







 本文提出了一种新的持续学习方法——神经元校准在线持续学习(NCCL),旨在通过调节神经网络各层的转换函数来缓解灾难性遗忘的问题。该方法通过引入可训练的软掩码对模型参数进行正则化,实现对新旧任务的有效学习。
本文提出了一种新的持续学习方法——神经元校准在线持续学习(NCCL),旨在通过调节神经网络各层的转换函数来缓解灾难性遗忘的问题。该方法通过引入可训练的软掩码对模型参数进行正则化,实现对新旧任务的有效学习。
论文地址点这里
这一篇是百度研究的一篇文章
一. 介绍
为了应对灾难性遗忘,本篇文章专注于基于重放的方式(例如我们之前讲过的GEM和MEGA两篇)。允许模型对过去任务的数据进行有限访问,从而排练过去去的经验。然而基于重放的方式容易导致数据不平衡问题,也就是稳定-可塑性困境。一方面,模型可能受到过去知识的影响从而无法迅速学习到新知识,另一方面,过去的知识可能在学习中慢慢消失。
在本文中,作者从全新的角度解决这个问题,即通过神经元校准寻求稳定性和可塑性之间的平衡。具体来说神经元校准是指对深层神经网络各层的变换函数进行数学调整的过程。神经元校准方式旨在通过参数设置一个可训练的软掩膜来正则化参数更新以防止灾难性遗忘,然后通过正向推理路径和反向优化路径影响模型推理过程和模型训练过程。也就是说,该文训练出一个共享校准模型,将来自不同任务分布的数据交织在一起,从而有效地优化模型,而不是保留特定任务的参数保存任务知识以防止遗忘。
二. 相关工作
根据现有的方法处理灾难性遗忘,目前主要分为三大类,如下。
基于情景记忆重放的方式: 将过去的部分数据存储到情景记忆中,以便以后知识排练使用。基于记忆的方式可以更好地解决灾难性遗忘,但如果内存和实际情况的限制下,很容易受到干扰。
基于正则化重放的方式: 通过扩展了连续学习中的损失函数,以促进对存储在模型参数中的过去知识的选择性巩固。这种方式采用权衡参数信息,识别对过去任务更加重要的参数,来避免遗忘。
动态架构方式: 通过近似地训练每个任务单独的网络来解决灾难性遗忘问题。
三. NCCL(在线持续学习的神经元校准)
符号定义
{
T
1
,
.
.
.
T
T
}
:
\{\mathcal{T_1,...}\mathcal{T}_T\}:
{T1,...TT}:表示在线地持续学习任务序列。每个任务都被授予少量的存储空间来保存过去的数据。
M
t
\mathcal{M}_t
Mt:表示在训练到第t个任务时,存下的关于第t个任务的部分数据。
{
θ
i
}
i
=
1
L
:
\{\theta_i\}^L_{i=1}:
{θi}i=1L:共有L层神经网络,每一层的参数
3.1 神经元校准
通过应用神经元校准,目标是适应深度神经网络层中的转换函数,从而有效地缓解模型参数的灾难性变化,实现来自不同任务的知识的稳定范围。具体来说,本文将两种常用的层进行转换:全连接层和卷积层。作者这里给了个图说明是如何进行工作的。
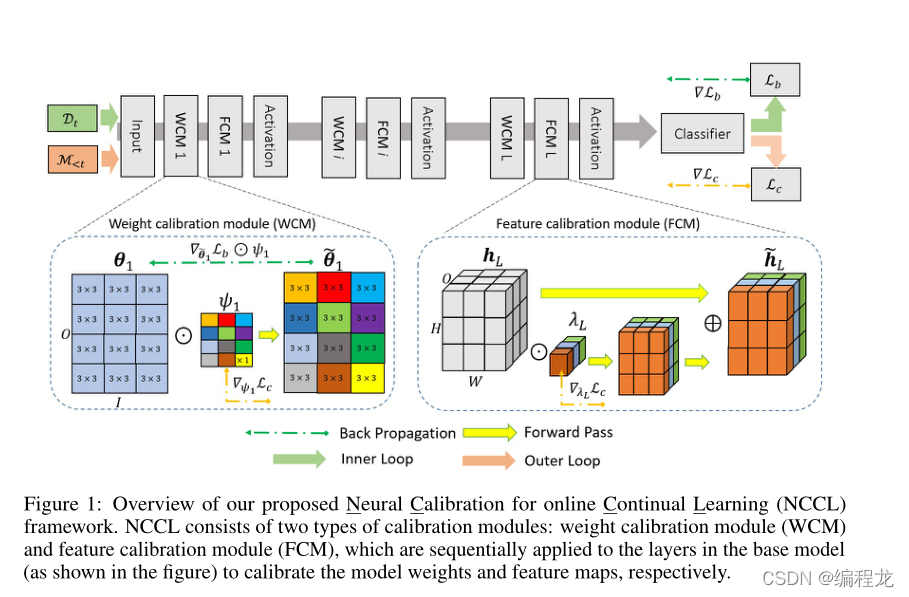
在图中提到了两种转换的方式。第一是权值校准模块(WCM),第二是特征校准模块(FCM)。权值校准模块学习缩放变换函数中参数的权值,而特征校准模块学习缩放变换函数预测的输出特征映射。为了方便说明,用
θ
i
\theta_i
θi表示WCM前的参数,
θ
~
i
\tilde{\theta}_i
θ~i表示经过WCM的参数。同理
h
i
,
h
~
i
h_i,\tilde{h}_i
hi,h~i表示FCM前后的输出特征的映射。
WCM
设
Ω
ψ
i
(
.
)
\Omega_{\psi_i}(.)
Ωψi(.)表示权值校准函数部署在第i层网络上,其参数为
ψ
i
\psi_i
ψi。权值校准但愿是模块化的,采用单元相乘操作,应用于基本网络参数和校准参数之间。具体来说如下:
Ω
ψ
i
(
θ
i
)
=
{
t
i
l
e
(
ψ
i
)
⊙
θ
i
ψ
i
∈
R
O
∗
I
(Convolution Layer)
t
i
l
e
(
ψ
i
)
⊙
θ
i
ψ
i
∈
R
O
(Fully Connected Layer)
(1)
\Omega_{\psi_i}(\theta_i)=\begin{dcases} tile(\psi_i)\odot \theta_i & \psi_i\in\mathbb{R}^{O*I} \ \ \ \text{(Convolution Layer)}\\ tile(\psi_i)\odot \theta_i &\psi_i\in\mathbb{R}^{O} \ \ \ \ \ \ \text{(Fully Connected Layer)} \tag{1} \end{dcases}
Ωψi(θi)={tile(ψi)⊙θitile(ψi)⊙θiψi∈RO∗I (Convolution Layer)ψi∈RO (Fully Connected Layer)(1)
其中O和I表示输出和输入的通道数。为了减少校准参数
ψ
i
\psi_i
ψi,其大小比
θ
i
\theta_i
θi小很多,因此使用tile函数(一个重复的放置函数,可以百度上搜一搜)进行扩大。权值校准方法中,骑着至关作用:在前向传播中,其缩放了基网络参数值进行预测。在反向传播优化过程中,它作为一个优先级权重来正则化重要参数的更新(
∇
θ
1
L
b
\nabla_{\theta_1}\mathcal{L_b}
∇θ1Lb是以
∇
θ
i
~
L
b
⊙
t
i
l
e
(
ψ
1
)
\nabla_{\tilde{\theta_i}}\mathcal{L_b}\odot tile(\psi_1)
∇θi~Lb⊙tile(ψ1)进行导出的,是以校准器参数进行的缩放。)
经过权重的校准后,我们的第i层的输出为:
h
i
=
F
θ
~
i
(
h
~
i
−
1
)
s
.
t
θ
~
i
=
Ω
ψ
i
(
θ
i
)
(2)
h_i = \mathcal{F}_{\tilde{\theta}_i }(\tilde{h}_{i-1}) \ \ \ \ \ s.t\ \ \ \tilde\theta_i =\Omega_{\psi_i}(\theta_i) \tag{2}
hi=Fθ~i(h~i−1) s.t θ~i=Ωψi(θi)(2)
FCM
在经过WCM以及层的处理和激活后,我们获得了一个特征输出,接下来我们需要对特征输出进行FCM。使用
Ω
λ
i
(
.
)
\Omega_{\lambda_i}(.)
Ωλi(.)表示FCM函数。在进行FCM时,校准参数与输出特征进行相乘,具体如下:
Ω
λ
i
(
h
i
)
=
{
t
i
l
e
(
λ
i
)
⊙
h
i
λ
i
∈
R
O
(Convolution Layer)
λ
i
⊙
h
i
λ
i
∈
R
O
(Fully Connected Layer)
(3)
\Omega_{\lambda_i}(h_i)=\begin{dcases} tile(\lambda_i)\odot h_i& \lambda_i\in\mathbb{R}^{O} \ \ \ \text{(Convolution Layer)}\\ \lambda_i\odot h_i&\lambda_i\in\mathbb{R}^{O} \ \ \ \ \ \ \text{(Fully Connected Layer)} \tag{3} \end{dcases}
Ωλi(hi)={tile(λi)⊙hiλi⊙hiλi∈RO (Convolution Layer)λi∈RO (Fully Connected Layer)(3)
处理之后,类似resnet一样,将两个特征输出相加即可。
因此,从i-1层到i层的完整处理如下:
h
~
i
=
σ
(
B
N
(
Ω
λ
i
(
F
θ
~
i
(
h
~
i
−
1
)
)
⊕
F
θ
~
i
(
h
~
i
−
1
)
)
)
s
.
t
θ
~
i
=
Ω
ψ
i
(
θ
i
)
(4)
\tilde{h}_i = \sigma(\ \mathcal{BN}\ (\ \Omega_{\lambda_i}\ (\mathcal{F}_{\tilde{\theta}_i }(\tilde{h}_{i-1}) )\oplus \mathcal{F}_{\tilde{\theta}_i }(\tilde{h}_{i-1}))) \ \ \ \ \ s.t\ \ \ \tilde\theta_i =\Omega_{\psi_i}(\theta_i) \tag{4}
h~i=σ( BN ( Ωλi (Fθ~i(h~i−1))⊕Fθ~i(h~i−1))) s.t θ~i=Ωψi(θi)(4)
BN为batch normalization,
σ
\sigma
σ为激活函数
3.2 参数的学习
层进行处理后,我们需要相应地变换我们的损失函数以便于更好地去更新参数。作者根据EWC中的fisher信息作为一个处理依据。巩固过程发生在训练基础模型参数吸收新知识,并通过重现情景记忆中的数据来排练过去的知识之后,可以进行以下损失计算:
L
c
(
{
ψ
,
λ
,
θ
}
,
(
x
,
y
,
k
)
)
=
1
2
v
e
c
(
θ
~
−
θ
~
t
)
T
Λ
t
(
θ
~
−
θ
~
t
)
⏟
t
e
r
m
(
a
)
+
β
D
K
L
(
S
(
z
^
τ
)
∥
S
(
z
k
^
τ
)
)
⏟
t
e
r
m
(
b
)
(5)
\mathcal{L_c}(\{\psi,\lambda,\theta\},(x,y,k)) = \underbrace{\frac{1}{2}vec(\tilde{\theta}-\tilde{\theta}^t)^T\Lambda_t(\tilde{\theta}-\tilde{\theta}^t)}_{term(a)}+\underbrace{\beta D_{KL}(S(\frac{\hat{z}}{\tau}) \parallel S(\frac{\hat{z_k}}{\tau}))}_{term(b)} \tag{5}
Lc({ψ,λ,θ},(x,y,k))=term(a)
21vec(θ~−θ~t)TΛt(θ~−θ~t)+term(b)
βDKL(S(τz^)∥S(τzk^))(5)
损失其中
β
\beta
β为一个平衡参数,S(.)为一个softmax函数,
τ
\tau
τ为softmax的蒸馏温度,
z
^
\hat{z}
z^为针对当前任务预测出的值,
z
k
^
\hat{z^k}
zk^为之前任务的预测。vec(.)则是将对应的内容存入到数据中。
Λ
t
\Lambda_t
Λt为EWC中的fisher information从存储中的知识蒸馏的损失求出。term(a)是进行对权重的部分的冻结已保证处理灾难性遗忘,而term(b)为在训练的同时保证稳定。
3.3 优化
NCCL的优化类似maml,分为内部优化和外部优化。内部优化更新
θ
\theta
θ,而外部优化更新
ψ
,
λ
\psi,\lambda
ψ,λ。优化目标为:
Outer Loop:
(
ψ
∗
,
λ
∗
)
=
a
r
g
m
i
n
(
ψ
,
λ
)
L
c
(
(
ψ
,
λ
)
,
θ
∗
,
M
<
t
)
(6)
\text{Outer Loop: }(\psi^*,\lambda^*) = argmin_{(\psi,\lambda)}\mathcal{L_c}((\psi,\lambda),\theta^*,\mathcal{M}_{<t}) \tag{6}
Outer Loop: (ψ∗,λ∗)=argmin(ψ,λ)Lc((ψ,λ),θ∗,M<t)(6)
InnerLoop:
θ
∗
=
a
r
g
m
i
n
θ
L
b
(
(
ψ
,
λ
)
,
θ
,
M
<
=
t
)
(7)
\text{InnerLoop: }\theta^* = argmin_{\theta}\mathcal{L_b}((\psi,\lambda),\theta,\mathcal{M}_{<=t}) \tag{7}
InnerLoop: θ∗=argminθLb((ψ,λ),θ,M<=t)(7)
最后设定学习率进行学习更新即可。
完整的算法过程如图所示:

四.代码解读
作者的github代码点这里
本篇文章难点在于网络层的构造,也就是WCM和FCM两块,以及层的处理,那么首先我们来看这段代码。
每一层结构如图所示
h
~
i
=
σ
(
B
N
(
Ω
λ
i
(
F
θ
~
i
(
h
~
i
−
1
)
)
⊕
F
θ
~
i
(
h
~
i
−
1
)
)
)
s
.
t
θ
~
i
=
Ω
ψ
i
(
θ
i
)
\tilde{h}_i = \sigma(\ \mathcal{BN}\ (\ \Omega_{\lambda_i}\ (\mathcal{F}_{\tilde{\theta}_i }(\tilde{h}_{i-1}) )\oplus \mathcal{F}_{\tilde{\theta}_i }(\tilde{h}_{i-1}))) \ \ \ \ \ s.t\ \ \ \tilde\theta_i =\Omega_{\psi_i}(\theta_i)
h~i=σ( BN ( Ωλi (Fθ~i(h~i−1))⊕Fθ~i(h~i−1))) s.t θ~i=Ωψi(θi)
其中WCM为:
Ω
ψ
i
(
θ
i
)
=
{
t
i
l
e
(
ψ
i
)
⊙
θ
i
ψ
i
∈
R
O
∗
I
(Convolution Layer)
t
i
l
e
(
ψ
i
)
⊙
θ
i
ψ
i
∈
R
O
(Fully Connected Layer)
\Omega_{\psi_i}(\theta_i)=\begin{dcases} tile(\psi_i)\odot \theta_i & \psi_i\in\mathbb{R}^{O*I} \ \ \ \text{(Convolution Layer)}\\ tile(\psi_i)\odot \theta_i &\psi_i\in\mathbb{R}^{O} \ \ \ \ \ \ \text{(Fully Connected Layer)} \end{dcases}
Ωψi(θi)={tile(ψi)⊙θitile(ψi)⊙θiψi∈RO∗I (Convolution Layer)ψi∈RO (Fully Connected Layer)
FCM为:
Ω
λ
i
(
h
i
)
=
{
t
i
l
e
(
λ
i
)
⊙
h
i
λ
i
∈
R
O
(Convolution Layer)
λ
i
⊙
h
i
λ
i
∈
R
O
(Fully Connected Layer)
\Omega_{\lambda_i}(h_i)=\begin{dcases} tile(\lambda_i)\odot h_i& \lambda_i\in\mathbb{R}^{O} \ \ \ \text{(Convolution Layer)}\\ \lambda_i\odot h_i&\lambda_i\in\mathbb{R}^{O} \ \ \ \ \ \ \text{(Fully Connected Layer)} \end{dcases}
Ωλi(hi)={tile(λi)⊙hiλi⊙hiλi∈RO (Convolution Layer)λi∈RO (Fully Connected Layer)
根据代码首先定义每一层的参数:
作者这里是将两个CNN层处理后定义成一层,具体如下:
class CalibratedBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1, activation='relu', norm='batch_norm', downsample=None):
super(CalibratedBlock, self).__init__()
## 第一层CNN
self.conv1 = conv3x3(in_planes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
## 第二层CNN
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.stride = stride
self.sigma = 0.05
self.downsample=downsample
## 定义调整参数,cw(WCM中的权重调整) cb(卷积层的bias) cf(FCM的输出映射)
self.calib_w_conv1 = torch.nn.Parameter(torch.ones(planes, in_planes, 1, 1, ), requires_grad = True)
self.calib_b_conv1 = torch.nn.Parameter(torch.zeros([planes]), requires_grad = True)
self.calib_f_conv1 = torch.nn.Parameter(torch.ones([1, planes, 1, 1]), requires_grad = True)
self.calib_w_conv2 = torch.nn.Parameter(torch.ones(planes, planes, 1, 1, ), requires_grad = True)
self.calib_b_conv2 = torch.nn.Parameter(torch.zeros([planes, 1, 1, 1]), requires_grad = True)
self.calib_f_conv2 = torch.nn.Parameter(torch.ones([1, planes, 1, 1, ]), requires_grad = True)
## 放到模型中
self.register_parameter('calib_w_conv1', self.calib_w_conv1)
self.register_parameter('calib_b_conv1', self.calib_b_conv1)
self.register_parameter('calib_f_conv1', self.calib_f_conv1)
self.register_parameter('calib_w_conv2', self.calib_w_conv2)
self.register_parameter('calib_b_conv2', self.calib_b_conv2)
self.register_parameter('calib_f_conv2', self.calib_f_conv2)
# 另外独自进行一次普通的conv
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion * planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion * planes, kernel_size=1,
stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * planes)
)
self.activation = activation
self.norm = norm
接下来来看具体的forward过程:
def forward(self, x):
# compute the mask first
if self.activation == 'relu':
activation = nn.functional.relu
elif self.activation == 'leaky_relu':
activation = nn.functional.leaky_relu
else:
activation = None
[dim0, dim1] = self.conv1.weight.shape[2:]
calibrated_conv1 = self.calib_w_conv1
## 执行tail操作,扩大\psi
this_ss_weights = torch.tile(calibrated_conv1, (1, 1, dim0, dim1))
## 相乘更新我们的w
cw = self.conv1.weight * this_ss_weights
## 更新后的w再进行卷积操作
conv_output = torch.nn.functional.conv2d(x, cw, stride=self.stride,
padding=1, bias=self.calib_b_conv1.squeeze())
## 计算出h后,进行FCM
[dim1, dim2] = conv_output.shape[2:]
this_scale_weights = torch.tile(self.calib_f_conv1, (conv_output.shape[0], 1, dim1, dim2))
conv_output = conv_output * this_scale_weights
# normalize
if self.norm == 'batch_norm':
normed = self.bn1(conv_output)
elif self.norm == 'layer_norm':
normed = torch.nn.functional.layer_norm(conv_output)
else:
normed = conv_output
## 最后进行激活
out = activation(normed)
#### 接下来和上面一样,对上一轮的out 再进行一次WCM FCM完整操作
# second conv layer
[dim0, dim1] = self.conv2.weight.shape[2:]
# epsilon_weight = torch.randn(self.masked_conv2.shape).to(self.masked_conv2.device) * self.sigma
calibrated_conv2 = self.calib_w_conv2 #+ epsilon_weight * self.masked_conv2_sigma
this_ss_weights = torch.tile(calibrated_conv2, (1, 1, dim0, dim1))
cw = self.conv2.weight * this_ss_weights
# < resnet_conv_block_scale>
conv_output = torch.nn.functional.conv2d(out, cw,
stride=1, padding=1, bias=self.calib_b_conv2.squeeze())
[dim1, dim2] = conv_output.shape[2:]
this_scale_weights = torch.tile(self.calib_f_conv2, (conv_output.shape[0], 1, dim1, dim2))
conv_output = conv_output * this_scale_weights
# normalize
if self.norm == 'batch_norm':
normed = self.bn2(conv_output)
elif self.norm == 'layer_norm':
normed = torch.nn.functional.layer_norm(conv_output)
else:
normed = conv_output
out = activation(normed)
# residual
## 原本的值
residual = self.shortcut(x)
## 直接进行相加
return out + residual
之后我们来看对应的inner update 和outer update
首先是inner update。假设当前为第t个任务,我们根据第t个任务用crossentropy计算出loss1,然后从我们存储的数据[1,t)中选取一部分数据(这里作者用的是随机选取,也就是第一个任务抽出几个数据,第二个任务抽出几个数据,以此类推)。之后我们根据抽取的任务计算出loss2,最后再计算loss3=KL散度。loss2和loss3作为对旧任务的学习,加到loss1中。具体过程如下:
for step in range(self.inner_steps):
self.zero_grad()
self.opt.zero_grad()
offset1, offset2 = self.compute_offsets(t)
copy_net = copy.deepcopy(self.net)
# 从当前任务选取数据并计算损失
if step == 0:
pred = self.forward(x, t)
pred = pred[:, offset1:offset2]
yy = y - offset1
elif self.count >= step * self.batch_size:
xx, yy, _, mask, list_t = self.memory_sampling(t, self.batch_size, intra_class=True)
pred = self.net(xx)
pred = torch.gather(pred, 1, mask)
else:
pred = self.forward(x, t)
pred = pred[:, offset1:offset2]
yy = y - offset1
# return 0.0
loss1 = self.bce(pred, yy)
## 从旧任务中选取数据,并计算损失
if t > 0:
xx, yy, feat, mask, list_t = self.memory_sampling(t, self.replay_batch_size)
pred_ = self.net(xx)
pred = torch.gather(pred_, 1, mask)
## 这里是旧任务损失
loss2 = self.bce(pred, yy)
## 计算散度,feat为存储的之前数据的softmax的值
loss3 = self.reg * self.kl(F.log_softmax(pred / self.temp, dim=1), feat)
loss = loss1 + (loss2 + loss3) * self.gamma
else:
loss = loss1
## 梯度更新
grads = torch.autograd.grad(loss, self.net.base_param(), create_graph=True, allow_unused=True, retain_graph=True)
# 只更新\theta
num_none, num_grad = 0, 0
for param, grad in zip(self.net.base_param(), grads):
if grad is not None:
new_param = param.data.clone()
if self.inner_clip > 0:
grad.data.clamp_(-self.inner_clip, self.inner_clip)
new_param = new_param - self.inner_lr * grad
param.data.copy_(new_param)
num_grad += 1
else:
num_none += 1
inner更新后,我们需要处理outer的损失。outer的损失同理需要采取一部分旧任务数据,根据旧任务数据计算出KL散度的loss,根据这个loss计算梯度之后,再用梯度去计算EWC中的fisher信息。最后用fisher信息计算正则化的损失(term (a)),再用这个损失更新我们的 ψ 和 λ \psi和\lambda ψ和λ即可。
if t > 0:
self.net.zero_grad()
self.opt.zero_grad()
xval, yval, feat, mask, list_t = self.memory_sampling(t, self.batch_size)
pred_ = self.net(xval)
pred_ = torch.gather(pred_, 1, mask)
# 1st loss update
outer_loss = self.reg * self.kl(F.log_softmax(pred_ / self.temp, dim=1), feat)
outer_grad = torch.autograd.grad(outer_loss, self.net.context_param() + self.net.base_weight_params(),
retain_graph=True, allow_unused=True,)
# 2nd loss update
old_masked_params, _, _ = copy_net.base_and_calibrated_params()
cur_masked_params, cur_tiled_mask_params, cur_base_params = self.net.base_and_calibrated_params()
reg = self.beta * self.reg #* self.reg
ewc_loss = 0.0
num_meta_params = len(self.net.context_param())
for ii, p in enumerate(cur_masked_params):
##这里就是计算fisher信息 = (p.grad / tile(\psi) )^2
pg = (outer_grad[num_meta_params + ii].data/(cur_tiled_mask_params[ii].data +1e-12)).pow(2)
cur_loss = reg * pg.detach() * (p - old_masked_params[ii].data.clone()).pow(2)
ewc_loss += cur_loss.sum()
ewc_loss.backward()
self.opt.step()

















 1557
1557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









