






文章目录
集合基本知识
什么是集合?
是一种容器,用来装数据对象的引用(非对象本身),类似数组,但长度可变
集合分类
大分类:单列集合和双列集合
| 单列集合 | 双列集合 | |
|---|---|---|
| 区别 | 一次添加一个元素 | 一次添加两个元素 |
| 成员 | ArrayList、LinkedList、TreeSet、HashSet、LinkedHashSet | TreeMap、HashMap、LinkedHashMap |
| 接口实现 | 实现Collection接口 | 实现Map接口 |
小分类:实现Collection接口和实现Map接口
实现Collection接口
| List接口 | Set接口 | |
|---|---|---|
| 成员 | ArrayList、LinkedList | TreeSet、HashSet、LinkedHashSet |
| 总体特点 | 存取有序、有索引、可以重复存储 | 存取无序、没有索引、不可以重复存储 |
| 底层结构 | ArrayList:数组 LinkedList:双向链表 | TreeSet:红黑树 HashSet:哈希表(数组+链表+红黑树) LinkedHashSet:哈希表+双向链表 |
实现Map接口
Set的底层实现是Map
| Map接口 | |
|---|---|
| 成员 | TreeMap、HashMap、LinkedHashMap |
| 总体特点 | 同Set接口 |
| 底层结构 | TreeMap:红黑树 HashMap:哈希表(数组+链表+红黑树) LinkedHashMap:哈希表+双向链表 |
集合的遍历方式
通用遍历方式
迭代器
package com.itheima.collection;
import com.itheima.domain.Student;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class CollectionTest2 {
public static void main(String[] args) {
Collection<Student> c = new ArrayList<>();
c.add(new Student("张三", 23));
c.add(new Student("李四", 24));
c.add(new Student("王五", 25));
// 1. 获取迭代器
Iterator<Student> it = c.iterator();
// 2. 循环判断, 集合中是否还有元素
while (it.hasNext()) {
// 3. 调用next方法, 将元素取出
Student stu = it.next();
System.out.println(stu.getName() + "---" + stu.getAge());
}
}
}
增强for循环
public class CollectionTest2 {
public static void main(String[] args) {
Collection<Student> c = new ArrayList<>();
c.add(new Student("张三", 23));
c.add(new Student("李四", 24));
c.add(new Student("王五", 25));
// 使用增强for循环遍历集合:内部还是迭代器,通过.class文件可以看出来
for (Student stu : c) {
System.out.println(stu);
}
}
}
forEach方法
public class CollectionTest2 {
public static void main(String[] args) {
Collection<Student> c = new ArrayList<>();
c.add(new Student("张三", 23));
c.add(new Student("李四", 24));
c.add(new Student("王五", 25));
// foreach方法遍历集合:匿名内部类
c.forEach(stu -> System.out.println(stu));
}
}
额外遍历方式【List集合】
普通for循环
public class ListDemo2 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("abc");
list.add("bbb");
list.add("ccc");
list.add("abc");
// 普通for循环
for (int i = 0; i < list.size(); i++) {
String s = list.get(i);
System.out.println(s);
}
}
}
ListIterator【List集合特有】
public class ListDemo2 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("abc");
list.add("bbb");
list.add("ccc");
list.add("abc");
ListIterator<String> it = list.listIterator();
while (it.hasNext()) {
String s = it.next();
System.out.println(s);
}
}
}
特点
- 先调用
hasPrevious会打印不出来数据 - 要想进行一次正向打印,一次反向打印:需要先调用
hasNext,再掉用hasPrevious
Iterator和ListIterator在遍历过程中添加、删除元素的区别
- 用任何迭代器,在遍历过程中,调用【集合对象】本身的添加、删除方法,会引发异常
- 用
Iterator普通迭代器,在遍历过程中:支持使用迭代器的删除操作,不支持其添加操作 - 用
ListIterator迭代器,在遍历过程中:支持使用迭代器的删除操作,也支持其添加操作- 删除操作:删除当前迭代到的数据
- 添加操作:添加数据到当前迭代到的数据后面
- 在一个迭代内,不支持即增加,又删除的操作
package com.itheima.collection.list;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.ListIterator;
public class ListDemo3 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("眼瞅着你不是真正的高兴");
list.add("温油");
list.add("离开俺们这旮表面");
list.add("伤心的人别扭秧歌");
list.add("私奔到东北");
ListIterator<String> it = list.listIterator();
while (it.hasNext()) {
String s = it.next();
if ("温油".equals(s)) {
it.add("哈哈"); // 迭代器的添加操作:没问题
it.remove(); // 迭代器的删除操作:没问题(但是和上边的添加操作放在一个迭代内,就报错了)
list.add("哈哈"); // 集合本身的添加操作:报错
list.remove("温油"); // 集合本身的删除操作:报错
}
}
System.out.println(list);
}
}
Collection接口
| List接口 | Set接口 | |
|---|---|---|
| 成员 | ArrayList、LinkedList | TreeSet、HashSet、LinkedHashSet |
| 总体特点 | 存取有序、有索引、可以重复存储 | 存取无序、没有索引、不可以重复存储 |
| 底层结构 | ArrayList:数组 LinkedList:双向链表 | TreeSet:红黑树 HashSet:哈希表(数组+链表+红黑树) LinkedHashSet:哈希表+双向链表 |
通用函数
Collection是所有单列集合的顶层接口
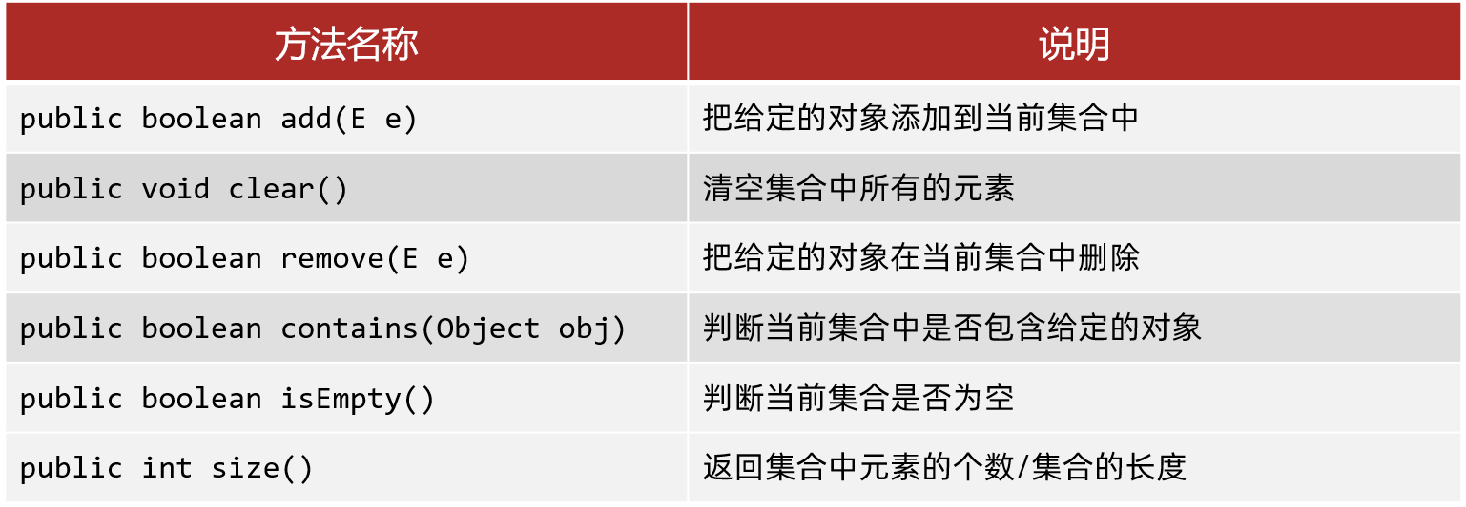
remove()、contains()两个函数依赖对象底层的equals()方法。若对象没有重写equals()方法,比较的是地址值,无法按照要求删除- 上述方法均以对象为参数,不以索引为参数(因为Collection接口里面的Set接口没有索引)
List接口-ArrayList
常用方法
| 函数 | 功能 |
|---|---|
public void add(int index, E element); | 在指定的索引位置, 添加元素 |
public E remove(int index); | 根据索引删除集合中的元素 |
public E set(int index, E element); | 根据索引修改集合中的元素 |
public E get(int index); | 返回指定索引处的元素 |
package com.itheima.collection.list;
import java.util.ArrayList;
import java.util.List;
public class ListDemo1 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张三");
list.add("李四");
list.add("王五");
list.set(0, "赵六");
list.remove(1); // 根据索引删除:List接口的特点
System.out.println(list.get(0));
System.out.println(list);
System.out.println("-------------------------");
List<Integer> list2 = new ArrayList<>();
list2.add(111); // Integer e = 111;
list2.add(222);
list2.add(333);
list2.remove(Integer.valueOf(222)); // 根据元素删除,需要这样写,以跟索引删除的方法区分开
System.out.println(list2);
}
}
-
根据索引删除元素:是List接口(子)的特点
-
根据元素删除元素:是Collection接口(父)的特点
ArrayList的长度可变原理
- 空参构造时,底层创建长度为0的数组【非空参构造,创建长度为10的数组】
- 添加元素
- 当还有空间的时候,可以继续添加
- 当数组存满时,会扩容1.5倍
List接口-LinkedList
常用方法
| 函数 | 功能 |
|---|---|
public void addFirst(E e); | 头部添加 |
public void addLast(E e) | 尾部添加 |
public E getFirst() | 获取第一个元素 |
public E getLast() | 获取最后一个元素 |
public E removeFirst() | 删除第一个元素 |
public E removeLast() | 删除最后一个元素 |
public E get(int index); | 返回指定索引处的元素 |
package com.itheima.collection.list;
import java.util.LinkedList;
public class LinkedListDemo {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
list.add("张三");
list.add("李四");
list.add("王五");
String s = list.get(1);
System.out.println(s);
}
private static void method2() {
LinkedList<String> list = new LinkedList<>();
list.add("张三");
list.add("李四");
list.add("王五");
list.add("赵六");
System.out.println(list.getFirst());
System.out.println(list.getLast());
list.removeFirst();
list.removeLast();
System.out.println(list);
}
private static void method1() {
LinkedList<String> list = new LinkedList<>();
list.addFirst("张三");
list.addFirst("李四");
list.addFirst("王五");
list.addLast("赵六");
// 王五 李四 张三 赵六
System.out.println(list);
}
}
LinkedList接口get(int index)方法实现原理
LinkedList底层是双向链表,其get方法的实现原理是:
-
将索引和集合长度比较
-
若靠近头部:从头找数据,一个一个找
-
若靠近尾部:从尾找数据,一个一个找
-
-
不同于ArrayList的查询(地址值+索引),LinkedList的存储内存不连续,是一个一个元素查找,速度慢
Set接口-TreeSet
排序规则1-自然排序
常见类排序(String):默认增序排序
package com.itheima.day10.set;
import java.util.TreeSet;
public class TreeSetDemo1 {
public static void main(String[] args) {
TreeSet<String> ts = new TreeSet<>();
ts.add("a");
ts.add("d");
ts.add("e");
ts.add("c");
ts.add("b");
ts.add("b");
ts.add("b");
ts.add("b");
ts.add("b");
System.out.println(ts); // [a, b, c, d, e]
}
}
自定义类排序
-
类实现Comparable接口
-
重写compareTo方法
-
根据返回值,组织排序规则
-
返回负数:往树左边存储
-
返回正数:往树右边存储
-
返回0:不存(对于根节点除外,即第一个元素除外)
-
// Student类
package com.itheima.day10.domain;
@Data
public class Student implements Comparable<Student>{
// this.xxx - o.xxx 增序
// o.xxx - this.xxx 降序
@Override
public int compareTo(Student o) {
System.out.println(this.getAge() + "+" + this.name + "---" + o.age + "+" + o.name);
// 根据年龄做主要排序条件
int ageResult = o.age - this.age;
// 根据姓名做次要排序条件
int nameResult = ageResult == 0 ? o.name.compareTo(this.name) : ageResult;
// 判断姓名是否相同
int result = nameResult == 0 ? 1 : nameResult;
return result;
}
private String name;
private int age;
public String toString() {
return "Student{name = " + name + ", age = " + age + "}";
}
}
public class TreeSetDemo2 {
public static void main(String[] args) {
TreeSet<Student> ts = new TreeSet<>();
ts.add(new Student("A", 23));
ts.add(new Student("B", 26));
ts.add(new Student("C", 27));
ts.add(new Student("D", 20));
// [Student{name = C, age = 27}, Student{name = B, age = 26}, Student{name = A, age = 23}, Student{name = D, age = 20}]
System.out.println(ts);
}
}
比较过程的输出结果:
23+A—23+A
26+B—23+A
27+C—23+A
27+C—26+B
20+D—26+B
20+D—23+A可以看出:新增加的元素,是作为
this,与树里面的元素一个一个比较
排序规则2-比较器排序
-
在 TreeSet 的构造方法中, 传入 Compartor 接口的实现类对象
-
重写 compare 方法
-
根据方法的返回值, 来组织排序规则
-
负数 : 左边走
-
正数 : 右边走
-
0 : 不存
-
-
该接口也是函数式接口,可以写为Lambda表达式
package com.itheima.day10.set;
import com.itheima.day10.domain.Student;
import java.util.Comparator;
import java.util.TreeSet;
public class TreeSetDemo3 {
public static void main(String[] args) {
TreeSet<Student> ts = new TreeSet<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
int ageResult = o1.getAge() - o2.getAge();
return ageResult == 0 ? o1.getName().compareTo(o2.getName()) : ageResult;
}
});
ts.add(new Student("赵六", 26));
ts.add(new Student("李四", 24));
ts.add(new Student("张三", 23));
ts.add(new Student("王五", 25));
// [Student{name = 张三, age = 23}, Student{name = 李四, age = 24}, Student{name = 王五, age = 25}, Student{name = 赵六, age = 26}]
System.out.println(ts);
}
}
两种排序规则优先级
如果同时具备比较器排序和自然排序,会优先按照比较器的规则,进行排序操作
- 有些类给出默认的排序规则(即自然排序),不好重写其底层代码,就自定义比较器排序规则
Set接口-HashSet
底层实现原理的变迁
| JDK7及以前 | JDK8及以后 |
|---|---|
| 数组+链表 | 数组+链表+红黑树 |
JDK7版本的数据存储过程
存入的数据要求
-
每个数据的存储都需要进行比较,根据比较结果来判断是否存
-
需要重写存入对象的hashCode方法、equals方法
存储过程
- 创建一个默认长度16的数组,数组名table
- 根据元素的哈希值跟数组的长度求余计算出应存入的位置(调用hashCode方法)
- 判断当前位置是否为null
- 如果是null直接存入
- 如果位置不为null,表示有元素,则调用equals方法比较
- 如果一样,则不存
- 如果不一样,则存入数组
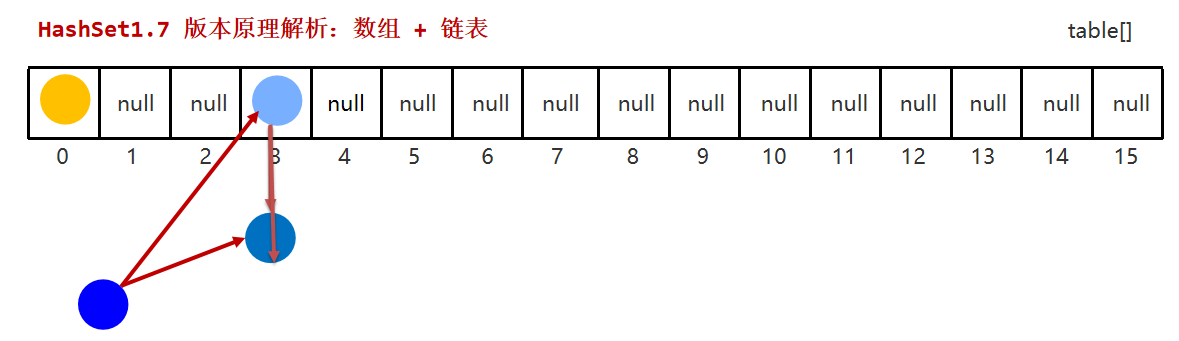
JDK 7:新元素占老元素位置,指向老元素 (头插法)
JDK 8:新元素挂在老元素下面(尾插法)
底层数组扩容的条件
- 条件1:数组存满到16*0.75(加载因子)=12时,就自动扩容,每次扩容为原先的两倍
- 条件2:链表挂载元素超过了8个 (阈值) ,但数组长度没有到达64
底层链表转红黑树的条件
- 链表挂载元素超过了8个 (阈值),且数组长度到达64
HashSet特点
-
底层是哈希表存储数据,对增删改查数据性能都比较好
-
存储的数据具有唯一性
-
不对数据进行排序
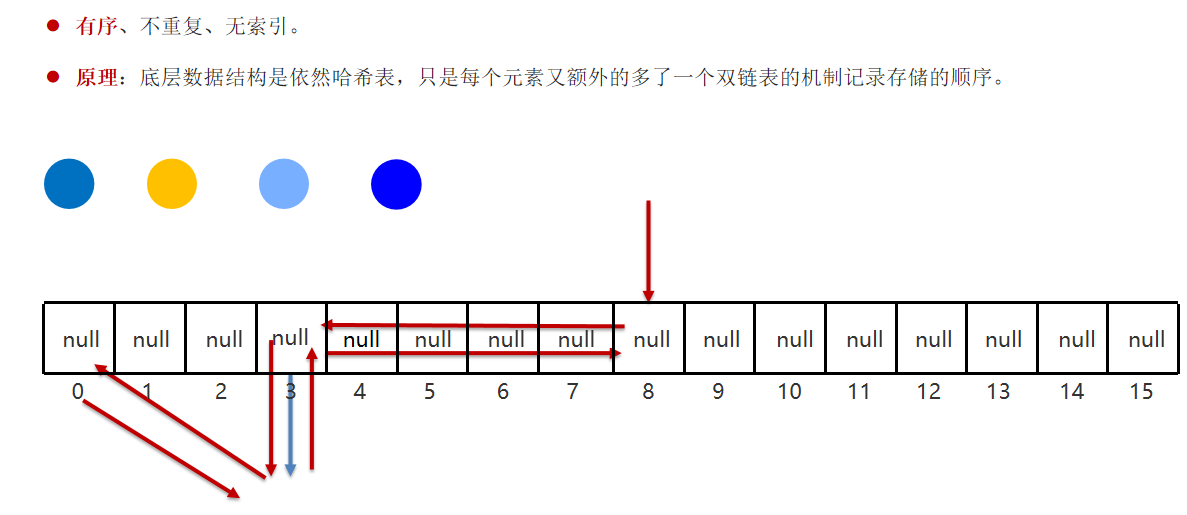
Set接口-LinkedHashSet
总结
类型选用
| Case | Choice |
|---|---|
| 如果想要集合中的元素可重复 | ArrayList |
| 如果想要集合中的元素可重复,而且当前的增删操作明显多于查询 | LinkedList |
| 如果想对集合中的元素去重 | HashSet |
| 如果想对集合中的元素去重,而且保证存取顺序 | LinkedHashSet |
| 如果想对集合中的元素进行排序 | TreeSet |
Collections工具类

package com.itheima.day11.tools;
import com.itheima.day11.domain.Student;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
public class CollectionsDemo {
public static void main(String[] args) {
// 批量添加
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "a", "b", "c", "d");
System.out.println(list);
// 二分查找 (前提: 必须是排好序的数据)
System.out.println(Collections.binarySearch(list, "b"));
// 洗牌
Collections.shuffle(list);
System.out.println(list);
ArrayList<Student> nums = new ArrayList<>();
Collections.addAll(nums, new Student("张三", 23), new Student("王五", 25), new Student("李四", 24));
// 从集合中找最值
System.out.println(Collections.max(nums));
System.out.println(Collections.min(nums));
// 对集合中的元素进行交换
Collections.swap(nums, 0, 2);
System.out.println(nums);
// sort : 对集合进行排序
ArrayList<Integer> box = new ArrayList<>();
Collections.addAll(box, 1, 3, 5, 2, 4);
Collections.sort(box, (o1, o2) -> o2 - o1);
System.out.println(box);
}
}
Map接口
| Map接口 | |
|---|---|
| 成员 | TreeMap、HashMap、LinkedHashMap |
| 总体特点 | 同Set接口 |
| 底层结构 | TreeMap:红黑树 HashMap:哈希表(数组+链表+红黑树) LinkedHashMap:哈希表+双向链表 |
基础介绍
Map是双列集合,每个元素包含两个数据
Map元素格式:key=value
-
key:不允许重复
-
value:允许重复
-
key-value一一对应
-
key-value整体,称为【键值对】或【键值对对象】,用Entry表示
Map接口下的集合类别:TreeMap、HashMap、LinkedHashMap
通用函数
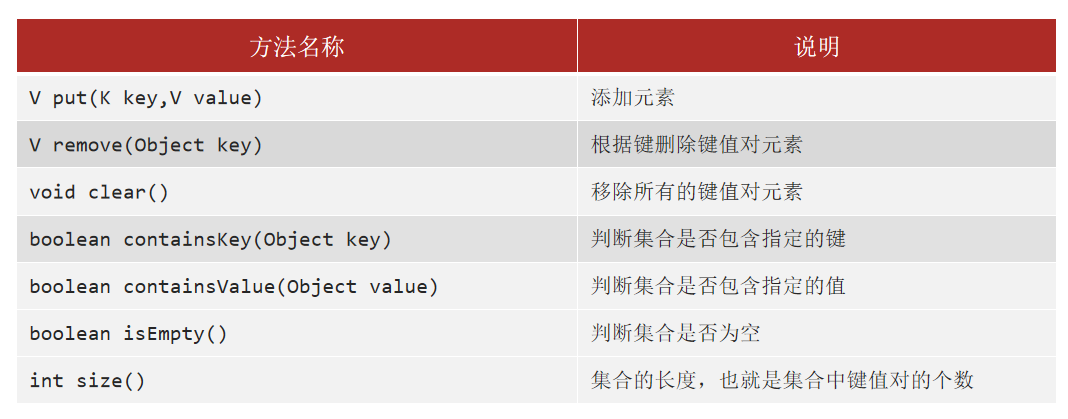
Map是双列集合的顶层接口
底层原理了解
TreeMap底层原理
底层数据结构是红黑树,是一种特殊的二叉树,满足二叉树的所有性质,又具备自己的红黑规则
节点存储内容有:父节点地址、左右子节点地址、红黑颜色、元素的Key及Value
数据的存储过程按照键来进行排序,存储过程完全遵守红黑树的存储规则
HashMap底层原理

用键值对中的键来计算哈希值,该步骤与值无关
后续原理同HashSet,只不过每个节点中存储的数据是一个Entry对象
遍历方式
增强For循环
增强for循环,也即迭代器的方式遍历
map.keySet() + map.get(key):获取map集合的所有键,并用增强for遍历所有键,然后用get方法获取每一个键对应的值map.values():获取map集合的所有值,进行遍历map.entrySet() + entry.getKey() + entry.getValue():获取map集合的Entry对象,每个对象里面包含键和值
通过forEach方法遍历
map.forEach:直接获取每一个集合对象的键和值,进行遍历操作
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class MapTest {
public static void main(String[] args) {
HashMap<Integer, String> testMap = new HashMap<>();
testMap.put(1, "One");
testMap.put(2, "Two");
testMap.put(3, "Three");
testMap.put(4, "Four");
testMap.put(5, "Five");
// 增强for:第一种
for (Integer key : testMap.keySet()) {
System.out.print(key + "-" + testMap.get(key) + "\t");
}
System.out.println("\nforeach keySet");
// 增强for:第二种
for (String value : testMap.values()) {
System.out.print(value + "\t");
}
System.out.println("\nforeach values");
// 增强for:第三种
for (Map.Entry<Integer, String> entry : testMap.entrySet()) {
System.out.print(entry.getKey() + "-" + entry.getValue() + "\t");
}
System.out.println("\nforeach entrySet");
// 增强for:第三种(迭代器形式,上述第三种本质也是迭代器方式,但是书写更简单)
Iterator<Map.Entry<Integer, String>> it = testMap.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<Integer, String> entry = it.next();
System.out.print(entry.getKey() + "-" + entry.getValue() + "\t");
}
System.out.println("\nentrySet iterator");
// foreach:Map的forEach方法,Java8独有
testMap.forEach((key, value) -> {
System.out.print(key + "-" + value + "\t");
});
System.out.println("\nMap.forEach()");
}
}
运行结果:
1-One 2-Two 3-Three 4-Four 5-Five
foreach keySet
One Two Three Four Five
foreach values
1-One 2-Two 3-Three 4-Four 5-Five
foreach entrySet
1-One 2-Two 3-Three 4-Four 5-Five
entrySet iterator
1-One 2-Two 3-Three 4-Four 5-Five
Map.forEach()
Map集合选用
| Case | Choice |
|---|---|
| 如果想根据集合中的键进行去重 | HashMap |
| 如果想根据键对集合中的元素去重,而且保证存取顺序 | LinkedHashMap |
| 如果想根据集合中的键进行排序 | TreeMap |















 15万+
15万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









