









隐马尔可夫模型(HMM)实现命名实体识别(NER)
一、命名实体识别(Named Entity Recognition,NER)
识别文本中具有特定意义的实体,包括人名、地名、机构名、专有名词等等
在使用的NER数据集中包含七个标签:
- “B-ORG” : 组织或公司(organization)
- “I-ORG” : 组织或公司
- “B-PER” : 人名(Person)
- “I-PER” : 人名
- “O” : 其他非实体(other)
- “B-LOC” : 地名(location)
- “I-LOC” : 地名
文本中以每一个字为单位,每一个字对应上面的任一种标签。
标签前面有分为B和I,"B"表示begin,实体开头的那个字,在实体中间或者结尾部分,,用”I“来标注。
例如:自(B-PER)贸(I-LOC)区(I-LOC),这是一个错误的标注,原因是我们以(B-PER)开头,那么后面的应该是I-PER类型,而不是其他类型。
由此,我们可以发现,仅仅采用语言模型(Bert 或者 LSTM)进行标注的话会产生很多的错误标注,我们需要在语言模型后加上概率图模型(条件随机场)由来约束模型的 输出,从而达到防止输出不合法的标注。
二、一个栗子
采用训练好的隐马尔可夫模型进行实体标注
from HMM_model import *
model = HMM_NER(char2idx_path="./dicts/char2idx.json",
tag2idx_path="./dicts/tag2idx.json")
model.fit("./corpus/train_data.txt")
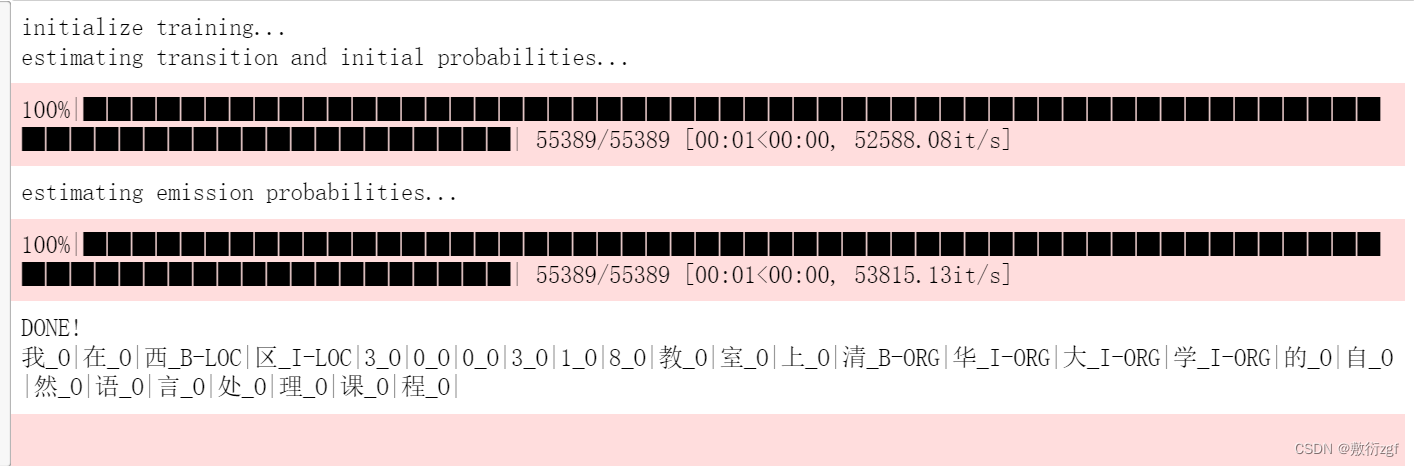
model.predict("我在西区300318教室上清华大学的自然语言处理课程")
识别人名
text = "张吉惟、林国瑞、林玟书、林雅南、江奕云、刘柏宏、阮建安、林子帆"
model.predict(text)

三、什么是隐马尔可夫模型
隐马尔可夫模型又称隐马模型又称HMM,是概率图模型之一,我们常见的贝叶斯模型也是概率图模型之一。
HMM属于生成模型,上面描述的BIO实体标签就是一个不可观测的隐藏状态,而HMM模型描述的就是由这些隐藏状态序列(实体标记)生成可观测结果(可读文本)的过程。
例如
隐藏状态序列: B-ORG | I-ORG | I-ORG | I-ORG |
观测结果序列: 清 华 大 学
假设可观测状态序列是由所有汉字组成的集合,用 𝑉𝑂𝑏𝑠𝑒𝑣𝑎𝑡𝑖𝑜𝑛 来表示:
𝑉𝑂𝑏𝑠𝑒𝑣𝑎𝑡𝑖𝑜𝑛 ={v1,v2,… ,vM} v表示字典中的单个字,假设已知字数为M
假设所有可能的隐藏状态集合为 𝑄ℎ𝑖𝑑𝑑𝑒𝑛 , 一共有 𝑁 种隐藏状态, 例如现在的命名实体识别数据里面只有7种标签: 𝑄ℎ𝑖𝑑𝑑𝑒𝑛 = {q1,q2, … ,qN}
假设有观测到的一串自然语言序列文本 𝑂 , 一共有 𝑇 个字, 又有这段观测到的文本所对应的实体标记, 也就是隐状态 𝐼 : 𝐼 = {i1,i2,… ,iT}(隐状态)
O = {o1,o2,… ,oT}(观测)
上述式子中常称 𝑡 为时刻, 如上式中一共有 𝑇 个时刻( 𝑇 个汉字).
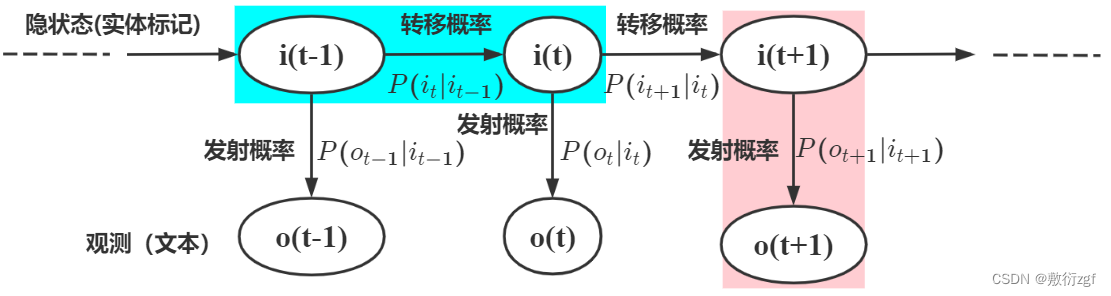
HMM模型有两个基本假设: 灰常重要!!!
1. 第 𝑡 个隐状态(实体标签)只跟前一时刻的 𝑡−1 隐状态(实体标签)有关, 与除此之外的其他隐状态无关.
例如上图中: 蓝色的部分指的是 𝑖𝑡 只与 𝑖𝑡−1 有关, 而与蓝色区域之外的所有内容都无关, 而 𝑃(𝑖𝑡|𝑖𝑡−1) 指的是隐状态 𝑖 从 𝑡−1 时刻转向 𝑡 时刻的概率
2. 观测独立的假设, HMM模型中是由隐状态序列(实体标记)生成可观测状态(可读文本)的过程, 观测独立假设是指在任意时刻观测 𝑜𝑡 只依赖于当前时刻的隐状态 𝑖𝑡 , 与其他时刻的隐状态无关.
例如上图中: 粉红色的部分指的是 𝑖𝑡+1 只与 𝑜𝑡+1 有关, 跟粉红色区域之外的所有内容都无关。
四、HMM模型的参数
1. HMM的转移概率(transition probabilities):
我们上面提到了 𝑃(𝑖𝑡|𝑖𝑡−1) 指的是隐状态 𝑖 从 𝑡−1 时刻转向 𝑡 时刻的概率, 比如说我们现在实体标签一共有 7 种, 也就是 𝑁=7 (注意 𝑁 是所有可能的实体标签种类的集合), 也就是 𝑄ℎ𝑖𝑑𝑑𝑒𝑛={𝑞0,𝑞1,…,𝑞6} (注意我们实体标签编号从 0 算起), 假设在 𝑡−1 时刻任何一种实体标签都可以在 𝑡 时刻转换为任何一种其他类型的实体标签, 则总共可能的转换的路径一共有 𝑁2 种, 所以我们可以做一个 𝑁∗𝑁 的矩阵来表示所有可能的隐状态转移概率.
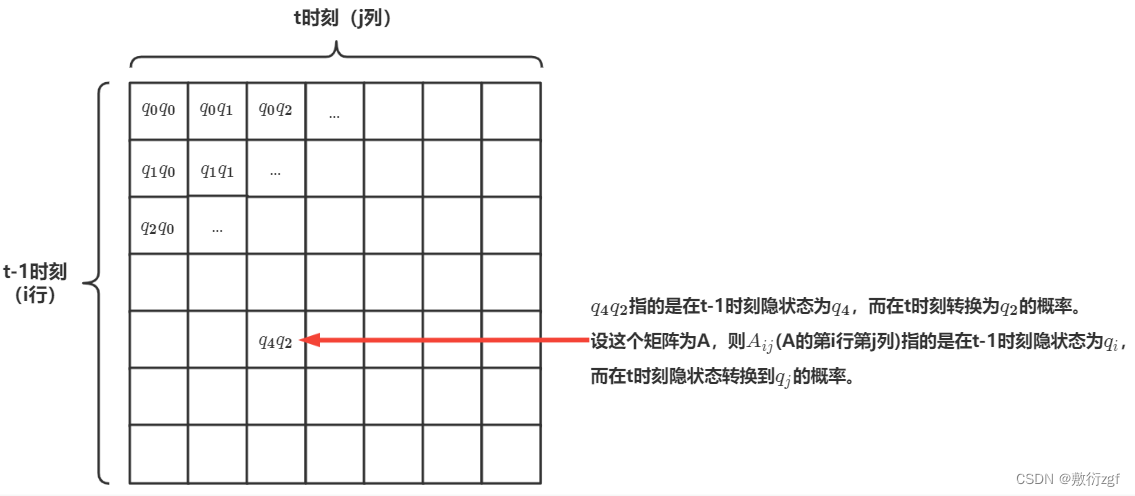
𝐴𝑖𝑗=𝑃(𝑖𝑡=𝑞𝑗|𝑖𝑡-1=𝑞𝑖)𝑞𝑖∈𝑄ℎ𝑖𝑑𝑑𝑒𝑛
对A矩阵的每一行求和概率之和为1
2. HMM的发射概率(emission probabilities):
我们上面提到任意时刻观测 𝑜t只依赖于当前时刻的隐状态 𝑖𝑡 , 也就是 𝑃(𝑜𝑡|𝑖𝑡) , 也叫做发射概率, 指的是隐状态生成观测结果的过程. 设字典里有 𝑀 个字, 𝑉𝑜𝑏𝑠.={𝑣0,𝑣1,…,𝑣𝑀−1} (注意这里下标从0算起, 所以最后的下标是 𝑀−1 , 一共有 𝑀 种观测), 则每种实体标签(隐状态)可以生成 𝑀 种不同的汉字(也就是观测), 这一过程可以用一个发射概率矩阵来表示, 他的维度是 𝑁∗𝑀 .
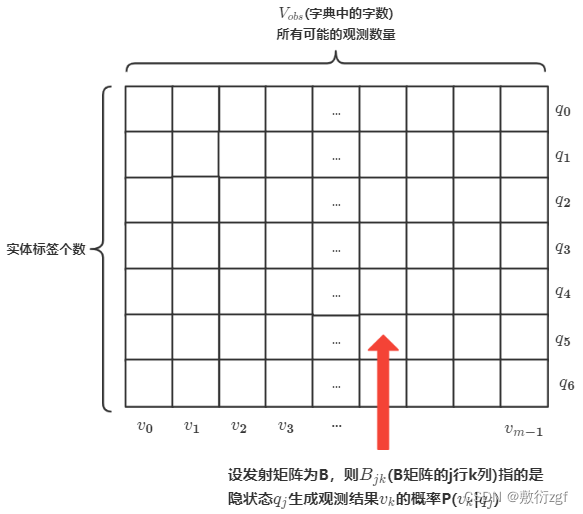
𝐵𝑗𝑘=𝑃(𝑜𝑡=𝑣𝑘|𝑖𝑡=𝑞𝑗) 𝑞𝑖∈𝑄ℎ𝑖𝑑𝑑𝑒𝑛 𝑣𝑘∈𝑉𝑜𝑏𝑠={𝑣0,𝑣1,…,𝑣𝑀−1}
3. HMM的初始隐状态概率:( 𝑖𝑛𝑖𝑡𝑖𝑎𝑙 𝑝𝑟𝑜𝑏𝑎𝑏𝑖𝑙𝑖𝑡𝑖𝑒𝑠)
通常用 𝜋 来表示, 注意这里可不是圆周率:
𝜋=𝑃(𝑖1=𝑞𝑖) 𝑞𝑖∈𝑄ℎ𝑖𝑑𝑑𝑒𝑛={𝑞0,𝑞1,…,𝑞𝑁−1}
上式指的是自然语言序列中第一个字 𝑜1 的实体标记是 𝑞𝑖 的概率, 也就是初始隐状态概率.
五、用HMM解决序列标注问题(HMM的学习算法)
我们现在已经了解了HMM的三大参数 𝐴, 𝐵, 𝜋 , 假设我们已经通过建模学习, 学到了这些参数, 得到了模型的概率, 我们怎么使用这些参数来解决序列标注问题呢?
假设目前在时刻 𝑡 , 我们有当前时刻的观测到的一个汉字 𝑜𝑡=𝑣𝑘 (指的第 𝑡 时刻观测到 𝑣𝑘汉字), 假设我们还知道在 𝑡−1 时刻(前一时刻)对应的实体标记类型 𝑖𝑡−1=𝑞̂𝑡−1𝑖 (指的 𝑡−1 时刻标记为 𝑞̂𝑡−1𝑖 ). 我们要做的仅仅是列举所有 𝑖𝑡 可能的实体标记 𝑞̂ 𝑡𝑗, 并求可以使下式输出值最大的那个实体类型 𝑞𝑡𝑗 (也就是隐状态类型):
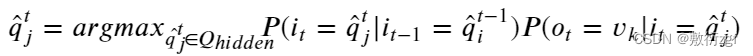
将所有 𝑡 时刻当前可取的实体标签带入下式中, 找出一个可以使下式取值最大的那个实体标签作为当前字的标注:
𝑃(当前可取实体标签|上一时刻实体标签)𝑃(测到的汉字|当前可取实体标签)
注意: 这里只讲到了怎样求第 𝑡 时刻的最优标注, 但是在每一时刻进行这样的计算, 并不一定能保证最后能得出全局最优序列路径, 例如在第 𝑡 时刻最优实体标签是 𝑞𝑗 , 但到了下一步, 由于从 𝑞𝑗 转移到其他某些实体标签的转移概率比较低, 而降低了经过 𝑞𝑗的路径的整体概率, 所以到了下一时刻最优路径就有可能在第 𝑡 时刻不经过 𝑞𝑗 了, 所以每一步的局部最优并不一定可以达成全局最优, 所以之后会用到维特比算法来找到全局最优的标注序列.
HMM参数学习(监督学习): 要用HMM解决的是序列标注问题, 所以解决的是监督学习的问题. 也就是说现在有一些文本和与之对应的标注数据, 要训练一个HMM来拟合这些数据, 以便之后用这个模型进行数据标注任务, 最简单的方式是直接用极大似然估计来估计参数:
1. 初始隐状态概率 𝜋 的参数估计:
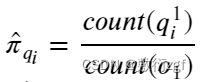
上式指的是, 计算在第 1 时刻, 也就是文本中第一个字, 𝑞1𝑖 出现的次数占总第一个字 𝑜1 观测次数的比例, 𝑞1𝑖上标1指的是第1时刻, 下标 𝑖 指的是第 𝑖 种标签(隐状态), 𝑐𝑜𝑢𝑛𝑡 是的是记录次数.
2. 转移概率矩阵 𝐴 的参数估计:
之前提到过 𝑡𝑟𝑎𝑛𝑠𝑖𝑡𝑖𝑜𝑛 𝑚𝑎𝑡𝑟𝑖𝑥 里面 𝐴𝑖𝑗 (矩阵的第i行第j列)指的是在 𝑡 时刻实体标签为 𝑞𝑖 , 而在 𝑡+1 时刻实体标签转换到 𝑞𝑗 的概率, 则转移概率矩阵的参数估计相当与一个二元模型 𝑏𝑖𝑔𝑟𝑎𝑚 , 也就是把所有的标注序列中每相邻的两个实体标签分成一组, 统计他们出现的概率:
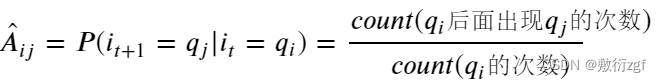
3. 发射概率矩阵 𝐵 的参数估计:
我们提到过 𝑒𝑚𝑖𝑠𝑠𝑖𝑜𝑛 𝑚𝑎𝑡𝑟𝑖𝑥 中的 𝐵𝑗𝑘 (矩阵第j行第k列)指的是在 𝑡 时刻由实体标签(隐状态) 𝑞𝑗 生成汉字(观测结果) 𝑣𝑘 的概率.
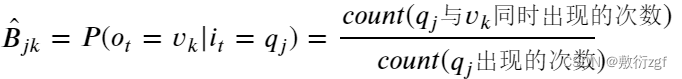
综上,根据上面的方式得到模型的参数 𝐴, 𝐵, 𝜋 的估计.
六、代码实现
import numpy as np
from utils import *
from tqdm import tqdm
class HMM_NER:
def __init__(self, char2idx_path, tag2idx_path):
# 载入一些字典
# char2idx: 字 转换为 token
self.char2idx = load_dict(char2idx_path)
# tag2idx: 标签转换为 token
self.tag2idx = load_dict(tag2idx_path)
# idx2tag: token转换为标签
self.idx2tag = {v: k for k, v in self.tag2idx.items()}
# 初始化隐状态数量(实体标签数)和观测数量(字数)
self.tag_size = len(self.tag2idx)
self.vocab_size = max([v for _, v in self.char2idx.items()]) + 1
# 初始化A, B, pi为全0
self.transition = np.zeros([self.tag_size,
self.tag_size])
self.emission = np.zeros([self.tag_size,
self.vocab_size])
self.pi = np.zeros(self.tag_size)
# 偏置, 用来防止log(0)或乘0的情况
self.epsilon = 1e-8
def fit(self, train_dic_path):
"""
fit用来训练HMM模型
:param train_dic_path: 训练数据目录
"""
print("initialize training...")
train_dic = load_data(train_dic_path)
# 估计转移概率矩阵, 发射概率矩阵和初始概率矩阵的参数
self.estimate_transition_and_initial_probs(train_dic)
self.estimate_emission_probs(train_dic)
# take the logarithm
# 取log防止计算结果下溢
self.pi = np.log(self.pi)
self.transition = np.log(self.transition)
self.emission = np.log(self.emission)
print("DONE!")
def estimate_emission_probs(self, train_dic):
"""
发射矩阵参数的估计
estimate p( Observation | Hidden_state )
:param train_dic:
:return:
"""
print("estimating emission probabilities...")
for dic in tqdm(train_dic):
for char, tag in zip(dic["text"], dic["label"]):
self.emission[self.tag2idx[tag],
self.char2idx[char]] += 1
self.emission[self.emission == 0] = self.epsilon
self.emission /= np.sum(self.emission, axis=1, keepdims=True)
def estimate_transition_and_initial_probs(self, train_dic):
"""
转移矩阵和初始概率的参数估计, 也就是bigram二元模型
estimate p( Y_t+1 | Y_t )
:param train_dic:
:return:
"""
print("estimating transition and initial probabilities...")
for dic in tqdm(train_dic):
for i, tag in enumerate(dic["label"][:-1]):
if i == 0:
self.pi[self.tag2idx[tag]] += 1
curr_tag = self.tag2idx[tag]
next_tag = self.tag2idx[dic["label"][i+1]]
self.transition[curr_tag, next_tag] += 1
self.transition[self.transition == 0] = self.epsilon
self.transition /= np.sum(self.transition, axis=1, keepdims=True)
self.pi[self.pi == 0] = self.epsilon
self.pi /= np.sum(self.pi)
def get_p_Obs_State(self, char):
# 计算p( observation | state)
# 如果当前字属于未知, 则讲p( observation | state)设为均匀分布
char_token = self.char2idx.get(char, 0)
if char_token == 0:
return np.log(np.ones(self.tag_size)/self.tag_size)
return np.ravel(self.emission[:, char_token])
def predict(self, text):
# 预测并打印出预测结果
# 维特比算法解码
if len(text) == 0:
raise NotImplementedError("输入文本为空!")
best_tag_id = self.viterbi_decode(text)
self.print_func(text, best_tag_id)
def print_func(self, text, best_tags_id):
# 用来打印预测结果
for char, tag_id in zip(text, best_tags_id):
print(char+"_"+self.idx2tag[tag_id]+"|", end="")
def viterbi_decode(self, text):
"""
维特比解码, 详见视频教程或文字版教程
:param text: 一段文本string
:return: 最可能的隐状态路径
"""
# 得到序列长度
seq_len = len(text)
# 初始化T1和T2表格
T1_table = np.zeros([seq_len, self.tag_size])
T2_table = np.zeros([seq_len, self.tag_size])
# 得到第1时刻的发射概率
start_p_Obs_State = self.get_p_Obs_State(text[0])
# 计算第一步初始概率, 填入表中
T1_table[0, :] = self.pi + start_p_Obs_State
T2_table[0, :] = np.nan
for i in range(1, seq_len):
# 维特比算法在每一时刻计算落到每一个隐状态的最大概率和路径
# 并把他们暂存起来
# 这里用到了矩阵化计算方法, 详见视频教程
p_Obs_State = self.get_p_Obs_State(text[i])
p_Obs_State = np.expand_dims(p_Obs_State, axis=0)
prev_score = np.expand_dims(T1_table[i-1, :], axis=-1)
# 广播算法, 发射概率和转移概率广播 + 转移概率
curr_score = prev_score + self.transition + p_Obs_State
# 存入T1 T2中
T1_table[i, :] = np.max(curr_score, axis=0)
T2_table[i, :] = np.argmax(curr_score, axis=0)
# 回溯
best_tag_id = int(np.argmax(T1_table[-1, :]))
best_tags = [best_tag_id, ]
for i in range(seq_len-1, 0, -1):
best_tag_id = int(T2_table[i, best_tag_id])
best_tags.append(best_tag_id)
return list(reversed(best_tags))
if __name__ == '__main__':
model = HMM_NER(char2idx_path="./dicts/char2idx.json",
tag2idx_path="./dicts/tag2idx.json")
model.fit("./corpus/train_data.txt")
model.predict("我在中国吃美国的面包")
















 544
544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











