






链接:https://arxiv.org/abs/2207.11163 ICPR2022
Abstract
自监督在无人标注的表示学习中取得了巨大的成功,其主要的方法是对比学习。对比学习通常基于实例区分任务,意思就是个体样本被视为独立的类别。这就意味着所有样本是不同的,这与公开数据集中对相似样本的分组是相矛盾的。为了弥补这一差距,论文提出了自适应软对比学习(Adaptive Soft Contrastive Learning)
具体来说,ASCL将原始的实例判别任务转化为多实例的软判别任务,即instance discriminagtion task to multi-instance soft discrimination task,并自适应地引入样本间关系。
ASCL本质做的事情:utilize a sharpened inter-sample distribution to introduce extra positives and adaptively adjust its confidence based on the entropy of the distribution.
ASCL作为一个现有自监督学习框架的有效且简洁的插件模块,在各种测试上性能与效率都达到了最佳结果。
Introduction
前言概述
自监督学习通过标签无关的任务学习有意义的表示信息,在许多任务中达到接近甚至超过监督学习模型的性能。
早期的自监督学习方法通常基于启发式(heuristic)任务,如图像旋转角度的预测,而目前的主流方法一般是基于实例区分任务,即将每个单独的实例作为一个单独的语义类。这类方法通常共享相同的框架,称为对比学习。
对于特定实例的增强视图,将其定义为正样本视图,以及作为其它实例的负样本视图。并将正负样本间的距离最小化,负样本间的距离最大化。后续人们又做了大量的工作来改进这个框架,例如使用动量编码器等等。
论文主要解决对比学习的一个内在缺陷,即“class collision”。
对比学习的基本逻辑,即实例区分规则违反了视觉数据集的自然分组,这就会导致假负例的存在(SPCL也提到这一问题并给出解决方案),例如两张相似的狗图片(指不同的源图)应该彼此接近,而不是被模型错误地推开。为了解决这一问题,我们需要在对比学习中引入有意义的样本间(inter-sample)关系。
在介绍ASCL之前先举例其它为解决该问题所做的工作
去偏(Debiased)对比学习利用简化的数据集分布假设,提出了一种理论无偏的对比损失近似,然而它并没有真正解决假负例的问题。除此之外,有些模型会采用渐进式的识别机制并在训练阶段移除假负例。
NNCLR尝试在学习过的特征空间中对前k个进行排序和提取,为每个特定视图定义额外的正样本。
Co2引入了一致性正则化,加强了不同正样本视图对所有负样本视图的相对分布一致性。
基于聚类的方法也提供了额外的正样本,但假设整个聚类在训练早期是正样本,这种思路是有问题的,并且聚类有额外的计算成本。
此外这些方法都依赖于手动设置的阈值或预定义的邻域数量,而这些邻域数量通常是未知的或很难预先确定的。
ASCL的提出
论文提出了 ASCL,并重新制定对比学习问题,引入了自适应风格的样本间关系。为了提高训练的稳定性和样本间关系的准确性,使用弱增强(weak augmentation)视图计算相似度分布,并得到锐化后的软标签信息。
详细内容就是基于相似度分布的不确定性,自适应调整软标签的权重:在训练的早期,由于初始化是随机的,所以软标签的权重较低,模型的训练会类似于原来的对比学习。随着特征的成熟和软标签的集中,模型将学习到更强的样本间关系。
论文的主要贡献如下
- 提出了ASCL,该方法能够解决实例识别任务中的假负例问题,缩小基于实例的对比学习方法与基于聚类的对比学习方法之间的差距。
- 证明了无论是在ASCL方法中,还是在MoCo等经典对比框架中,弱增强策略都有助于稳定对比训练。
- 与论文中其他两种变体相比,实验表明ASCL在初始阶段保持了较高的学习速度。
- ASCL在各种基准测试中获得了最先进的结果。
Related Works
1.Early methods on self-supervised learning
大多数早期的自监督任务如jigsaw puzzles,patch localization,image inpainting,rotation prediction。然而这些预定义任务与后续任务(如图像分类)之间的关系不足,目前对比学习方法的性能大大优于这些任务。
2.Contrastive learning with instance discrimination
对比学习的思想首次由Hadsell等人提出,近年来作为主要的自监督学习方法,于是再次流行了起来,在许多数据集上取得了接近甚至超过完全监督方法的优异性能。
Examplear提出通过将每一张图像及其增强图作为为唯一的代理类,为包含K张图像的数据集构造K-way分类器,其解决了内存需求过多的问题。
MoCo是目前对比学习方法的一个重要基线,因为小批量的样本可能导致负样本对不足,该方法使用了memory bank,并提出了一个动量编码器实时更新memory bank。
SimCLR是另一个重要的基线,将mini-batch大小设置得足够大,以便消除对memory bank的需求。
也有一些模型探讨了无负样本的对比学习,例如BYOL提出了一个带有预测器的非对称网络结构,以避免在没有显式负样本的情况下模型崩溃。
SimSiam表明甚至不需要动量编码器,其本质是不带动量的BYOL。
3.Introducing inter-sample relations
探索如何将样本间关系引入到原始的实例区分任务中。
NNCLR建立在SimCLR的基础上,引入了一个memory bank,并搜索最近邻域样本来替换原来的正样本。
MeanShift基于上述相同的想法,只不过是建立在BYOL的基础上。
Co2提出了一个额外的正则化项,以确保正样本和负样本的相对一致性。
ReSSL验证了一致性正则化项本身足以学习有意义的表示。
Method
目前自监督学习方法主要关注实例识别任务,更具体地说,是将每个图像实例视为一个单独的语义类进行学习。
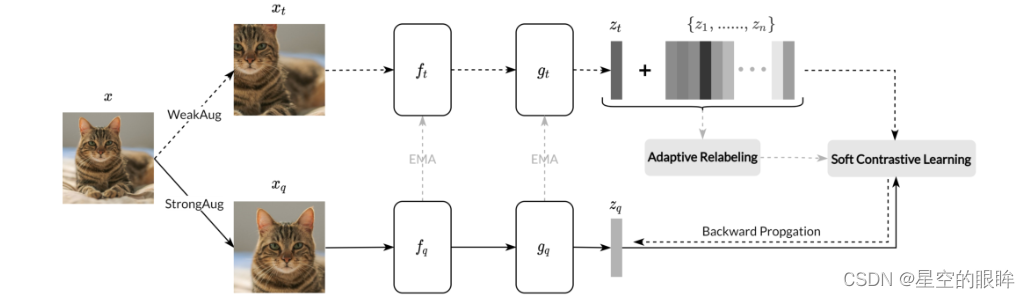
后续介绍遵循MoCo的相关结构:给定一个特定的图片x,生成两个不同的增强视图,分别作为查询xq和目标xt,然后将xq和xt分别输入至特征映射结构(encodr+projector),分别得到zq和zt,我们希望最小化zq和zt的距离,同时最大化zq和缓存在memory bank中{z1, …, zn}的距离。得到一个优化后的InfoNCE损失:
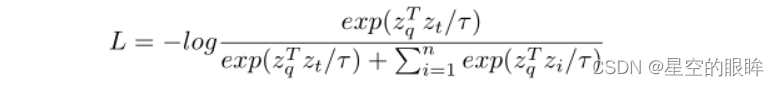
1.Soft contrastive learning
将zt和memory bank中的{z1, …, zn}合并为{z1’, …, zn‘,zn+1‘},或者记为{zt ,z1, …, zn}
并且将损失公式优化为:
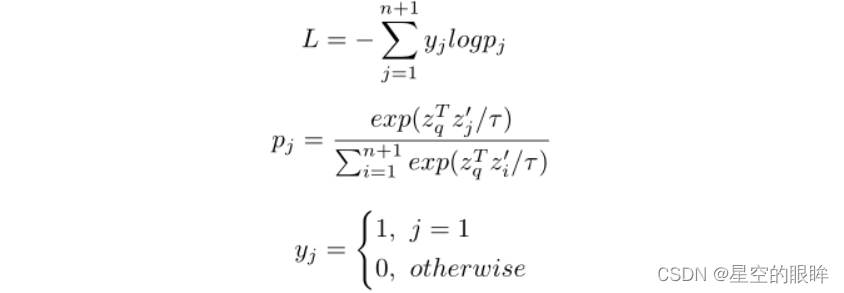
其中y = {y1,…yn+1}是one-hot伪标签(pseudo label),而p = {p1,…pn+1}为相应的预测概率向量。
回顾下监督学习,prediction overconfidence问题引出了对标签平滑(label smoothing)和知识蒸馏的研究。
类似地,在自监督学习中,由于个体样本之间的距离小于类别之间的距离,prediction overconfidence问题更加明显,特别是当数据集中存在重复样本或极其相似的样本时,即前面描述的假负例。
通过修改伪标签,特别是与其他样本相对的部分,可以将原来的对比学习问题转化为软对比学习问题。
2.Adaptive Relabelling
如前所述,InfoNCE中的伪标签忽略了样本间的关系,从而导致假负例。针对这一问题,论文提出了基于特征空间中相邻关系的伪标签修改方法。
首先计算encoder编码分支中的正样本z1’和在memory bank中的其它样本{z2’, …, zn‘,zn+1‘}的余弦相似度:
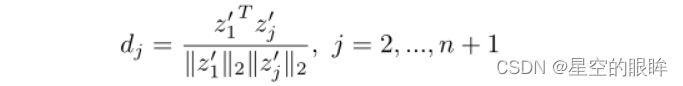
1)Hard relabelling:根据上述相似度公式计算的值进行排序,定义memory bank中前k个样本,分别与zq构成额外正样本对。新的伪标签yhard的定义如下:
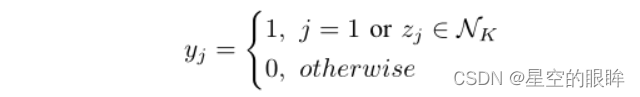
2)Adaptive hard relabelling:上述方法较为’‘粗鲁‘’地将memory bank中前k个样本视为正样本,这是不太精确的做法,特别是在训练的早期,此时memory bank中的样本量过少。针对该问题,论文提出了一种自动修改伪标签置信度的自适应机制。更具体点,使用余弦相似度dj来构建原正样本z1‘和在memory bank中的其它样本{z2’, …, zn‘,zn+1‘}之间的相对分布qj,具体表示如下:
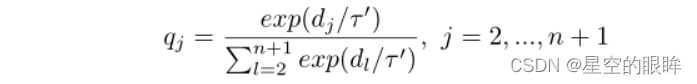
为了量化相对分布的不确定性,应该将置信度定义为分布的归一化熵:
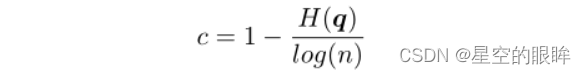
H(q)指q的Shannon熵,并进一步用log(n)将c归一化为[0,1],然后将yhard与c相加得到自适应硬标签yahcl
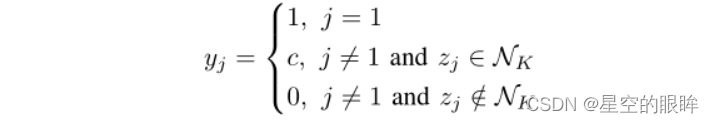
3)Adaptive soft relabelling:使用分布q本身作为软标签,而不是使用top-K邻域作为额外的正样本。换句话说,越集中的分布产生的置信度越高,意味着样本的邻接关系越可靠。得到自适应软标签yascl
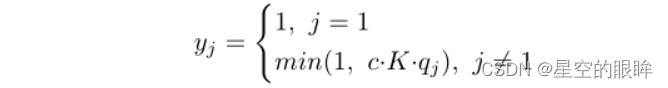
注:c为软标签的权重,K为top-k领域数。min式子中还设置了上限1,这指的是memory bank中即使置信度最高的样本也不会比原正样本z1‘获得的置信度高。
最后将yascl,yahcl,yhard都进行归一化。为了方便,我们对规范化伪标签使用与非规范化伪标签相同的表示法。
默认情况下,使用yascl进行训练,也就是所谓的ASCL方法。将使用yahcl的训练方法称为AHCL,将使用yhard的训练方法称为Hard。当设K为零时,该方法退化为原来的MoCo框架。
3.Distribution sharpening
InfoNCE损失公式中的温度参数τ是用来控制学习到的表示的密度。受当前半监督学习工作的相关启发,即为了过滤特征空间中可能的噪声关系,我们为相对分布q设置了一个比Soft Contrastive Learning中τ更小的温度τ’
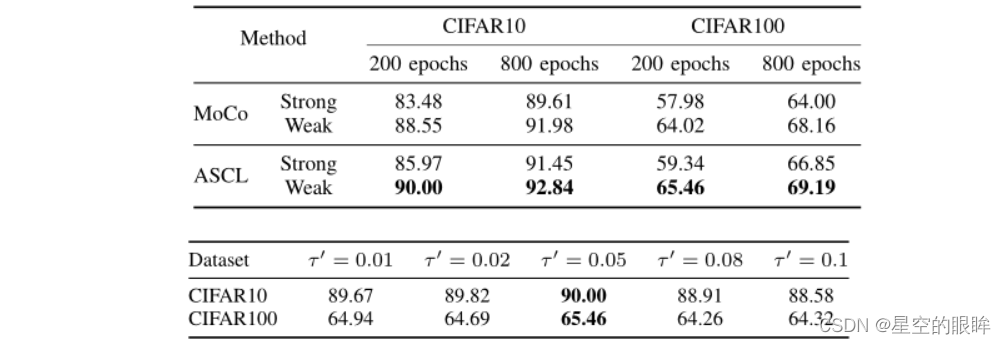
注:默认设置τ=0.1,τ‘=0.05
4.Augmentation strategies
在MeanShift和ReSSL的启发下,论文还探索了ASCL的不同增强策略。直观地看,强增强样本在描述样本间关系时具有更大的随机性和更大的误差,而弱增强的使用会导致更纯粹的最近邻关系,从而使训练更稳定。
注:ASCL对momentum encoder和memory bank使用弱增强,对encoder使用强增强。
5.ASCL without negative samples and memory bank
探讨不使用memory bank或显示负例的对比学习框架中使用ASCL。
更具体点,为了说明ASCL是一个灵活的框架,论文还将ASCL与BYOL进行了相关应用。
原BYOL使用一个额外的predictor h,然后通过加器h(zq)和zt之间的一致性学习。此处,考虑一个batch中的所有样本,根据样本的距离来进行软标记,并根据软标记进行后续的优化
BYOL使用一个额外的预测器h,并通过加强h(zq)和zt之间的一致性进行学习。我们扩展了这一点,考虑批次中的所有样品,根据与问题样品的距离软标记它们,并根据软标记进行优化一致性。
Experimental Results
Experiment settings
1)datasets
CIFAR10/100,STL10,Tiny ImageNet,ImageNet-1k
2)Implementation details
对于小规模数据集如CIFAR10/100,STL10和Tiny ImageNet,使用ResNet-18作为骨干,为了适应低分辨率的图像,修改ResNet-18的结构(修改第一卷积层和去除最大池化层),对于ImageNet-1k则使用ResNet-50作为骨干。
对于小规模数据集,将memory bank大小设置为4096,而ImageNet-1k设置为65536
momentum encoder的动量设置为0.99
对于数据增强,应用了强增强,包括随机调整的缩放,水平翻转(p=0.5),颜色失真(s=0.8),高斯模糊(p=0.5)以及灰度(p=0.2);对于弱增强,只保留随机调整的作物和水平翻转。
对于模型超参数,默认设置K = 1,τ=0.1,τ’=0.05
对于优化器和学习率,使用SGD优化器训练网络200个周期,动量为0.9,权值衰减为1e-4,初始学习率为0.06,由cosine schedule来控制,batch大小固定为256
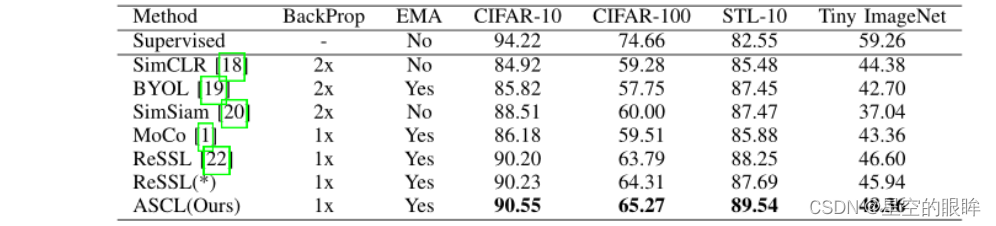
Results on small-scale and medium-scale datasets
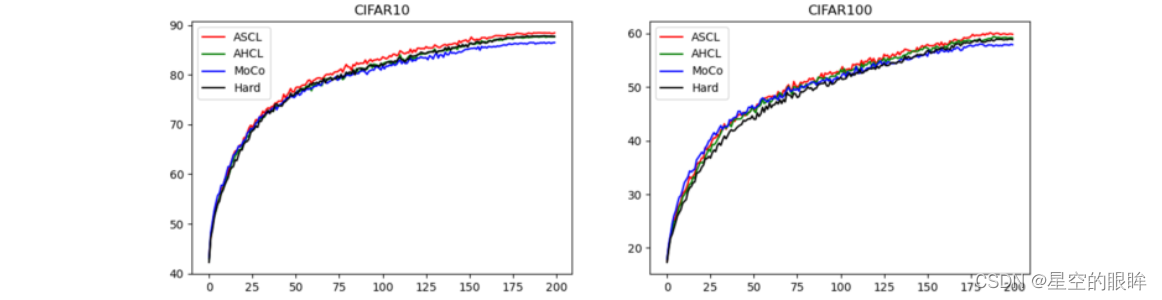
Ablations study
详细见原论文,此处贴出部分结果图。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









