










目录
接上前文:xCCL: A Survey of Industry-Led Collective Communication Libraries for Deep Learning-1
4.2 xCCL Collective Communication Algorithms
实际应用中的xCCL将会根据系统配置、网络拓扑和调用情况来优化性能。
4.2.1 NCCL
- Ring:在All-reduce中使用,延迟随着GPU数量增加而增加。CUDA中,一个CUDA线程块被分配到这个库中的一个环方向
- Double binary tree:树是对数延迟的,性能更优。同时在这个算法中,一个节点在A树中是叶子,在B树中是中间节点,这种double tree的方式使得root以外的每个rank都有两个root和两个child。在nccl更早期版本的时候,一个rank可能有3个出口,但是调整为balanced tree以后,所有rank都是两出两进,即更加平衡了。
4.2.2 MSCCL
- Ring:All-reduce、reduce-scatter和All-gather都有实现。MSCCL会在一个逻辑环中分配多个channel。因此同一对GPU可能有不同的P2P链接。安排时序的协议会根据数据的大小来选择不同channel。在这种策略下,通过不同的p2p链接也可以实现更有效的overlap和逻辑环。
- All-Pairs:在MSCCL中,用于数据块的有三种不同的GPU buffer(input,output,scratch)。由于ring不适合用于小块的数据(Ring需要2n-2步),因此他们为All-Reduce实现了All-pairs这种算法(只要两步)。
- Hierarchical:用于All-Reduce(4步:1、节点内执行reduce-scatter。2、节点间执行reduce-scatter。3、节点间All-gather。4、节点内All-gather)
- Tow-Step:传统的All-to-All可以在一步内完成,但是传输数据量太大。MSCCL的两步All2All算法可以通过节点间聚合的方式降低通信成本。
4.2.3 Gloo
- Ring:与前文4.1.1实现方式没区别.
- Ring-Chunked:基于ring,把buffer划分成小块,以便每个进程在传输另一个块时将一个块归约为本地结果。
- Halving-Doubling:与前文相似,Halving-Doubling算法使用距离来决定进程之间的通信对。例如,当通信距离为1时,每个进程从其旁边的进程发送和接收数据缓冲区;当距离为2时,从距离为一个进程的进程发送和接收。该算法由两个阶段组成。1)距离加倍的Reduce-Scatter操作阶段。在此结果中,每个进程持有归约结果的一部分。2)距离减半的All-Gather操作阶段。在此结果中,所有进程从其他进程接收归约结果的其余部分。
- Pairwise-Exchange:简化版Halving-Doubling。每一步中的进程成对,且通信时数据大小不变。
- BCube:该算法将进程分成组。首先,它在组内的进程之间执行Reduce-Scatter操作,并在来自不同组的相应进程之间执行All-Reduce操作。其次,每个组在组内执行All-Gather操作,以便最终每个进程都能接收到归约结果。
4.2.4 ACCL
- Hybrid:通过混合的算法,使得All-Reduce的带宽利用率最大化。混合All-Reduce将All-Reduce操作解耦为多个微操作,消除了无意义的微操作。这种混合算法分为三个步骤。第一步,基于Ring算法执行节点内的Reduce-Scatter;第二步,基于Halving-Doubling算法执行节点间的All-Reduce;第三步,基于Ring算法执行节点内的All-Gather。
5. Collectives and DeepLearning
机器学习如今在工业界和科研界的应用都很广泛,而且效果比传统方法更好。(包括精确系统、自动机、癌症检测、自动驾驶。。)
为通用计算而调整的GPU,通常称为通用图形处理器(GPGPU)。并行计算又可以剧烈地提升性能。
随着模型尺寸越来越大,和硬件加速结合得更紧密的分布式训练解决方案成为刚需。所以集合通信作为一个范式能提供更灵活的实现,同时保持其准确性。
当然,大模型的诞生也更加强调了并行训练的重要性。
NCCL+RDMA可以让VGG16提速30%。
5.1 Case Study with Meta Workloads
推荐系统:为用户提供个性化的推送。(商业、社交媒体、广告领域)
Meta的模型:DNN based RMCs(Recommendation model classes),用于产品销售。Meta还涉及了用于软硬件协同设计的Neo(基于PyTorch)。Neo里面的kernl融合放在FBGEMM里面开源了。
1)Neo基于可伸缩变形的DLRM,4D并行度(表格式并行)解决了工作负载中的不平衡。
2)hybrid kernel fusion。融合了参数更新部分,并内嵌到CUDA kernel中。
3)新的硬件平ZionEX
在ResNet上面也有做一定的改进。
Meta能够在一个分布式训练系统上在一小时内训练一个ResNet50模型。怎么做到的呢?
首先部署32个节点,每个节点上8张GPU,共计256张。网卡要是8Gbit并且还要使用NVLink。
节点内估计是P2P直接通信,节点间和Host到GPU间使用了NCCL。
尝试使用多个GPU进行训练可能会导致通信和聚合成本增加到不可接受的水平。
为了缓解这些问题,通过使用缓冲区大小将通信在CPU和GPU资源之间平衡,
并手动选择对于正在测试的特定工作负载和网络拓扑最有效的集体算法。
5.2 Case Study with Google Workloads
DistBelief:该框架中观察到多级分布式训练对大型DNN模型很有用。1,7B的参数,81台机器,可加速12倍。
TensorFlow:讲了一点tf的优点和一些DNN on distributed/HPC系统上的工作。也提到了正在做的工作。
NCCL Fast socket:谷歌云的一些NCCL相关优化。
5.3 Case Study with Uber Workloads
Uber使用的ML应用更加多样化(包括饮食、市场预测、客户支持、RideCheck、抵达时间预测、One-Click chat、自动驾驶等)Uber的平台上一个应用可能要运行多种模型(搜索排名、自动补全、餐馆排名等)
Data Science Workbench(DSW):可以为入门级数据科学家和工程师提供很好服务的,大规模分布式深度学习训练与部署平台。
Horovod:Uber还有篇论文,怎么用Horovod代替百度的ring-allreduce NCCL实现。
NCCL2: Tensorflow的NCCL2支持。
5.4 Case Study with Amazon Workloads
万恶的亚马逊时间。
亚马逊提供了各种云端部署工具。
公共云上可用的网络架构和速度通常与专用ML训练集群的网络架构和速度大不相同,后者的带宽更加异构。试图执行涉及所有级别的集体行动可能是非常昂贵的。
因此出现了亚马逊的MiCS:
MiCS如何解决异构问题,关键思想是减少集体通信的参与者数量,并通过扩展减少在低带宽连接上发生的通信的数据量。通过使用分层通信策略并将通信分解为阶段,即使模型大小超过节点上设备内存需求,也可以实现这一点。
首先,设备对其他节点上具有相同相对等级的设备执行节点间All-Gather操作。
其次,节点执行节点内All-Gather来完成通信。此外,MiCS使用“2跳”的梯度同步过程,而不是标准的梯度聚合过程。这一步通常非常昂贵,因为它的成本随着设备数量的增加而增加。设备被分成跨节点的小组。梯度分区和同步首先在小组内执行,然后在全局执行,从而减少总流量。
6 Industry Solutions—xCCL
6.1 NCCL
NVIDIA集体通信库㉘是目前最流行的gpu加速集体通信库。
它实现了跨多个节点的多个gpu的集体操作以及特定的点对点通信原语。
NCCL官方只支持NVIDIA gpu,尽管已经努力将其以ROCm Collective的形式移植到AMD显卡上。
NCCL的目标是提供GPU之间的快速通信,用于密集的多gpu系统,而MPI侧重于集群中数千个节点之间的高效通信。
NCCL使用ring算法来在所有GPU之间传输数据,数据被划分为communicator中所有rank的块,以在降低延迟的同时获得合理的带宽。
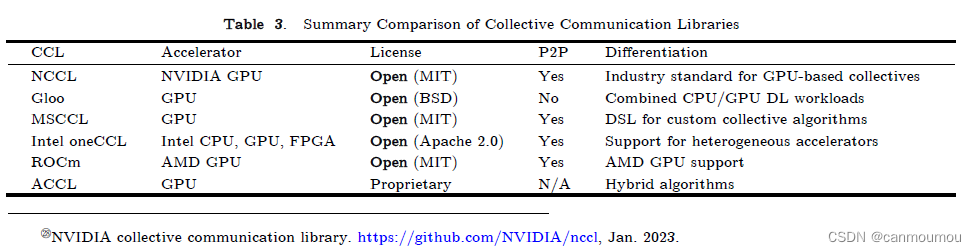
NCCL通过PCIe(Peripheral Component Interconnect Express)、NVLink(NVIDIA的一种高速互连技术)和GPUDirect(一种允许网络或存储直接与GPU通信的技术)执行节点内通信。
NCCL中的节点间通信是通过GDR(GPU Direct RDMA,一种直接内存访问技术)进行的。NCCL的CUDA内核可以使用GDR和GPUDirect将存储在一台GPU的全局内存中的数据复制到另一台GPU。
6.1.1 Architecture
6.1.2 NCCL API
类似于NVIDIA的CUDA,NCCL提供了一个C语言的API,因此程序员可以在现有的C项目中使用NCCL,或者甚至在像Python这样的高级语言中使用C绑定。
通过ncclCommInitRank()、ncclCommInitRankConfig()或ncclCommInitAll()函数来初始化。每个函数都为开发者提供了不同的配置等级和通信选项。
可以使用相应命名的API调用来运行各个集体操作。All-Reduce操作可以使用ncclAllReduce()函数来运行,Broadcast操作可以使用ncclBroadcast()函数来运行,
NCCL还支持点对点(P2P)通信,形式为(向特定等级发送数据)的ncclSend()和(从特定等级接收数据)的ncclRecv()。
6.1.3 Framework Support
由于深度神经网络训练的规模变得太大,无法在单个计算节点上执行,一些最先进的深度学习框架,如TensorFlow[62]、Caffe[69]、PyTorch[57]、CNTK[70]和MXNet[71],已经通过使用NCCL实现了在多个节点上的分布式训练。这些框架利用NCCL在所有可用的GPU之间执行集体通信。
Horovod[53]通过采用NCCL进行高效的GPU间通信,使得在TensorFlow中进行更快、更简单的分布式训练成为可能。
6.1.4 Supported Features
Communicator.
NCCL为通信体中的每个CUDA设备分配一个唯一的等级(rank),这个等级是一个介于0到n-1(包括0和n-1)之间的整数。每个与固定等级和同一NCCL通信体中的CUDA设备相关联的通信体对象将被用来启动集体通信。这意味着在执行如All-Reduce或Broadcast等集体操作时,每个参与的CUDA设备都有一个明确的角色和编号,从而确保数据能够正确地在它们之间传递和同步。
Stream.
点对点原语和集合通信:这些是两种基本的通信方式。点对点通信涉及两个GPU之间的数据传输,而集体通信则涉及多个GPU之间的数据同步。
单个CUDA内核:NCCL的设计使得这些通信操作可以在不需要多个内核切换的情况下,在单个CUDA内核中完成,这减少了上下文切换的开销。
消息分块:为了实现快速同步,每个通信步骤中的整个消息被细分为更小的块(chunks)。这种分块策略有助于减少延迟,并允许更高效的数据传输。
CUDA流:CUDA编程模型中的一个概念,允许开发者将序列化的内核执行为并行流。通过在不同的CUDA流中调度NCCL操作,可以在等待网络通信完成的同时,让GPU执行其他操作。
异步行为:由于使用了CUDA流,NCCL调用可以在通信过程仍在进行中时返回,这样可以更有效地利用GPU资源,避免潜在的空闲时间。这种异步性是现代GPU编程中提高性能的关键特性之一。
Topology.
基于互连网络,NCCL从一组拓扑结构中选择,包括基于环(ring)和基于树(tree)的方法。
Protocols.
在NCCL发送数据时,存在三种协议:
-
低延迟,8字节原子存储(LL):提供低延迟的通信,原子存储操作使用8字节。
-
低延迟,128字节原子存储(LL128):与LL类似,但原子存储操作使用128字节,某些情况下可能提供更好的带宽效率。
-
Simple:简化的协议,实现上更简单,可能性能不如前两种协议。
对于需要快速响应的应用程序,可能会优先选择低延迟的协议。对于需要处理大量数据传输的应用程序,可能会选择提供更高带宽的协议。
6.2 Intel oneCCL
英特尔oneAPI集体通信库(oneCCL)是一个旨在开发单一标准的集体通信库
6.2.1 Architecture
Intel oneCCL是建立在现有的低级中间件之上的,因此它支持InfiniBand(无限带宽网络)、以太网以及其他互连技术。更具体地说,它建立在Intel自己的定制MPICH支持的MPI库(即Intel MPI库)和libfabric(一个用于织物的开源库集合)之上。这些库处理低级别的节点间和设备间通信,以实现可移植性和互连支持。然而,对于性能关键型计算和设备上的通信,oneCCL仍然提供了直接访问硬件(级别0)的功能。
多层架构:oneCCL作为一个高层通信库,建立在较低级别的中间件之上,这允许它利用现有的基础设施。
基于Intel MPI库:oneCCL基于Intel MPI库构建,这是一个为高性能计算环境设计的MPI(消息传递接口)的实现。
libfabric:这是一个开源库,提供了对多种网络硬件的抽象表示,使得应用程序能够更容易地与不同的网络硬件交互。
低级通信处理:低级别的节点间和设备间通信由底层库处理,这有助于确保oneCCL的可移植性和对不同互连技术的支持。
直接硬件访问:尽管oneCCL依赖于底层库来处理通信,但它仍然提供了直接访问硬件的接口,这对于性能至关重要,特别是在需要快速的设备上通信和计算时。
性能与可移植性的平衡:oneCCL的设计在提供高性能的同时,也考虑了在不同硬件和网络配置上的可移植性。
6.2.2 Routines
目前支持的集合通信操作:
- All-Gather(v)
- All-Reduce
- All-to-All(v)
- Barrier
- Broadcast,
- Reduce
- Reduce-Scatter
这些操作可以异步运行,并且可以使用操作运行时返回的事件对象来跟踪操作的状态。程序员还可以通过优先级字段来控制操作调度。
6.2.3 Framework Support
torch_ccl, PyTorch,Horovod.
6.3 Alibaba ACCL
- 多种多样的可用结构+利用多轨道网络降低通信成本
- 支持Tensorflow和Horovod
- Apsara AI Accelerator(AIACC),阿里利用云服务作为AI加速基础设施
6.3.1 Hybrid Algorithms
- 混合集体算法:只用标准集合通信算法的组合(以最大限度地提高网络利用率,从而提高整体通信性能)
6.4 AMD RCCL
The AMD ROCm Communication Collectives Library(RCCL)
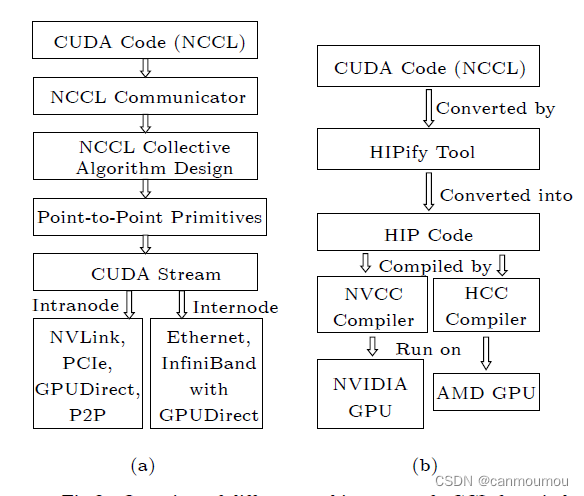
这个是NCCL porting到AMD上的。目的是允许开发者同时在NV和AMD上使用NCCL,且不需要重写代码。
RCCL是AMD ROCm开放软件堆栈的一个组件,并与HIPify一起运行在可以将CUDA代码转换为HIP的系统上
(可移植性的异构计算接口)
- 支持通过PCIe和xGMI互连在本地传输数据
- 支持通过InfiniBand Verbs和TCP/IP套接字在网络上传输数据。
- gpu到gpu(P2P)直接通信操作
6.4.1 Architecture
类似NCCL。
如前面b图所示。
如NCCL库本身的CUDA代码,可以通过HIPify转换为HPI代码。
6.4.2 Supported Features and Workloads
- PyTorch1.8开始支持
- Tensorflow v1.1.5开始支持
因为它使用与NCCL相同的API,所以RCCL还支持通信器和拓扑等特性。
RCCL中的流特性与NCCL中的流特性不同,它使用HIP流而不是CUDA流。
6.5 Meta Gloo
- 支持P2P
- 支持集合通信(All-Reduce、All-Gather、Boradcast)
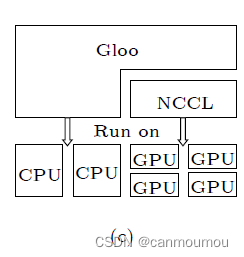
6.5.1 Architecture
Gloo支持通过PCIe和NVLink等互连进行多gpu通信。
Gloo支持不同的数据传输方式进行节点间和节点内的数据通信。
例如,cpu到cpu的传输采用TCP、RoCE和IB, cpu到cpu的传输采用GPUDirect技术(GPU-to-GPU)运输。
6.5.2 Supported Features and Workloads
在PyTorch的torch:distributed中,Gloo被当做通信后端被提供。也可以在tf、MXNet和Keras中使用。
两种方法来协调CPU数据传输的通信通道:
- MPI
- 自定义会合进程(custom rendezvous process)
MPI进程控制跨设备的连接通道,MPI通信器绑定到GPU上下文。管理跨多台机器通信的另一种方法是使用Gloo的会合通道设置过程
Rendezvous(自定义会合进程)使用一个所有进程都可以访问的中央键值存储系统来存储Gloo上下文。
每个进程都有一组对应于它的对等进程的键。 当一个进程想要向另一个进程发送消息时,它使用键值存储系统来获取相应的IP地址和端口等信息作为值
6.6 Microsoft MSCCL
MSCCL由GC3、TACCL和SCCL三部分组成。
GC3提供了一种面向数据的领域特定语言(DSL)和相应的编译器来简化GPU通信编程
TACCL致力于通过引导合成器自动生成算法。
SCCL综合了针对硬件拓扑定制的集体通信算法。
6.6.1 Architecture
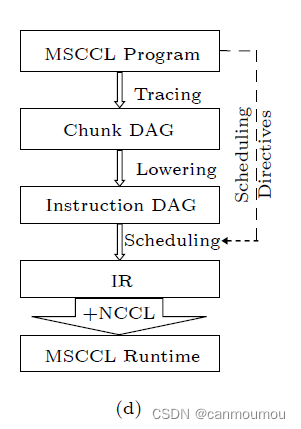
- 使用面向块的程序(chunk-oriented program)生成高效的自定义通信算法:
基于块的程序指定了从源到目的地的块路由。
为了通过GPU指定块路由,GC3 中使用了 DSL,而 TACCL 中使用了通信草图。
创建程序后,可以将其追踪为一个块定向无环图 (DAG)。然后,通过将块操作扩展为指令操作来创建指令 DAG (与块 DAG 不同)。之后,将指令 DAG 编译成中间表示 (IR) 后进行调度。在生成 IR 后,MSCCL 运行时能够有效地执行它,因为 MSCCL 运行时继承了 NCCL 在各种互连环境(如 NVLink 和 PCIe)上设置点对点链接的能力。
6.6.2 Framework Support
MSCCL的API与NCCL兼容。使用PyTorch的时候直接把NCCL后端换掉即可。
6.6.3 MSCCL Runtime
MSCCL DSL
DSL是一种面向块的数据流语言,可用于编写高效的通信内核。程序员指定块如何在这种语言中跨gpu路由。
MSCCL Runtime
IR是由MSCCL编译器生成的可执行文件。MSCCL运行时扩展了NCCL,并使用NCCL的点对点发送和接收功能,并向后兼容NCCL的API。
MSCCL Compiler
MSCCL编译器跟踪程序,在块DAG中记录块依赖关系。然后,编译器执行一系列优化,并将生成的块DAG调度到IR中指定的线程块。的MSCCL
DSL允许用户指导编译器对程序进行优化和调度。
Optimization.(优化)
1)同一对gpu中可能存在多个连接,并将其标记为通道,以帮助区分不同的连接。然后可以为特定的操作分配最有效的通道。
2)一个传输可以被分解成多个较小的传输,以提高执行的并行性
3)当多个连续块从一个GPU发送到另一个时,聚合这些块可以减少延迟。
7 Experimental Comparison of Implementations
部署环境

测试结果
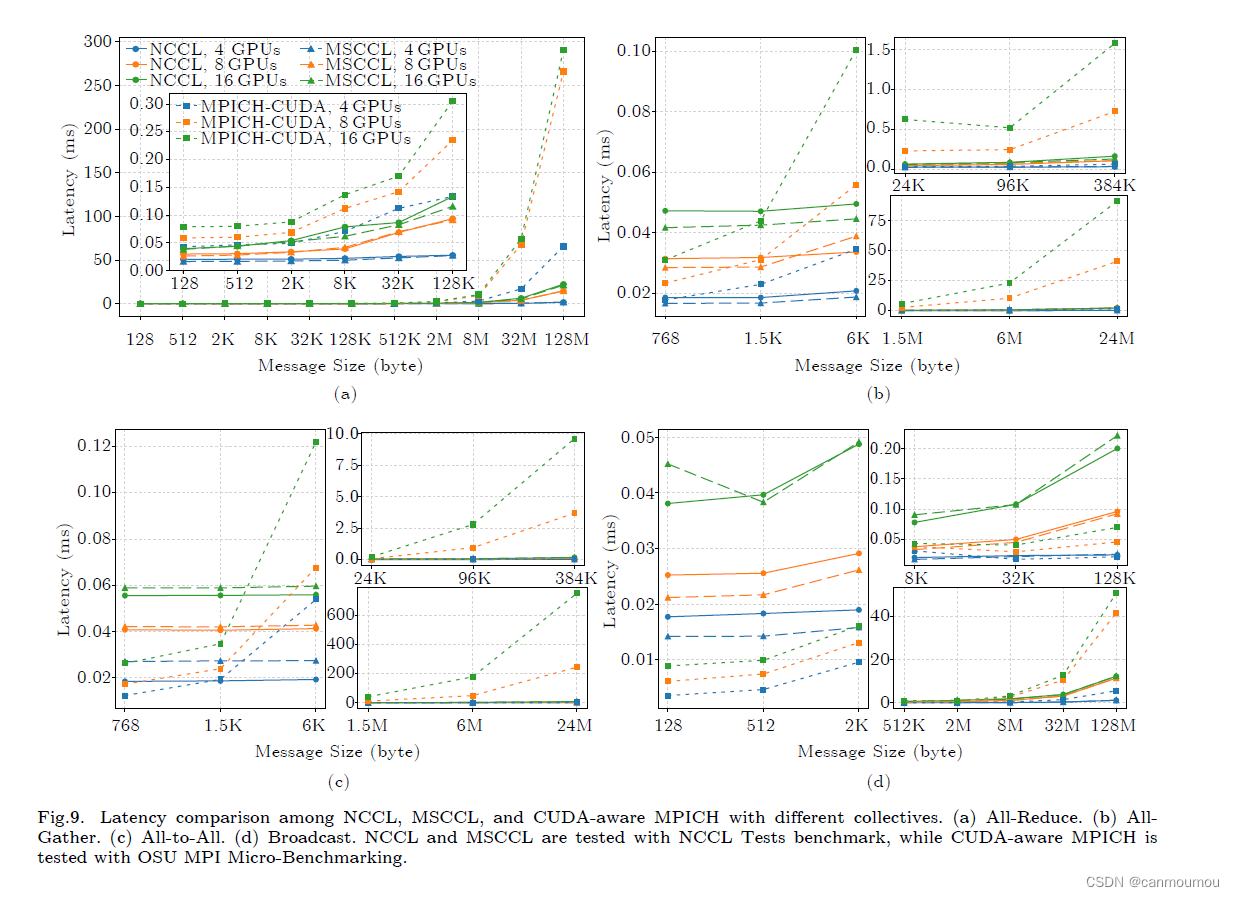
8 Discussion
来解答第一篇笔记中提到的两个问题。
第一个问题,为什么xCCL库相比经典MPI更有吸引力?
- 由于近年来机器学习/深度学习的流行,GPU已经成为工业和研究中普遍存在的设备。因此,学术界对于调查针对GPU和专用硬件(如NVIDIA的NCCL)的集体通信库感兴趣。
- NCCL 本身设计良好。实质上,NCCL 可以被视为带有CUDA的简化的MPI实现,这使得它能够更好地利用强大的GPU,特别是对于机器学习/深度学习工作负载。NCCL 使用简单,轻量级,并且提供高可伸缩性和稳定性能。
- 与 xCCL 相比,经典的MPI通信库尚未能够有效利用硬件加速,使得它们的吸引力较小。例如,尽管 MPI 库在几十年间增加了许多功能(如 GPU 支持),但这些众多功能使得库变得越来越臃肿,这对 MPI 的性能和可用性造成了损害
第二个问题:这其中谁的性能最好?
NCCL
第三个问题:这些xCCL库有哪些共同点和差异?
共通点:都支持All-Reduce和Broadcast,都基于NCCL或者NCCL后端
差异:采用不同的开源许可证。在支持的加速器方面,NCCL是GPU加速的集体通信的工业事实标准,ROCm旨在为AMD GPU提供支持,而Intel oneCCL可以支持异构加速器。
第四个问题:当前的瓶颈是?
- 由于服务器配置和GPU作业调度等原因,GPU之间的通信瓶颈无法完全消除。网络协议也会影响扩展效率,因为与RDMA相比,TCP网络性能提升不明显。
- 也有研究人员认为网络速度本身并不是瓶颈,而是如何更有效地利用快速网络速度。网络速度是影响xCCL性能的一个重要因素,而现实世界中的xCCL设计是另一个因素。
当前,xCCL的趋势是采用更快的网络
最后,Related Work和结论就不整理了。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











