









**
nltk_download()下载不了解决办法
运行代码时报这个错
?[31m>>> import nltk
>>> nltk.download('stopwords')
?[0m
For more information see: https://www.nltk.org/data.html
Attempted to load ?[93mcorpora/stopwords?[0m
Searched in:
- 'C:\\Users\\l/nltk_data'
- 'E:\\2021-2022-1\\anaconda\\nltk_data'
- 'E:\\2021-2022-1\\anaconda\\share\\nltk_data'
- 'E:\\2021-2022-1\\anaconda\\lib\\nltk_data'
- 'C:\\Users\\l\\AppData\\Roaming\\nltk_data'
- 'C:\\nltk_data'
- 'D:\\nltk_data'
- 'E:\\nltk_data'
尝试去给定的网站下载,也下载不了。原因是因为原来的网站404。**
借此我将nltk_data资源包放到网盘链接如下。
链接:https://pan.baidu.com/s/1-E45d9Cmf4I7gp_GHScLbw 提取码:apta
**
下载好资源包解压,找到压缩包里的*corpora*文件
根据上面的提示,将该文件放到对应的路径,如果没有创建一个。我是放到第一个的。
注!!!:上面报错中 nltk.download(‘stopwords’) ,在corpora中找到相应的stopwords并解压。
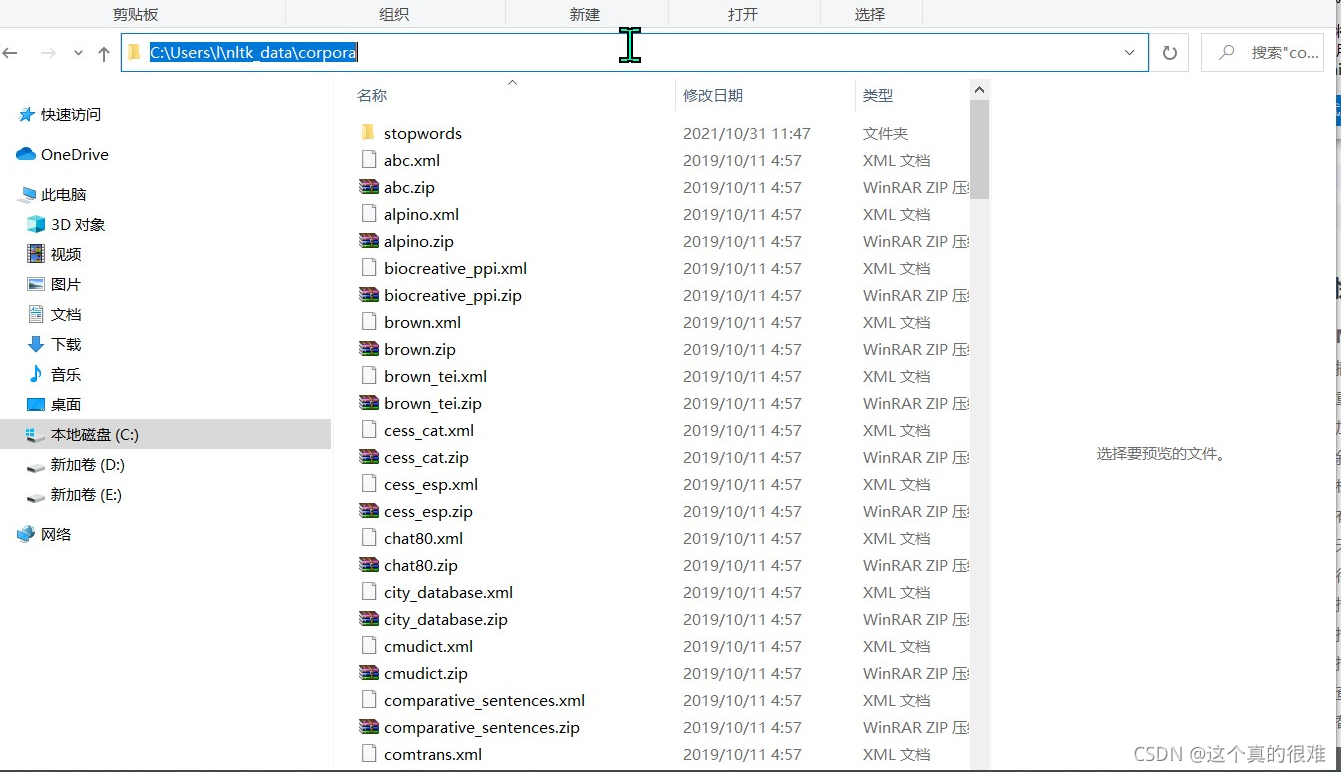
这样成功解决了















 3432
3432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









