







本笔记跟随视频黑马测试——Jmeter自动化工具从入门到进阶6小时搞定完成软件安装以及使用项目
特别标注:因为本节内容主要是练习JMeter中的功能,所以虽然结果树中的结果一般都是飘红的,但是除了没有显示抓到的数据,其他都是一样的
线程

放到JMeter中则为

线程组设置
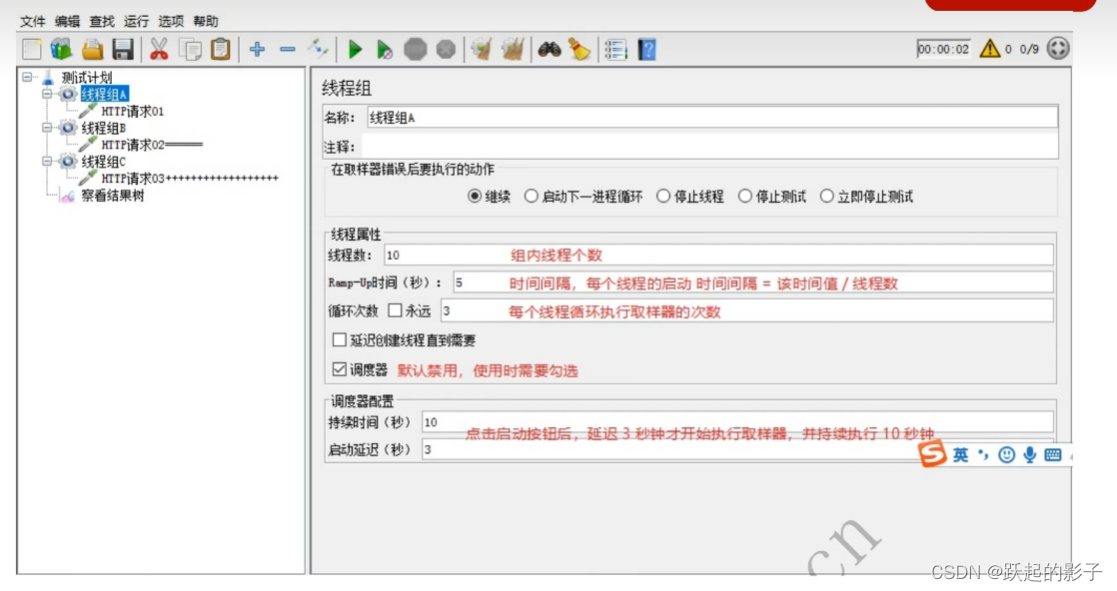
注:没标注的东西就是目前不需要了解也不需要修改
线程数:模拟的用户个数,每次执行有几个人在“操作“
Ramp-UP时间:给用户的准备时间
循环次数:每个线程循环的次数,”永远“的意思是,在运行时不停止,会一直运行下去,但是运行时间过长可能会导致电脑死机
调度器:
持续时间:进程总运行时间,如果调度器时间输入2,循环次数选永远,那进程会在2s内”永远“执行
启动延迟:进程停止几秒后才开始执行
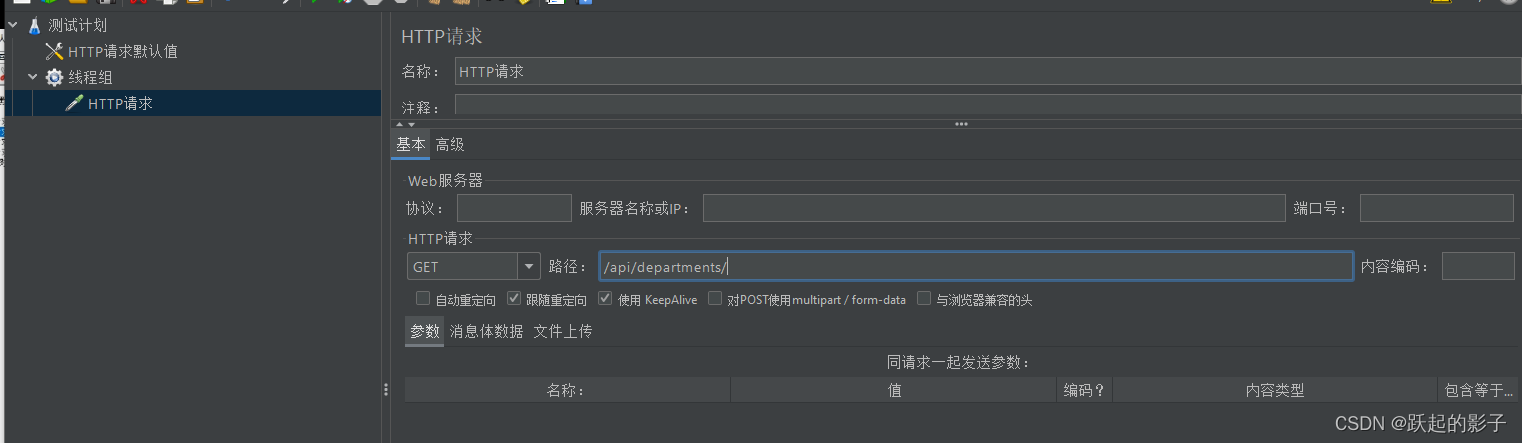
http请求设置
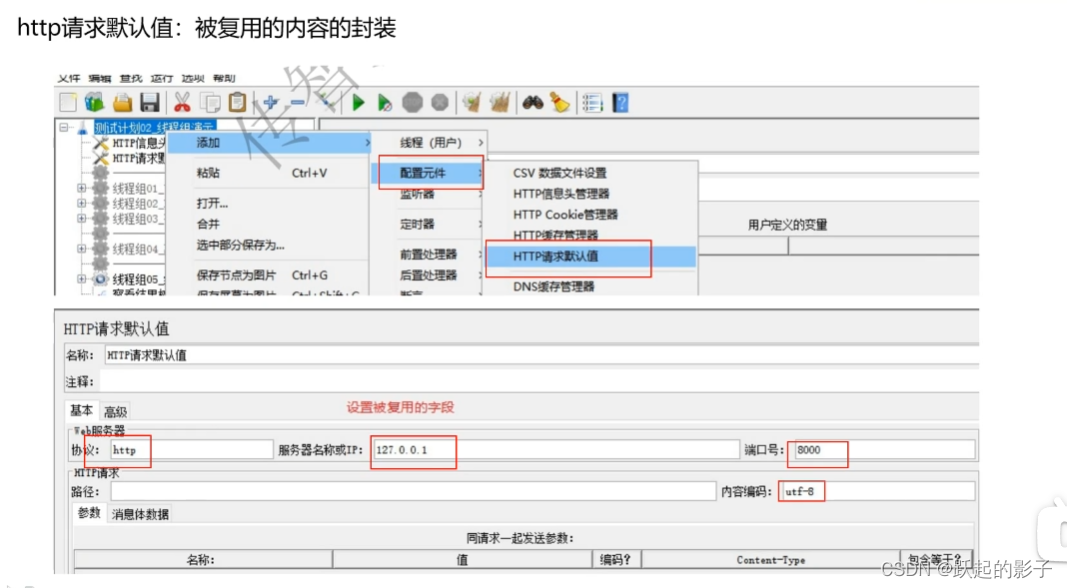
协议:一般是http
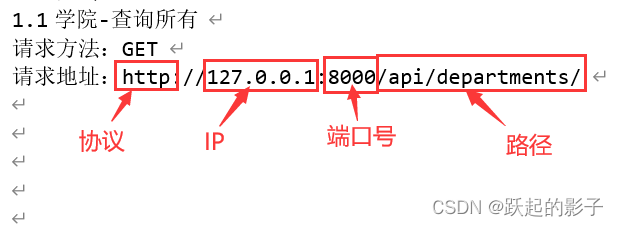
ip、端口号、HTTP请求、路径都是需要在API端口文件中查询的
内置编码:一般为UTF-8
- 如果配置都差不多,可以使用HTTP请求默认值来减少资源浪费
进程-配置元件-HTTP请求默认值
在默认值中输入请求相同的地方,不同的比如路径这些就不要填写了

这样的话,在线程组的HTTP请求中,默认值已经填好的地方就不需要再输入了
运行也是没有问题的

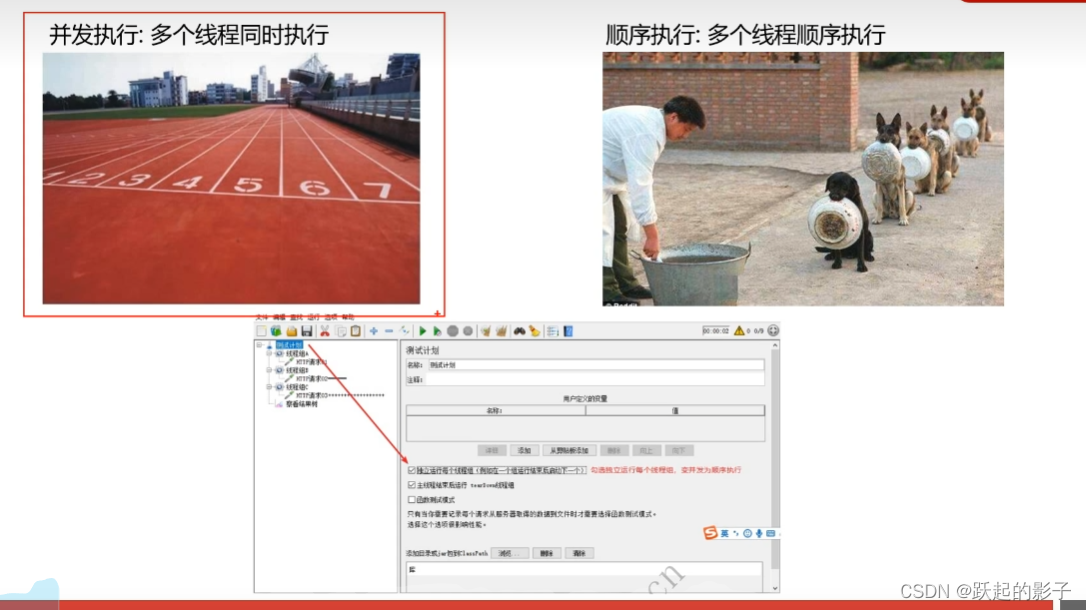
并发执行和顺序执行
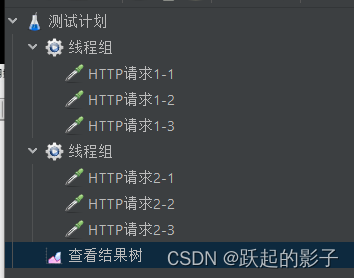
在JMeter中添加两组线程组以及结果树
Tips:
JMeter中复制时,需要选中要将项目复制进的组中,比如复制线程,需要选中线程组再按Ctrl+V;复制线程组,需要选中进程再按Ctrl+V
执行之后可以看到,线程的执行没有按照顺序来,也就是说,他是并发执行的,所以,一般默认操作是并发执行
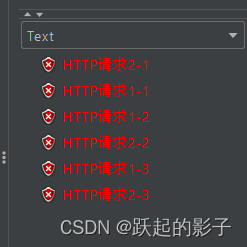
顺序执行:选择独立运行每个线程组
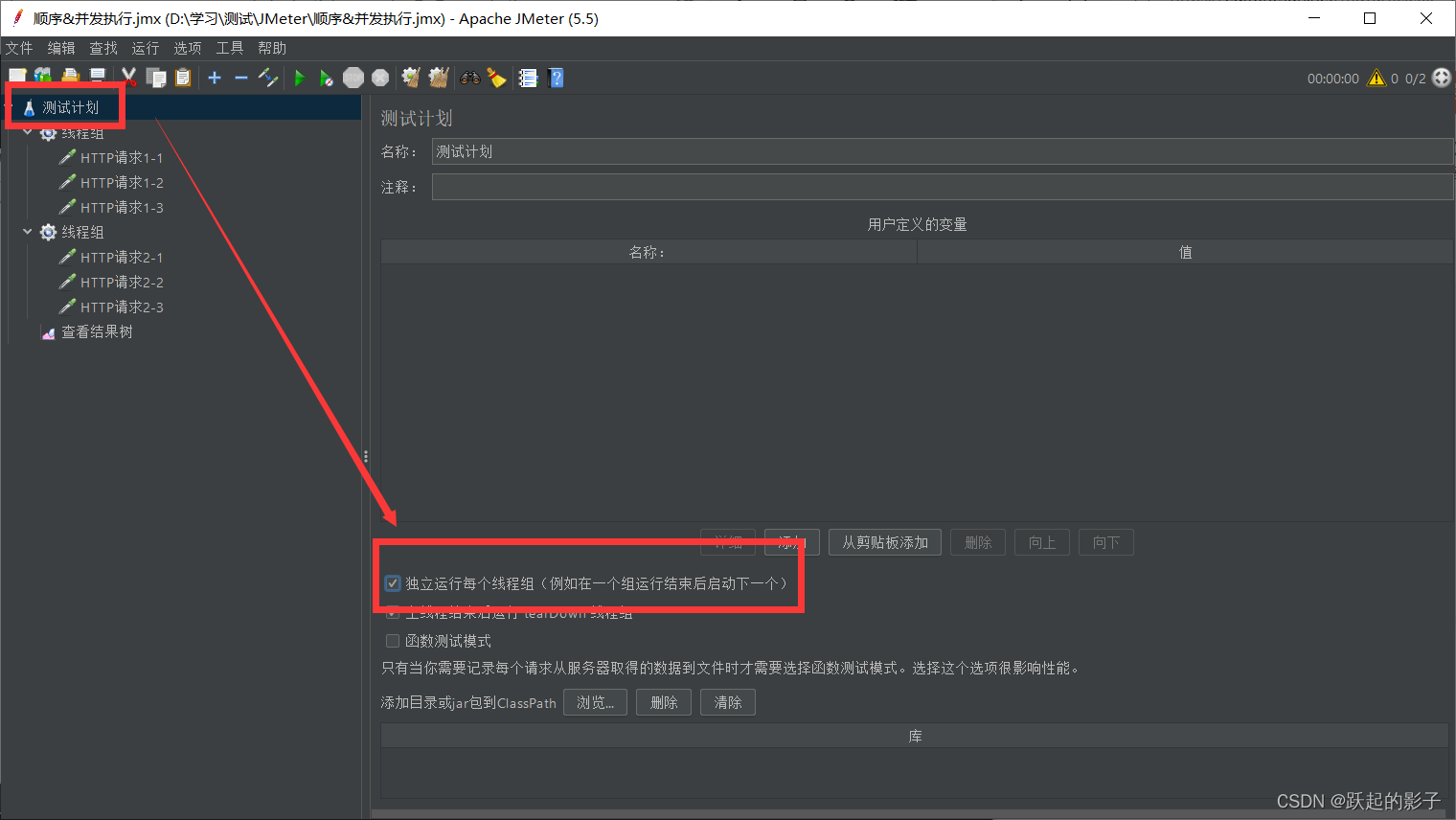
这样运行之后就会按照顺序来了

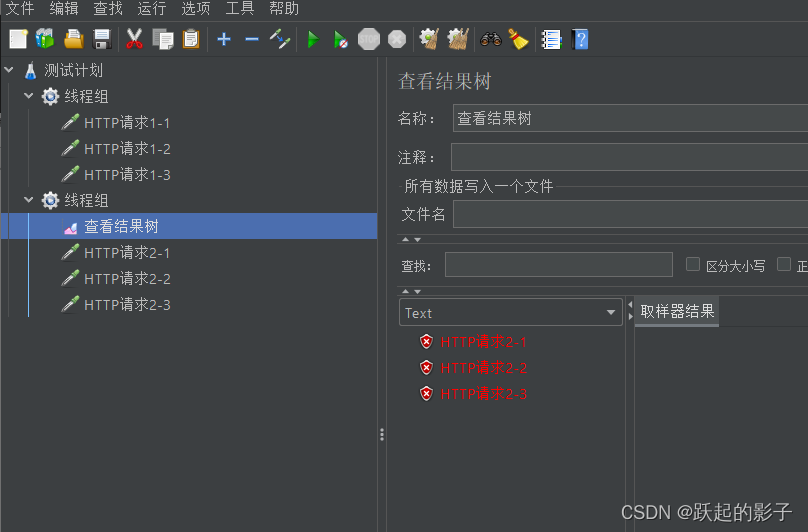
添加结果树之后,如果将结果树拖到线程组上松手,结果树会到该线程组中,而且仅显示该线程组返回的结果
两个特殊的线程组
setUp线程组:最优先执行的线程组,tearDown线程组:最后执行线程组
在进程中添加setUp、tearDown线程组以及一个普通线程组(两个特殊线程组的添加方式和普通一样,都在 进程-添加-线程(用户) 中
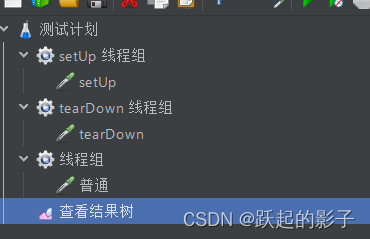
无论是否勾选“独立运行每个线程组”,都会按照setUp线程组->普通线程组->tearDown线程组的顺序执行
直连数据库

在进程中添加数据库有关的jar包
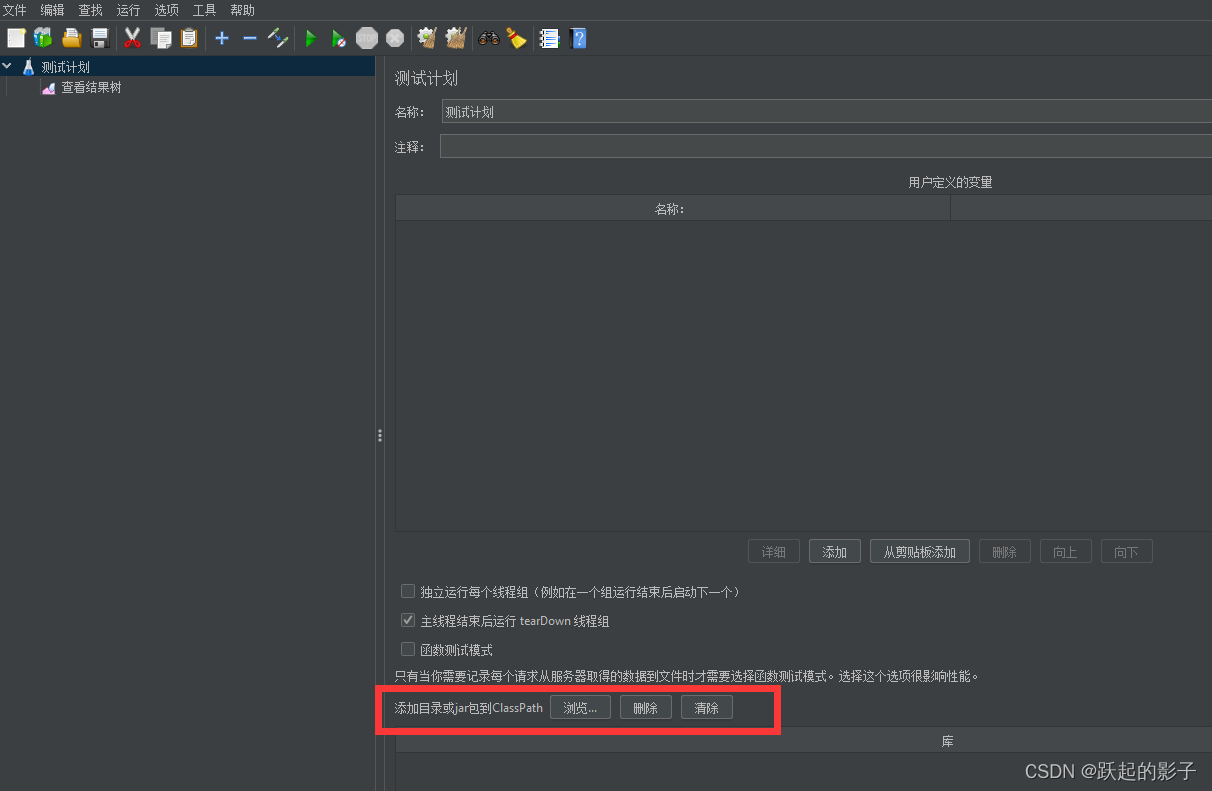
添加数据库连接池
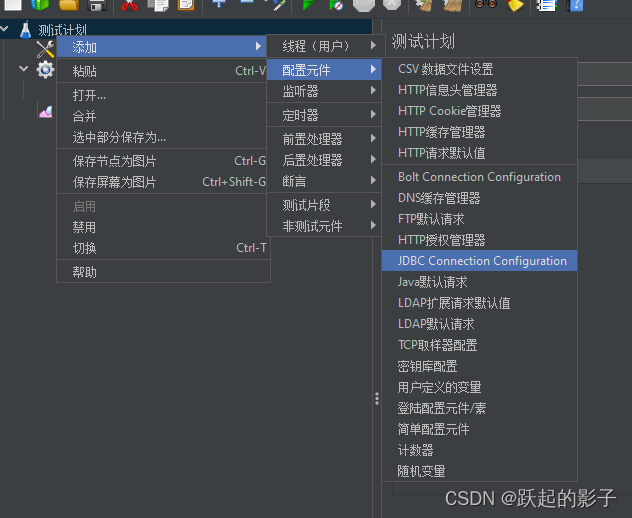
注:
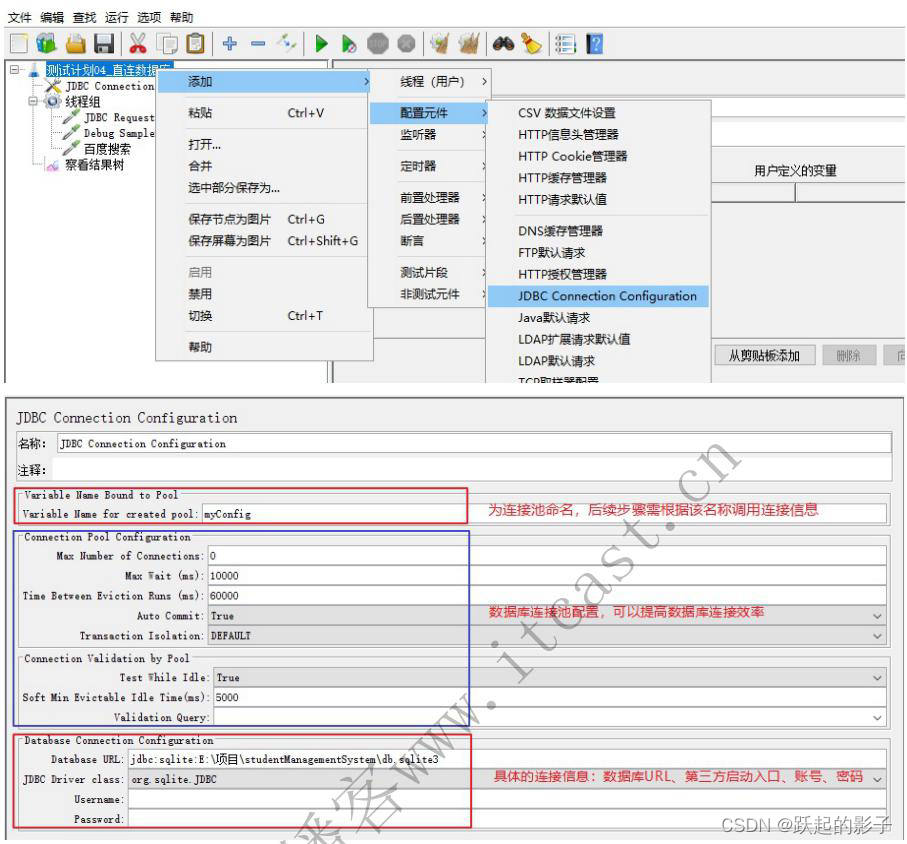
- 这是Sqlite数据库的连接,如果是MySQL等的需要根据自己的数据库进行相应的操作
- 最下面Database URL
//jdbc:sqlite:数据库路径,比如我的为
jdbc:sqlite:D:\BaiduNetdiskDownload\入门篇\入门篇资料\资料\项目\项目\studentManagementSystem\db.sqlite3
Tip:选中文件,按住Shift+右键文件名,有选项可以直接复制文件地址
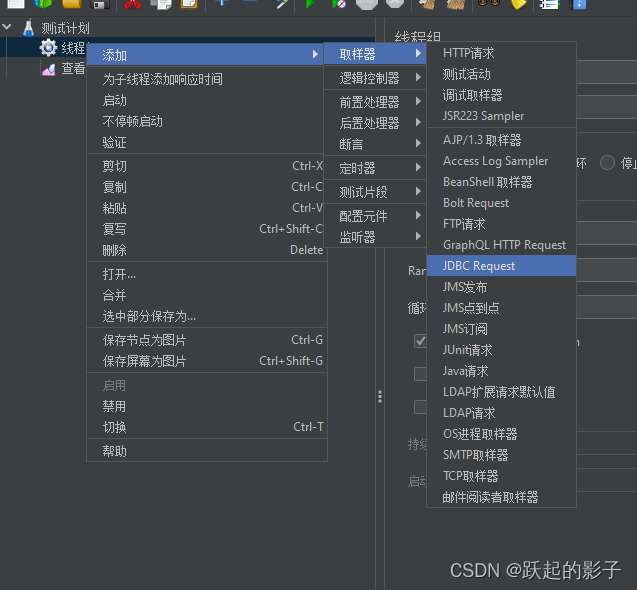
之后添加线程组, 结果树, 在添加请求的时候不要添加HTTP请求了, 要添加JDBC Request
Variable Name of Pool declared in JDBC Connection Configuration:在数据库连接池中自己填的名字
填写下面第三行的Variable Name,用来在将在JDBC Request获取到的结果用Variable Name定义的名称为前缀进行数据的保存
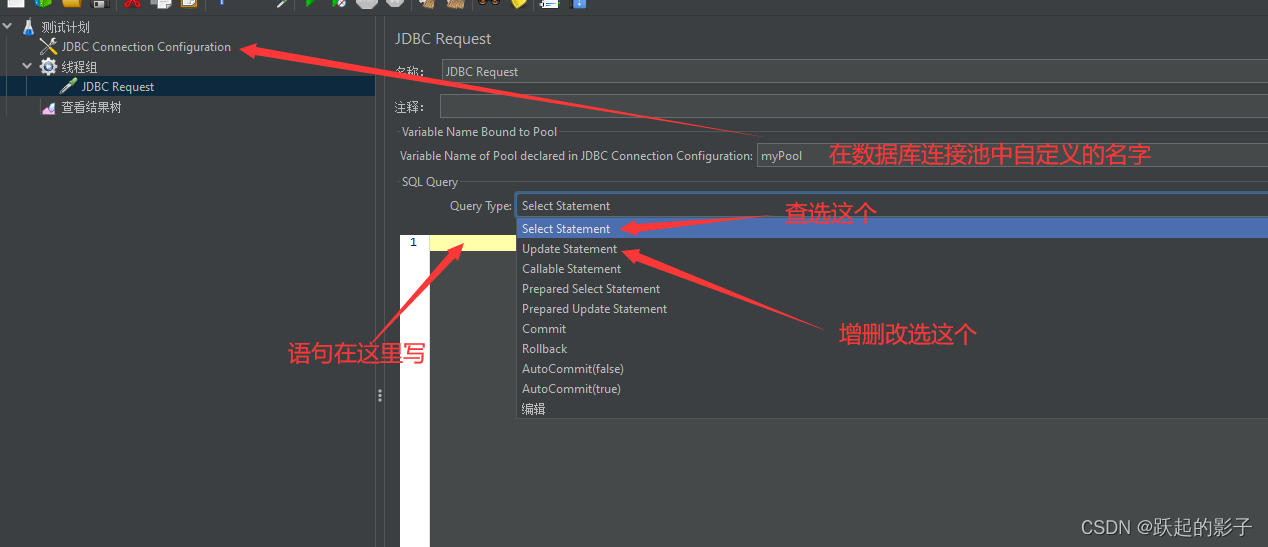
语句写一个简单的查询学院名
select dep_name from departments
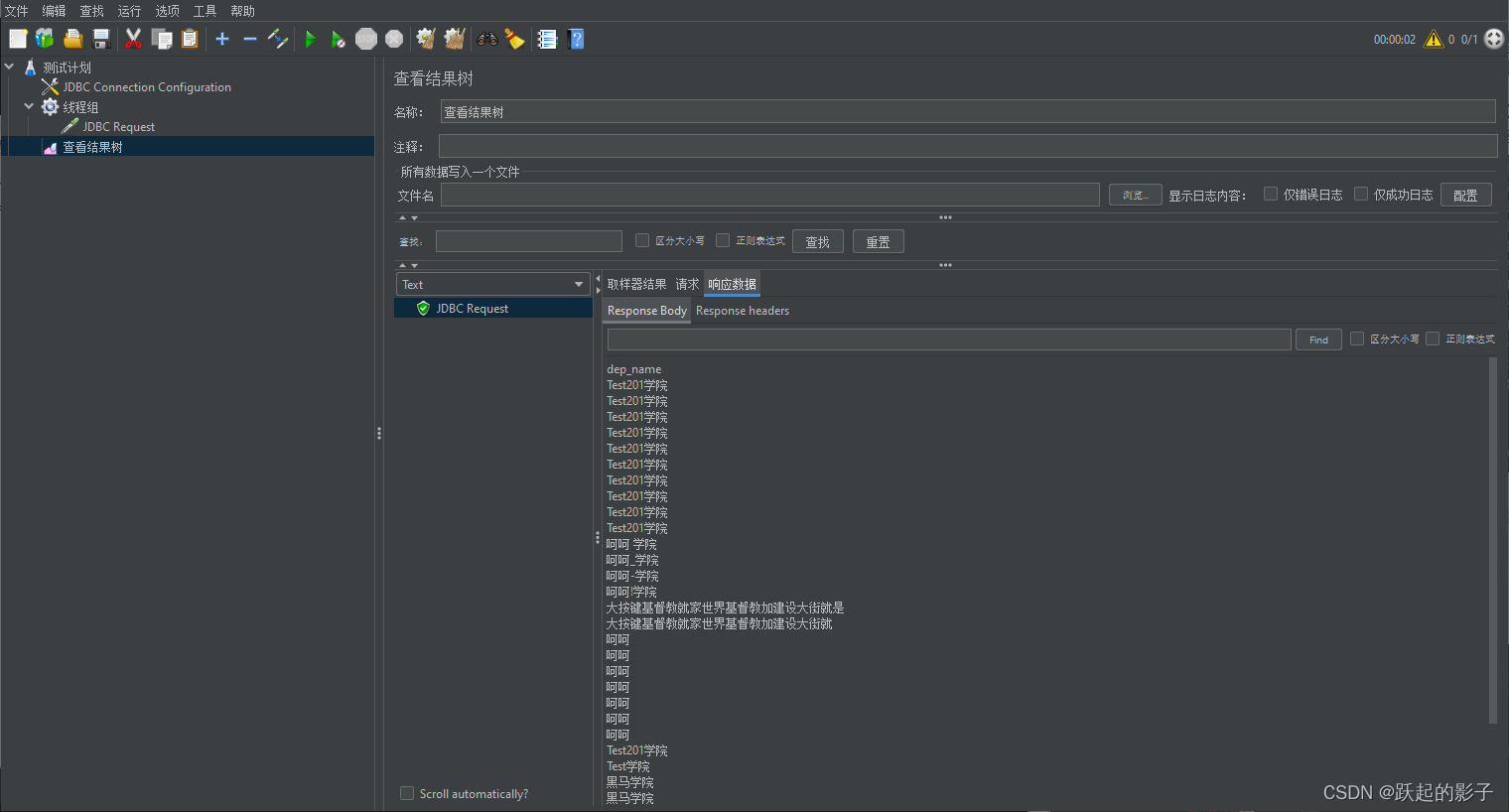
运行,可以看到结果
添加调试取样器
添加调式取样器之后运行,可以看到,所有结果前都带了Variable Name的前缀,同时,val_num则是变量名,可以调用

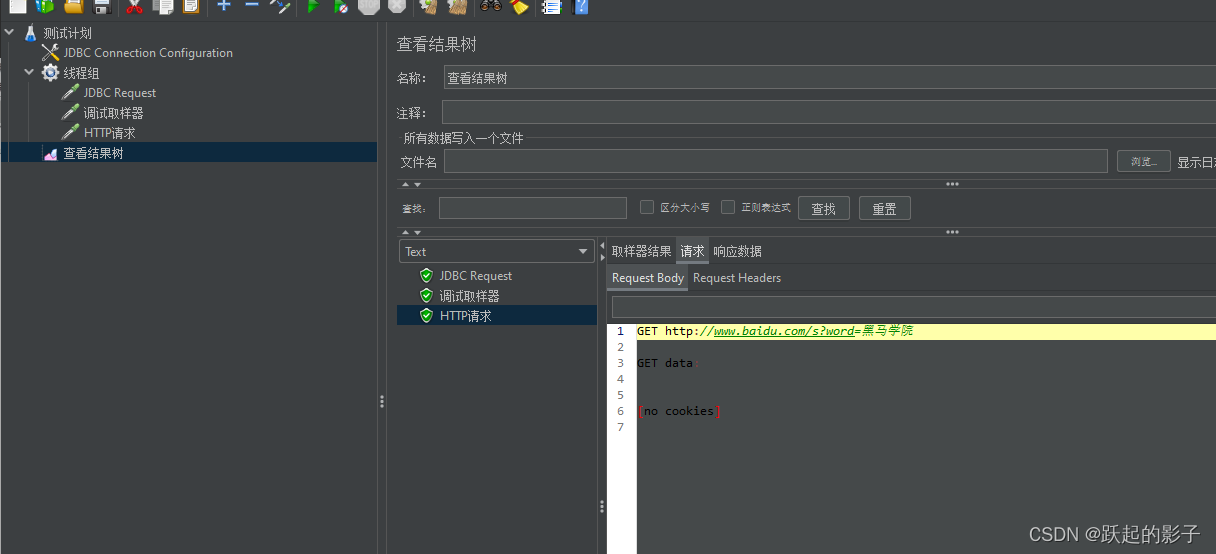
新建HTTP请求,使用Variable Name,访问百度的搜索
注意:网站的端口号一般为80
在百度中搜索的是s?word=XXX,所以可以在路径中输入/s?word=&{val_num},这样就可以得到相应的响应(以val_28为例)
运行,可以看到请求中搜索的是“黑马学院”















 309
309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









