







在后台回复【阅读书籍】
即可获取python相关电子书~
Hi,我是山月。
之前给大家介绍了python处理excel、word、ppt的相关教程,不知道大家学的怎么样?
在后台回复【自动化办公】即可查看全部自动化办公教程哦~
今天来给大家介绍下python处理pdf文档的一个库--PyPDF2。
PyPDF2 是源自 pyPdf 项目的纯 Python PDF 工具包。它擅长处理PDF文档本身,比如对 PDF 文档进行分割、 合并、 插入等操作。
官网:https://pythonhosted.org/PyPDF2/index.html
安装:pip install pypdf2
01
基础知识
PyPDF2 一共有4大主模块:PdfFileReader、PdfFileWriter、PdfFileMerger、PageObject,分别是读、写、合并、页面对象。
1、PdfFileReader
1、导入
from PyPDF2 import PdfFileReader2、获取 PdfFileReader 对象
PdfFileReader(stream, strict=True, warndest=None, overwriteWarnings=True)
参数:
stream : 一个 File 对象或支持类似于 File 对象的标准读取和查找方法的对象。也可以是表示 PDF 文件路径的字符串。
strict (bool) : 确定是否应该警告用户所有的问题,也会导致一些可纠正的问题是致命的。默认值为True。
warndest : 记录警告的目标(默认为 sys.stderr)。
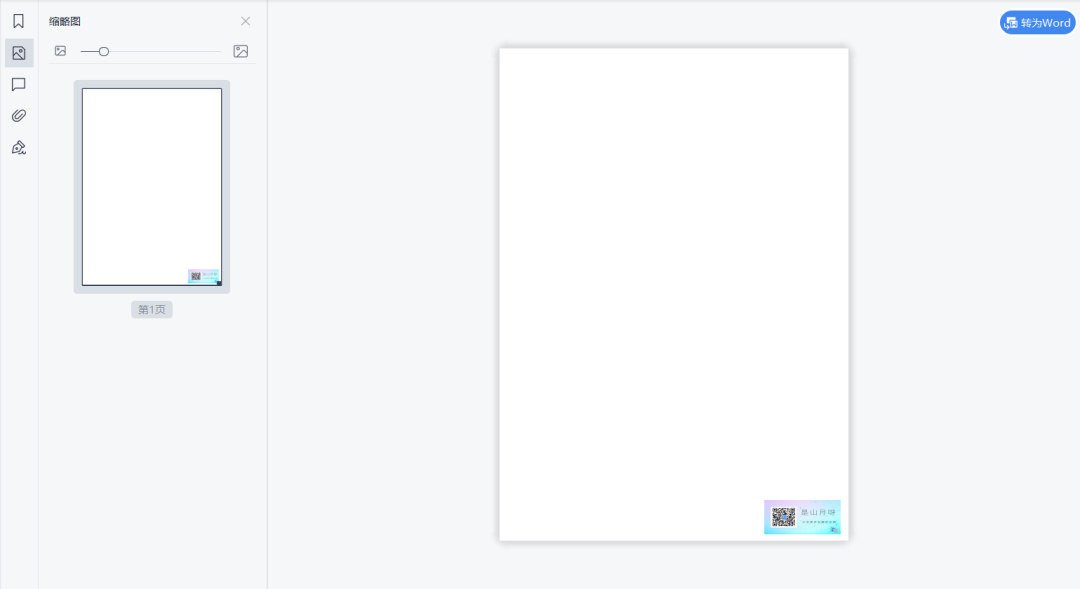
overwriteWarnings (bool) :确定是否使用自定义实现覆盖 Python 的 warnings.py 模块(默认为 True)。比如想读取将进酒.pdf内容:
pdfFileReader = PdfFileReader(open('将进酒.pdf', 'rb')) # 获取PdfileReader对象
# 也可以:pdfFileReader = PdfFileReader('将进酒.pdf')3、一些方法与属性
4、实例
现在有一个2页的将进酒.pdf文件:
from PyPDF2 import PdfFileReader
pdfFileReader = PdfFileReader(open('将进酒.pdf', 'rb'))
documentInfo = pdfFileReader.documentInfo
print(documentInfo) # 检索文档信息
'''
{'/Author': '是山月呀', '/Comments': '', '/Company': '', '/CreationDate': "D:20220312161040+08'10'",
'/Creator': 'WPS 文字', '/Keywords': '', '/ModDate': "D:20220314130926+08'00'", '/Producer': '',
'/SourceModified': "D:20220312161040+08'10'", '/Subject': '', '/Title': '', '/Trapped': '/False'}
'''
print(documentInfo.author) # 检索文档的作者--->> 是山月呀
pages = pdfFileReader.numPages #计算文件的页数
print(pages) # --->> 2
page = pdfFileReader.getPage(1) #检索第2页页面
print(page)
'''
{'/Type': '/Page', '/Parent': IndirectObject(2, 0), '/MediaBox': [0, 0, 595.276, 841.89], '/Rotate': 0,
'/Resources': {'/Font': {'/KSPF1': IndirectObject(29, 0), '/KSPF2': IndirectObject(31, 0)}}, '/Contents': IndirectObject(33, 0)}
'''
pageLayout = pdfFileReader.pageLayout # 获取页面布局
print(pageLayout) # --->> None
is_Encrypted = pdfFileReader.isEncrypted # 判断是否加密
print(is_Encrypted) # --->> False2、PdfFileWriter
1、导入
from PyPDF2 import PdfFileWriter2、初始化PdfFileReader 对象
PdfFileWriter = PdfFileWriter()3、一些方法与属性
1、文件写入
write(stream)
参数:
stream:要将文件写入的对象。2、添加页面
addPage(page)
参数:
page:要添加到文档的页面,应该是 PageObject 的一个实例3、添加空白页
addBlankPage(width=None, height=None)
参数:
width (float) – 页面的宽度。
height (float) –页面的高度。
如果未指定页面大小,则使用最后一页的大小。
如果未指定页面大小并且上一页不存在,则会引发PageSizeNotDefinedError。4、添加书签
addBookmark(title, pagenum, parent=None, color=None, bold=False, italic=False, fit='/Fit', *args)
参数:
title (str): 用于此书签的标题。
pagenum (int) :此书签将指向的页码。
parent :对父书签的引用以创建嵌套书签。
color (tuple) : 书签的颜色为从 0.0 到 1.0 的红、绿、蓝元组
bold (bool):书签为粗体
italic (bool) :书签是斜体
fit (str) : 目标页面的适合度。5、写入读取的文档
appendPagesFromReader(reader, after_page_append=None)
参数:
reader: 一个 PdfFileReader 对象
after_page_append (function):调用的回调函数6、加密
encrypt(user_pwd, owner_pwd=None, use_128bit=True)
参数:
user_pwd (str) : “用户密码”,允许在提供的限制下打开和阅读 PDF 文件。
owner_pwd (str) : “所有者密码”,允许不受任何限制地打开 PDF 文件。默认情况下,所有者密码与用户密码相同。
use_128bit (bool) : 标记是否使用 128 位加密,默认为True。为 false 时,将使用 40 位加密。7、插入空白页
insertBlankPage(width=None, height=None, index=0)
参数:
width (float) :页面的宽度。
height (float) :页面的高度。
index (int) :添加页面的位置。
如果未指定页面大小,则使用最后一页的大小。
如果未指定页面大小并且上一页不存在,则会引发 PageSizeNotDefinedError8、插入页面
insertPage(page, index=0)
参数:
page (PageObject): 要添加到文档的页面,该参数是 PageObject 的一个实例。
index (int) :将插入页面的位置。9、获取页数
getNumPages()10、按页码检索页面
getPage(pageNumber)
参数:
pageNumber (int) :要检索的页码(从0开始)11、设置页面布局
setPageLayout(layout)
参数:
layout (str):要使用的页面布局。但是设置了没有发生作用。
可设置的布局有:
/NoLayout: 未指定布局
/SinglePage: 一次显示一页
/OneColumn: 一次显示一列
/TwoColumnLeft: 分两列显示页面,奇数页在左边
/TwoColumnRight: 分两列显示页面,奇数页在右边
/TwoPageLeft: 一次显示两页,奇数页在左边
/TwoPageRight: 一次显示两页,奇数页在右边12、获取页面布局
getPageLayout()
# 也可以:
pageLayout13、设置页面模式
setPageMode(mode)
参数:
mode (str) :要使用的页面模式。但是设置了没有发生作用。
可设置的页面模式有:
/UseNone: 不显示面板
/UseOutlines: 查看文档书签
/UseThumbs: 查看文档缩略图
/UseAttachments: 查看文件附件
/FullScreen: 全屏视图
/UseOC: 显示可选内容组 (OCG)14、获取页面模式
getPageMode()
# 也可以:
pageMode15、删除图像
removeImages(ignoreByteStringObject=False)
参数:
ignoreByteStringObject (bool) :忽略 ByteString 对象的可选参数。16、删除文字
removeText(ignoreByteStringObject=False)
参数:
ignoreByteStringObject (bool) :忽略 ByteString 对象的可选参数。17、删除链接和注释
removeLinks()3、PdfFileMerger
1、导入
from PyPDF2 import PdfFileMerger2、获取PdfFileMerger 对象
PdfFileMerger(strict=True)
参数:
strict (bool) – 确定是否应该警告用户所有的问题,也会导致一些可纠正的问题是致命的。默认值为True。3、一些方法与属性
1、合并
merge(position, fileobj, bookmark=None, pages=None, import_bookmarks=True)
参数:
position (int):插入此文件的页码,文件将在给定编号之后插入。
fileobj:文件对象或支持类似于文件对象的标准读取和查找方法的对象,也可以是表示 PDF 文件路径的字符串。
bookmark (str):可以通过提供书签的文本来指定要在包含文件的开头应用的书签。
pages : 指定要合并的的页面范围,可以是Range 或 (start, stop[, step]) 元组
import_bookmarks (bool) : 可以通过将其指定为 False 来阻止导入源文档的书签。2、附加
append(fileobj, bookmark=None, pages=None, import_bookmarks=True)
参数:
fileobj:文件对象或支持类似于文件对象的标准读取和查找方法的对象,也可以是表示 PDF 文件路径的字符串。
bookmark (str):可以通过提供书签的文本来指定要在包含文件的开头应用的书签。
pages : 指定要合并的的页面范围,可以是Range 或 (start, stop[, step]) 元组
import_bookmarks (bool) : 可以通过将其指定为 False 来阻止导入源文档的书签。3、添加书签
addBookmark(title, pagenum, parent=None)
参数:
title (str) : 用于此书签的标题。
pagenum (int): 此书签将指向的页码。
parent:对父书签的引用以创建嵌套书签。4、文件写入
write(fileobj)
参数:
fileobj : 输出文件。可以是文件名或任何类型的类似文件的对象。5、设置页面布局
setPageLayout(layout)
参数:
layout (str) : 要使用的页面布局6、设置页面模式
setPageMode(mode)
参数:
mode (str): 要使用的页面模式。4、PageObject
页面对象一般是通过访问 PdfFileReader 的 getPage() 方法创建的。
1、几个页面大小属性
1、artBox
一个 RectangleObject,以默认用户空间单位表示,定义页面创建者所期望的页面有意义内容的范围。
2、bleedBox
一个 RectangleObject,以默认用户空间单位表示,定义在生产环境中输出时页面内容应剪切到的区域。
3、cropBox
一个 RectangleObject,以默认用户空间单位表示,定义默认用户空间的可见区域。
当页面被显示或打印时,其内容将被剪裁(裁剪)到这个矩形,然后以某种实现定义的方式施加到输出介质上。
默认值:与 mediaBox 相同。
4、mediaBox
一个 RectangleObject,以默认用户空间单位表示,定义了要在其上显示或打印页面的物理介质的边界。
5、trimBox
一个 RectangleObject,以默认用户空间单位表示,定义修剪后完成页面的预期尺寸。
2、合并页面
1、合并页面
mergePage(page2)
参数:
page2 (PageObject):要合并到此页面的页面,是 PageObject 的一个实例。2、合并旋转页面
mergeRotatedPage(page2, rotation, expand=False)
参数:
page2 (PageObject) :要合并到此页面的页面,是 PageObject 的一个实例。
rotation (float) :旋转的角度,以度为单位
expand (bool) :是否应扩展页面以适应要合并的页面的尺寸。3、合并旋转缩放页面
mergeRotatedScaledPage(page2, rotation, scale, expand=False)
参数:
page2 (PageObject): 要合并到此页面的页面,是 PageObject 的一个实例。
rotation (float): 旋转的角度,以度为单位
scale (float): 比例因子
expand (bool) :是否应扩展页面以适应要合并的页面的尺寸。4、合并旋转缩放平移页面
mergeRotatedScaledTranslatedPage(page2, rotation, scale, tx, ty, expand=False)
参数:
page2 (PageObject) : 要合并到此页面的页面,是 PageObject 的一个实例。
tx (float) :X轴平移
ty (float) :Y轴平移
rotation (float) :旋转的角度,以度为单位
scale (float) : 比例因子
expand (bool) :是否应扩展页面以适应要合并的页面的尺寸。5、合并旋转平移页面
mergeRotatedTranslatedPage(page2, rotation, tx, ty, expand=False)
参数:
page2 (PageObject): 要合并到此页面的页面,是 PageObject 的一个实例。
tx (float) :X轴平移
ty (float) :Y轴平移
rotation (float) :旋转的角度,以度为单位
expand (bool) : 是否应扩展页面以适应要合并的页面的尺寸。6、合并缩放页面
mergeScaledPage(page2, scale, expand=False)
参数:
page2 (PageObject) :要合并到此页面的页面,是 PageObject 的一个实例。
scale (float) :比例因子
expand (bool) :是否应扩展页面以适应要合并的页面的尺寸。7、合并缩放平移页面
mergeScaledTranslatedPage(page2, scale, tx, ty, expand=False)
参数:
page2 (PageObject) : 要合并到此页面的页面,是 PageObject 的一个实例。
scale (float) :比例因子
tx (float) :X轴平移
ty (float) :Y轴平移
expand (bool) : 是否应扩展页面以适应要合并的页面的尺寸。8、合并转换页面
mergeTransformedPage(page2, ctm, expand=False)
参数:
page2 (PageObject): 要合并到此页面的页面,是 PageObject 的一个实例。
ctm (tuple):包含转换矩阵操作的6元元组
expand (bool) :是否应扩展页面以适应要合并的页面的尺寸。9、合并平移页面
mergeTranslatedPage(page2, tx, ty, expand=False)
参数:
page2 (PageObject) :要合并到此页面的页面,是 PageObject 的一个实例。
tx (float) :X轴平移
ty (float) :Y轴平移
expand (bool) :是否应扩展页面以适应要合并的页面的尺寸。3、旋转
1、顺时针旋转
rotateClockwise(angle)
参数:
angle (int) : 旋转页面的角度,必须是 90 度的增量。2、逆时针旋转
rotateCounterClockwise(angle)
参数:
angle (int):旋转页面的角度,必须是 90 度的增量。4、缩放
1、x、y轴分别缩放
scale(sx, sy)
参数:
sx (float):水平轴上的比例因子。
sy (float) : 垂直轴上的比例因子。2、x、y轴同时缩放
scaleBy(factor)
参数:
factor (float): 比例因子(对于 X 和 Y 轴)。3、缩放到指定尺寸
scaleTo(width, height)
参数:
width (float):新的宽度
height (float): 新的高度02
实例
1、添加水印
有一个将进酒.pdf文件:

现在要给它加上水印,要如何实现呢?
1、文字水印
新建一个pdf水印文件,里面是要加的水印文字,如:

代码实现:
from PyPDF2 import PdfFileReader, PdfFileWriter # 导入读、写模块
PdfFileWriter = PdfFileWriter() # 获取PdfFileWriter对象
pdf_file = PdfFileReader(open('将进酒.pdf', 'rb')) # 要添加水印的文档
num_pages = pdf_file.getNumPages() # 获取pdf文件的页数
for i in range(num_pages):
first_page = pdf_file.getPage(i) # 获取文件的第i+1页
text_watermark = PdfFileReader(open('文字.pdf', 'rb')) # 文字水印文档
page_watermark = text_watermark.getPage(0) # 获取pdf文件第1页页面
page_watermark.mergePage(first_page) # 合并两个页面
PdfFileWriter.addPage(page_watermark) # 把合并后的页面写入pdf文件
PdfFileWriter.write(open('实例.pdf', 'wb')) # 保存pdf文件效果:

2、图片水印
添加图片水印与添加文字水印是一样的操作。
新建一个图片水印文件:
然后把代码里的文字水印文件改成图片水印文件:
from PyPDF2 import PdfFileReader, PdfFileWriter # 导入读、写模块
PdfFileWriter = PdfFileWriter() # 获取PdfFileWriter对象
pdf_file = PdfFileReader(open('将进酒.pdf', 'rb')) # 要添加水印的文档
num_pages = pdf_file.getNumPages() # 获取pdf文件的页数
for i in range(num_pages):
first_page = pdf_file.getPage(i) # 获取文件的第i+1页
text_watermark = PdfFileReader(open('图片.pdf', 'rb')) # 图片水印文档
page_watermark = text_watermark.getPage(0) # 获取pdf文件第1页页面
page_watermark.mergePage(first_page) # 合并两个页面
PdfFileWriter.addPage(page_watermark) # 把合并后的页面写入pdf文件
PdfFileWriter.write(open('实例.pdf', 'wb')) # 保存pdf文件效果:
2、PDF合并
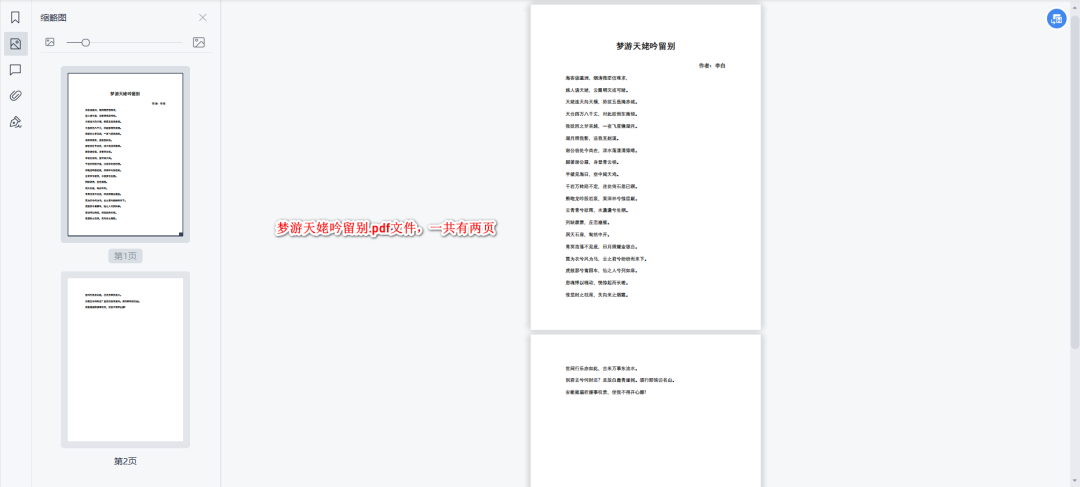
现在有两个pdf文件:将进酒.pdf、梦游天姥吟留别.pdf。

合并两个文档的代码实现:
from PyPDF2 import PdfFileMerger
PdfFileMerger = PdfFileMerger()
PdfFileMerger.append('将进酒.pdf') # 附加将进酒.pdf内容
PdfFileMerger.append('梦游天姥吟留别.pdf') # 附加梦游天姥吟留别.pdf内容
PdfFileMerger.write(open('实例.pdf', 'wb'))效果:
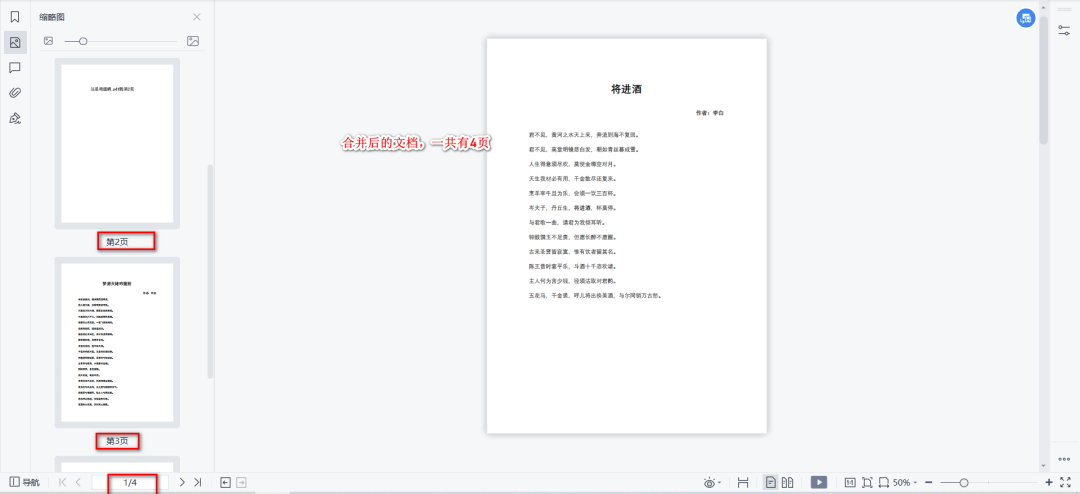
3、PDF插入
以我们刚刚的两个文件:将进酒.pdf、梦游天姥吟留别.pdf为例。
假如我们现在需要,在将进酒.pdf第一页的后面插入梦游天姥吟留别.pdf的文档内容,要如何实现呢?
代码实现:
from PyPDF2 import PdfFileMerger
PdfFileMerger = PdfFileMerger()
PdfFileMerger.merge(0, '将进酒.pdf')
PdfFileMerger.merge(1, '梦游天姥吟留别.pdf')
PdfFileMerger.write(open('实例.pdf', 'wb'))效果:

4、PDF分割
假设我们现在有这样一个文件:数据.pdf,它一共有6页:
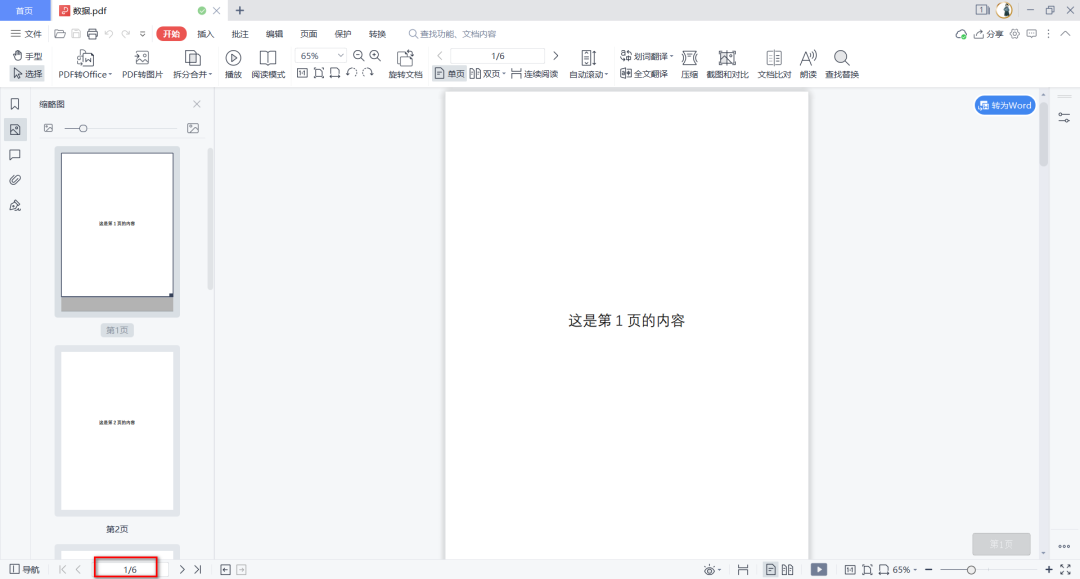
现在我们把它两页两页的分割成一个文档,也就是一共分成三个文档。
代码实现:
from PyPDF2 import PdfFileReader,PdfFileWriter
pdfFileReader = PdfFileReader('数据.pdf') # 获取 PdfFileReader 对象
num_pages = pdfFileReader.getNumPages() # 获取页数
for i in range(0,num_pages,2):
pdfFileWriter = PdfFileWriter()
page_Obj = pdfFileReader.getPage(i) # 获取第i+1页页面
pdfFileWriter.addPage(page_Obj) # 添加读取的第i+1页页面
page_Obj = pdfFileReader.getPage(i+1) # 获取第i+2页页面
pdfFileWriter.addPage(page_Obj) # 添加读取的第i+2页页面
outfile = '第%s页--第%s页.pdf'%(i+1,i+2)
pdfFileWriter.write(open(outfile, 'wb'))效果:

5、PDF删除页面
一样的,我们以数据.pdf文件为例,现在我们来删除第3页的内容。
代码实现:
from PyPDF2 import PdfFileReader,PdfFileWriter
pdfFileReader = PdfFileReader('数据.pdf') # 获取 PdfFileReader 对象
num_pages = pdfFileReader.getNumPages() # 获取页数
pdfFileWriter = PdfFileWriter()
for i in range(num_pages):
if i != 2:
page_Obj = pdfFileReader.getPage(i) # 获取第i+1页页面
pdfFileWriter.addPage(page_Obj) # 添加读取的第i+1页页面
outfile = '实例.pdf'
pdfFileWriter.write(open(outfile, 'wb'))效果:
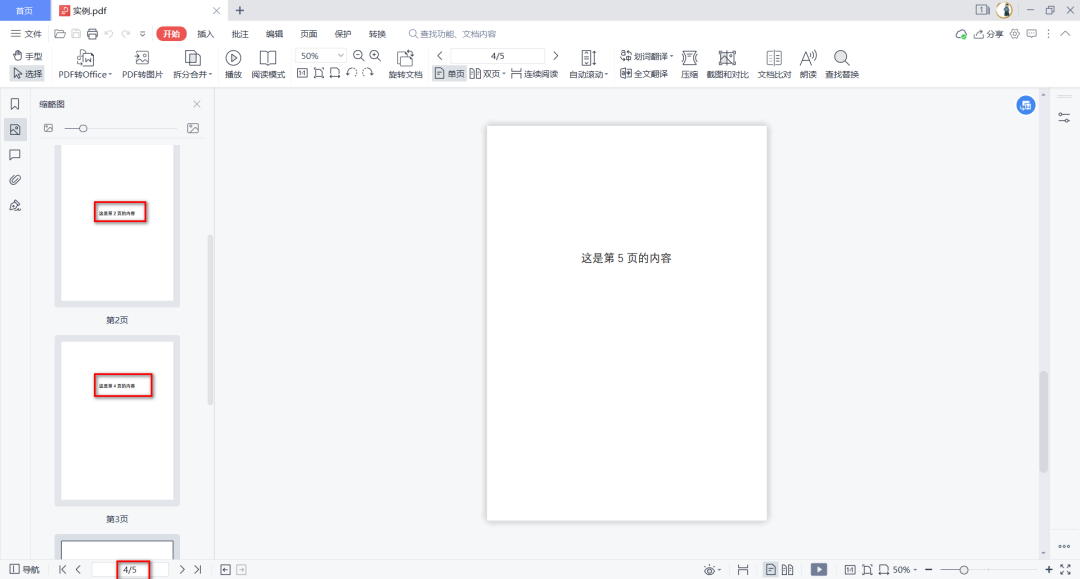
6、PDF提取页面
一样的,我们以数据.pdf文件为例,现在我们来提取第3页的内容,并另存为一个新文件。
代码:
from PyPDF2 import PdfFileReader,PdfFileWriter
pdfFileReader = PdfFileReader('数据.pdf') # 获取 PdfFileReader 对象
num_pages = pdfFileReader.getNumPages() # 获取页数
pdfFileWriter = PdfFileWriter()
for i in range(num_pages):
if i == 2:
page_Obj = pdfFileReader.getPage(i) # 获取第i+1页页面
pdfFileWriter.addPage(page_Obj) # 添加读取的第i+1页页面
outfile = '实例.pdf'
pdfFileWriter.write(open(outfile, 'wb'))效果:
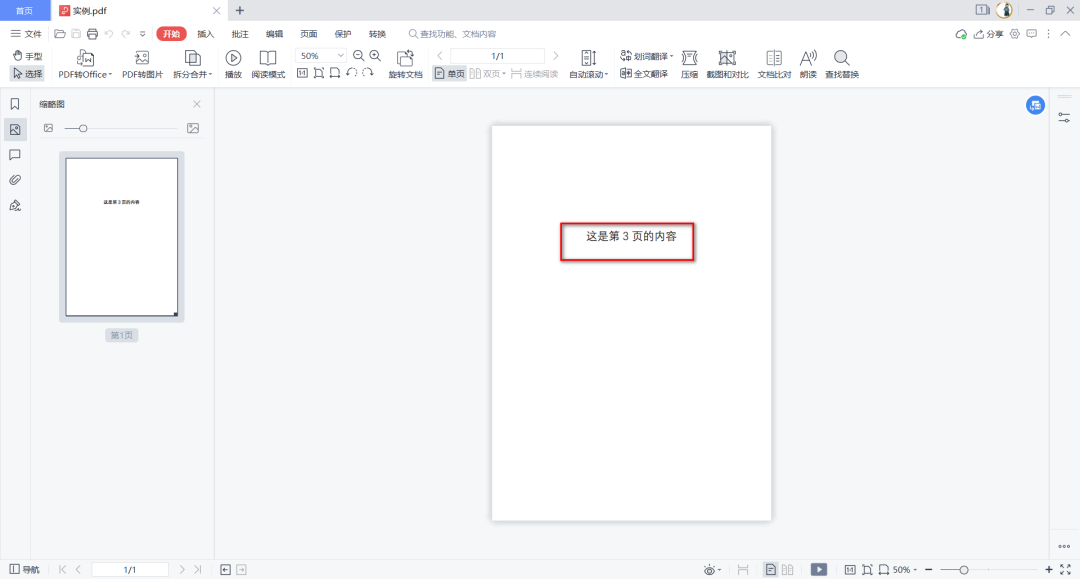
7、PDF旋转页面
我们把将进酒.pdf文档顺时针旋转90°。
代码:
from PyPDF2 import PdfFileReader,PdfFileWriter
pdfFileReader = PdfFileReader('将进酒.pdf') # 获取 PdfFileReader 对象
num_pages = pdfFileReader.getNumPages() # 获取页数
pdfFileWriter = PdfFileWriter()
for i in range(num_pages):
page_Obj = pdfFileReader.getPage(i) # 获取第i+1页页面
page_Obj.rotateClockwise(90) # 顺时针旋转90°
pdfFileWriter.addPage(page_Obj) # 添加读取的第i+1页页面
outfile = '实例.pdf'
pdfFileWriter.write(open(outfile, 'wb'))效果:
8、PDF拼接页面
我们以数据.pdf为例,假设我们现在需要把前4页的页面,拼接到一个页面上去,如何实现呢?
代码实现:
from PyPDF2 import PdfFileReader, PdfFileWriter
PdfFileWriter = PdfFileWriter()
pdfFileReader = PdfFileReader(open('数据.pdf', 'rb'))
page_1 = pdfFileReader.getPage(0) # 获取第1页页面
page_1.scaleTo(100, 150) # 页面缩放至宽100,高150
page_2 = pdfFileReader.getPage(1) # 获取第2页页面
page_2.scaleTo(100, 150) # 页面缩放至宽100,高150
page_3 = pdfFileReader.getPage(2) # 获取第3页页面
page_3.scaleTo(100, 150) # 页面缩放至宽100,高150
page_4 = pdfFileReader.getPage(3) # 获取第4页页面
page_4.scaleTo(100, 150) # 页面缩放至宽100,高150
page_1.mergeTranslatedPage(page_2, 100, 0, expand=True) # 拼接页面
page_1.mergeTranslatedPage(page_3, 0, -150, expand=True) # 拼接页面
page_1.mergeTranslatedPage(page_4, 100, -150, expand=True) # 拼接页面
PdfFileWriter.addPage(page_1)
PdfFileWriter.write(open('实例.pdf', 'wb'))效果:

9、PDF加密解密
1、加密
from PyPDF2 import PdfFileReader,PdfFileWriter
pdfFileReader = PdfFileReader('将进酒.pdf') # 获取 PdfFileReader 对象
num_pages = pdfFileReader.getNumPages() # 获取页数
pdfFileWriter = PdfFileWriter()
for i in range(num_pages):
page_Obj = pdfFileReader.getPage(i) # 获取第i+页页面
pdfFileWriter.addPage(page_Obj) # 添加读取的第i+1页页面
pdfFileWriter.encrypt('123456') # 加密
outfile = '实例.pdf'
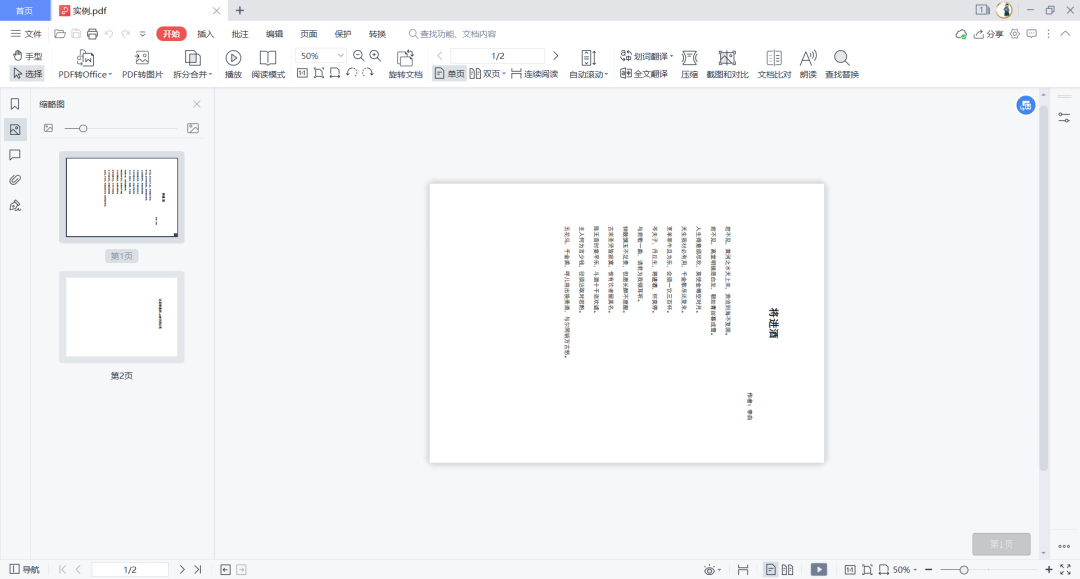
pdfFileWriter.write(open(outfile, 'wb'))效果:
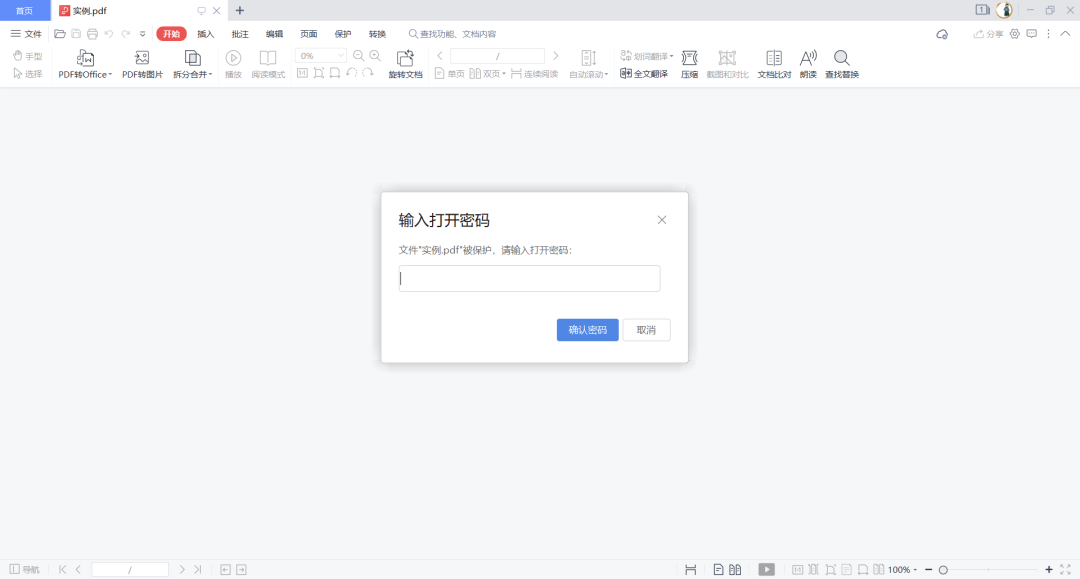
如果这个时候我们操作文件的话,会报错:
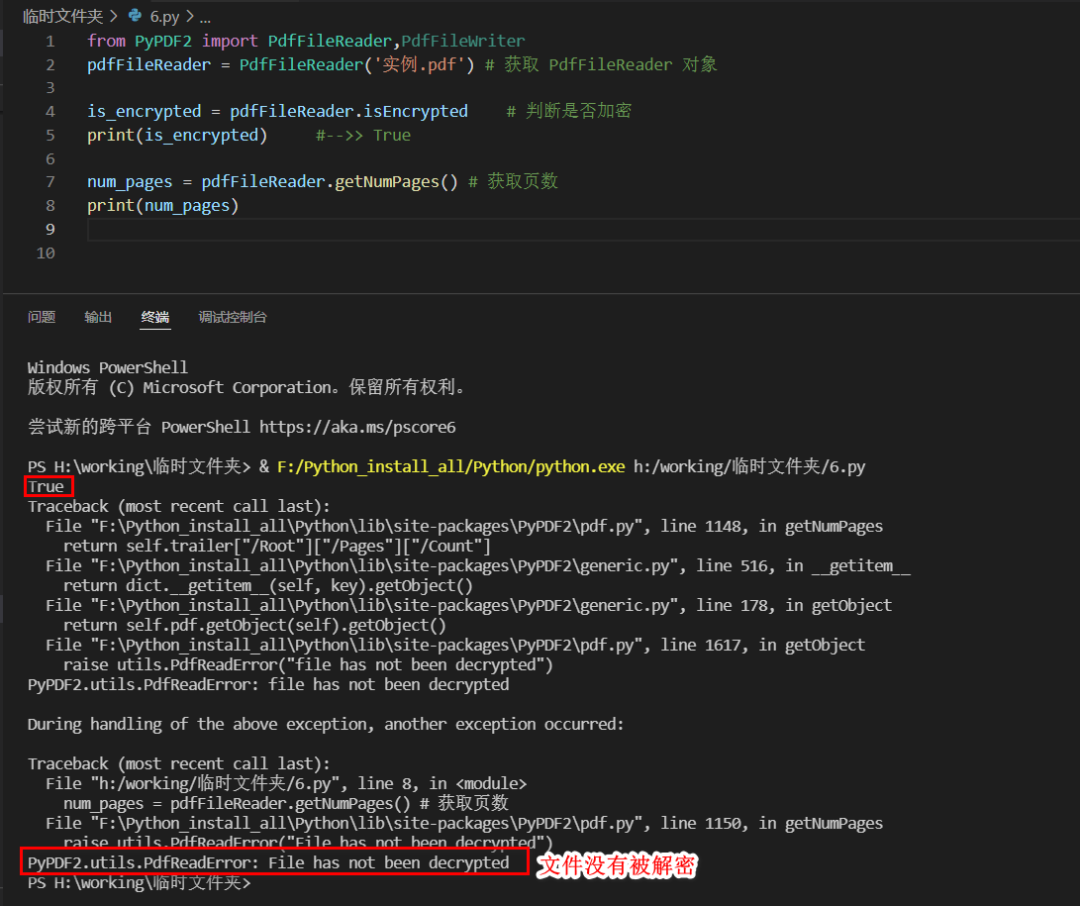
2、解密
from PyPDF2 import PdfFileReader
pdfFileReader = PdfFileReader('实例.pdf') # 获取 PdfFileReader 对象
is_encrypted = pdfFileReader.isEncrypted # 判断是否加密
print(is_encrypted) #-->> True
is_password = pdfFileReader.decrypt('123456')
print(is_password) #-->> 1
is_encrypted = pdfFileReader.isEncrypted # 判断是否加密
print(is_encrypted) #-->> True
num_pages = pdfFileReader.getNumPages() # 获取页数
print(num_pages) #-->> 2好啦,关于PyPDF2的内容我们就讲到这。
当然,对于PyPDF2的操作更多是在文档本身上,因此如果想对文档内容进行操作的话,得另找它路。这个我们就下次再分享啦。
关注👉是山月呀,来和山月一起学习吧~

END

您的“点赞”、“在看”和 “分享”是我们产出的动力。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









