






论文链接:https://arxiv.org/abs/2207.08220 ECCV 2022
Abstract
基于对比的自监督学习方法近年来取得了巨大成功,但是自监督训练想要获得不错的结果需要很长的训练时间,例如MoCo v3需要800epochs。
本论文重新审视了基于动量的对比学习框架,并发现两个增强视图仅产生一个正样本对的低效性。
于是论文提出了一种fast-moco模型,其可以随机组合patches对应特征,通过组合特征来构建多个正样本对。从而使得该模型能够提供大量的监督信息,带来显著的加速。注:patch是什么,以及具体如何组合等后续会说。
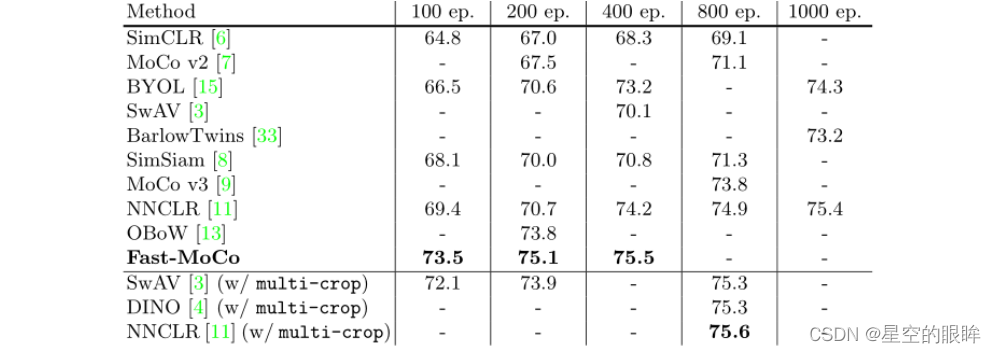
fast-moco仅训练100轮就可以达到同moco v3训练800轮的准确度,即73.5%,并且如果在此基础上fast-moco再训练200轮,可以将准确度提升至75.1%
Introduction
对比学习模型常常选择使用momentum encoder、predictor、stop-grad等工具使模型上下分支不对称,从而使得输入的样本增强数据获得不同的特征表示,以便为架构设计提供更大的灵活性。
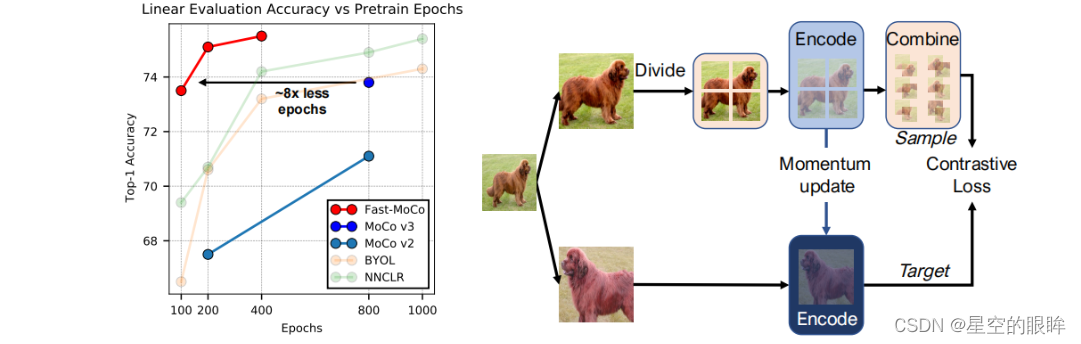
前面说过传统对比模型需要极长的时间来训练(通常800epochs),当处理大型工业数据集时,将会带来极其高额的训练成本。为了加速训练,论文发现了基于动量的对比学习方法的一个局限性:two-image-one-pair strategy
该局限性具体来说就是:一张图片的两个增强数据图经过深层模型后得到的特征,仅仅作为一对来用于对比学习。尽管对称损耗设计通常用于提高采样效率,但论文认为two-image-one-pair strategy机制是次优的,即认为这种特性可以不使用,后续进行优化。
为了解决上述局限性,论文提出了组合切片(combinatorial patches),一种对图片的局部特征任意组合,高效生成组合特征的机制。在这种方法下,增强图像对可用于生成多个正样本对进行对比学习。
解决上述局限性的具体措施是Divide-Encode-Combine and then Contrast pipeline模式,
具体细节如下:
1.在数据准备阶段,将输入(数据增强图)划分为多个不重叠的局部patch
2.并分别用深度模型对局部patch进行编码
3.然后合并多个patch的编码特征
4.最后再计算出对比损失
Related Works
1.Patch Based Representation Learning
合并patches的一种常见方法是分别对它们进行编码,例如 Jigsaw Clustering方法。该方法同时对多个patch进行编码:对每个patch进行独立的扩增和拼接,形成一个新的图像用于编码,然后对编码后的特征进行空间分离以及池化,得到每个patch的嵌入特征。
无论使用哪种方式,编码后的嵌入特征可用于拼图、对比预测或词句重建。例如ViT encoder, BEiT, MAE等方法,它们将图像分割成一个由patches组成的网格,并屏蔽其中的一些patches,收集其余的patches并得到编码嵌入。
然而,这些方法并没有从组合patches中构建多对样本,因此与Divide-Encode-Combine模式不同。
2.Contrastive Learning
基于动量的对比学习方法采用非对称分支结构,在online分支上,输入的增强数据被送入编码器中,而在target分支上,原图的另一个增强数据被送入momentum编码器中。最后根据上下分支输出的编码向量形成一对进行对比学习。以上都是传统MoCo使用的方法。
在论文中,fast-moco使用了two-image-one-pair strategy机制,即在一个batch中生成更多的样本对,以提高模型速度。
Method
首先给出传统MoCo的基本情况,作为基准。然后引入combinatorial patches的设计。最后讨论所提出的方法将如何影响性能和计算。
1.Preliminaries about MoCo
略,详细可见如下论文:
MoCo:https://arxiv.org/abs/1911.05722
MoCo v2:https://arxiv.org/abs/2003.04297
MoCo v3:https://arxiv.org/abs/2205.13137
2.Fast-MoCo
Fast-MoCo主要由如下步骤构成:
- 划分步骤,将online分支中的输入图像划分为多个patch
- 编码步骤,编码器f对patch的特征进行单独编码
- 合并步骤,将编码后的特征进行组合(在神经网络的最后一层)
- 将组合特征分别输入projector g以及predictor q
- 最后计算对比损失
具体模型图如下:
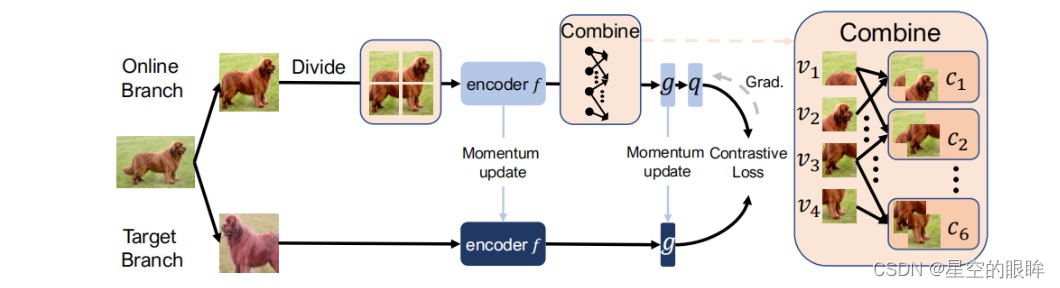
如果以MoCo v3为基准,Fast-MoCo只做了三处修改:
- 添加一个Divide步骤,将图像分成多个patch,然后将patch输入online分支的编码器
- 在编码器后面插入一个Combine步骤
- 稍微修改了与Divide and Combine操作相对应的正负样本对的定义
下面将详细说明Divide步骤、Combine步骤和修改后的损失函数:
1.Divede step
对于online分支,不像以往直接将图像的增强数据输入encoder,而是先将其分为mxm网格大小的patches,记为{xp|p∈{1,…,m2}},下标p表示为patches索引集{p}
2.Combine step
将每个patch送入encoder得到对应的特征(encoded embedding),但不是单独利用每个patch对应的特征,而是将多个patch生成的对应特征vp合并为特征c,然后将合并后的特征进行后续projector处理以及predictor处理。
注:多个指随机数量,小于m2
虽然可以有不同的方法(例如连接或求和)来合并多个特征,但根据经验发现,对所选特征进行平均处理就可以得到较高的计算效率。即上述的合并是指一种过程,它可以是求和,也可以是求平均。
注:在后文的分析阶段,还引入了其它方法,如加权平均等。
注:记vpn = {vp|p∈pn},合并方法对应的平均公式为c = ∑p∈pnvp / n
为了提高样本利用率,我们将所有可能的组合特征,记为组合特征的集合{ci|i∈{1,…,cm2n}},即m2个patch对应的特征中随机选取n个进行组合。
上述方式中,我们就可以通过平均运算来产生大量的样本,而额外的开销可以忽略不计,并且由于组合的patch特征只覆盖了部分图像信息,所以可以保证样本和目标有足够的信息缺口。
Combine步骤之后,online分支中的projector和predictor按顺序将每个组合特征c投影到另一个空间,从而得到若干个向量zo,另一方面,target分支以MoCo v3相同的方式将另一个数据增强图映射到zt,然后它们被L2归一化并用于后续的对比损失计算。
3.Loss Functions
与MoCo v3一样,仍然利用对比损失来优化encoder、projector和predictor。
与MoCo v3相比,FastMoCo没有额外需要学习的参数,唯一区别是有Cm2n个组合特征经过projector和predictor得到若干个向量zo,而不是像传统MoCo中一个图像生成的两个数据增强图形成的zo与zt。
我们直接调整以往的对比损失函数,将online分支得到的若干向量zo两两组成正样本对,同时进行对比损失计算并取平均值,然后将online分支中的向量zo与target分支中其他图片的zt作为负样本对。
3.Discussion
FastMoCo收敛速度更快的主要原因是利用大量随机组合patch生成的特征,其显著增加了正样本对的数量。
以m=2和n=2为例,FastMoCo将online分支的输入图像分成mxm=4个patch,然后4个patch得到4个特征,根据4个特征可以组合成6种合并特征c,因为n=2,故每个合并特征由2个特征组成,这样可以直接将正对的数量扩大到MoCo v3的6倍。
因此与MoCo v3相比,Fast-MoCo可以在每次迭代中获得更多的监督信号,从而在迭代次数较少的情况下获得良好的性能。这就是Combinatorial Patches的核心思想。
同时,Fast-MoCo中引入了其它操作,例如将一幅图像划分为多个patch,并对几个patch的表示进行平均,由于过程简单,其额外的计算量可以忽略不计。
主要增加的计算成本是patches对应特征的组合,得到的合并特征通过online分支中 projector和 predictor,但是这些过程只涉及基本的线性变换,与主干算法相比,基本的线性变换开销很小。因此与MoCo相比,Fast-MoCo的总开销占额外训练时间的7%
此外,由于组合特征只包含整个图像中的一部分信息,将组合的部分patch拉向包含整个图像信息的目标视图比拉原始图像对更具挑战性,隐式增加了网络结构的不对称性,这已经被证明有利于增加特征表示的丰富度,提高自监督学习性能。
综上:由于这些优点,Fast-MoCo可以在边际额外计算成本的情况下获得较高的样本利用率,从而在较短的训练时间内获得较好的性能
Experimental Results
1.Implementation Details
编码器encoder是一个ResNet-50网络,不包括分类层。在SimSiam和MoCo v3之后,projector与predictor均是MLP层,对于自监督训练过程,我们采取batch大小为512,momentum为0.9,weight decay为1e-4的SGD优化器,学习率为从0.1到0的cosine schedule,并且lr为0.025时变为warm up epoch
2.Results
Analysis
1.Same or Different Augmented Views
对比方法对数据增强方法很敏感,尤其是空间变换过程。与具有不同增强视图的常规设置相比,该论文对应的实验观察到,如果正样本对来自同一增强视图,当使用相同的增强视图时,patch中有害的非语义信息会暴露在它的对比目标面前,导致准确率显著下降。
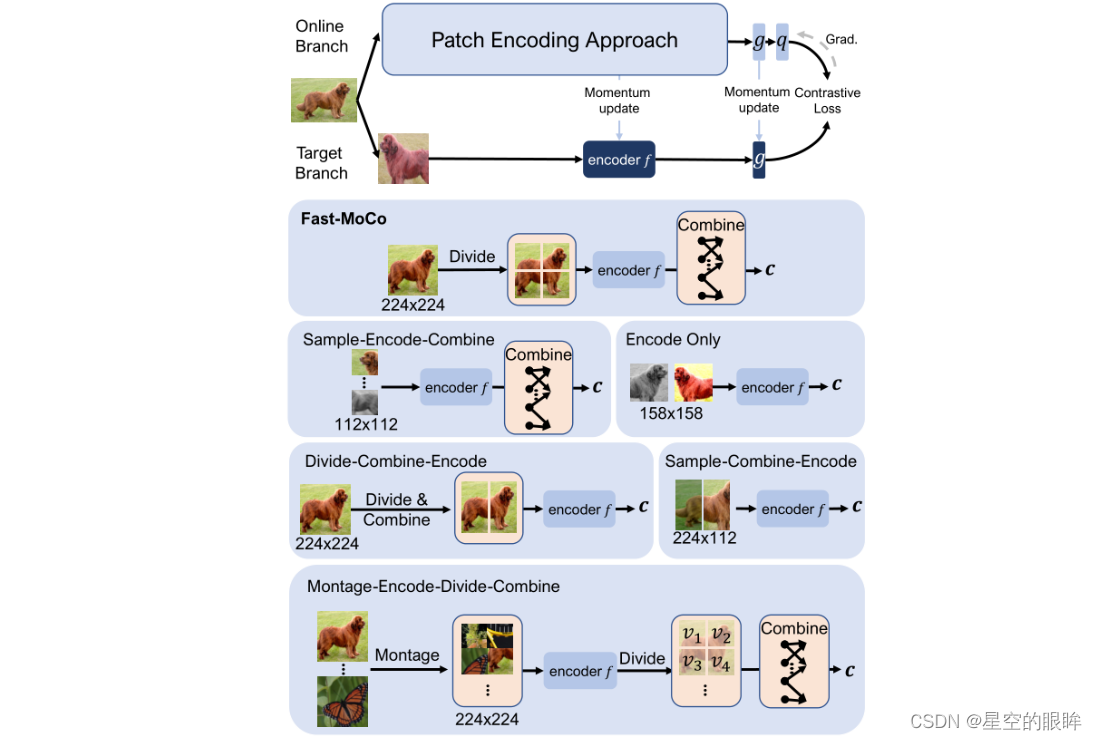
2.Comparison on Patch Encoding Approaches
详细见原论文。
3.Relationship with Multi-Crop
Multi-Crop方法出自SwAV:以往的对比学习方法都是在一张256×256的图片上使用两个224×224的crop求两个正样本,但是由于crop过大,所选取的crop都是基于全局特征的。因为很多局部特征才是非常有价值的,于是SwAV使用了一种multi-crop的思路进行操作,即选择了两个160×160的crop去搞定全局特征,选择四个96×96的crop去搞定局部特征。这样在计算量变化不大的情况下,可以获取更多的正样本。
4.Ablation on Fast-MoCo
消融实验见原论文。
5.Combination Method
之前在Method中指出可以使用平均的方法,现虑两种方案:加权平均和最大运算合并。
Weighted Average:考虑从2×2划分的patch中合并两个patch,其分别为p,p0,二者对应的特征为vp,vp0,从而可以计算组合特征c = γ*vp + (1 − γ) *vp0,
Max Operation:即根据若干patch对应的特征取最大的那个作为组合特征c = max{vp,vp0}
Algorithm
# f_o: online branch networks [encoder, projector, predictor]
# f_t: target branch networks [encoder, projector]
# a: exponential moving average momentum \alpha, t: temperature \tau
# combine: generate all possible 2-combinations between patch embeddings
for x in loader: # load a minibatch
x1, x2 = aug(x), aug(x) # augemtation, NxCxHxW
x1_d, x2_d = divide(x1), divide(x2) # Divide step, 4NxCx(H/2)x(W/2)
v1, v2 = f_o[0](x1_d), f_o[0](x2_d) # online branch encode
c1, c2 = combine(v1), combine(v2) # Combine step
z1_c, z2_c = f_o[1:](c1), f_o[1:](c2) # project & predict
z1, z2 = f_t(x1), f_t(x2) # target branch encode & project
loss = (ctr(z1_c, z2) + ctr(z2_c, z1)) / 2
loss.backward()
# weight update
update(f_o.params)
f_t.params = a * f_t.params + (1-a) * f_o[:2].params
def ctr(z_c, z):
z_c, z = normalize(z_c, dim=1), normalize(z, dim=1) # l2-normalize
z_c = z_c.split(z.size(0))
# calculate loss for each of the 6 combined samples
loss = 0
for _z in z_c:
logits = mm(_z, z.t())
loss += CorssEntropyLoss(logits/t, labels)
# positive pairs are sourced from the same instance
return loss /= len(z_c)















 343
343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









