: nginx-deployment
spec:
containers:
- name: nginx
image: nginx:1.8
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
创建pod,-–record 参数的作用,是记录下你每次操作所执行的命令,以方便后面查看
kubectl apply -f nginx-deploy.yaml --record
在滚动更新中,因为设置了maxUnavailable=1,表示最多只允许一个pod不可用,所以会先终止一个pod,而另外两个pod处于Runing状态。由于设置了maxSurge=0,表示最多创建0个额外的pod副本,更新过程中有一个正在创建的pod以及两个正在运行的pod(正好三个),因此符合3个副本和0个额外副本的设置
观察升级过程,中间过程是滚动进行的,也就是边销毁边创建
[root@master ~]# kubectl get pods -n dev -w
NAME READY STATUS RESTARTS AGE
deployment-nginx-9588fc68c-5jn5v 1/1 Running 0 49m
deployment-nginx-9588fc68c-mmrcd 1/1 Running 0 49m
deployment-nginx-9588fc68c-s6dls 1/1 Running 0 49m
deployment-nginx-9588fc68c-5jn5v 1/1 Terminating 0 49m
deployment-nginx-86b659b6c4-znhh6 0/1 Pending 0 0s
deployment-nginx-86b659b6c4-znhh6 0/1 Pending 0 0s
deployment-nginx-86b659b6c4-znhh6 0/1 ContainerCreating 0 0s
deployment-nginx-9588fc68c-5jn5v 0/1 Terminating 0 49m
deployment-nginx-9588fc68c-5jn5v 0/1 Terminating 0 49m
deployment-nginx-9588fc68c-5jn5v 0/1 Terminating 0 49m
deployment-nginx-86b659b6c4-znhh6 1/1 Running 0 20s
deployment-nginx-9588fc68c-s6dls 1/1 Terminating 0 49m
deployment-nginx-86b659b6c4-cc4x4 0/1 Pending 0 0s
deployment-nginx-86b659b6c4-cc4x4 0/1 Pending 0 0s
deployment-nginx-86b659b6c4-cc4x4 0/1 ContainerCreating 0 0s
deployment-nginx-9588fc68c-s6dls 0/1 Terminating 0 49m
deployment-nginx-9588fc68c-s6dls 0/1 Terminating 0 49m
deployment-nginx-9588fc68c-s6dls 0/1 Terminating 0 49m
deployment-nginx-86b659b6c4-cc4x4 1/1 Running 0 32s
deployment-nginx-9588fc68c-mmrcd 1/1 Terminating 0 50m
deployment-nginx-86b659b6c4-qgrng 0/1 Pending 0 0s
deployment-nginx-86b659b6c4-qgrng 0/1 Pending 0 0s
deployment-nginx-86b659b6c4-qgrng 0/1 ContainerCreating 0 1s
deployment-nginx-9588fc68c-mmrcd 0/1 Terminating 0 50m
deployment-nginx-9588fc68c-mmrcd 0/1 Terminating 0 50m
deployment-nginx-9588fc68c-mmrcd 0/1 Terminating 0 50m
deployment-nginx-86b659b6c4-qgrng 1/1 Running 0 2s
[root@master ~]# kubectl describe deploy -n dev deployment-nginx
Events:
Type Reason Age From Message
Normal ScalingReplicaSet 61m deployment-controller Scaled up replica set deployment-nginx-dcbd8844d to 2
Normal ScalingReplicaSet 57m deployment-controller Scaled up replica set deployment-nginx-dcbd8844d to 5
Normal ScalingReplicaSet 54m deployment-controller Scaled down replica set deployment-nginx-dcbd8844d to 3
Normal ScalingReplicaSet 50m deployment-controller Scaled up replica set deployment-nginx-9588fc68c to 1
Normal ScalingReplicaSet 50m deployment-controller Scaled down replica set deployment-nginx-dcbd8844d to 2
Normal ScalingReplicaSet 50m deployment-controller Scaled up replica set deployment-nginx-9588fc68c to 2
Normal ScalingReplicaSet 50m deployment-controller Scaled down replica set deployment-nginx-dcbd8844d to 1
Normal ScalingReplicaSet 50m deployment-controller Scaled up replica set deployment-nginx-9588fc68c to 3
Normal ScalingReplicaSet 50m deployment-controller Scaled down replica set deployment-nginx-dcbd8844d to 0
Normal ScalingReplicaSet 102s deployment-controller Scaled down replica set deployment-nginx-9588fc68c to 2
Normal ScalingReplicaSet 102s deployment-controller Scaled up replica set deployment-nginx-86b659b6c4 to 1
Normal ScalingReplicaSet 82s deployment-controller Scaled down replica set deployment-nginx-9588fc68c to 1
Normal ScalingReplicaSet 82s deployment-controller Scaled up replica set deployment-nginx-86b659b6c4 to 2
Normal ScalingReplicaSet 50s deployment-controller Scaled down replica set deployment-nginx-9588fc68c to 0
Normal ScalingReplicaSet 50s deployment-controller Scaled up replica set deployment-nginx-86b659b6c4 to 3
发现镜像已更新,之前的rs还在,只不过replicas变为了0
[root@master ~]# kubectl get rs -n dev -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
deployment-nginx-86b659b6c4 3 3 3 4m2s nginx nginx:1.8 app=nginx-deployment,pod-template-hash=86b659b6c4
deployment-nginx-9588fc68c 0 0 0 53m nginx nginx:1.17.1 app=nginx-deployment,pod-template-hash=9588fc68c
deployment-nginx-dcbd8844d 0 0 0 63m nginx nginx:1.16.1 app=nginx-deployment,pod-template-hash=dcbd8844d
[root@master ~]# kubectl get rs deployment-nginx-dcbd8844d -n dev -o yaml
spec:
replicas: 0
回滚
kubectl rollout: 版本升级相关功能,支持下面的选项:
kubectl rollout status 显示当前升级状态
kubectl rollout history 显示升级历史记录
kubectl rollout pause 暂停版本升级过程
kubectl rollout resume 继续已经暂停的版本升级过程
kubectl rollout restart 重启版本升级过程
kubectl rollout undo 回滚到上一级版本,可以使用 --to-revision回滚到指定版本
默认情况下 Deployment 的所有上线记录都保留在系统中,以便可以随时回滚 。假设你在更新 Deployment 时犯了一个拼写错误,将镜像名称命名设置为 nginx:1.161 而不是 nginx:1.61.1
kubectl set image deploy deployment-nginx nginx=nginx:1.161 -n dev --record
此上线进程会出现停滞,你可以通过检查上线状态来验证
[root@master ~]# kubectl rollout status deploy deployment-nginx -n dev
Waiting for deployment "deployment-nginx" rollout to finish: 1 out of 3 new replicas have been updated...
查看所创建的 Pod,你会注意到新 ReplicaSet 所创建的 1 个 Pod 卡顿在镜像拉取循环中
[root@master ~]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
deployment-nginx-8545c8f6d8-gzbcq 0/1 ImagePullBackOff 0 80s
deployment-nginx-86b659b6c4-cc4x4 1/1 Running 0 25m
deployment-nginx-86b659b6c4-znhh6 1/1 Running 0 26m
查看ReplicaSet发现新版本的 ReplicaSet(hash=8545c8f6d8)的水平扩展已经停止。而且此时它已经创建了一个 Pod,但是它们都没有进入 READY 状态。这当然是因为这个 Pod 都拉取不到有效的镜像。(nginx:1.161这个镜像在docker hub中并不存在,因此滚动更新被触发后会立即停止)。与此同时旧版本的 ReplicaSet(hash=86b659b6c4)的水平收缩,也自动停止了。此时已经有一个旧 Pod 被删除,还剩下两个旧 Pod
[root@master ~]# kubectl get rs -n dev
NAME DESIRED CURRENT READY AGE
deployment-nginx-8545c8f6d8 1 1 0 44s
deployment-nginx-86b659b6c4 2 2 2 25m
deployment-nginx-9588fc68c 0 0 0 74m
deployment-nginx-dcbd8844d 0 0 0 85m
Deployment 控制器自动停止有问题的上线过程,并停止对新的 ReplicaSet 扩容。 这行为取决于所指定的 rollingUpdate 参数(具体为 maxUnavailable)。 默认情况下,Kubernetes 将此值设置为 25%
[root@master ~]# kubectl describe deployment deployment-nginx -n dev
RollingUpdateStrategy: 1 max unavailable, 0 max surge
我们只需要执行一条 kubectl rollout undo 命令,就能把整个 Deployment 回滚到上一个版本,让这个旧 ReplicaSet(hash=86b659b6c4)再次扩展成 3 个 Pod,而让新的 ReplicaSet(hash=8545c8f6d8)重新收缩到 0 个 Pod
[root@master ~]# kubectl rollout undo deployment deployment-nginx -n dev
deployment.apps/deployment-nginx rolled back
[root@master ~]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
deployment-nginx-86b659b6c4-4gfn4 1/1 Running 0 24s
deployment-nginx-86b659b6c4-cc4x4 1/1 Running 0 30m
deployment-nginx-86b659b6c4-znhh6 1/1 Running 0 30m
[root@master ~]# kubectl get rs -n dev
NAME DESIRED CURRENT READY AGE
deployment-nginx-8545c8f6d8 0 0 0 6m32s
deployment-nginx-86b659b6c4 3 3 3 31m
deployment-nginx-9588fc68c 0 0 0 80m
deployment-nginx-dcbd8844d 0 0 0 91m
如果我想回滚到更早之前的版本,可以通过 kubectl rollout history 命令,查看每次 Deployment 变更对应的版本。由于我们在创建这个 Deployment 的时候,指定了--record 参数,所以我们创建这些版本时执行的 kubectl 命令,都会被记录下来。如果执行命令时没有指定--record参数,那么 CHANGE-CAUSE 字段记录值为<none>
[root@master ~]# kubectl rollout history deploy deployment-nginx -n dev
deployment.apps/deployment-nginx
REVISION CHANGE-CAUSE
1 <none>
2 kubectl set image deployment deployment-nginx nginx=nginx:1.17.1 --namespace=dev --record=true
4 kubectl set image deploy deployment-nginx nginx=nginx:1.161 --namespace=dev --record=true
5 kubectl apply --filename=nginx-deploy.yaml --record=true
你还可以通过这个 kubectl rollout history 指令,看到每个版本对应的 Deployment 的 API 对象的细节
kubectl rollout history deploy deployment-nginx -n dev --revision=2
然后,我们就可以在 kubectl rollout undo 命令行最后,加上要回滚到的指定版本的版本号,就可以回滚到指定版本了。直接使用--to-revision=2回滚到了2版本, 如果省略这个选项,就是回退到上个版本。
kubectl rollout undo deploy deployment-nginx -n dev --to-revision=2
这样Deployment Controller 还会按照滚动更新的方式,完成对 Deployment 的降级操作
[root@master ~]# kubectl get rs -n dev -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
deployment-nginx-8545c8f6d8 0 0 0 18m nginx nginx:1.161 app=nginx-deployment,pod-template-hash=8545c8f6d8
deployment-nginx-86b659b6c4 0 0 0 43m nginx nginx:1.8 app=nginx-deployment,pod-template-hash=86b659b6c4
deployment-nginx-9588fc68c 3 3 3 92m nginx nginx:1.17.1 app=nginx-deployment,pod-template-hash=9588fc68c
deployment-nginx-dcbd8844d 0 0 0 103m nginx nginx:1.16.1 app=nginx-deployment,pod-template-hash=dcbd8844d
回滚后,历史版本会新+1
kubectl rollout history deploy deployment-nginx -n dev
其实deployment之所以可是实现版本的回滚,就是通过记录历史RS来实现的,一旦想回滚到哪个版本,只需要将当前版本pod数量降为0,然后将回滚版本的pod提升为目标数量就可以了。保留历史记录的本质是保留每次修改创建的RS控制器,而回滚的本质是切换到对应版本的RS控制器。deployment对象spec.revisionHistoryLimit字段就是k8s为deployment保留的历史版本个数,如果设置为0,那么就再也不能进行回滚操作了
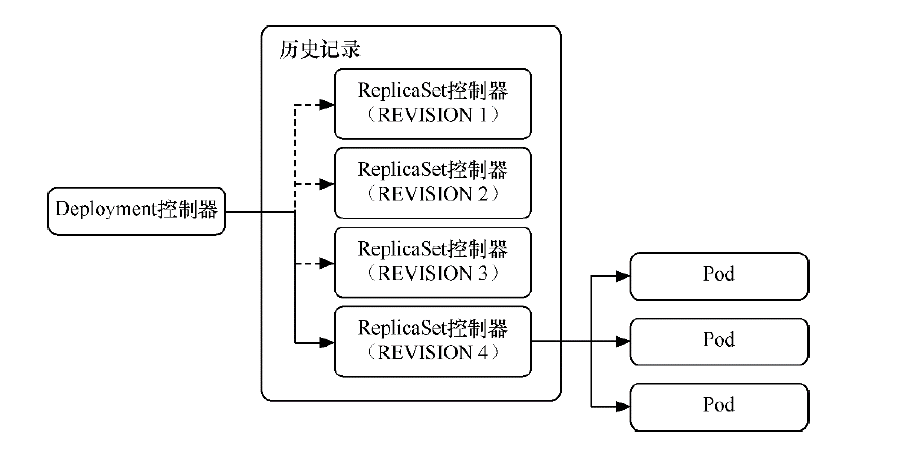
通过控制RS,比如创建新RS,旧RS就会把里面的pod副本数一个个转移到新RS,达到滚动更新,滚动更新以后旧RS并没有被删除,而是被停用,如果想要用旧RS,达到回滚
更新的暂停与恢复
无论是直接更新还是滚动更新,都会一直更新到结束。但为了避免更新有问题,可以尝试只更新一个pod,待这个pod验证无误后,再更新其它pod。Deployment控制器支持控制更新过程中的控制,如暂停(pause)或继续(resume)更新操作
kubectl rollout pause deployment <deployment name> #暂停
kubectl rollout resume deployment <deployment name> #恢复
比如有一批新的Pod资源创建完成后立即暂停更新过程,此时,仅存在一部分新版本的应用,主体部分还是旧的版本。然后,再筛选一小部分的用户请求路由到新版本的Pod应用,继续观察能否稳定地按期望的方式运行。确定没问题之后再继续完成余下的Pod资源滚动更新,否则立即回滚更新操作。这就是所谓的金丝雀发布
例如,对于一个刚刚创建的 Deployment,获取 Deployment 信息:
[root@master ~]# kubectl get deploy -n dev -owide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
deployment-nginx 3/3 3 3 8s nginx nginx:1.8 app=nginx-deployment
[root@master ~]# kubectl get rs -n dev -owide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
deployment-nginx-86b659b6c4 3 3 3 14s nginx nginx:1.8 app=nginx-deployment,pod-template-hash=86b659b6c4
更新deployment的版本,并配置暂停deployment,升级完第一个pod后会立即暂停后续操作
kubectl set image deploy deployment-nginx nginx=nginx:1.17.4 -n dev && kubectl rollout pause deployment deployment-nginx -n dev
查看pod状态
[root@master ~]# kubectl get deploy -n dev -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
deployment-nginx 3/3 1 3 36s nginx nginx:1.17.4 app=nginx-deployment
[root@master ~]# kubectl get rs -n dev -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
deployment-nginx-749c54bf88 1 1 1 15s nginx nginx:1.17.4 app=nginx-deployment,pod-template-hash=749c54bf88
deployment-nginx-86b659b6c4 2 2 2 44s nginx nginx:1.8 app=nginx-deployment,pod-template-hash=86b659b6c4
验证新版本Pod是否有问题
[root@master ~]# kubectl get pod -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-nginx-749c54bf88-dv6wd 1/1 Running 0 39s 10.244.1.132 node1 <none> <none>
deployment-nginx-86b659b6c4-rwwjv 1/1 Running 0 68s 10.244.2.169 node2 <none> <none>
deployment-nginx-86b659b6c4-sqnlt 1/1 Running 0 68s 10.244.1.131 node1 <none> <none>
[root@master ~]# curl -I 10.244.1.132
HTTP/1.1 200 OK
Server: nginx/1.17.4
验证没有问题后,就可以结束暂停了,让剩余的Pod继续更新为最新版
kubectl rollout resume deploy deployment-nginx -n dev
观察更新状态
[root@master ~]# kubectl rollout status deploy deployment-nginx -n dev
Waiting for deployment "deployment-nginx" rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for deployment "deployment-nginx" rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for deployment "deployment-nginx" rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for deployment "deployment-nginx" rollout to finish: 2 of 3 updated replicas are available...
deployment "deployment-nginx" successfully rolled out
监控更新的过程,可以看到已经新增了一个资源,但是并未按照预期的状态去删除一个旧的资源,就是因为使用了pause暂停命令
[root@master ~]# kubectl get deploy -n dev -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
deployment-nginx 3/3 3 3 4m6s nginx nginx:1.17.4 app=nginx-deployment
[root@master ~]# kubectl get rs -n dev -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
deployment-nginx-749c54bf88 3 3 3 4m7s nginx nginx:1.17.4 app=nginx-deployment,pod-template-hash=749c54bf88
deployment-nginx-86b659b6c4 0 0 0 4m36s nginx nginx:1.8 app=nginx-deployment,pod-template-hash=86b659b6c4
[root@master ~]# kubectl get pod -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-nginx-749c54bf88-dv6wd 1/1 Running 0 4m23s 10.244.1.132 node1 <none> <none>
deployment-nginx-749c54bf88-n2b82 1/1 Running 0 84s 10.244.2.170 node2 <none> <none>
deployment-nginx-749c54bf88-thd8s 1/1 Running 0 82s 10.244.1.133 node1 <none> <none>
Deployment删除
删除deployment,其下的RS和pod也将被删除
kubectl delete -f nginx-deploy.yaml # 基于模板文件删除资源
kubectl delete deploy deployment-nginx -n dev # 删除deployment
查看是否被删除
[root@master ~]# kubectl get deploy -n dev
No resources found in dev namespace.
[root@master ~]# kubectl get rs -n dev
No resources found in dev namespace.
[root@master ~]# kubectl get pod -n dev
No resources found in dev namespace.
如果某台服务器宕机或关机,那么在该节点上的pod将变成了ternminating状态,表示已经终止。另外还有新的pod在创建,所以控制器保证集群中的pod数量与配置中期望的pod数量保持一致
部署策略
在Kubernetes中有几种不同的方式发布应用,所以为了让应用在升级期间依然平稳提供服务,选择一个正确的发布策略就非常重要了。选择正确的部署策略是要依赖于我们的业务需求的,下面我们列出了一些可能会使用到的策略:
重建(recreate):停止旧版本部署新版本
滚动更新(rolling-update):一个接一个地以滚动更新方式发布新版本
蓝绿(blue/green):新版本与旧版本一起存在,然后切换流量
金丝雀(canary):将新版本面向一部分用户发布,然后继续全量发布
A/B测(a/b testing):以精确的方式(HTTP 头、cookie、权重等)向部分用户发布新版本。A/B测实际上是一种基于数据统计做出业务决策的技术。在 Kubernetes 中并不原生支持,需要额外的一些高级组件来完成改设置(比如Istio、Linkerd、Traefik、或者自定义 Nginx/Haproxy 等)。
你可以在Kubernetes集群上来对上面的这些策略进行测试,下面的仓库中有需要使用到的资源清单:https://github.com/ContainerSolutions/k8s-deployment-strategies
接下来我们来介绍下每种策略,看看在什么场景下面适合哪种策略。
重建(Recreate)
策略定义为Recreate的Deployment,直接删除当前控制器下的所有pod,之后新建更新后的RS控制器及pod
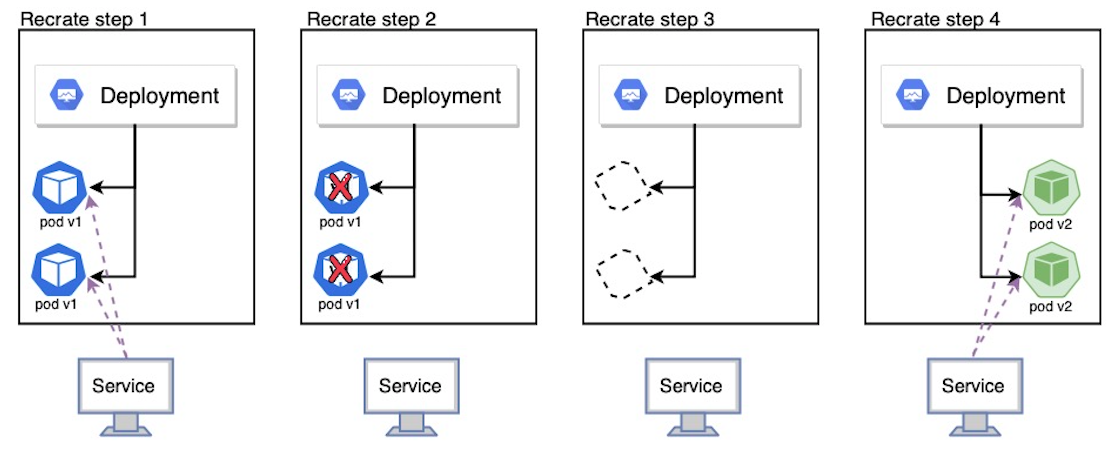
下图是重新创建过程应用接收流量的示意图:
重新创建策略是一个虚拟部署,包括关闭版本A,然后在关闭版本A后部署版本B。此技术意味着服务的停机时间取决于应用程序的关闭和启动持续时间。我们这里创建两个相关的资源清单文件
app-v1.yaml文件内容如下:
apiVersion: v1
kind: Service
metadata:
name: my-app
labels:
app: my-app
spec:
type: NodePort
ports:
- name: http
port: 80
targetPort: http
selector:
app: my-app
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
labels:
app: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
strategy:
type: Recreate
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
version: v1.0.0
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9101"
spec:
containers:
- name: my-app
image: containersol/k8s-deployment-strategies
ports:
- name: http
containerPort: 8080
- name: probe
containerPort: 8086
env:
- name: VERSION
value: v1.0.0
livenessProbe:
httpGet:
path: /live
port: probe
initialDelaySeconds: 5
periodSeconds: 5
readinessProbe:
httpGet:
path: /ready
port: probe
periodSeconds: 5
app-v2.yaml 文件内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
labels:
app: my-app
spec:
replicas: 3
strategy:
type: Recreate
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
version: v2.0.0
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9101"
spec:
containers:
- name: my-app
image: containersol/k8s-deployment-strategies
ports:
- name: http
containerPort: 8080
- name: probe
containerPort: 8086
env:
- name: VERSION
value: v2.0.0
livenessProbe:
httpGet:
path: /live
port: probe
initialDelaySeconds: 5
periodSeconds: 5
readinessProbe:
httpGet:
path: /ready
port: probe
periodSeconds: 5
上面两个资源清单文件中的 Deployment 定义几乎是一直的,唯一不同的是定义的环境变量VERSION值不同,接下来按照下面的步骤来验证Recreate策略:
- 版本1提供服务
- 删除版本1
- 部署版本2
- 等待所有副本准备就绪
首先部署第一个应用
kubectl apply -f app-v1.yaml
测试版本1是否部署成功
[root@master ~]# kubectl get pods -l app=my-app
NAME READY STATUS RESTARTS AGE
my-app-6964668d64-6nv6j 1/1 Running 0 21s
my-app-6964668d64-d5vjs 1/1 Running 0 21s
my-app-6964668d64-xdr45 1/1 Running 0 21s
[root@master ~]# kubectl get svc my-app
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-app NodePort 10.96.83.121 <none> 80:31924/TCP 40s
[root@master ~]# curl 10.96.83.121:80
Host: my-app-6964668d64-d5vjs, Version: v1.0.0
可以看到版本1的应用正常运行了,为了查看部署的运行情况,打开一个新终端并运行以下命令
kubectl get pod -l app=my-app -w
然后部署版本2的应用
kubectl apply -f app-v2.yaml
然后测试第二个版本应用的部署进度:
[root@master ~]# while sleep 0.1; do curl http://127.0.0.1:31924; done
curl: (7) Failed connect to 127.0.0.1:31924; Connection refused
curl: (7) Failed connect to 127.0.0.1:31924; Connection refused
......
Host: my-app-5c967c586b-bzqjp, Version: v2.0.0
Host: my-app-5c967c586b-nhscj, Version: v2.0.0
Host: my-app-5c967c586b-f5zb8, Version: v2.0.0
......
这个时候可以观察上面新开的终端中的 Pod 列表的变化,可以看到之前的3个 Pod 都会先处于Terminating状态,并且3个 Pod 都被删除后才开始创建新的 Pod
[root@master ~]# kubectl get pod -l app=my-app -w
NAME READY STATUS RESTARTS AGE
my-app-6964668d64-6nv6j 1/1 Running 0 115s
my-app-6964668d64-d5vjs 1/1 Running 0 115s
my-app-6964668d64-xdr45 1/1 Running 0 115s
my-app-6964668d64-6nv6j 1/1 Terminating 0 2m7s
my-app-6964668d64-d5vjs 1/1 Terminating 0 2m7s
my-app-6964668d64-xdr45 1/1 Terminating 0 2m7s
my-app-6964668d64-6nv6j 0/1 Terminating 0 2m7s
my-app-6964668d64-d5vjs 0/1 Terminating 0 2m7s
my-app-6964668d64-xdr45 0/1 Terminating 0 2m7s
my-app-6964668d64-6nv6j 0/1 Terminating 0 2m7s
my-app-6964668d64-d5vjs 0/1 Terminating 0 2m7s
my-app-6964668d64-6nv6j 0/1 Terminating 0 2m8s
my-app-6964668d64-d5vjs 0/1 Terminating 0 2m8s
my-app-6964668d64-xdr45 0/1 Terminating 0 2m8s
my-app-6964668d64-xdr45 0/1 Terminating 0 2m8s
my-app-5c967c586b-nhscj 0/1 Pending 0 0s
my-app-5c967c586b-nhscj 0/1 Pending 0 0s
my-app-5c967c586b-f5zb8 0/1 Pending 0 0s
my-app-5c967c586b-bzqjp 0/1 Pending 0 0s
my-app-5c967c586b-nhscj 0/1 ContainerCreating 0 0s
my-app-5c967c586b-f5zb8 0/1 Pending 0 0s
my-app-5c967c586b-bzqjp 0/1 Pending 0 0s
my-app-5c967c586b-bzqjp 0/1 ContainerCreating 0 0s
my-app-5c967c586b-f5zb8 0/1 ContainerCreating 0 0s
my-app-5c967c586b-f5zb8 0/1 Running 0 16s
my-app-5c967c586b-f5zb8 1/1 Running 0 17s
my-app-5c967c586b-bzqjp 0/1 Running 0 17s
my-app-5c967c586b-bzqjp 1/1 Running 0 17s
my-app-5c967c586b-nhscj 0/1 Running 0 33s
my-app-5c967c586b-nhscj 1/1 Running 0 33s
发现镜像已更新,之前的rs已经停用
[root@master ~]# kubectl get rs -l app=my-app -owide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
my-app-5c967c586b 3 3 3 10m my-app containersol/k8s-deployment-strategies app=my-app,pod-template-hash=5c967c586b
my-app-6964668d64 0 0 0 12m my-app containersol/k8s-deployment-strategies app=my-app,pod-template-hash=6964668d64
Recreate更新方式直接删除当前控制器下的所有pod,只保留旧的rs控制器的定义,之后新建更新后的rs控制器及pod
最后,可以执行下面的命令来清空上面的资源对象
kubectl delete all -l app=my-app
滚动更新(rolling-update)
滚动更新通过逐个替换实例来逐步部署新版本的应用,直到所有实例都被替换完成为止。它通常遵循以下过程:在负载均衡器后面使用版本 A 的实例池,然后部署版本 B 的一个实例,当服务准备好接收流量时(Readiness Probe 正常),将该实例添加到实例池中,然后从实例池中删除一个版本 A 的实例并关闭,如下图所示:
下图是滚动更新过程应用接收流量的示意图:
下面是 Kubernetes 中通过 Deployment 来进行滚动更新的关键参数
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 2 # 一次可以添加多少个Pod
maxUnavailable: 1 # 滚动更新期间最大多少个Pod不可用
现在仍然使用上面的 app-v1.yaml 这个资源清单文件,新建一个定义滚动更新的资源清单文件 app-v2-rolling-update.yaml,文件内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
labels:
app: my-app
spec:
replicas: 10
# maxUnavailable设置为0可以完全确保在滚动更新期间服务不受影响,还可以使用百分比的值来进行设置。
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
version: v2.0.0
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9101"
spec:
containers:
- name: my-app
image: containersol/k8s-deployment-strategies
ports:
- name: http
containerPort: 8080
- name: probe
containerPort: 8086
env:
- name: VERSION
value: v2.0.0
livenessProbe:
httpGet:
path: /live
port: probe
initialDelaySeconds: 5
periodSeconds: 5
readinessProbe:
httpGet:
path: /ready
port: probe
# 初始延迟设置高点可以更好地观察滚动更新过程
initialDelaySeconds: 15
periodSeconds: 5
上面的资源清单中我们在环境变量中定义了版本2,然后通过设置strategy.type=RollingUpdate来定义该 Deployment 使用滚动更新的策略来更新应用,接下来我们按下面的步骤来验证滚动更新策略:
- 版本1提供服务
- 部署版本2
- 等待直到所有副本都被版本2替换完成
首先部署版本1应用
kubectl apply -f app-v1.yaml
测试版本1是否部署成功
[root@master ~]# kubectl get pods -l app=my-app
NAME READY STATUS RESTARTS AGE
my-app-7b4874cd75-h8c4d 1/1 Running 0 47s
my-app-7b4874cd75-p4l8f 1/1 Running 0 47s
my-app-7b4874cd75-qnt7p 1/1 Running 0 47s
[root@master ~]# kubectl get svc my-app
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-app NodePort 10.109.99.184 <none> 80:30486/TCP 1m
[root@master ~]# curl http://127.0.0.1:30486
Host: my-app-7b4874cd75-qnt7p, Version: v1.0.0
可以看到版本1的应用正常运行了,为了查看部署的运行情况,打开一个新终端并运行以下命令
kubectl get pod -l app=my-app -w
然后部署滚动更新版本2应用
kubectl apply -f app-v2-rolling-update.yaml
这个时候在上面的 watch 终端中可以看到多了很多 Pod,还在创建当中,并没有一开始就删除之前的 Pod,同样,这个时候执行下面命令,测试应用状态:
[root@master ~]# while sleep 0.1; do curl http://127.0.0.1:30486; done
Host: my-app-7b4874cd75-vrlj7, Version: v1.0.0
......
Host: my-app-7b4874cd75-vrlj7, Version: v1.0.0
Host: my-app-6b5479d97f-2fk24, Version: v2.0.0
Host: my-app-7b4874cd75-p4l8f, Version: v1.0.0
......
Host: my-app-6b5479d97f-s5ctz, Version: v2.0.0
Host: my-app-7b4874cd75-5ldqx, Version: v1.0.0
......
Host: my-app-6b5479d97f-5z6ww, Version: v2.0.0
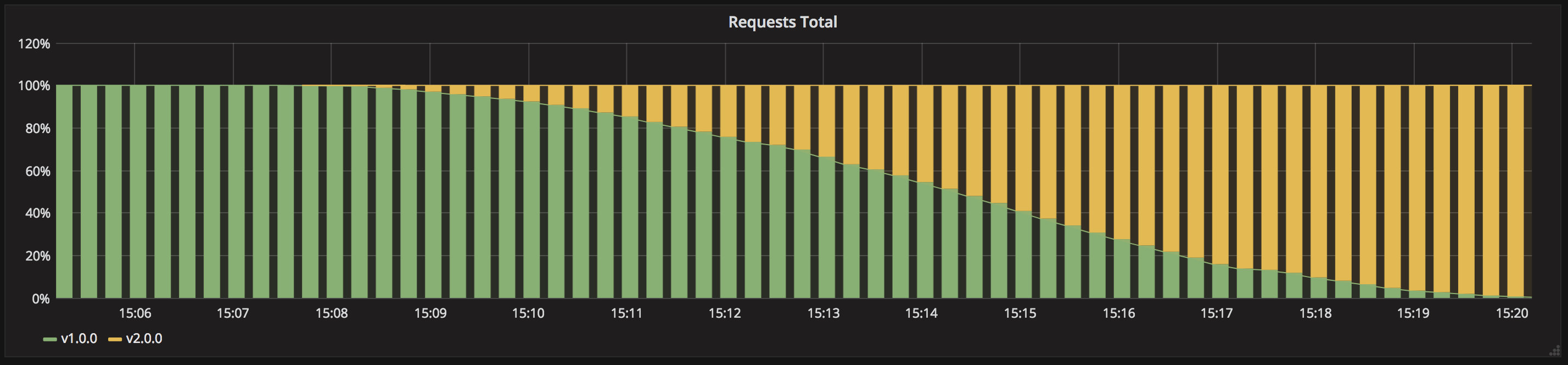
们可以看到上面的应用并没有出现不可用的情况,最开始访问到的都是版本1的应用,然后偶尔会出现版本2的应用,直到最后全都变成了版本2的应用,而这个时候看上面 watch 终端中 Pod 已经全部变成10个版本2的应用了,我们可以看到这就是一个逐步替换的过程。
如果在滚动更新过程中发现新版本应用有问题,我们可以通过下面的命令来进行一键回滚:
kubectl rollout undo deploy my-app
如果你想保持两个版本的应用都存在,那么我们也可以执行 pause 命令来暂停更新:
kubectl rollout pause deploy my-app
这个时候我们再去循环访问我们的应用,就可以看到偶尔会出现版本1的应用信息了。如果新版本应用程序没问题了,也可以继续恢复更新:
kubectl rollout resume deploy my-app
最后,可以执行下面的命令来清空上面的资源对象:
kubectl delete all -l app=my-app
蓝/绿(blue/green)
蓝/绿发布是 版本2 与 版本1 一起发布,然后流量切换到版本2,也称为红/黑部署。蓝/绿发布与滚动更新不同,版本2(绿) 与版本1(蓝)一起部署,在测试新版本满足要求后,然后更新更新 Kubernetes 中扮演负载均衡器角色的 Service 对象,通过替换 label selector 中的版本标签来将流量发送到新版本,如下图所示:
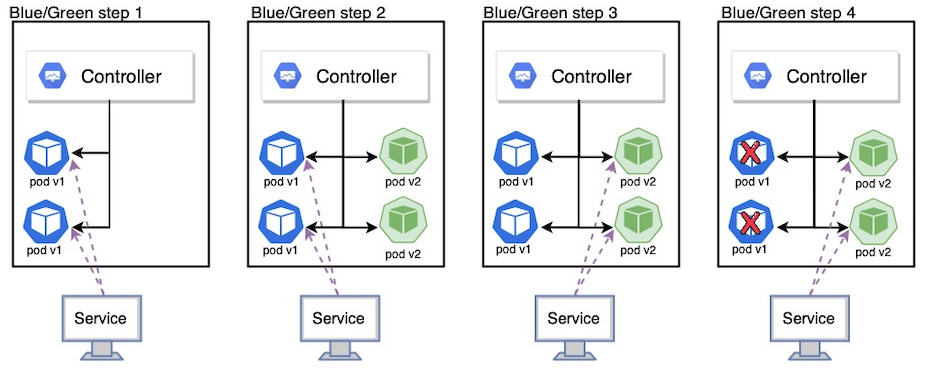
下面是蓝绿发布策略下应用方法的示例图:
在 Kubernetes 中,我们可以用两种方法来实现蓝绿发布,通过单个 Service 对象或者 Ingress 控制器来实现蓝绿发布,实现蓝绿发布的关键点就在于 Service 对象中 label selector 标签的匹配方法,比如我们重新定义版本1 的资源清单文件 app-v1-single-svc.yaml,文件内容如下:
apiVersion: v1
kind: Service
metadata:
name: my-app
labels:
app: my-app
spec:
type: NodePort
ports:
- name: http
port: 80
targetPort: http
# 注意这里我们匹配 app 和 version 标签,当要切换流量的时候,我们更新 version 标签的值,比如:v2.0.0
selector:
app: my-app
version: v1.0.0
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app-v1
labels:
app: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
version: v1.0.0
template:
metadata:
labels:
app: my-app
version: v1.0.0
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9101"
spec:
containers:
- name: my-app
image: containersol/k8s-deployment-strategies
ports:
- name: http
containerPort: 8080
- name: probe
containerPort: 8086
env:
- name: VERSION
value: v1.0.0
livenessProbe:
httpGet:
path: /live
port: probe
initialDelaySeconds: 5
periodSeconds: 5
readinessProbe:
httpGet:
path: /ready
port: probe
periodSeconds: 5
上面定义的资源对象中,最重要的就是 Service 中 label selector 的定义:
selector:
app: my-app
version: v1.0.0
版本2 的应用定义和以前一样,新建文件 app-v2-single-svc.yaml,文件内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app-v2
labels:
app: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
version: v2.0.0
template:
metadata:
labels:
app: my-app
version: v2.0.0
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9101"
spec:
containers:
- name: my-app
image: containersol/k8s-deployment-strategies
ports:
- name: http
containerPort: 8080
- name: probe
containerPort: 8086
env:
- name: VERSION
value: v2.0.0
livenessProbe:
httpGet:
path: /live
port: probe
initialDelaySeconds: 5
periodSeconds: 5
readinessProbe:
httpGet:
path: /ready
port: probe
periodSeconds: 5
然后按照下面的步骤来验证使用单个 Service 对象实现蓝/绿部署的策略:
1、版本1 应用提供服务
2、部署版本2 应用
3、等到版本2 应用全部部署完成,切换入口流量从版本1 到版本2,关闭版本1 应用
首先,部署版本1 应用
kubectl apply -f app-v1-single-svc.yaml
测试版本1 应用是否部署成功
[root@master ~]# kubectl get pods -l app=my-app
NAME READY STATUS RESTARTS AGE
my-app-v1-6964668d64-lwbqm 1/1 Running 0 55s
my-app-v1-6964668d64-n7fpd 1/1 Running 0 55s
my-app-v1-6964668d64-rlf7n 1/1 Running 0 55s
[root@master ~]# kubectl get svc -l app=my-app
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-app NodePort 10.96.134.46 <none> 80:32211/TCP 67s
[root@master ~]# curl http://127.0.0.1:32211
Host: my-app-v1-6964668d64-n7fpd, Version: v1.0.0
同样,新开一个终端,执行如下命令观察 Pod 变化
kubectl get pod -l app=my-app -w
然后部署版本2 应用
kubectl apply -f app-v2-single-svc.yaml
然后在上面 watch 终端中可以看到会多3个my-app-v2开头的 Pod,待这些 Pod 部署成功后,我们再去访问当前的应用
[root@master ~]# while sleep 0.1; do curl http://127.0.0.1:32211; done
Host: my-app-v1-6964668d64-lwbqm, Version: v1.0.0
Host: my-app-v1-6964668d64-n7fpd, Version: v1.0.0
Host: my-app-v1-6964668d64-rlf7n, Version: v1.0.0
......
我们会发现访问到的都是版本1 的应用,和我们刚刚部署的版本2 没有任何关系,这是因为我们 Service 对象中通过 label selector 匹配的是version=v1.0.0这个标签,我们可以通过修改 Service 对象的匹配标签,将流量路由到标签version=v2.0.0的 Pod 去
kubectl patch service my-app -p '{"spec":{"selector":{"version":"v2.0.0"}}}'
然后再去访问应用,可以发现现在都是版本2 的信息了
[root@master ~]# while sleep 0.1; do curl http://127.0.0.1:32211; done
Host: my-app-v2-5c967c586b-mshb9, Version: v2.0.0
Host: my-app-v2-5c967c586b-h4pt7, Version: v2.0.0
Host: my-app-v2-5c967c586b-k68l5, Version: v2.0.0
......
如果你需要回滚到版本1,同样只需要更改 Service 的匹配标签即可
$ kubectl patch service my-app -p '{"spec":{"selector":{"version":"v1.0.0"}}}'
如果新版本已经完全符合我们的需求了,就可以删除版本1 的应用了
kubectl delete deploy my-app-v1
最后,同样执行如下命令清理上述资源对象
kubectl delete all -l app=my-app
金丝雀
金丝雀部署是让部分用户访问到新版本应用,在 Kubernetes 中,可以使用两个具有相同 Pod 标签的 Deployment 来实现金丝雀部署。新版本的副本和旧版本的一起发布。在一段时间后如果没有检测到错误,则可以扩展新版本的副本数量并删除旧版本的应用。
如果需要按照具体的百分比来进行金丝雀发布,需要尽可能的启动多的 Pod 副本,这样计算流量百分比的时候才方便,比如,如果你想将 1% 的流量发送到版本 B,那么我们就需要有一个运行版本 B 的 Pod 和 99 个运行版本 A 的 Pod,当然如果你对具体的控制策略不在意的话也就无所谓了,如果你需要更精确的控制策略,建议使用服务网格(如 Istio),它们可以更好地控制流量。
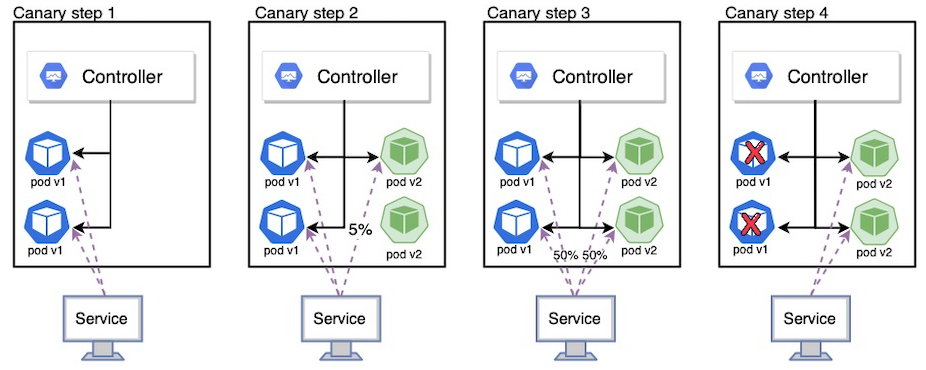
在下面的例子中,我们使用 Kubernetes 原生特性来实现一个穷人版的金丝雀发布,如果你想要对流量进行更加细粒度的控制,请使用豪华版本的 Istio。下面是金丝雀发布的应用请求示意图:
接下来我们按照下面的步骤来验证金丝雀策略:
- 10个副本的版本1 应用提供服务
- 版本2 应用部署1个副本(意味着小于10%的流量)
- 等待足够的时间来确认版本2 应用足够稳定没有任何错误信息
- 将版本2 应用扩容到10个副本
- 等待所有实例完成
- 关闭版本1 应用
首先,创建版本1 的应用资源清单 app-v1-canary.yaml,内容如下:
apiVersion: v1
kind: Service
metadata:
name: my-app
labels:
app: my-app
spec:
type: NodePort
ports:
- name: http
port: 80
targetPort: http
selector:
app: my-app
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app-v1
labels:
app: my-app
spec:
replicas: 10
selector:
matchLabels:
app: my-app
version: v1.0.0
template:
metadata:
labels:
app: my-app
version: v1.0.0
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9101"
spec:
containers:
- name: my-app
image: containersol/k8s-deployment-strategies
ports:
- name: http
containerPort: 8080
- name: probe
containerPort: 8086
env:
- name: VERSION
value: v1.0.0
livenessProbe:
httpGet:
path: /live
port: probe
initialDelaySeconds: 5
periodSeconds: 5
readinessProbe:
httpGet:
path: /ready
port: probe
periodSeconds: 5
其中核心的部分也是 Service 对象中的 label selector 标签,不在具有版本相关的标签了,然后定义版本2 的资源清单文件app-v2-canary.yaml,文件内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app-v2
labels:
app: my-app
spec:
replicas: 1
selector:
matchLabels:
app: my-app
version: v2.0.0
template:
metadata:
labels:
app: my-app
version: v2.0.0
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9101"
spec:
containers:
- name: my-app
image: containersol/k8s-deployment-strategies
ports:
- name: http
containerPort: 8080
- name: probe
containerPort: 8086
env:
- name: VERSION
value: v2.0.0
livenessProbe:
httpGet:
path: /live
port: probe
initialDelaySeconds: 5
periodSeconds: 5
readinessProbe:
httpGet:
path: /ready
port: probe
periodSeconds: 5
版本1 和版本2 的 Pod 都具有一个共同的标签app=my-app,所以对应的 Service 会匹配两个版本的 Pod。
首先,部署版本1 应用
kubectl apply -f app-v1-canary.yaml
然后测试版本1 应用是否正确部署了
[root@master ~]# kubectl get svc -l app=my-app
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-app NodePort 10.96.15.100 <none> 80:31950/TCP 13s
[root@master ~]# curl http://127.0.0.1:31950
Host: my-app-v1-6964668d64-8l9jz, Version: v1.0.0
同样,新开一个终端,查看 Pod 的变化:
kubectl get pod -l app=my-app -w
然后部署版本2 应用
kubectl apply -f app-v2-canary.yaml
然后在 watch 终端页面可以看到多了一个 Pod,现在一共 11 个 Pod,其中只有1 个 Pod 运行新版本应用
[root@master ~]# kubectl get pod -l app=my-app
NAME READY STATUS RESTARTS AGE
my-app-v1-6964668d64-24g6g 1/1 Running 0 102s
my-app-v1-6964668d64-6qgrr 1/1 Running 0 101s
my-app-v1-6964668d64-87ldv 1/1 Running 0 101s
my-app-v1-6964668d64-8l9jz 1/1 Running 0 102s
my-app-v1-6964668d64-b4lpw 1/1 Running 0 101s
my-app-v1-6964668d64-cv8hk 1/1 Running 0 101s
my-app-v1-6964668d64-sgfs4 1/1 Running 0 101s
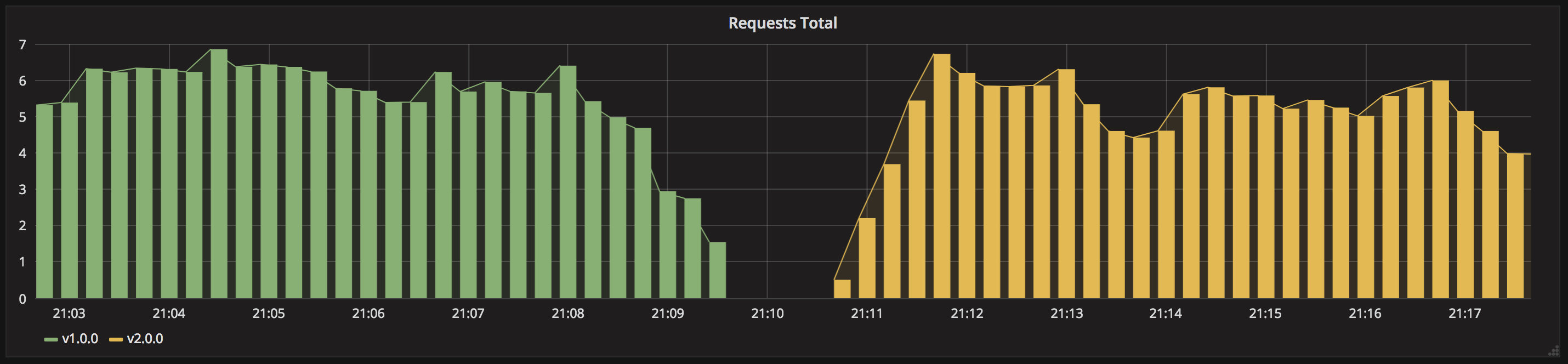
my-app-v1-6964668d64-tnsnm 1/1 Running 0 101s
my-app-v1-6964668d64-vs9l2 1/1 Running 0 102s
my-app-v1-6964668d64-zhm87 1/1 Running 0 101s
my-app-v2-5c967c586b-p28d9 1/1 Running 0 29s
然后同样可以循环访问该应用,查看是否会有版本2 的应用信息:
[root@master ~]# while sleep 0.1; do curl http://127.0.0.1:31950; done
Host: my-app-v1-6964668d64-24g6g, Version: v1.0.0
Host: my-app-v1-6964668d64-tnsnm, Version: v1.0.0
Host: my-app-v1-6964668d64-zhm87, Version: v1.0.0
Host: my-app-v2-5c967c586b-p28d9, Version: v2.0.0
......
正常情况下可以看到大部分都是返回的版本1 的应用信息,偶尔会出现版本2 的应用信息,这就证明我们的金丝雀发布成功了,待确认了版本2 的这个应用没有任何问题后,可以将版本2 应用扩容到10 个副本
kubectl scale --replicas=10 deploy my-app-v2
其实这个时候访问应用的话新版本和旧版本的流量分配是1:1了,确认了版本2 正常后,就可以删除版本1 的应用了
kubectl delete deploy my-app-v1
最终留下的是 10 个新版本的 Pod 了,到这里我们的整个金丝雀发布就完成了。同样,最后执行下面的命令删除上面的资源对象
kubectl delete all -l app=my-app
A/B测试
A/B 测试实际上是一种基于统计信息而非部署策略来制定业务决策的技术,与业务结合非常紧密。但是它们也是相关的,也可以使用金丝雀发布来实现。除了基于权重在版本之间进行流量控制之外,A/B 测试还可以基于一些其他参数(比如 Cookie、User Agent、地区等等)来精确定位给定的用户群,该技术广泛用于测试一些功能特性的效果,然后按照效果来进行确定。
我们经常可以在今日头条的客户端中就会发现有大量的 A/B 测试,同一个地区的用户看到的客户端有很大不同。要使用这些细粒度的控制,仍然还是建议使用 Istio,可以根据权重或 HTTP 头等来动态请求路由控制流量转发。
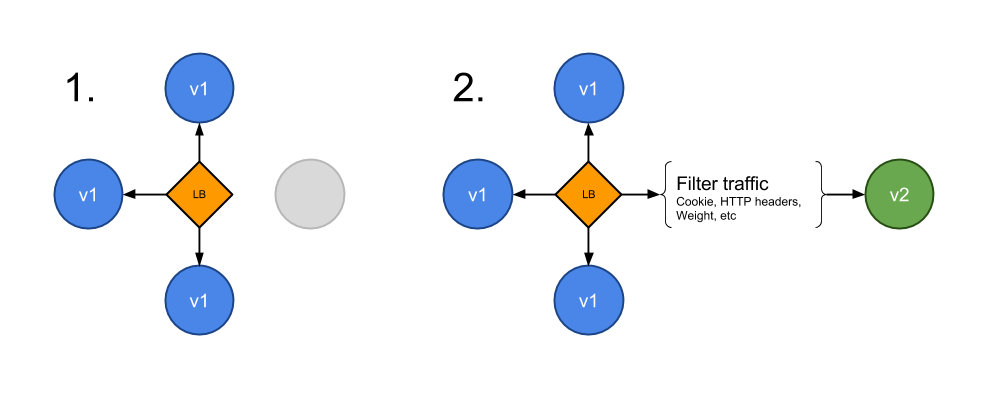
下面是使用 Istio 进行规则设置的示例,因为 Istio 还不太稳定,以下示例规则将来可能会更改:
route:
- tags:
version: v1.0.0
weight: 90
- tags:
version: v2.0.0
weight: 10
关于在 Istio 中具体如何做 A/B 测试,我们这里就不再详细介绍了,我们在istio-book文档中有相关的介绍。
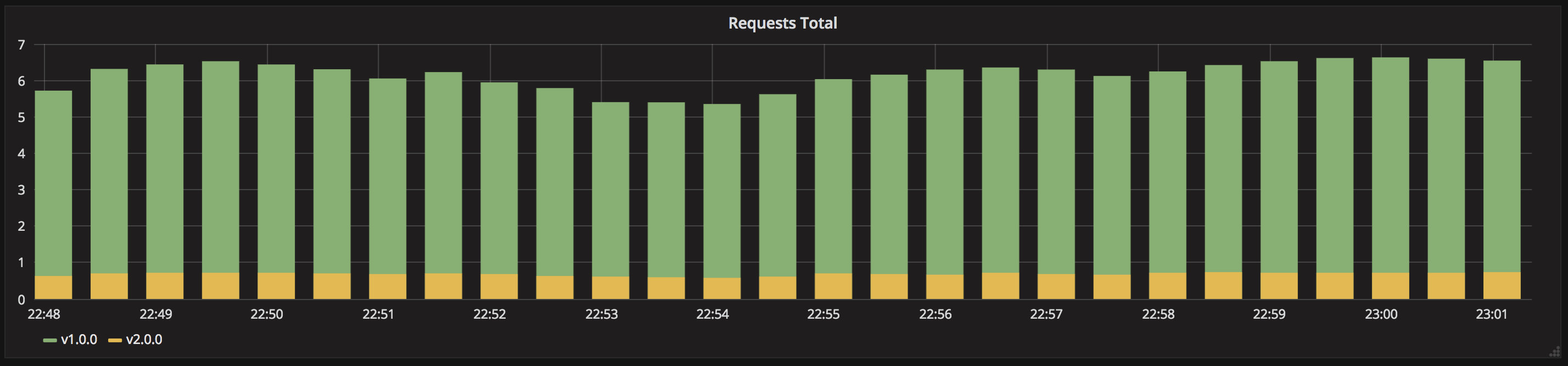
结论:
1、几个版本并行运行
2、完全控制流量分配
3、特定的一个访问错误难以排查,需要分布式跟踪
4、Kubernetes 没有直接的支持,需要其他额外的工具
deployment排查拓扑图
DaemonSet
DaemonSet 的主要作用,就是让你在 Kubernetes 集群里每个节点只运行一个Pod,当有新节点加入到 Kubernetes 集群中,该 Pod 会自动在该节点上被创建出来,当节点从集群移除后,该节点上的这个 Pod 也会被回收。当然如果我们删除 DaemonSet,所有和这个对象相关的 Pod都会被删除。
使用DaemonSet的一些典型用法:
集群存储守护程序,如 glusterd、ceph 要部署在每个节点上以提供持久性存储;
节点监控守护进程,如 Prometheus 监控集群,可以在每个节点上运行一个 node-exporter 进程来收集监控节点的信息;
日志收集守护程序,如 fluentd 或 logstash,在每个节点上运行以收集容器的日志
节点网络插件,比如 flannel、calico,在每个节点上运行为 Pod 提供网络服务。

工作原理
DaemonSet 其实是一个非常简单的控制器。在它的控制循环中,只需要遍历所有节点,然后根据节点上是否有被管理 Pod 的情况,来决定是否要创建或者删除一个 Pod。DaemonSet首先从Etcd里获取所有节点的列表,然后遍历所有节点,检查每个节点是否有一个携带了 key=value 标签的pod在运行,如果没有这种pod,就在该节点创建该pod;如果有这种pod,但是数量大于1,则删除该节点上多余的pod。
正常情况下 Pod 运行在哪个节点上是由 Kubernetes 的调度器策略来决定的,然而由 DaemonSet 控制器创建的 Pod 实际上已经提前确定调度在哪个节点上了。DaemonSet控制器会在Pod创建时,自动在这个pod的API对象里加上nodeAffinity,需要绑定的节点名正是当前正在遍历的这个节点。同时还会自动加上Toleration,容忍标记污点为unschedulable的节点被调度,即使调度器还没有启动。而在正常情况下,被标记了 unschedulable 污点的 Node,是不会有任何 Pod 被调度上去的(effect: NoSchedule)。可是,DaemonSet 自动地给被管理的 Pod 加上了这个特殊的 Toleration,就使得这些 Pod 可以忽略这个限制,继而保证每个节点上都会被调度一个 Pod。当然,如果这个节点有故障的话,这个 Pod 可能会启动失败,而 DaemonSet 则会始终尝试下去,直到 Pod 启动成功。
系统日志收集fluentd-elasticsearch
例如,下面的 daemonset.yaml 文件描述了一个运行 fluentd-elasticsearch Docker 镜像的 DaemonSet,这个 DaemonSet 管理的是一个 fluentd-elasticsearch 镜像的 Pod。这个镜像的功能非常实用:通过 fluentd 将 Docker 容器里的日志转发到 ElasticSearch 中。
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v4
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
EOF
DaemonSet 跟 Deployment 其实非常相似,只不过是没有 replicas 字段。Pod 的模板,也是用 template 字段定义的。在这个字段中,我们定义了一个使用 fluentd:v4 镜像的容器,而且这个容器挂载了两个 hostPath 类型的 Volume,分别对应宿主机的 /var/log 目录和 /var/lib/docker/containers 目录。fluentd 启动之后,它会从这两个目录里搜集日志信息,并转发给 ElasticSearch 保存。这样,我们通过 ElasticSearch 就可以很方便地检索这些日志了。
需要注意的是,Docker 容器里应用的日志,默认会保存在宿主机的 /var/lib/docker/containers/{{. 容器 ID}}/{{. 容器 ID}}-json.log 文件里,所以这个目录正是 fluentd 的搜集目标。
查看DaemonSet发现每个node节点都会有一个pod
[root@master ~]# kubectl get ds -n kube-system -l k8s-app=fluentd-logging
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
fluentd-elasticsearch 3 3 3 3 3 <none> 65s
[root@master ~]# kubectl get pod -n kube-system -l name=fluentd-elasticsearch -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
fluentd-elasticsearch-5tn4g 1/1 Running 0 93s 10.244.104.6 node2 <none> <none>
fluentd-elasticsearch-85vkm 1/1 Running 0 93s 10.244.219.67 master <none> <none>
fluentd-elasticsearch-ksmdz 1/1 Running 0 93s 10.244.166.184 node1 <none> <none>
删除其中一个pod,pod被删除后自动被创建,因为DaemonSet确保一个节点一个pod
[root@master ~]# kubectl delete pod -n kube-system fluentd-elasticsearch-5tn4g
pod "fluentd-elasticsearch-5tn4g" deleted
[root@master ~]# kubectl get pod -n kube-system -l name=fluentd-elasticsearch -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
fluentd-elasticsearch-85vkm 1/1 Running 0 9m29s 10.244.219.67 master <none> <none>
fluentd-elasticsearch-d79bh 1/1 Running 0 108s 10.244.104.2 node2 <none> <none>
fluentd-elasticsearch-ksmdz 1/1 Running 0 9m29s 10.244.166.184 node1 <none> <none>
更新
DaemonSet 和 Deployment 一样,也有 DESIRED、CURRENT 等多个状态字段。这也就意味着,DaemonSet 可以像 Deployment 那样,进行版本管理。DaemonSet也有对应的更新策略,OnDelete和RollingUpdate两种方式:默认是滚动更新,在更新DaemonSet控制器模板后,旧的DaemonSet就会被终止,然后创建新的DaemonSet;OnDelete方式,只有手动删除旧的DaemonSet控制器pod后,才会创建新的DaemonSet控制器pod
[root@master ~]# kubectl get ds -n kube-system fluentd-elasticsearch -oyaml | grep -A4 updateStrategy
updateStrategy:
rollingUpdate:
maxSurge: 0
maxUnavailable: 1
type: RollingUpdate
接下来,我们来把这个 DaemonSet 的容器镜像版本更新到 v4.1
kubectl set image ds fluentd-elasticsearch fluentd-elasticsearch=quay.io/fluentd_elasticsearch/fluentd:v4.1 --record -n kube-system
这时候,我们可以使用 kubectl rollout status 命令看到这个“滚动更新”的过程,如下所示:
[root@master ~]# kubectl rollout status ds/fluentd-elasticsearch -n kube-system
Waiting for daemon set "fluentd-elasticsearch" rollout to finish: 0 out of 3 new pods have been updated...
Waiting for daemon set "fluentd-elasticsearch" rollout to finish: 0 out of 3 new pods have been updated...
Waiting for daemon set "fluentd-elasticsearch" rollout to finish: 1 out of 3 new pods have been updated...
Waiting for daemon set "fluentd-elasticsearch" rollout to finish: 1 out of 3 new pods have been updated...
Waiting for daemon set "fluentd-elasticsearch" rollout to finish: 1 out of 3 new pods have been updated...
Waiting for daemon set "fluentd-elasticsearch" rollout to finish: 2 out of 3 new pods have been updated...
Waiting for daemon set "fluentd-elasticsearch" rollout to finish: 2 out of 3 new pods have been updated...
Waiting for daemon set "fluentd-elasticsearch" rollout to finish: 2 out of 3 new pods have been updated...
Waiting for daemon set "fluentd-elasticsearch" rollout to finish: 2 out of 3 new pods have been updated...
Waiting for daemon set "fluentd-elasticsearch" rollout to finish: 2 of 3 updated pods are available...
daemon set "fluentd-elasticsearch" successfully rolled out
这一次我在升级命令后面加上了--record 参数,所以这次升级使用到的指令就会自动出现在 DaemonSet 的 rollout history 里面,如下所示:
[root@master ~]# kubectl rollout history daemonset fluentd-elasticsearch -n kube-system
daemonset.apps/fluentd-elasticsearch
REVISION CHANGE-CAUSE
1 <none>
2 kubectl set image ds fluentd-elasticsearch fluentd-elasticsearch=quay.io/fluentd_elasticsearch/:v4.1 --record=true --namespace=kube-system
有了版本号,你也就可以像 Deployment 一样,将 DaemonSet 回滚到某个指定的历史版本了。
接下来我们将更新策略改为OnDelete
kubectl patch ds fluentd-elasticsearch -n kube-system --type='json' -p='[{"op": "replace", "path": "/spec/updateStrategy/type", "value":"OnDelete"}]'
接下来,我们来把这个 DaemonSet 的容器镜像版本更新到 v4.2
kubectl set image ds fluentd-elasticsearch fluentd-elasticsearch=quay.io/fluentd_elasticsearch/fluentd:v4.2 --record -n kube-system
镜像更新完后,发现pod的镜像并没有更新
[root@master ~]# kubectl describe pod -n kube-system -l name=fluentd-elasticsearch | grep Image:
Image: quay.io/fluentd_elasticsearch/fluentd:v4.1
Image: quay.io/fluentd_elasticsearch/fluentd:v4.1
Image: quay.io/fluentd_elasticsearch/fluentd:v4.1
此时我们可以删除一个pod,再进行观察,可以看到,只有被删除的 pod 更新到指定的镜像版本
[root@master ~]# kubectl delete pod fluentd-elasticsearch-6rm99 -n kube-system
pod "fluentd-elasticsearch-6rm99" deleted
[root@master ~]# kubectl describe pod -n kube-system -l name=fluentd-elasticsearch | grep Image:
Image: quay.io/fluentd_elasticsearch/fluentd:v4.2
Image: quay.io/fluentd_elasticsearch/fluentd:v4.1
Image: quay.io/fluentd_elasticsearch/fluentd:v4.1
最后我们将所有的pod进行删除,完成所有的更新
kubectl delete pod -l name=fluentd-elasticsearch -n kube-system
查看pod镜像版本,发现已完成了更新
[root@master ~]# kubectl describe pod -n kube-system -l name=fluentd-elasticsearch | grep Image:
Image: quay.io/fluentd_elasticsearch/fluentd:v4.2
Image: quay.io/fluentd_elasticsearch/fluentd:v4.2
Image: quay.io/fluentd_elasticsearch/fluentd:v4.2
回滚
Kubernetes v1.7 之后添加了一个 API 对象,名叫 ControllerRevision,专门用来记录某种 Controller 对象的版本。DaemonSet 使用 ControllerRevision,来保存和管理自己对应的版本。这种 面向 API 对象 的设计思路,大大简化了控制器本身的逻辑,也正是 Kubernetes 项目 声明式 API 的优势所在。比如,你可以通过如下命令查看 fluentd-elasticsearch 对应的 ControllerRevision:
[root@master ~]# kubectl get controllerrevision -n kube-system -l name=fluentd-elasticsearch
NAME CONTROLLER REVISION AGE
fluentd-elasticsearch-547b7d98c5 daemonset.apps/fluentd-elasticsearch 1 37m
fluentd-elasticsearch-5ddccc9db9 daemonset.apps/fluentd-elasticsearch 2 4m56s
而如果你使用 kubectl describe 查看这个 ControllerRevision 对象,就会看到,这个 ControllerRevision 对象,实际上是在 Data 字段保存了该版本对应的完整的 DaemonSet 的 API 对象。并且,在 Annotation 字段保存了创建这个对象所使用的 kubectl 命令
fluentd-elasticsearch-547b7d98c5 fluentd-elasticsearch-5ddccc9db9
[root@master ~]# kubectl describe controllerrevision fluentd-elasticsearch-5ddccc9db9 -n kube-system
......
Annotations: deprecated.daemonset.template.generation: 2
kubernetes.io/change-cause:
kubectl set image ds fluentd-elasticsearch fluentd-elasticsearch=quay.io/fluentd_elasticsearch/:v4.1 --record=true --namespace=kube-system
API Version: apps/v1
Data:
Spec:
Template:
$patch: replace
Metadata:
Creation Timestamp: <nil>
Labels:
Name: fluentd-elasticsearch
......
将这个 DaemonSet 回滚到 REVISION=1 时的状态
[root@master ~]# kubectl rollout undo daemonset fluentd-elasticsearch --to-revision=1 -n kube-system
daemonset.apps/fluentd-elasticsearch rolled back
[root@master ~]# kubectl rollout history daemonset fluentd-elasticsearch -n kube-system
daemonset.apps/fluentd-elasticsearch
REVISION CHANGE-CAUSE
1 <none>
2 kubectl set image ds fluentd-elasticsearch fluentd-elasticsearch=quay.io/fluentd_elasticsearch/:v4.1 --record=true --namespace=kube-system
3 <none>
这个 kubectl rollout undo 操作,实际上相当于读取到了 REVISION=1 的 ControllerRevision 对象保存的 Data 字段。而这个 Data 字段里保存的信息,就是 REVISION=1 时这个 DaemonSet 的完整 API 对象。所以,现在 DaemonSet Controller 就可以使用这个历史 API 对象,对现有的 DaemonSet 做一次 PATCH 操作,等价于执行一次 kubectl apply -f 旧的 DaemonSet 对象 ,从而把这个 DaemonSet 更新到一个旧版本。这也是为什么,在执行完这次回滚完成后,你会发现 DaemonSet 的 REVISION 并不会从 REVISION=2 退回到 1,而是会增加成 Revision=3。这是因为,一个新的 ControllerRevision 被创建了出来。
Job/CronJob
为什么需要Job/CronJob
Kubernetes 的核心对象 Pod,用来编排一个或多个容器,让这些容器共享网络、存储等资源,总是共同调度,从而紧密协同工作。Pod 比容器更能够表示实际的应用,所以 Kubernetes 不会在容器层面来编排业务,而是把 Pod 作为在集群里调度运维的最小单位。
Kubernetes使用的是RESTful API,把集群中的各种业务都抽象为HTTP资源对象,那么在这个层次之上,我们就可以使用面向对象的方式来考虑问题。如果你有一些编程方面的经验,就会知道面向对象编程(OOP),它把一切都视为高内聚的对象,强调对象之间互相通信来完成任务。虽然面向对象的设计思想多用于软件开发,但它放到Kubernetes里却意外地合适。因为Kubernetes使用YAML来描述资源,把业务简化成了一个个的对象,内部有属性,外部有联系,也需要互相协作,只不过我们不需要编程,完全由Kubernetes自动处理,其实Kubernetes的Go语言内部实现就大量应用了面向对象。
面向对象的设计有许多基本原则,其中有两条我认为比较恰当地描述了Kubernetes对象设计思路:单一职责和组合优于继承
单一职责的意思是对象应该只专注于做好一件事情,不要贪大求全,保持足够小的粒度才更方便复用和管理
组合优于继承的意思是应该尽量让对象在运行时产生联系,保持松耦合,而不要用硬编码的方式固定对象的关系
应用这两条原则,我们再来看Kubernetes的资源对象就会很清晰了。因为Pod已经是一个相对完善的对象,专门负责管理容器,那么我们就不应该再画蛇添足地盲目为它扩充功能,而是要保持它的独立性,容器之外的功能就需要定义其他的对象,把Pod作为它的一个成员组合进去。这样每种Kubernetes对象就可以只关注自己的业务领域,只做自己最擅长的事情,其他的工作交给其他对象来处理,既不缺位也不越位,既有分工又有协作,从而以最小成本实现最大收益。
Job 和 CronJob,它们就组合了 Pod,实现了对离线业务的处理:
在线业务:比如Nginx、Node.js、MySQL、Redis等等,一旦运行起来基本上不会停,也就是永远在线。
离线业务:一般不直接服务于外部用户,只对内部用户有意义,比如日志分析、数据建模、视频转码等等,虽然计算量很大,但只会运行一段时间。离线业务的特点是必定会退出,不会无期限地运行下去,所以它的调度策略也就与“在线业务”存在很大的不同,需要考虑运行超时、状态检查、失败重试、获取计算结果等管理事项。而这些业务特性与容器管理没有必然的联系,如果由Pod来实现就会承担不必要的义务,违反了单一职责,所以我们应该把这部分功能分离到另外一个对象上实现,让这个对象去控制Pod的运行,完成附加的工作。
离线业务也可以分为两种。一种是临时任务,跑完就完事了,下次有需求了说一声再重新安排;另一种是定时任务,可以按时按点周期运行,不需要过多干预。对应到Kubernetes里,临时任务就是API对象Job,定时任务就是API对象CronJob,使用这两个对象你就能够在Kubernetes里调度管理任意的离线业务了。
Job
Job对象通常用于运行那些仅需要执行一次的任务,例如数据库迁移,批处理脚本等等。Job的本质是确保一个或多个Pod健康地运行直至运行完毕,如定时脚本意外退出是没办法再次重新执行的,job可以判断这个脚本是不是正常退出,如果不是正常退出job会重新执行该脚本直到正常退出为止。并且还可以设置正常退出的次数。运行一个脚本正常退出,以0为正常退出,job就会记录正常退出次数的个数,退出几次记录几次,比如定义job退出个数4,运行4次正常后,job达到4,job就退出
Job API 对象的定义非常简单,我来举个例子,在给定时间点只运行一次,周期性地在给定时间点运行。如下所示:
cat <<EOF | kubectl apply -f -
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: busybox
command: ["sh", "-c", "echo 'scale=5000; 4*a(1)' | bc -l "]
restartPolicy: Never #重启策略
backoffLimit: 4 #失败时重试次数,默认为6
EOF
我们可以看到这个 Job 创建的 Pod 进入了 Running 状态,这意味着它正在计算 Pi 的值
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pi-mmjnd 1/1 Running 0 40s
跟其他控制器不同的是,Job 对象并不要求你定义一个 spec.selector 来描述要控制哪些 Pod。在成功创建后,我们来查看一下这个 Job 对象
[root@master ~]# kubectl describe jobs pi
......
Pod Template:
Labels: controller-uid=500d112e-df22-43f4-a6e0-49efc462f15b
job-name=pi
......
可以看到,这个 Job 对象在创建后,它的 Pod 模板,被自动加上了一个 controller-uid=< 一个随机字符串 > 这样的 Label。而这个 Job 对象本身,则被自动加上了这个 Label 对应的 Selector,从而保证了 Job 与它所管理的 Pod 之间的匹配关系。而 Job Controller 之所以要使用这种携带了 UID 的 Label,就是为了避免不同 Job 对象所管理的 Pod 发生重合。像这种离线job可能要执行多次,若是pod的标签一样,会出现错误选择的问题
我们可以看到很快 Pod 变成了 Completed 状态,这是因为容器的任务执行完成正常退出了,我们可以查看对应的日志
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pi-mmjnd 0/1 Completed 0 48s
[root@master ~]# kubectl logs pi-8xv5b
3.141592653589793238462643383279...
但是如果执行任务的 Pod 因为某种原因一直没有结束怎么办呢?同样我们可以在 Job 对象中通过设置字段 spec.activeDeadlineSeconds 来限制任务运行的最长时间,比如:
activeDeadlineSeconds: 10
那么当我们的任务 Pod 运行超过了 10s 后,这个 Job 的所有 Pod 都会被终止,并且 Pod 的终止原因会变成 DeadlineExceeded
cat <<EOF | kubectl apply -f -
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
activeDeadlineSeconds: 10
template:
spec:
containers:
- name: pi
image: busybox
command: ["sh", "-c", "echo 'scale=5000; 4*a(1)' | bc -l "]
restartPolicy: Never #重启策略
backoffLimit: 4 #失败时重试次数,默认为6
EOF
查看pod状态为Terminating
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pi-ws9gj 1/1 Terminating 0 16s
如果这个离线作业失败了要怎么办?比如,我们在例子中定义了 restartPolicy=Never,那么离线作业失败后 Job Controller 就会不断地尝试创建一个新 Pod。这也是我们需要在 Pod 模板中定义 restartPolicy=Never 的原因,离线计算的 Pod 永远都不应该被重启,所以想让任务进行就只能创新的Pod。如果你定义的 restartPolicy=OnFailure,那么离线作业失败后,Job Controller 就不会去尝试创建新的 Pod。但是,它会不断地尝试重启 Pod 里的容器。
重启策略为Never
cat <<EOF | kubectl apply -f -
apiVersion: batch/v1
kind: Job
metadata:
name: job-failed-demo
spec:
template:
spec:
containers:
- name: test-job
image: busybox
command: ["echo123", "test failed job!"]
restartPolicy: Never
backoffLimit: 4 #失败时重试次数,默认为6
EOF
查看pod,发现重新创建了4个新的pod
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
job-failed-demo-58mnf 0/1 ContainerCannotRun 0 24s
job-failed-demo-g9r69 0/1 ContainerCannotRun 0 44s
job-failed-demo-mp9tv 0/1 ContainerCannotRun 0 39s
job-failed-demo-smsl2 0/1 ContainerCannotRun 0 34s
job-failed-demo-z9ggl 0/1 ContainerCannotRun 0 29s
可以看到当我们设置成 Never 重启策略的时候,Job 任务执行失败后会不断创建新的 Pod,但是不会一直创建下去,会根据 spec.backoffLimit 参数进行限制,通过该字段可以定义重建 Pod 的次数,这里我们设置的重试次数为4(即backoffLimit=4),而这个字段的默认值是 6。另外需要注意的是 Job 控制器重新创建 Pod 的间隔是呈指数增加的,即下一次重新创建 Pod 的动作会分别发生在 10s、20s、40s… 后。
重启策略为OnFailure
cat <<EOF | kubectl apply -f -
apiVersion: batch/v1
kind: Job
metadata:
name: job-failed-demo
spec:
template:
spec:
containers:
- name: test-job
image: busybox
command: ["echo123", "test failed job!"]
restartPolicy: OnFailure
EOF
重启策略改为 OnFailure,则当 Job 任务执行失败后不会创建新的 Pod 出来,只会不断重启 Pod
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
job-failed-demo-9hsfx 0/1 RunContainerError 1 (21s ago) 33s
并行
在 Job 对象中,负责并行控制的参数有两个:
spec.parallelism:它定义的是一个 Job 在任意时间最多可以启动多少个 Pod 同时运行
spec.completions:它定义的是 Job 至少要完成的 Pod 数目,即 Job 的最小完成数
现在,我在之前计算 Pi 值的 Job 里,添加这两个参数,这样我们就指定了这个 Job 最大的并行数是 2,而最小的完成数是 4
cat <<EOF | kubectl apply -f -
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
parallelism: 2
completions: 4
template:
spec:
containers:
- name: pi
image: busybox
command: ["sh", "-c", "echo 'scale=5000; 4*a(1)' | bc -l "]
restartPolicy: Never
backoffLimit: 4
EOF
查看这个job,COMPLETIONS 定义的最小完成数
[root@master ~]# kubectl get job
NAME COMPLETIONS DURATION AGE
pi 0/4 79s 79s
我们可以看到,这个 Job 首先创建了两个并行运行的 Pod 来计算 Pi
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pi-8f766 1/1 Running 0 19s
pi-lzdbh 1/1 Running 0 19s
而在 59s 后,这两个 Pod 相继完成计算。每当有一个 Pod 完成计算进入 Completed 状态时,就会有一个新的 Pod 被自动创建出来
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pi-8f766 0/1 Completed 0 59s
pi-9rkfc 0/1 ContainerCreating 0 1s
pi-hzwmb 0/1 ContainerCreating 0 3s
pi-lzdbh 0/1 Completed 0 59s
当所有的 Pod 均已经成功退出,这个 Job 也就执行完了,所以你会看到它的 COMPLETIONS 字段的值变成了 4/4
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pi-8f766 0/1 Completed 0 107s
pi-9rkfc 0/1 Completed 0 49s
pi-hzwmb 0/1 Completed 0 51s
pi-lzdbh 0/1 Completed 0 107s
[root@master ~]# kubectl get job
NAME COMPLETIONS DURATION AGE
pi 4/4 104s 110s
Job Controller 控制的对象,直接就是 Pod。Job Controller在控制循环中进行调谐操作,根据实际运行的、已经退出的和设置的允许并行的和最少完成的这两个参数共同计算出在这个周期里应该创建或者删除的 Pod 数目,然后调用 Kubernetes API 来执行这个操作。以上面计算 Pi 值的这个例子为例,当 Job 一开始创建出来时,实际处于 Running 状态的 Pod 数目 = 0,已经成功退出的 Pod 数目 = 0,而用户定义的 completions,也就是最终用户需要的 Pod 数目 = 4。所以在这个时刻,需要创建的 Pod 数目 = 最终需要的 Pod 数目 - 实际在 Running 状态 Pod 数目 - 已经成功退出的 Pod 数目 = 4 - 0 - 0= 4。也就是说,Job Controller 需要创建 4 个 Pod 来纠正这个不一致状态。可是,我们又定义了这个 Job 的 parallelism=2。也就是说,我们规定了每次并发创建的 Pod 个数不能超过 2 个。所以,Job Controller 会对前面的计算结果做一个修正,修正后的期望创建的 Pod 数目应该是:2 个。这时候,Job Controller 就会并发地向 kube-apiserver 发起两个创建 Pod 的请求。类似地,如果在这次调谐周期里,Job Controller 发现实际在 Running 状态的 Pod 数目,比 parallelism 还大,那么它就会删除一些 Pod,使两者相等。
CronJob
CronJob 与 Job 的关系,正如同 Deployment 与 ReplicaSet 的关系一样。CronJob 是一个专门用来管理 Job 对象的控制器。只不过,它创建和删除 Job 的依据,是 schedule 字段定义的、一个标准的Unix Cron格式的表达式。
一个 CronJob 对象其实就对应linux系统中 crontab 文件中的一行,它根据配置的时间格式周期性地运行一个Job,格式和 crontab 也是一样的:分 时 日 月 周 要运行的命令
现在,我们用 CronJob 来管理我们上面的 Job 任务,
cat <<EOF | kubectl apply -f -
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: cronjob-demo
spec:
schedule: "*/1 * * * *"
jobTemplate: #CronJob 是一个 Job 对象的控制器
spec:
template:
spec:
restartPolicy: OnFailure
containers:
- name: busybox
image: busybox
args:
- "bin/sh"
- "-c"
- "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"
EOF
还有一些值得我们关注的字段 spec.successfulJobsHistoryLimit(默认为3) 和 spec.failedJobsHistoryLimit(默认为1),表示历史限制,是可选的字段,指定可以保留多少完成和失败的 Job。然而,当运行一个 CronJob 时,Job 可以很快就堆积很多,所以一般推荐设置这两个字段的值。如果设置限制的值为 0,那么相关类型的 Job 完成后将不会被保留。
查看创建的 Cronjob 资源对象
[root@master ~]# kubectl get cronjob
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
cronjob-demo */1 * * * * False 0 <none> 17s
稍微等一会儿查看可以发现多了几个 Job 资源对象,这个就是因为上面我们设置的 CronJob 资源对象,每1分钟执行一个新的 Job
[root@master ~]# kubectl get job
NAME COMPLETIONS DURATION AGE
cronjob-demo-28651212 1/1 7s 84s
cronjob-demo-28651213 0/1 24s 24s
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
cronjob-demo-28651212-pg529 0/1 Completed 0 91s
cronjob-demo-28651213-469cp 0/1 ContainerCreating 0 31s
由于定时任务的特殊性,很可能某个 Job 还没有执行完,另外一个新 Job 就产生了。这时候,你可以通过 spec.concurrencyPolicy 字段来定义具体的处理策略。比如:
concurrencyPolicy=Allow这也是默认情况,这意味着这些 Job 可以同时存在;
concurrencyPolicy=Forbid这意味着不会创建新的 Pod,该创建周期被跳过;
concurrencyPolicy=Replace这意味着新产生的 Job 会替换旧的、没有执行完的 Job。
而如果某一次 Job 创建失败,这次创建就会被标记为“miss”。当在指定的时间窗口内,miss 的数目达到 100 时,那么 CronJob 会停止再创建这个 Job。这个时间窗口,可以由 spec.startingDeadlineSeconds 字段指定。比如 startingDeadlineSeconds=200,意味着在过去 200 s 里,如果 miss 的数目达到了 100 次,那么这个 Job 就不会被创建执行了。
Job 备份 MySQL 数据库
由于阿里云 RDS MYSQL 数据库没有开放外网连接权限,然后生产环境又没有安装 MYSQL 数据库,缺少 mysqldump 命令,所有决定使用 kubernetes 起一个 job 执行备份操作。k8s 的 Job 负责批量处理短暂的一次性任务 (short lived one-off tasks),即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。这里刚好可以用来备份 MYSQL 数据库
创建 job 文件 mysqldump-job.yaml,内容如下
cat > mysqldump-job.yaml <<EOF
apiVersion: batch/v1
kind: Job
metadata:
name: mysql-backup
spec:
template:
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k8s-prod-master01
tolerations:
- key: "groups"
operator: "Equal"
effect: "NoExecute"
value: "vbaas"
- key: "role"
operator: "Equal"
effect: "NoExecute"
value: "master"
containers:
- name: mysqldump
image: nacos/nacos-mysql-master:latest
imagePullPolicy: "IfNotPresent"
command:
- "/bin/sh"
- "-c"
- "/data/mysql/shell/mysqldump.sh"
volumeMounts:
- mountPath: "/etc/localtime"
name: "localtime"
- mountPath: "/data/mysql/shell"
name: mysql-backup-scripts
- mountPath: "/data/mysql/backup"
name: mysql-backup-data
- mountPath: "/etc/resolv.conf"
name: resolv
volumes:
- name: "mysql-backup-scripts"
hostPath:
path: "/data/mysql/shell"
- name: "mysql-backup-data"
hostPath:
path: "/data/mysql/backup"
- hostPath:
path: "/usr/share/zoneinfo/Asia/Shanghai"
name: "localtime"
- name: resolv
hostPath:
path: /etc/resolv.conf
restartPolicy: Never
backoffLimit: 2
EOF
创建数据备份存放目录以及脚本目录
mkdir -p /data/mysql/{backup,shell}
创建 mysqldump.sh 脚本文件,内容如下
#!/bin/bash
# 保存备份个数
number=3
# 备份保存路径
backup_dir=/data/mysql/backup
# 日期
datetime=</span><span class="token function">date</span> +%Y%m%d<span class="token variable">
# 备份工具
mysqldump=/usr/bin/mysqldump
# 用户名
username=‘root’
# 密码
password=‘xawdadasfadasdqadad’
# 主机地址
host=“vonebaas-prod.mysql.zhangbei.rds.aliyuncs.com”
# 将要备份的数据库
database_name=“nacos
vbaas_c_platform_prod
vbaas_c_custom_core_prod
vbaas_c_open_core_prod
vchain_order_prod
vbaas_s_platform_prod
vbaas_s_platform_node_prod
vbaas_c_platform_explorer_prod
vchain_base_msg_prod
xxl_job_vbaas4_prod
vbaas_c_ops_prod
vbaas_s_platform_explorer_prod
vchain_core_gateway_prod
vchain_core_xxl_prod
vbaas_c_cross_prod
chainmaker_ca_prod
chainmaker_explorer_prod”
# 备份文件名称
backupFileName=“allDatabases-${datetime}.sql”
# 备份所有数据库
#$tool -u
u
s
e
r
n
a
m
e
−
p
username -p
username−ppassword -hmysql-master -P3306 --databases $database_name >
b
a
c
k
u
p
d
i
r
/
backup_dir/
backupdir/database_name-
d
d
.
s
q
l
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
dd.sql</span> <span class="token variable">
dd.sql</span><spanclass="tokenvariable">{mysqldump} -u KaTeX parse error: Undefined control sequence: \< at position 51: …n punctuation">\̲<̲/span> -p<spa…{password} </span>
-hKaTeX parse error: Undefined control sequence: \< at position 47: …n punctuation">\̲<̲/span> <span …{database_name} </span>
–ignore-table=vchain_core_xxl_prod.xxl_job_log </span>
–ignore-table=xxl_job_vbaas4_prod.xxl_job_log >
b
a
c
k
u
p
d
i
r
<
/
s
p
a
n
>
/
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
backup_dir</span>/<span class="token variable">
backupdir</span>/<spanclass="tokenvariable">{backupFileName}
#写创建备份日志
echo “create
b
a
c
k
u
p
d
i
r
<
/
s
p
a
n
>
/
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
backup_dir</span>/<span class="token variable">
backupdir</span>/<spanclass="tokenvariable">{backupFileName}” >> $backup_dir/log.txt
#找出需要删除的备份
delfile=</span><span class="token function">ls</span> <span class="token parameter variable">-l</span> <span class="token parameter variable">-crt</span> $backup_dir/*.sql <span class="token operator">|</span> <span class="token function">awk</span> <span class="token string">'{print $9 }'</span> <span class="token operator">|</span> <span class="token function">head</span> <span class="token parameter variable">-1</span><span class="token variable">
#判断现在的备份数量是否大于$number
count=</span><span class="token function">ls</span> <span class="token parameter variable">-l</span> <span class="token parameter variable">-crt</span> $backup_dir/*.sql <span class="token operator">|</span> <span class="token function">awk</span> <span class="token string">'{print $9 }'</span> <span class="token operator">|</span> <span class="token function">wc</span> <span class="token parameter variable">-l</span><span class="token variable">
if [
c
o
u
n
t
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
a
r
a
m
e
t
e
r
v
a
r
i
a
b
l
e
"
>
−
g
t
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
count</span> <span class="token parameter variable">-gt</span> <span class="token variable">
count</span><spanclass="tokenparametervariable">−gt</span><spanclass="tokenvariable">number ]
then
rm KaTeX parse error: Expected 'EOF', got '#' at position 73: …token comment">#̲写删除文件日志</span> …delfile" >> $backup_dir/log.txt
fi
执行以下命令创建 Job
kubectl apply -f mysqldump-job.yaml
查看备份好的文件
[root@master ~]# ls -lh /data/mysql/backup/
total 95M
-rw-r--r-- 1 root root 95M Feb 2 16:25 allDatabases-20230202.sql
-rw-r--r-- 1 root root 52 Feb 2 16:25 log.txt
查看需要备份的数据库是否都正常备份
[root@master ~]# grep -R "CREATE DATABASE" /data/mysql/backup/allDatabases-20230202.sql
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `nacos` /*!40100 DEFAULT CHARACTER SET utf8 */ /*!80016 DEFAULT ENCRYPTION='N' */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `vbaas_c_platform_prod` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `vbaas_c_custom_core_prod` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `vbaas_c_open_core_prod` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `vchain_order_prod` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `vbaas_s_platform_prod` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `vbaas_s_platform_node_prod` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `vbaas_c_platform_explorer_prod` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `vchain_base_msg_prod` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `xxl_job_vbaas4_prod` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `vbaas_c_ops_prod` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `vbaas_s_platform_explorer_prod` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `vchain_core_gateway_prod` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `vchain_core_xxl_prod` /*!40100 DEFAULT CHARACTER SET utf8 */ /*!80016 DEFAULT ENCRYPTION='N' */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `vbaas_c_cross_prod` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `chainmaker_ca_prod` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `chainmaker_explorer_prod` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */;
CronJob 备份 MySQL
CronJob 资源清单如下
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: mysqldump
spec:
jobTemplate:
spec:
completions: 1
template:
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k8s-prod-master01
tolerations:
- key: "groups"
operator: "Equal"
effect: "NoExecute"
value: "vbaas"
- key: "role"
operator: "Equal"
effect: "NoExecute"
value: "master"
restartPolicy: Never
volumes:
- name: "mysql-backup-scripts"
hostPath:
path: "/data/mysql/shell"
- name: "mysql-backup-data"
hostPath:
path: "/data/mysql/backup"
- name: "localtime"
hostPath:
path: "/etc/localtime"
- name: resolv
hostPath:
path: /etc/resolv.conf
containers:
- name: mysqldump
image: nacos/nacos-mysql-master:latest
volumeMounts:
- mountPath: "/etc/localtime"
name: "localtime"
- mountPath: "/data/mysql/shell"
name: mysql-backup-scripts
- mountPath: "/data/mysql/backup"
name: mysql-backup-data
- mountPath: "/etc/resolv.conf"
name: resolv
command:
- "/bin/sh"
- "-c"
- "/data/mysql/shell/mysqldump.sh"
schedule: "50 01 * * *"
kubernetesMySQLjobDatabases
StatefulSet
Deployments 和 ReplicaSet 是为无状态服务而设计,它们认为,一个应用的所有 Pod 是完全一样的(Deployment不仁,以pod为刍狗)。所以它们互相之间没有顺序,也无所谓运行在哪台宿主机上。需要的时候,Deployment 就可以通过 Pod 模板创建新的 Pod;不需要的时候,Deployment 就可以杀掉任意一个 Pod。但是对于有状态服务就无能为力了,有状态服务需要考虑的细节就要多很多了,不像无状态组件没有预定义的启动顺序、集群要求、点对点 TCP 连接、唯一的网络标识符、正常的启动和终止要求等,因此可以很容易地进行容器化。诸如数据库,大数据分析系统,分布式 key/value 存储、消息中间件需要有复杂的分布式体系结构,都可能会用到上述功能。为此Kubernetes 引入了 StatefulSet 这种资源对象来支持这种复杂的需求。StatefulSet 类似于 ReplicaSet,但是它可以处理 Pod 的启动顺序,为保留每个 Pod 的状态设置唯一标识,具有以下几个功能特性:
稳定的持久化存储:即Pod死亡重新调度后还是能访问到相同的持久化数据,数据不会丢失,基于PVC来实现(共用一个存储卷,pod死亡后,statefulset会维持副本数重新创建pod,仍会使用到上个pod使用到的存储卷)
稳定的网络标志:即Pod重新调度后其PodName和HostName不变,很多服务会以PodName或HostName为连接对象,为防止新的pod名字发生改变,需要从新写入),基于Headless Service(即没有Cluster IP的Service)来实现
有序部署,有序扩展:即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次进行,当前的Pod必须都是Running(运行)和Ready(就绪)状态,下一个pod才能运行
有序收缩,有序删除:即从N-1 到 0,比如先起mysql,再起nginx。停先停nginx,在停mysql
无状态服务(Stateless Service):该服务运行的实例不会在本地存储需要持久化的数据,并且多个实例对于同一个请求响应的结果是完全一致的。
有状态服务(Stateful Service):该服务运行的实例需要在本地存储持久化数据,比如 MySQL 数据库。
比如我们常见的 WEB 应用,是通过 Session 来保持用户的登录状态的。如果我们将 Session 持久化到节点上,那么该应用就是一个有状态的服务了。比如我现在登录进来我的 Session 被持久化到了节点 A ,下次我登录的时候可能会将请求路由到节点 B ,但是节点 B 上根本就没有我当前的 Session 数据,就会被认为是未登录状态,这样就导致我前后两次请求得到的结果不一致了。所以一般为了横向扩展,我们都会把这类 WEB 应用改成无状态的服务。将 Session 数据存入一个公共的地方,比如 Redis 里面,对于一些客户端请求 API 的情况,我们就不使用 Session 来保持用户状态,改成用 Token 也是可以的。
StatefulSet 的核心功能,就是通过某种方式记录这些状态,然后在 Pod 被重新创建时,能够为新 Pod 恢复这些状态。
StatefulSet 的设计其实非常容易理解。它把真实世界里的应用状态,抽象为了两种情况:
拓扑状态:这种情况意味着,应用的多个实例之间不是完全对等的关系。这些应用实例,必须按照某些顺序启动,比如应用的主节点 A 要先于从节点 B 启动。而如果你把 A 和 B 两个 Pod 删除掉,它们再次被创建出来时也必须严格按照这个顺序才行。并且,新创建出来的 Pod,必须和原来 Pod 的网络标识一样,这样原先的访问者才能使用同样的方法,访问到这个新 Pod。
存储状态:这种情况意味着,应用的多个实例分别绑定了不同的存储数据。对于这些应用实例来说,Pod A 第一次读取到的数据,和隔了十分钟之后再次读取到的数据,应该是同一份,哪怕在此期间 Pod A 被重新创建过。这种情况最典型的例子,就是一个数据库应用的多个存储实例。
所以,StatefulSet 的核心功能,就是通过某种方式记录这些状态,然后在 Pod 被重新创建时,能够为新 Pod 恢复这些状态。
定义一个Headless Service,所有携带了 app=nginx 标签的 Pod,都会被这个 Service 代理起来。它的 clusterIP 字段的值是None,即这个 Service 没有一个 VIP 作为头,这也就是 Headless 的含义。所以这个 Service 被创建后并不会被分配一个 VIP,而是会以 DNS 记录的方式暴露出它所代理的 Pod。只要我访问<pod-name>.<svc-name>.<namespace>.svc.cluster.local这条 DNS 记录,就可以访问到名叫 nginx 的 Service 所代理的某一个 Pod。
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Service
metadata:
name: nginxsvc
namespace: dev
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
EOF
查看创建的service
[root@master ~]# kubectl get svc -n dev -l app=nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginxsvc ClusterIP None <none> 80/TCP 8s
创建PV
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: PersistentVolume
metadata:
name: nginxpv1
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
local:
path: /data
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node1
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: nginxpv2
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
local:
path: /data
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node2
EOF
查看创建的pv
[root@master ~]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
nginxpv1 1Gi RWO Retain Available 7s
nginxpv2 1Gi RWO Retain Available 7s
接下来定义一个 StatefulSet 的 YAML 文件,如下所示
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginxsts
namespace: dev
spec:
#告诉 StatefulSet 控制器,在执行控制循环(Control Loop)的时候,请使用 nginx 这个 Headless Service 来保证 Pod 的“可解析身份”
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
name: web
volumeMounts:
- name: nginxpvc
mountPath: /usr/share/nginx/html
volumeClaimTemplates: #凡是被这个 StatefulSet 管理的 Pod,都会声明一个对应的 PVC
- metadata:
name: nginxpvc
spec:
accessModes:
- ReadWriteOnce #表示这个 Volume 的挂载方式是可读写,并且只能被挂载在一个节点上而非被多个节点共享
resources:
requests:
storage: 1Gi #表示我想要的 Volume 大小至少是 1 GiB
EOF
通过 kubectl 的 -w 参数,即 Watch 功能,实时查看 StatefulSet 创建两个有状态实例的过程。如果创建完了,可以通过这个 StatefulSet 的 Events 看到这些信息
[root@master ~]# kubectl get pods -w -l app=nginx -n dev
NAME READY STATUS RESTARTS AGE
nginxsts-0 0/1 Pending 0 0s
nginxsts-0 0/1 Pending 0 0s
nginxsts-0 0/1 Pending 0 1s
nginxsts-0 0/1 ContainerCreating 0 1s
nginxsts-0 0/1 ContainerCreating 0 2s
nginxsts-0 1/1 Running 0 22s
nginxsts-1 0/1 Pending 0 0s
nginxsts-1 0/1 Pending 0 0s
nginxsts-1 0/1 Pending 0 1s
nginxsts-1 0/1 ContainerCreating 0 1s
nginxsts-1 0/1 ContainerCreating 0 2s
nginxsts-1 1/1 Running 0 2s
StatefulSet 给它所管理的所有 Pod 的名字,进行了编号,编号规则是:<statefulset name>-<ordinal index>。这些编号都是从 0 开始累加,与 StatefulSet 的每个 Pod 实例一一对应,绝不重复。而这些 Pod 的创建,也是严格按照编号顺序进行的。比如,在 nginxsts-0 进入到 Running 状态、并且细分状态(Conditions)成为 Ready 之前,nginxsts-1 会一直处于 Pending 状态。
使用 kubectl exec 命令进入到容器中查看它们的主机名。可以看到,这两个 Pod 的 hostname 与 Pod 名字是一致的,都被分配了对应的编号
[root@master ~]# kubectl exec nginxsts-0 -n dev -- sh -c 'hostname'
nginxsts-0
[root@master ~]# kubectl exec nginxsts-1 -n dev -- sh -c 'hostname'
nginxsts-1
接下来,我们再试着以 DNS 的方式,访问一下这个 Headless Service
[root@master ~]# kubectl run -it --image busybox:1.28.4 test --restart=Never --rm /bin/sh -n dev
/ # nslookup nginxsts-0.nginxsvc
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: nginxsts-0.nginxsvc
Address 1: 10.244.166.135
/ # nslookup nginxsts-1.nginxsvc
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: nginxsts-1.nginxsvc
Address 1: 10.244.104.30
从 nslookup 命令的输出结果中,我们可以看到,在访问 nginxsts-0.nginxsvc 的时候,最后解析到的正是 nginxsts-0 这个 Pod 的 IP 地址;而当访问 nginxsts-1.nginxsvc 的时候,解析到的则是 nginxsts-1 的 IP 地址
[root@master ~]# kubectl get pod -l app=nginx -n dev -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginxsts-0 1/1 Running 0 6m32s 10.244.166.135 node1 <none> <none>
nginxsts-1 1/1 Running 0 6m29s 10.244.104.30 node2 <none> <none>
将pod删除
kubectl delete pod -l app=nginx -n dev
然后 Watch 一下这两个 Pod 的状态变化,可以看到,当我们把这两个 Pod 删除之后,Kubernetes 会按照原先编号的顺序,创建出了两个新的 Pod。并且,Kubernetes 依然为它们分配了与原来相同的网络身份:nginxsts-0.nginxsvc 和 nginxsts-1.nginxsvc。通过这种严格的对应规则,StatefulSet 就保证了 Pod 网络标识的稳定性
[root@master ~]# kubectl get pod -w -l app=nginx -n dev
NAME READY STATUS RESTARTS AGE
nginxsts-0 1/1 Terminating 0 54s
nginxsts-1 1/1 Terminating 0 53s
nginxsts-1 0/1 Terminating 0 53s
nginxsts-0 0/1 Terminating 0 54s
nginxsts-1 0/1 Terminating 0 54s
nginxsts-1 0/1 Terminating 0 54s
nginxsts-0 0/1 Terminating 0 60s
nginxsts-0 0/1 Terminating 0 60s
nginxsts-0 0/1 Pending 0 0s
nginxsts-0 0/1 Pending 0 0s
nginxsts-0 0/1 ContainerCreating 0 0s
nginxsts-0 0/1 ContainerCreating 0 1s
nginxsts-0 1/1 Running 0 1s
nginxsts-1 0/1 Pending 0 0s
nginxsts-1 0/1 Pending 0 0s
nginxsts-1 0/1 ContainerCreating 0 0s
nginxsts-1 0/1 ContainerCreating 0 1s
nginxsts-1 1/1 Running 0 1s
再用 nslookup 命令,查看一下这个新 Pod 对应的 Headless Service,可以看到再次解析到了正确的 Pod IP 地址
[root@master ~]# kubectl run -it --image busybox:1.28.4 test --restart=Never --rm /bin/sh -n dev
/ # nslookup nginxsts-0.nginxsvc
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: nginxsts-0.nginxsvc
Address 1: 10.244.166.139
/ # nslookup nginxsts-1.nginxsvc
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: nginxsts-1.nginxsvc
Address 1: 10.244.104.37
查看pod的ip发现跟解析的ip地址一样
[root@master ~]# kubectl get pod -n dev -l app=nginx -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginxsts-0 1/1 Running 0 4m8s 10.244.166.139 node1 <none> <none>
nginxsts-1 1/1 Running 0 4m7s 10.244.104.37 node2 <none> <none>
当我们创建了 StatefulSet 之后,就会看到 Kubernetes 集群里出现了两个 PVC,这些 PVC都以<PVC 名字 >-<StatefulSet 名字 >-< 编号 >的方式命名
[root@master ~]# kubectl get pvc -l app=nginx -n dev
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
nginxpvc-nginxsts-0 Bound nginxpv1 1Gi RWO 13m
nginxpvc-nginxsts-1 Bound nginxpv2 1Gi RWO 13m
在 Pod 的 Volume 目录里写入一个文件,来验证一下上述 Volume 的分配情况:
for i in 0 1; do kubectl exec nginxsts-$i -n dev -- sh -c 'echo hello $(hostname) > /usr/share/nginx/html/index.html'; done
访问 Pod 里 Nginx 服务器进程,而它会为你返回 /usr/share/nginx/html/index.html 里的内容
[root@master ~]# kubectl get pod -n dev -l app=nginx -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginxsts-0 1/1 Running 0 8m20s 10.244.166.139 node1 <none> <none>
nginxsts-1 1/1 Running 0 8m19s 10.244.104.37 node2 <none> <none>
[root@master ~]# curl 10.244.166.139
hello nginxsts-0
[root@master ~]# curl 10.244.104.37
hello nginxsts-1
删除这两个 Pod,在被删除之后,这两个 Pod 会被按照编号的顺序被重新创建出来,然后再次访问 Nginx 服务
[root@master ~]# kubectl delete pod -l app=nginx -n dev
pod "nginxsts-0" deleted
pod "nginxsts-1" deleted
[root@master ~]# kubectl get pod -n dev -l app=nginx -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginxsts-0 1/1 Running 0 13s 10.244.166.140 node1 <none> <none>
nginxsts-1 1/1 Running 0 11s 10.244.104.38 node2 <none> <none>
[root@master ~]# curl 10.244.166.140
hello nginxsts-0
[root@master ~]# curl 10.244.104.38
hello nginxsts-1
Pod删除之后,对应的 PVC 和 PV,并不会被删除,而这个 Volume 里已经写入的数据,也依然会保存在远程存储服务里。当pod被删除,StatefulSet 控制器发现 Pod 消失了,就会重新创建新的 Pod,新的 Pod 就可以挂载到旧 Pod 对应的那个 Volume,并且获取到保存在 Volume 里的数据。
更新
RollingUpdate
StatefulSet 默认更新策略为RollingUpdate滚动更新,StatefulSet Controller 将自动地删除并重建 StatefulSet 中的每一个 Pod。处理顺序如下:
从序号最大的 Pod 开始,逐个删除和更新每一个 Pod,直到序号最小的 Pod 被更新
当正在更新的 Pod 达到了 Running 和 Ready 的状态之后,才继续更新其前序 Pod
查看默认更新策略
[root@master ~]# kubectl describe sts -n dev nginxsts | grep 'Update Strategy'
Update Strategy: RollingUpdate
更新nginx镜像为1.17.2
kubectl set image sts nginxsts nginx:1.17.2 --record -n dev
这时候,我们可以使用 kubectl rollout status 命令看到这个“滚动更新”的过程,如下所示:
[root@master ~]# kubectl rollout status sts nginxsts -n dev
Waiting for partitioned roll out to finish: 1 out of 2 new pods have been updated...
Waiting for 1 pods to be ready...
Waiting for 1 pods to be ready...
partitioned roll out complete: 2 new pods have been updated...
这一次我在升级命令后面加上了--record 参数,所以这次升级使用到的指令就会自动出现在 StatefulSet 的 rollout history 里面,如下所示:
[root@master ~]# kubectl rollout history sts nginxsts -n dev
statefulset.apps/nginxsts
REVISION CHANGE-CAUSE
1 <none>
2 kubectl set image sts nginxsts nginx=nginx:1.17.2 --record=true --namespace=dev
删除从序号最大的 Pod 开始,逐个删除和更新每一个 Pod,直到序号最小的 Pod 被更新。当正在更新的 Pod 达到了 Running 和 Ready 的状态之后,才继续更新其前序 Pod
[root@master ~]# kubectl get pods -w -l app=nginx -n dev
NAME READY STATUS RESTARTS AGE
nginxsts-0 1/1 Running 0 15m
nginxsts-1 1/1 Running 0 15m
nginxsts-1 1/1 Terminating 0 15m
nginxsts-1 1/1 Terminating 0 15m
nginxsts-1 0/1 Terminating 0 15m
nginxsts-1 0/1 Terminating 0 15m
nginxsts-1 0/1 Terminating 0 15m
nginxsts-1 0/1 Pending 0 0s
nginxsts-1 0/1 Pending 0 0s
nginxsts-1 0/1 ContainerCreating 0 0s
nginxsts-1 0/1 ContainerCreating 0 1s
nginxsts-1 1/1 Running 0 1s
nginxsts-0 1/1 Terminating 0 15m
nginxsts-0 1/1 Terminating 0 15m
nginxsts-0 0/1 Terminating 0 15m
nginxsts-0 0/1 Terminating 0 15m
nginxsts-0 0/1 Terminating 0 15m
nginxsts-0 0/1 Pending 0 0s
nginxsts-0 0/1 Pending 0 0s
nginxsts-0 0/1 ContainerCreating 0 0s
nginxsts-0 0/1 ContainerCreating 0 1s
nginxsts-0 1/1 Running 0 1s
查看被更新的pod版本,发现已经完成了更新
[root@master ~]# kubectl describe pod nginxsts -n dev | grep Image:
Image: nginx:1.17.2
Image: nginx:1.17.2
OnDelete
如果 StatefulSet 的 .spec.updateStrategy.type 字段被设置为 OnDelete,当您修改 .spec.template 的内容时,StatefulSet Controller 将不会自动更新其 Pod。您必须手工删除 Pod,此时 StatefulSet Controller 在重新创建 Pod 时,使用修改过的 .spec.template 的内容创建新 Pod。
这里我们将更新策略改为OnDelete
kubectl patch statefulset nginxsts -n dev --type='json' -p='[{"op": "remove", "path": "/spec/updateStrategy/rollingUpdate"}]'
kubectl patch statefulset nginxsts -n dev --type='json' -p='[{"op": "replace", "path": "/spec/updateStrategy/type", "value":"OnDelete"}]'
更新镜像
kubectl patch sts nginxsts -n dev --type='json' -p='[{"op": "replace", "path": "/spec/template/spec/containers/0/image", "value":"nginx:1.17.3"}]'
镜像更新完后,发现pod的镜像并没有更新
[root@master ~]# kubectl describe pod -n dev | grep Image:
Image: nginx:1.17.2
Image: nginx:1.17.2
此时我们可以删除一个pod,如nginxsts-0,再进行观察,可以看到,只有被删除的 nginxsts-0 更新到指定的镜像版本
[root@master ~]# kubectl delete pod nginxsts-0 -n dev
pod "nginxsts-0" deleted
[root@master ~]# kubectl describe pod -n dev nginxsts-0 | grep Image:
Image: nginx:1.17.3
[root@master ~]# kubectl describe pod -n dev nginxsts-1 | grep Image:
Image: nginx:1.17.2
最后我们将所有的pod进行删除,完成所有的更新
kubectl delete pod -l app=nginx -n dev
查看pod镜像版本,发现已完成了更新
[root@master ~]# kubectl describe pod -n dev | grep Image:
Image: nginx:1.17.3
Image: nginx:1.17.3
自动扩缩
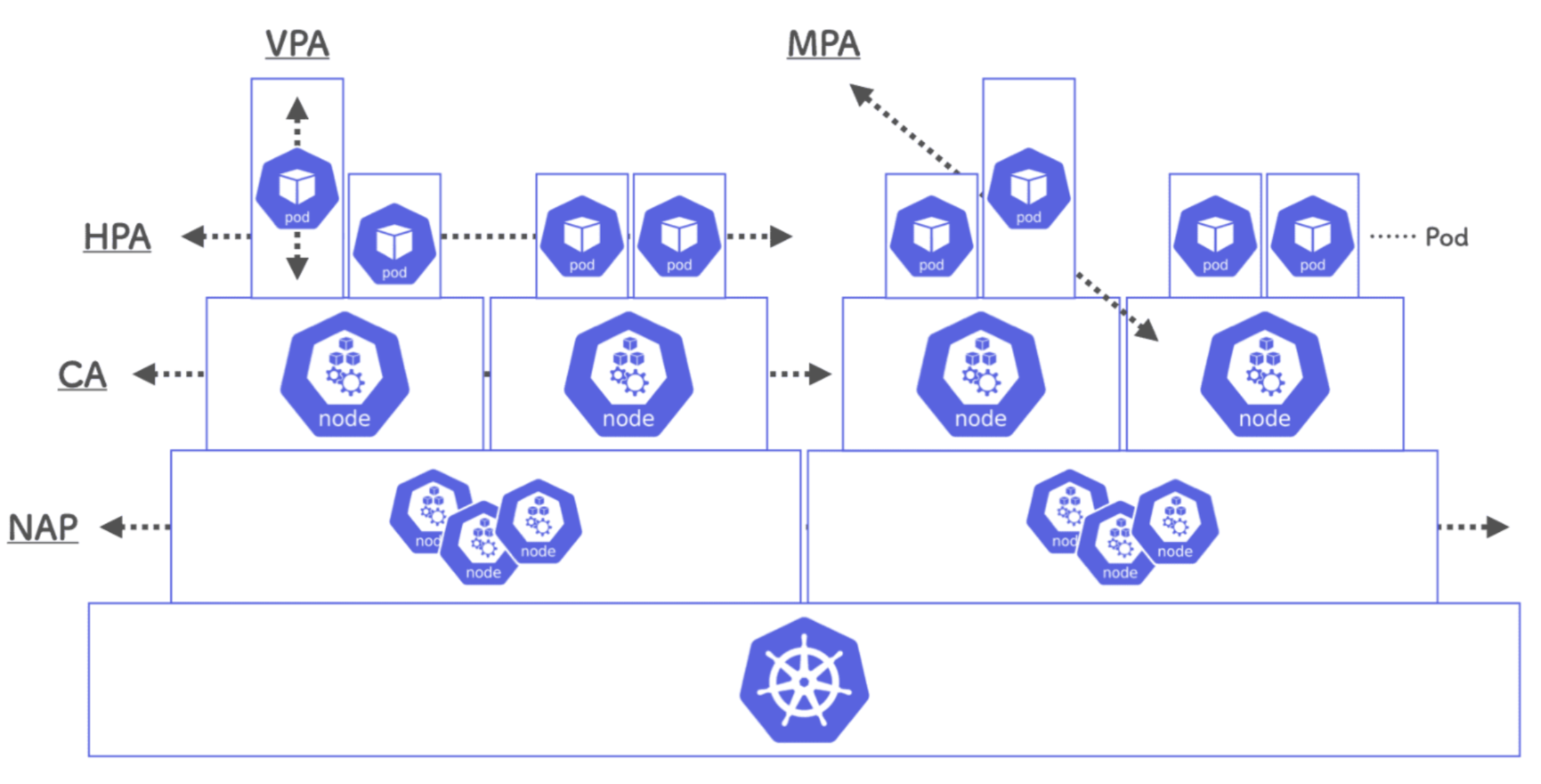
水平 Pod 自动缩放器 (HPA)
使用 kubectl scale 命令可以来实现 Pod 的扩缩容功能,但是这个毕竟是完全手动操作的,要应对线上的各种复杂情况,我们需要能够做到自动化去感知业务,来自动进行扩缩容。为此Kubernetes 也为我们提供了这样的一个资源对象:Horizontal Pod Autoscaling(Pod 水平自动伸缩),简称HPA,HPA 通过监控分析一些控制器控制的所有 Pod 的负载变化情况来确定是否需要调整 Pod 的副本数量
HPA 仅适用于 Deployment 和 ReplicaSet,在V1版本中仅支持根据 Pod的 CPU 利用率扩所容,在 v1alpha 版本中,支持根据内存和用户自定义的 metric 扩缩容。HPA它并不是一个控制器,而是控制器的附属品。比如运行一个RS ,RS管理者两个pod,基于RS在定义一个HPA去管理RS,HPA定义以下内容监视pod资源利用率:当 CPU>80 就扩展,扩展最大值为10个最小值2个,当CPU<80,还会自动删除(弹性伸缩)
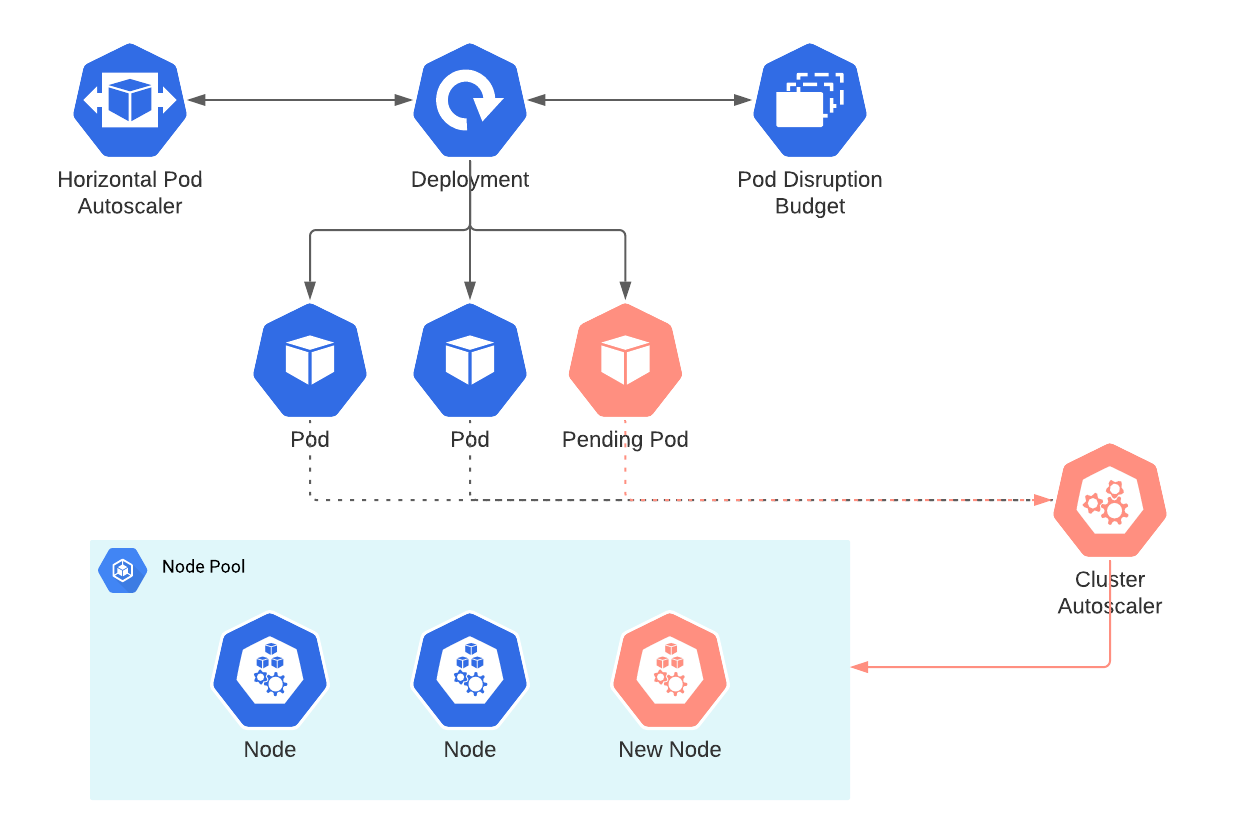
Metrics Server
在 HPA 的第一个版本中,我们需要 Heapster 提供 CPU 和内存指标,在 HPA v2 过后就需要安装 Metrcis Server 了,Metrics Server 可以通过标准的 Kubernetes API 把监控数据暴露出来,有了 Metrics Server 之后,我们就完全可以通过标准的 Kubernetes API 来访问我们想要获取的监控数据了。Metrics Server会请求每台node节点上的Kubelet接口来获取监控数据,并通过Metrics API在 Kubernetes apiserver 中公开指标数据,以供Horizontal Pod Autoscaler和Vertical Pod Autoscaler使用,也可以通过访问 kubectl top node/pod 查看指标数据。
Metrcis Server 官方仓库地址:https://github.com/kubernetes-sigs/metrics-server
wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.6.0/components.yaml
kubeadm安装节点的kubelet使用的是自签证书,若Metrics Server直接请求kubelet接口,将产生证书校验失败的错误,因此需要在components.yaml文件中添加--kubelet-insecure-tls参数跳过证书校验。如果不增加这一行的话,就会出现如下错误:k8s metric-server报错 x509: cannot validate
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-insecure-tls #添加参数
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
image: cnych/metrics-server:v0.6.0 #镜像源修改
部署
kubectl apply -f components.yaml
部署完后,可以通过如下命令来验证
[root@master ~]# kubectl get pods -n kube-system -l k8s-app=metrics-server
NAME READY STATUS RESTARTS AGE
metrics-server-5c4d856598-b9rjr 1/1 Running 0 6m22s
[root@master ~]# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master 164m 8% 1393Mi 75%
node1 61m 0% 971Mi 4%
node2 56m 2% 701Mi 37%
当我们使用kubectl get apiservice可以看到其他都是local类型的service,v1beta1.metrics.k8s.io的server来自kube-system/metrics-server
[root@master ~]# kubectl get apiservice | grep metrics
v1beta1.metrics.k8s.io kube-system/metrics-server True 6m45s
v1beta1.node.k8s.io Local True 9d
......
当我们部署metrics-server时其中部署了一个名字叫v1beta1.metrics.k8s.io的APIService,对应访问的就是kube-system名称空间下的metrics-server服务
kubectl get --raw /apis/metrics.k8s.io/v1beta1/nodes | python -m json.tool
比如当我们访问上面的 API 的时候,我们就可以获取到该 nodes的资源数据,这些数据其实是来自于 kubelet 的 Summary API 采集而来的。不过需要说明的是我们这里可以通过标准的 API 来获取资源监控数据,并不是因为 Metrics Server 就是 APIServer 的一部分,而是通过 Kubernetes 提供的 Aggregator 汇聚插件来实现的,是独立于 APIServer 之外运行的。
基于CPU扩缩容
我们用 Deployment 来创建一个 Nginx Pod,然后利用 HPA 来进行自动扩缩容,资源清单如下所示:
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-demo
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
resources:
requests:
memory: 50Mi
cpu: 50m
EOF
查看创建的Deployment
[root@master ~]# kubectl get pods -l app=nginx -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
hpa-demo-6c57788744-dlc7c 1/1 Running 0 2m39s 10.244.166.190 node1 <none> <none>
使用 kubectl autoscale 命令来创建一个 HPA 资源对象
kubectl autoscale deployment hpa-demo --cpu-percent=10 --min=1 --max=10
此命令创建了一个关联资源 hpa-demo 的 HPA,最小的 Pod 副本数为1,最大为10。HPA 会根据设定的 cpu 使用率(10%)动态的增加或者减少 Pod 数量
[root@master ~]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo Deployment/hpa-demo <unknown>/10% 1 10 0 14s
现在我们来创建一个 busybox 的 Pod,并且循环访问上面创建的 Pod,增大负载进行测试
[root@master ~]# kubectl run -it --image busybox test-hpa --restart=Never --rm /bin/sh
/ # while true; do wget -q -O- http://10.244.166.190; done
观察pod的变化
[root@master ~]# kubectl get pods -l app=nginx -w
NAME READY STATUS RESTARTS AGE
hpa-demo-6c57788744-dlc7c 1/1 Running 0 5m56s
hpa-demo-6c57788744-zxpql 0/1 Pending 0 0s
hpa-demo-6c57788744-7p2cj 0/1 Pending 0 0s
hpa-demo-6c57788744-zxpql 0/1 Pending 0 1s
hpa-demo-6c57788744-7p2cj 0/1 Pending 0 1s
hpa-demo-6c57788744-zxpql 0/1 ContainerCreating 0 1s
hpa-demo-6c57788744-7p2cj 0/1 ContainerCreating 0 1s
hpa-demo-6c57788744-zxpql 0/1 ContainerCreating 0 2s
hpa-demo-6c57788744-7p2cj 0/1 ContainerCreating 0 2s
hpa-demo-6c57788744-rcckf 0/1 Pending 0 0s
......
观察hpa的变化
[root@master ~]# kubectl get hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo Deployment/hpa-demo 0%/10% 1 10 1 2m45s
hpa-demo Deployment/hpa-demo 0%/10% 1 10 1 5m17s
hpa-demo Deployment/hpa-demo 26%/10% 1 10 1 9m3s
hpa-demo Deployment/hpa-demo 190%/10% 1 10 3 9m18s
hpa-demo Deployment/hpa-demo 222%/10% 1 10 6 9m34s
hpa-demo Deployment/hpa-demo 236%/10% 1 10 10 9m49s
hpa-demo Deployment/hpa-demo 232%/10% 1 10 10 10m
hpa-demo Deployment/hpa-demo 214%/10% 1 10 10 10m
我们可以看到已经自动拉起了很多新的 Pod,最后定格在了我们上面设置的 10 个 Pod,同时查看资源 hpa-demo 的副本数量,副本数量已经从原来的1变成了10个:
[root@master ~]# kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
hpa-demo-6c57788744-5qbbg 1/1 Running 0 3m9s
hpa-demo-6c57788744-7p2cj 1/1 Running 0 3m25s
hpa-demo-6c57788744-dhxhb 1/1 Running 0 2m54s
hpa-demo-6c57788744-dlc7c 1/1 Running 0 15m
hpa-demo-6c57788744-g7wrg 1/1 Running 0 2m54s
hpa-demo-6c57788744-rcckf 1/1 Running 0 3m10s
hpa-demo-6c57788744-sh2nz 1/1 Running 0 2m54s
hpa-demo-6c57788744-vw5mz 1/1 Running 0 3m9s
hpa-demo-6c57788744-xjlmf 1/1 Running 0 2m54s
hpa-demo-6c57788744-zxpql 1/1 Running 0 3m25s
现在我们来关掉 busybox 来减少负载,然后等待一段时间观察下 HPA 和 Deployment 对象:
[root@master ~]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo Deployment/hpa-demo 0%/10% 1 10 1 40m
[root@master ~]# kubectl get deployment hpa-demo
NAME READY UP-TO-DATE AVAILABLE AGE
hpa-demo 1/1 1 1 43m
从 Kubernetes v1.12 版本开始我们可以通过设置 kube-controller-manager 组件的 --horizontal-pod-autoscaler-downscale-stabilization 参数来设置一个持续时间,用于指定在当前操作完成后, HPA 必须等待多长时间才能执行另一次缩放操作。默认为5分钟,也就是默认需要等待5分钟后才会开始自动缩放。快启慢缩
基于内存扩缩容
现在我们再用 Deployment 来创建一个 Nginx Pod,然后利用 HPA 基于内存来进行自动扩缩容
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-mem-demo
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
volumes:
- name: increase-mem-script
configMap:
name: increase-mem-config
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: increase-mem-script
mountPath: /etc/script
resources:
requests:
memory: 50Mi
cpu: 50m
securityContext:
privileged: true
EOF
这里我们将一个名为 increase-mem-config 的 ConfigMap 资源对象挂载到了容器中,该配置文件是用于后面增加容器内存占用的脚本,由于这里增加内存的脚本需要使用到 mount 命令,这需要声明为特权模式,所以我们添加了 securityContext.privileged=true 这个配置
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: ConfigMap
metadata:
name: increase-mem-config
data:
increase-mem.sh: |
#!/bin/bash
mkdir /tmp/memory
mount -t tmpfs -o size=40M tmpfs /tmp/memory #挂在一个大小为40M类型的tmpfs文件系统
dd if=/dev/zero of=/tmp/memory/block #bs=1M count=100 #产生100M的文件
sleep 60
rm /tmp/memory/block
umount /tmp/memory
rmdir /tmp/memory
EOF
使用df命令,可以看到tmpfs文件
[root@node1 tmp]# free -h
total used free shared buff/cache available
Mem: 23G 816M 21G 18M 1.7G 22G
Swap: 0B 0B 0B
[root@master ~]# df -h | grep tmpfs
tmpfs 12G 0 12G 0% /dev/shm
tmpfs是一个临时文件系统,驻留在内存中,所以/dev/shm这个目录不在硬盘上,而是在内存里,所以读写非常快,可以提供较高的访问速度。在linux系统中,tmpfs默认最大为内存的一半大小,但是因为数据是在内存里,所以断电后文件会丢失,内存数据不会和硬盘中数据一样可以永久保存
产生一个100M的文件,文件系统只有40M,所以会提示 No space left on device

查看pod是否运行正常
[root@master ~]# kubectl get pod -l app=nginx
NAME READY STATUS RESTARTS AGE
hpa-mem-demo-74cf7f674f-tqcxp 1/1 Running 0 32s
接下来,创建一个基于内存的 HPA 资源对象
cat <<EOF | kubectl apply -f -
apiVersion: autoscaling/v2beta1 #注意这里使用的 apiVersion 是 autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: hpa-mem-demo
minReplicas: 1
maxReplicas: 5
metrics:
- type: Resource
resource:
name: memory
targetAverageUtilization: 60
EOF
查看创建的hpa
[root@master ~]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx-hpa Deployment/hpa-mem-demo 21%/60% 1 5 1 42s
HPA 资源对象已经部署成功了,接下来我们对应用进行压测,将内存压上去,直接执行上面我们挂载到容器中的 increase-mem.sh 脚本即可
$ kubectl exec -it hpa-mem-demo-66944b79bf-tqrn9 /bin/bash
root@hpa-mem-demo-66944b79bf-tqrn9:/# ls /etc/script/
increase-mem.sh
root@hpa-mem-demo-66944b79bf-tqrn9:/# source /etc/script/increase-mem.sh
dd: writing to '/tmp/memory/block': No space left on device
81921+0 records in
81920+0 records out
41943040 bytes (42 MB, 40 MiB) copied, 0.584029 s, 71.8 MB/s
然后打开另外一个终端观察 HPA 资源对象的变化情况,可以看到内存使用已经超过了我们设定的 60% 这个阈值了,HPA 资源对象也已经触发了自动扩容
[root@master ~]# kubectl get hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx-hpa Deployment/hpa-mem-demo 21%/60% 1 5 1 118s
nginx-hpa Deployment/hpa-mem-demo 21%/60% 1 5 1 2m32s
nginx-hpa Deployment/hpa-mem-demo 21%/60% 1 5 1 2m47s
nginx-hpa Deployment/hpa-mem-demo 103%/60% 1 5 1 3m2s
nginx-hpa Deployment/hpa-mem-demo 103%/60% 1 5 2 3m18s
查看pod变成了两个副本了
[root@master ~]# kubectl get pod -l app=nginx
NAME READY STATUS RESTARTS AGE
hpa-mem-demo-74cf7f674f-nqvv9 1/1 Running 0 47s
hpa-mem-demo-74cf7f674f-tqcxp 1/1 Running 0 4m36s
过了一分钟后内存使用率又会下降,这是因为我们脚本中写了sleep 60秒后会删除tmpfs中的block文件,也就是释放了40MB内存,但是HPA默认5分钟过后会进行缩放,到这里就完成了基于内存的 HPA 操作
垂直 Pod 自动缩放器 (VPA)
相对于水平自动扩缩容(HPA)在pod资源紧张时扩充pod个数来平衡负载。Pod的垂直扩容会自动调整Pod资源申请的requests值及limits值,它会依据pod当前运行状况动态地为Pod资源申请CPU及内存使用量。解放了手动设置request值及limits值的难点,使Pod运行更加智能。
与HPA一样,VPA在运行时的指标同样是由Metrics Server提供,所以安装VPA控制器前首先先运行好Metrics Server
安装VPA控制器,本次实验采用0.8版本的部署包
#git clone https://github.com/kubernetes/autoscaler.git
wget https://codeload.github.com/kubernetes/autoscaler/tar.gz/vertical-pod-autoscaler-0.8.0
解压后进入vertical-pod-autoscaler目录,批量修改镜像地址为registry.cn-shanghai.aliyuncs.com/ltzhang
cd autoscaler-vertical-pod-autoscaler-0.8.0/vertical-pod-autoscaler
sed -i 's@k8s.gcr.io/@registry.cn-shanghai.aliyuncs.com/ltzhang/@g' `egrep -r "\<image\>" deploy/ | awk -F: '{print $1}'`
安装VPA控制器
[root@master vertical-pod-autoscaler]# ./hack/vpa-up.sh
安装完成后会生成自定义API资源autoscaling.k8s.io并在其下生成两个资源VerticalPodAutoscalerCheckpoint及VerticalPodAutoscaler

创建测试应用
kubectl apply -f examples/hamster.yaml
测试pod会申请100m的CPU及50M内存并且其中会运行shell命令不断来消耗CPU及内存:
resources:
requests:
cpu: 100m
memory: 50Mi
command: ["/bin/sh"]
args:
- "-c"
- "while true; do timeout 0.5s yes >/dev/null; sleep 0.5s; done"
在pod运行中,VPA控制器会发现应用所需要的CPU及内存不断增加。根据当前的updatePolicy会不断重建pod给予Pod更多的CPU及内存申请值
Pod中的资源申请已经上调为587m个CPU及256MiB内存了,这都是VPA控制器自动帮我们完成的。在应用负载降低时,同样会删除Pod并给予相对资源申请值。

updatePolicy:这个字段可以通过describe vpa hamster-vpa看到,用于定义更新策略,目前有以下四种更新策略:
Off:仅会在VPA控制器中发现建议的资源申请值,Pod中的依然是原来的值。相当于dry run模式
Initial:仅会在Pod被创建时给予一个推荐的值,在Pod运行过程中不会修改。
Recreate:默认模式。除了在Pod创建时给予一个推荐值外,在Pod运行过程中会反复调整。调整的方式就是删除旧Pod新建新的Pod
Auto:相当于Recreate
查看测试Pod配置文件查看有关VPA的定义
---
apiVersion: "autoscaling.k8s.io/v1beta2"
kind: VerticalPodAutoscaler
metadata:
name: hamster-vpa
spec:
targetRef: #定义了VPA控制器作用的资源名称即相应的类型及API组
apiVersion: "apps/v1"
kind: Deployment
name: hamster
resourcePolicy: #定义指定资源(这里是CPU及内存)的计算策略。CPU在100m-1间浮动,内存在50MiB-500MiB之间浮动
containerPolicies:
- containerName: '*'
minAllowed:
cpu: 100m
memory: 50Mi
maxAllowed:
cpu: 1
memory: 500Mi
controlledResources: ["cpu", "memory"]
多维 Pod 自动缩放器 (MPA)
这是一种同时实现水平和垂直缩放的方法,以克服上一节中描述的同时使用 HPA 和 VPA 的限制。目前,唯一支持的扩展策略是一种模式:基于CPU使用率的水平扩展+内存资源请求的补偿,但我无法想象需要其他策略的情况,所以在实践中我不推荐它在大多数情况下,仅此政策就足够了
CA 节点扩缩容
节点无法满足 Pod Request 要求,而处于 Pending 状态触发扩容操作;节点低负载,并且节点上的 Pod 能移到其他节点触发缩容操作
很多云厂商都提供 Provider 给组件,AutoScaler 采用定期检测的方式,触发厂商扩缩容的接口动作。比如EKS、CCE、ACK、TKE 无一例外都是采用 autoscaler 组件结合自身 IaaS 服务实现节点的弹性伸缩。
由于底层都是采用 autoscaler 组件,在产品层面的呈现也会有所体现。以 EKS 为例,如下图:
EKS 集群,具有若干节点组,每个节点组构成一个弹性伸缩的单元。如下图,节点组最少有 1 个节点,最多有 7 个节点:
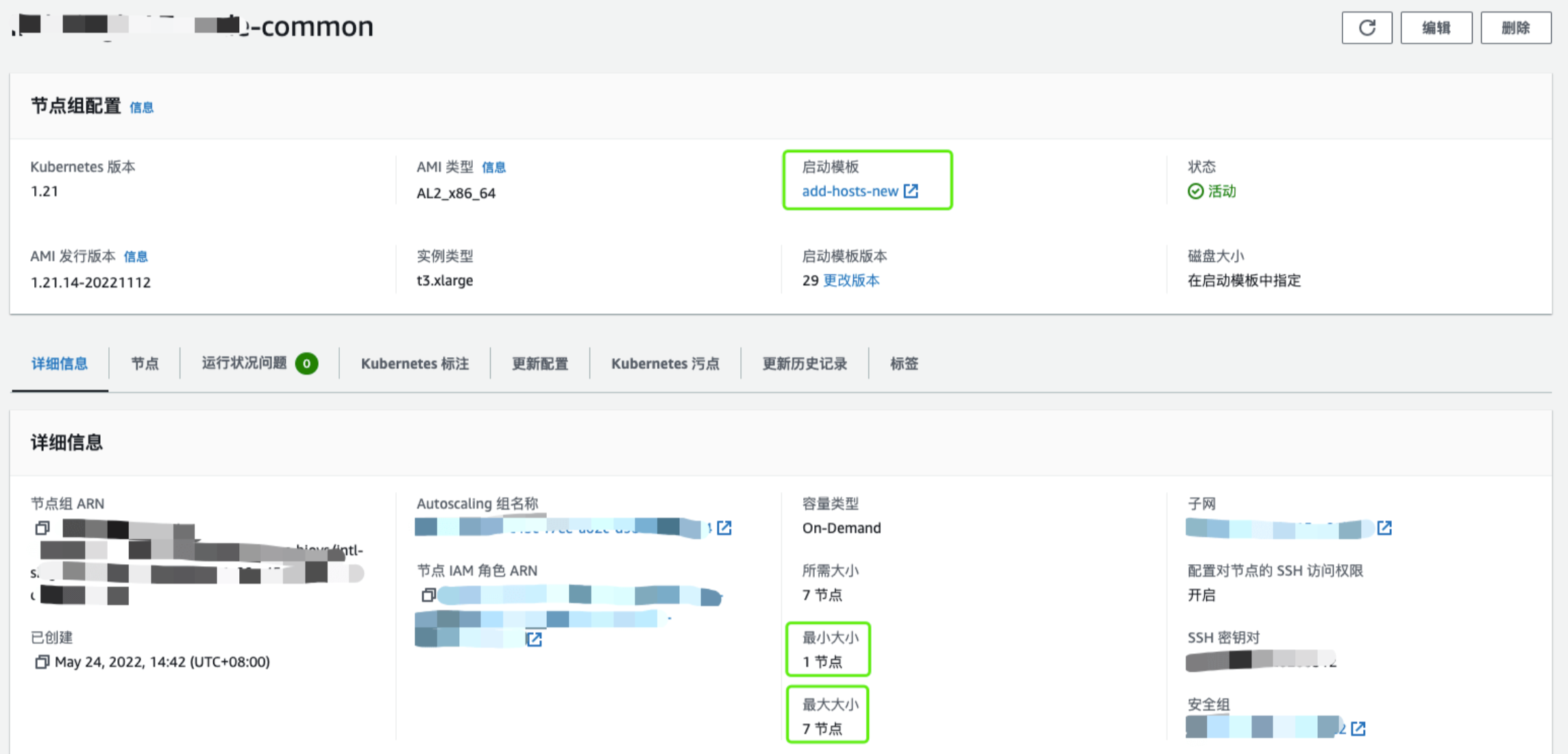
EKS 的节点弹性是针对节点组的,同一个节点组下的节点具有相同的机器配置、污点、标签、主机启动模板。当 EKS 判断需要进行节点扩容时,会结合节点组允许的最大节点数,进行扩容。这样也保障扩容出来的节点已经打上正确的污点和标签,能够直接被 Kubernetes 调度器使用。另外,节点组的概念,在产品和使用层面还可以包装成超级节点。只要节点数量的上限足够大,一个节点组就能提供超大的计算和内存资源池
HPA+CA实现工作负载和节点联动弹性伸缩
企业应用的流量大小不是每时每刻都一样,有高峰和低谷,如果每时每刻都要保持可承载高峰流量的机器数目,那么成本会很高。通常解决这个问题的办法就是根据流量大小或资源占用率自动调群中工作负载及节点的数量,也就是弹性伸缩。通常情况下,HPA和CA两者需要配合使用,因为HPA需要集群有足够的vCPU和内存等资源才能扩容成功,当集群资源不够时需要CA扩容节点,使得集群有足够资源;而当HPA缩容后集群会有大量空余资源,这时就需要CA对集群节点进行缩容以释放资源,才不至于造成浪费。
比如在CCE中,由于使用Pod/容器部署应用,容器可使用的资源是在部署时即配置好,不会无限制使用CCE节点中的资源,所以在CCE中弹性伸缩需要先对Pod数量进行伸缩,Pod数量增加后节点资源使用率才会增加,进而根据节点资源使用率再去伸缩集群中节点的数量。
CCE中的弹性伸缩主要使用HPA(Horizontal Pod Autoscaling)和CA(Cluster AutoScaling)两种弹性伸缩策略,HPA负责工作负载弹性伸缩,也就是应用层面的弹性伸缩;CA负责节点弹性伸缩,也就是资源层面的弹性伸缩。HPA根据监控指标进行扩容,当集群资源不够时,新创建的Pod会处于Pending状态,CA会检查所有Pending状态的Pod,根据用户配置的扩缩容策略,选择出一个最合适的节点池,在这个节点池扩容
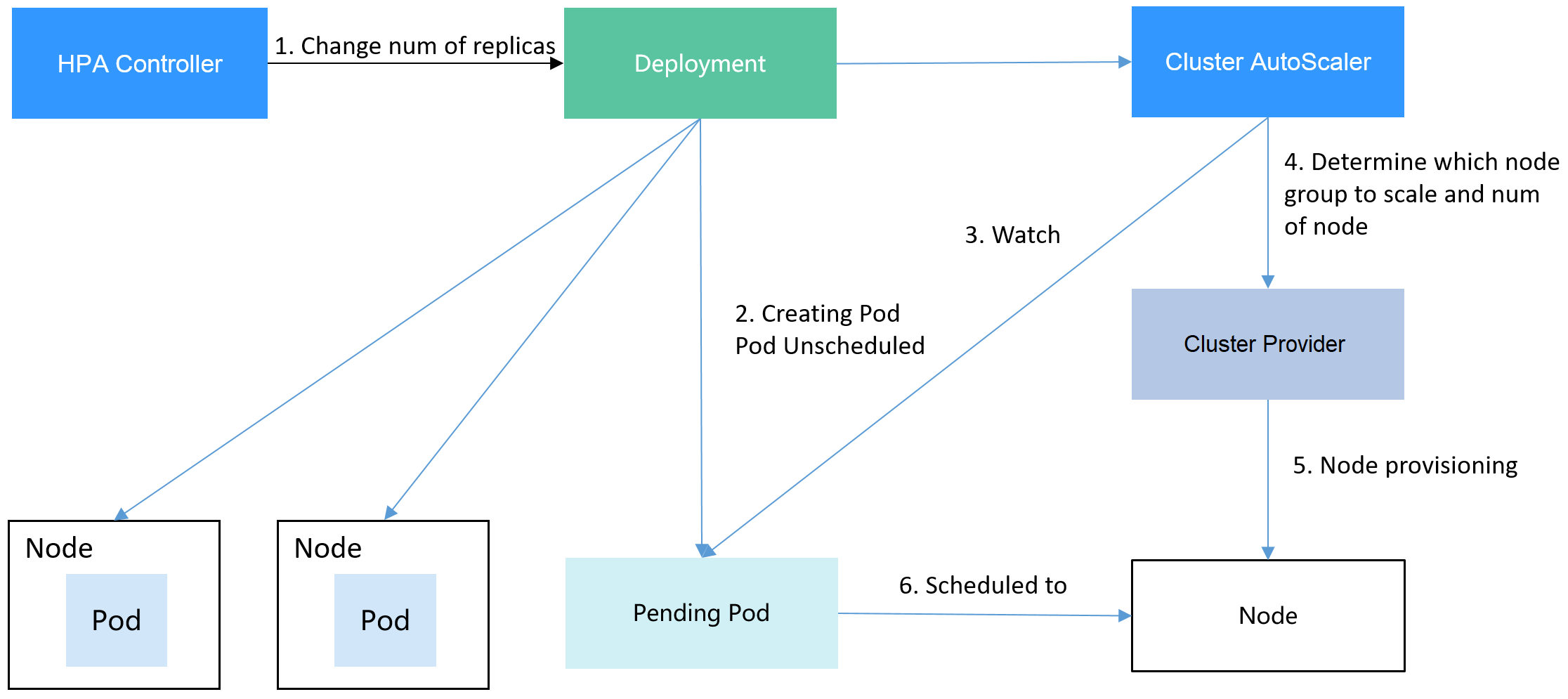
本案例将通过一个示例介绍HPA+CA两种策略配合使用下弹性伸缩的过程,从而帮助您更好的理解和使用弹性伸缩。
首先将镜像上传到镜像仓库

创建有1个工作节点规格2U4G,节点需要带弹性公网IP,以便访问公网。在CCE控制台“插件管理”中,如未安装请首先给集群安装好以下插件:
autoscaler:CA插件
metrics-server:是Kubernetes集群范围资源使用数据的聚合器,能够收集包括了Pod、Node、容器、Service等主要Kubernetes核心资源的度量数据
创建节点池和CA策略
在CCE控制台中,创建一个节点池,添加一个2U4G的节点,并打开节点池的弹性扩缩容开关,如下图所示
修改autoscaler插件配置,将自动缩容开关打开,并配置缩容相关参数,例如节点资源使用率小于50%时进行缩容扫描,启动缩容。插件规格建议至少选择“高可用50”,即保证运行不少于2个autoscaler实例。下面配置的节点池弹性伸缩,会根据Pod的Pending状态进行扩容,根据节点的资源使用率进行缩容。

CCE同时支持创建CA策略,这里的CA策略可以根据CPU/内存分配率扩容、还可以按照时间定期扩容。CA策略可以与autoscaler默认的根据Pod的Pending状态进行扩容共同作用。

创建工作负载
使用刚构建的busy-php容器镜像创建无状态工作负载,副本数为1。vCPU设置为0.5 core、内存设置为200MiB,limits与requests建议取值保持一致,避免扩缩容过程中出现震荡

然后再为这个负载创建一个Nodeport类型的Service,以便能从外部访问

创建HPA策略
创建HPA策略,如下图所示,该策略关联了名为busy-php的工作负载,期望CPU使用率为50%。
另外有两个配置参数,一个是CPU的阈值范围,最低30,最高70,表示CPU使用率在30%到70%之间时,不会扩缩容,防止小幅度波动造成影响。另一个是扩缩容冷却时间窗,表示策略成功触发后,在缩容/扩容冷却时间内,不会再次触发缩容/扩容,以防止短期波动造成影响。

准备压测环境
在本例中使用linux开源压测工具wrk模拟外部压力负载,您也可以使用其它压测工具进行模拟,确保对集群中的工作负载可形成持续的压力即可。为确保压测效果,建议在节点池外的同一集群工作节点上安装并运行压测工具,本例以在linux工作节点上安装wrk为例。如未安装git、gcc,首先安装:
yum -y install git
yum -y install gcc
下载wrk工具:
git clone https://github.com/wg/wrk.git
进入wrk目录,编译:
cd wrk && make
完成编译后,可将wrk可执行文件软连接至/usr/local/bin等目录下,方便后续使用。首先通过如下命令测试工作负载是否正常,正常结果应为返回OK。
curl http://192.168.0.149:31504
其中的{ip:port}为busy-php工作负载的访问地址和端口,可在负载详情页中获取

验证wrk工具并查看结果是否正常,wrk的详细使用方法和参数说明,请参考官方介绍https://github.com/wg/wrk
wrk -t2 -c10 -d3s http://192.168.0.149:31504/
弹性伸缩
查看HPA策略,因为之前已进行过连通性测试,可以看到目标负载busy-php的指标(CPU使用率)为16%

通过如下命令开始打压,其中{ip:port}为负载的访问地址,可以在busy-php负载的详情页中查询
wrk -t10 -c1000 -d1200s http://192.168.0.149:31504/
观察工作负载的伸缩过程,可以看到第二行开始负载的CPU使用率达到99%,超过了目标值,此时触发了工作负载的弹性伸缩,将负载扩容为2个副本/Pod,随后的几分钟内,CPU使用并未下降,这是因为虽然工作负载进行了扩容,但新创建的Pod并不一定创建成功,一般是因为资源不足Pod处于Pending状态,此时需同步进行节点扩容。

如下图所示,工作负载的副本数已通过动态扩容达到8,但因为没有充足的vCPU和内存资源,会被k8s集群标记为实例调度失败

之后工作负载CPU使用率一直保持在99%以上,工作负载持续进行扩容,副本数从2个扩容到4个,再扩容到8个最后扩容至12个。观察负载和HPA策略的详情,从事件中可以看到负载的扩容的过程和策略生效的时间线,如下所示。

与此同时,查看节点池中的节点数量,发现在刚才工作负载扩容的同时,节点数量也扩容了。在CCE控制台中可以看到伸缩历史,节点数量会根据CA及autoscaler策略,通过判断Pod的Pending状态进行扩容。

另外还可以看到CA策略也执行了一次,当集群中CPU分配率大于70%,将节点池中节点数量从2扩容到了3

本例中节点扩容机制具体是这样:
Pod数量变为4后,由于没有资源,Pod处于Pending状态,触发了autoscaler默认的扩容策略,将节点数量进行增加。同时因为集群中CPU分配率大于70%,触发了CA策略,从而将节点数增加一个,从控制台上伸缩历史可以看出来。根据分配率扩容,可以保证集群一直处于资源充足的状态。
本例中启动压测时设置了压力持续时间,因此当压测工具停止打压后,观察负载Pod数量。CPU负载快速下降,工作负载开始缩容,工作负载副本数也快速由12缩容至2个,最后恢复到1个副本。
观察负载和HPA策略的详情,从事件中可以看到负载的缩容过程和策略生效的时间线,在控制台中同样可以看到HPA策略生效历史。

再继续观察,会看到节点池中的节点数量会被不断缩容。

最终,节点池节点数量将稳定在2,这里节点没有继续被缩容,是因为节点池中这两个节点都存在namespace为kube-system的Pod且不是DaemonSets创建的Pod

通过上述的实践可以看到,使用CCE的HPA+CA机制,可以很容易做到工作负载及节点的弹性伸缩,且节点和Pod的伸缩过程可以非常方便的观察到,使用HPA+CA做弹性伸缩能够满足大部分业务场景需求。
CRD自定义资源类型
Custom Resource Define 简称 CRD,是 Kubernetes(v1.7+)为提高可扩展性,让开发者去自定义资源的一种方式。CRD 资源可以动态注册到集群中,注册完毕后,用户可以通过 kubectl 来创建访问这个自定义的资源对象,类似于操作 Pod 一样。不过需要注意的是 CRD 仅仅是资源的定义而已,需要一个 Controller 去监听 CRD 的各种事件来添加自定义的业务逻辑。
如果说只是对 CRD 资源本身进行 CRUD 操作的话,不需要 Controller 也是可以实现的,相当于就是只有数据存入了 etcd 中,而没有对这个数据的相关操作而已。比如我们可以定义一个如下所示的 CRD 资源清单文件:
cat <<EOF | kubectl apply -f -
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
# name 必须匹配下面的spec字段:<plural>.<group>
name: crontabs.stable.example.com
spec:
# group 名用于 REST API 中的定义:/apis/<group>/<version>
group: stable.example.com
# 列出自定义资源的所有 API 版本
versions:
- name: v1beta1 # 版本名称,比如 v1、v2beta1 等等
served: true # 是否开启通过 REST APIs 访问 `/apis/<group>/<version>/...`
storage: true # 必须将一个且只有一个版本标记为存储版本
schema: # 定义自定义对象的声明规范
openAPIV3Schema:
description: Define CronTab YAML Spec
type: object
properties:
spec:
type: object
properties:
cronSpec:
type: string
image:
type: string
replicas:
type: integer
# 定义作用范围:Namespaced(命名空间级别)或者 Cluster(整个集群)
scope: Namespaced
names:
# kind 是 sigular 的一个驼峰形式定义,在资源清单中会使用
kind: CronTab
# plural 名字用于 REST API 中的定义:/apis/<group>/<version>/<plural>
plural: crontabs
# singular 名称用于 CLI 操作或显示的一个别名
singular: crontab
# shortNames 相当于缩写形式
shortNames:
- ct
EOF
这个地方的定义和我们定义普通的资源对象比较类似,我们说我们可以随意定义一个自定义的资源对象,但是在创建资源的时候,肯定不是任由我们随意去编写 YAML 文件的,当我们把上面的 CRD 文件提交给 Kubernetes 之后,Kubernetes 会对我们提交的声明文件进行校验,从定义可以看出 CRD 是基于 OpenAPI v3 schem 进行规范的。当然这种校验只是对于字段的类型进行校验,比较初级,如果想要更加复杂的校验,这个时候就需要通过 Kubernetes 的 admission webhook 来实现了。关于校验的更多用法,可以前往官方文档查看。
创建这个 CRD 后,这个时候我们可以查看到集群中已经有我们定义的这个 CRD 资源对象了:
[root@master ~]# kubectl get crd | grep crontabs.stable.example.com
crontabs.stable.example.com 2024-07-05T13:48:00Z
这个时候一个新的 namespace 级别的 RESTful API 就会被创建,这个 CRD 相当于告诉了 Kubernetes:接下来,如果有 API 组(Group)是stable.example.com、API 资源类型(Kind)是 CronTab 的 YAML 文件被提交上来,你可一定要认识啊
/apis/stable/example.com/v1beta1/namespaces/*/crontabs/...
然后我们就可以使用这个 API 端点来创建和管理自定义的对象,这些对象的类型就是上面创建的 CRD 对象规范中的 CronTab。
现在在 Kubernetes 集群中我们就多了一种新的资源叫做 crontabs.stable.example.com,我们就可以使用它来定义一个 CronTab 资源对象了,这个自定义资源对象里面可以包含的字段我们在定义的时候通过 schema 进行了规范,比如现在我们来创建一个如下所示的资源清单
cat <<EOF | kubectl apply -f -
apiVersion: "stable.example.com/v1beta1"
kind: CronTab
metadata:
name: my-new-cron-object
spec:
cronSpec: "* * * * */5"
image: my-awesome-cron-image
EOF
然后我们就可以用 kubectl 来管理我们这里创建 CronTab 对象了
[root@master ~]# kubectl get ct #ct是简写
NAME AGE
my-new-cron-object 14s
[root@master ~]# kubectl get crontab
NAME AGE
my-new-cron-object 34s
Kubernetes 中的 API 对象都叫做资源(Resource),就是 Yaml 里 Kind 字段所描述的东西。















 663
663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









