







这是复习了数据结构后的笔记,因为之前模式匹配也看懂了好多次,但每次都过一段时间就忘了,想想总结一下可能会好点,理解得深点。
BM算法
设S是主串,T是模式(字串)。
BM算法是一种暴力的算法。
思想:S的第一位字符和T的第一位字符比较,若相等,则继续比较两者后续的字符。否者,从S的第二位字符开始和T的第一位字符开始比较。重复上述过程,若T的字符串全部比较完毕,则匹配成功,返回本趟匹配的开始位置;否则,匹配失败,返回-1。
缺点:BM算法效率十分低下,当某趟匹配失败后主串要回溯到该趟匹配开始位置的下一位,模式也要回溯到第一位。其实很多时候有一些匹配是没有必要的。
比如:主串T= abcabcacb,模式S=abcac
当第一趟匹配匹配到第5个字符时,T[4] != S[4],第一趟匹配失败。因为 T[1] != S[0],T[2] != S[0],所以用模式的第一位字符和主串的第二、三位匹配是没必要;同时在主串S[4]这个位置匹配失败后,可以通过模式T回溯到 T[1]位置开始匹配,即 S[4] 与 T[1] 匹配,这样只需两趟就匹配成功了(而BM算法需要四趟)。
主串不回溯的情况:

主串回溯(BM算法):

这种小规模数据可能影响并不大的,也只是做了两趟没必要的匹配。但是,当数据规模很大的时候,这没必要的匹配可能就会是数万次,甚至更多。
KMP算法
因此,我们希望某趟 S[i] 和 T[j] 匹配失败后,下标 i 不回溯,小标j回溯到某个位置k使得 T[k] 对准 S[i] 继续进行比较。那我们怎么知道 k 值呢?
k值主要从两种匹配状态联立其关系式获得:以下图片和上述例子无关,独立看
匹配失败后回溯开始新一趟时:画圈的就是代表式子部分

新一躺中部分匹配成功时:画圈的就是代表式子部分

两个式子联立得:
T[0] ~ T[k-1] = T[j-k] ~ T[j-1]
可得模式里的得每一个字符 T[j] 代表 一个k值,这个k值仅依赖于模式,与主串无关。
用next[j] 表示 T[j] 对应的 k 值(0<= j <m),其定义如下:
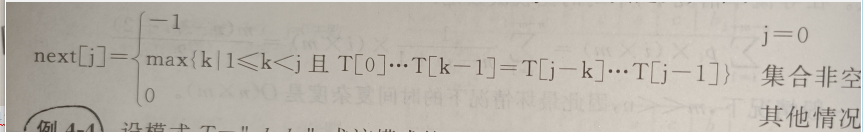
求next得例子:

















 6966
6966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











