







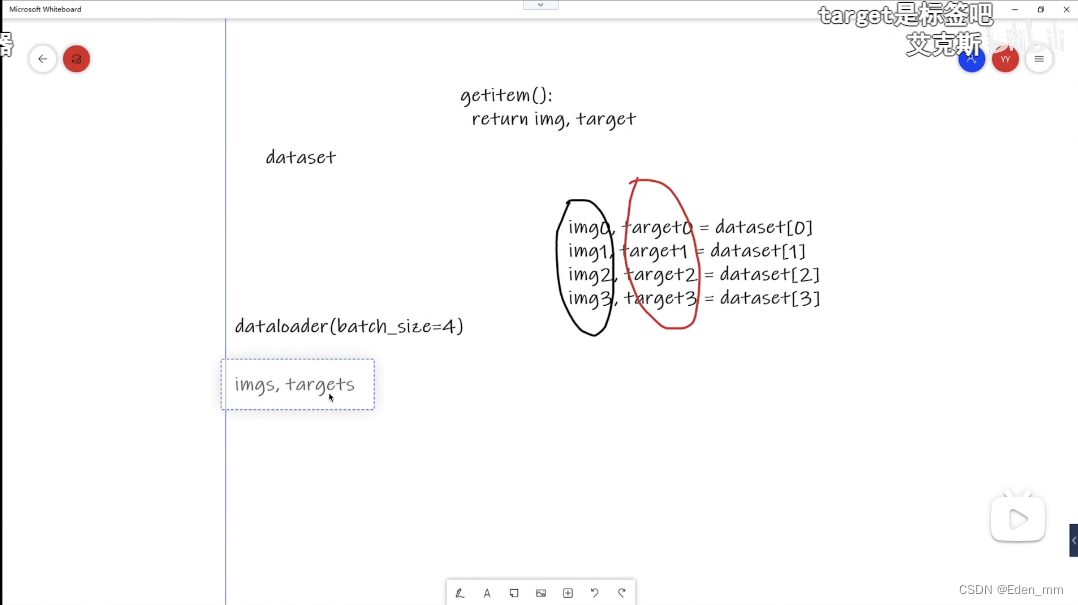
dataset只是单纯的给出位置,如索引等等,进行数据的相关设置。数据的加载需要靠dataloader,加载到神经网络当中,每次怎样取,取多少等等

dataloader有很多参数,但除了dataset都有默认值,而dataset就是告诉我们数据在什么地方,包括第一张数据,第二张数据等

dataset (Dataset) – dataset from which to load the data.
batch_size (int, optional) – how many samples per batch to load (default: 1).
shuffle (bool, optional) – set to True to have the data reshuffled at every epoch (default: False).
sampler (Sampler or Iterable, optional) – defines the strategy to draw samples from the dataset. Can be any Iterable with len implemented. If specified, shuffle must not be specified.
batch_sampler (Sampler or Iterable, optional) – like sampler, but returns a batch of indices at a time. Mutually exclusive with batch_size, shuffle, sampler, and drop_last.
num_workers (int, optional) – how many subprocesses to use for data loading. 0 means that the data will be loaded in the main process. (default: 0)
collate_fn (callable, optional) – merges a list of samples to form a mini-batch of Tensor(s). Used when using batched loading from a map-style dataset.
pin_memory (bool, optional) – If True, the data loader will copy Tensors into CUDA pinned memory before returning them. If your data elements are a custom type, or your collate_fn returns a batch that is a custom type, see the example below.
drop_last (bool, optional) – set to True to drop the last incomplete batch, if the dataset size is not divisible by the batch size. If False and the size of dataset is not divisible by the batch size, then the last batch will be smaller. (default: False)
timeout (numeric, optional) – if positive, the timeout value for collecting a batch from workers. Should always be non-negative. (default: 0)
worker_init_fn (callable, optional) – If not None, this will be called on each worker subprocess with the worker id (an int in [0, num_workers - 1]) as input, after seeding and before data loading. (default: None)
generator (torch.Generator, optional) – If not None, this RNG will be used by RandomSampler to generate random indexes and multiprocessing to generate base_seed for workers. (default: None)
prefetch_factor (int, optional, keyword-only arg) – Number of samples loaded in advance by each worker. 2 means there will be a total of 2 * num_workers samples prefetched across all workers. (default: 2)
persistent_workers (bool, optional) – If True, the data loader will not shutdown the worker processes after a dataset has been consumed once. This allows to maintain the workers Dataset instances alive. (default: False)
常见的参数设置,见示例
import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
ctrl+点击CIFAR10,进入定义
查看return为img,target
import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
# 测试数据集中第一张图片集
img, target = test_data[0]
print(img.shape)
print(target)
D:\anaconda\python.exe C:/Users/ASUS/Desktop/tudui/dataloader.py
torch.Size([3, 32, 32])
3
Process finished with exit code 0
dataset中的具体数据集中getitem返回相关的数据,dataloader根据nums设置的数目进行打包,作为返回
import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
# 测试数据集中第一张图片集
img, target = test_data[0]
print(img.shape)
print(target)
for data in test_loader:
imgs, targets = data
print(imgs.shape)
print(targets)
D:\anaconda\python.exe C:/Users/ASUS/Desktop/tudui/dataloader.py
torch.Size([3, 32, 32])
3
torch.Size([4, 3, 32, 32])
tensor([9, 9, 6, 3])
torch.Size([4, 3, 32, 32])
tensor([6, 1, 0, 7])
torch.Size([4, 3, 32, 32])
tensor([9, 0, 6, 7])
↑可见其将四张图片及target进行了打包
torch.Size([3, 32, 32])
3
torch.Size([4, 3, 32, 32])
tensor([9, 9, 6, 3])
↑第一target是3,在tensor中却是9,是因为没有进行相关的设置,sample随机取的
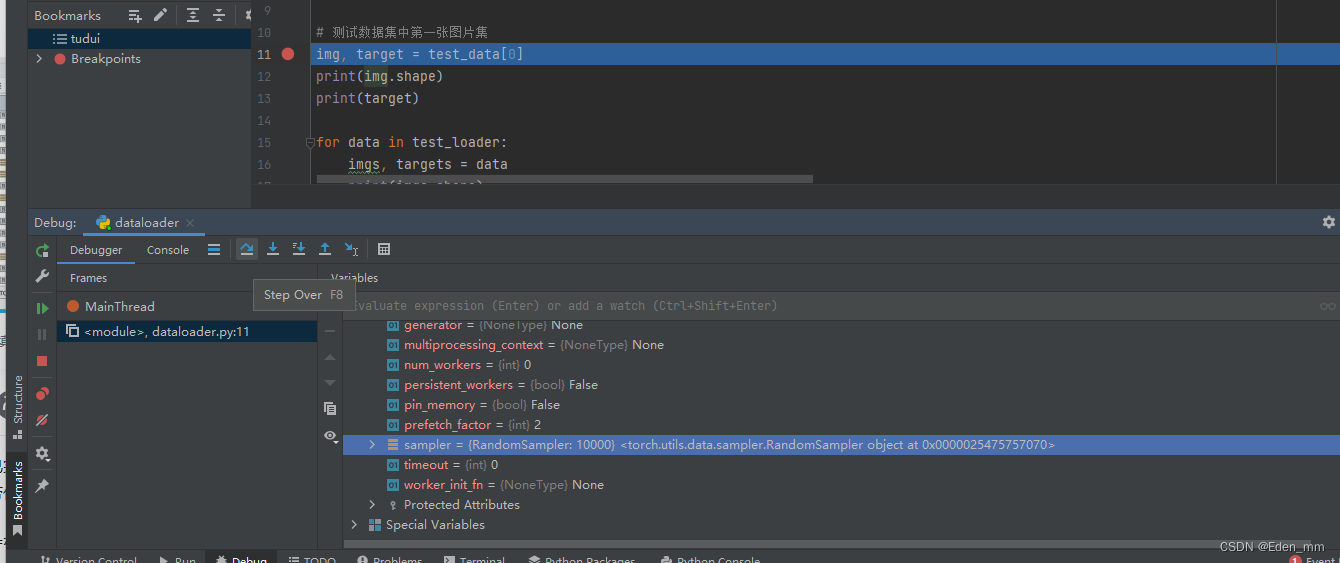
↑sample是random,随机抓取四张
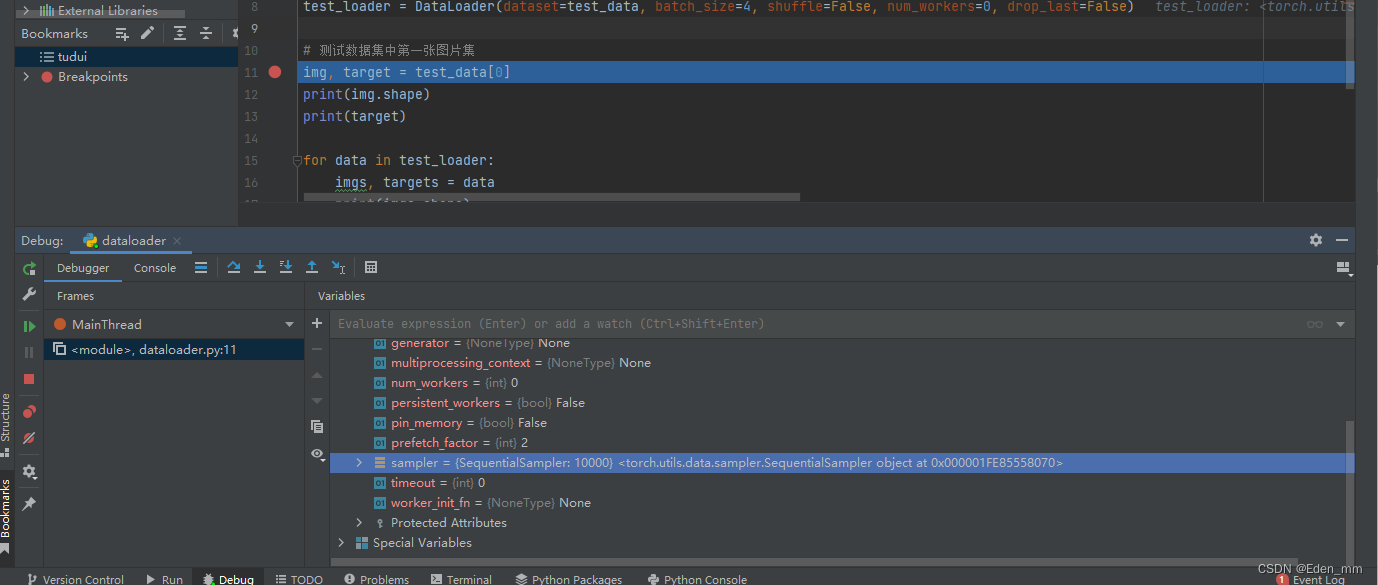
将dataloader中的shuffle改为False,不再随即抓取
import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=False, num_workers=0, drop_last=False)
# 测试数据集中第一张图片集
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
step = 0
for data in test_loader:
imgs, targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("test_data", imgs, step)
step = step + 1
writer.close()
PS C:\Users\ASUS\Desktop\tudui> tensorboard --logdir="dataloader"
TensorFlow installation not found - running with reduced feature set.
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.9.0 at http://localhost:6006/ (Press CTRL+C to quit)
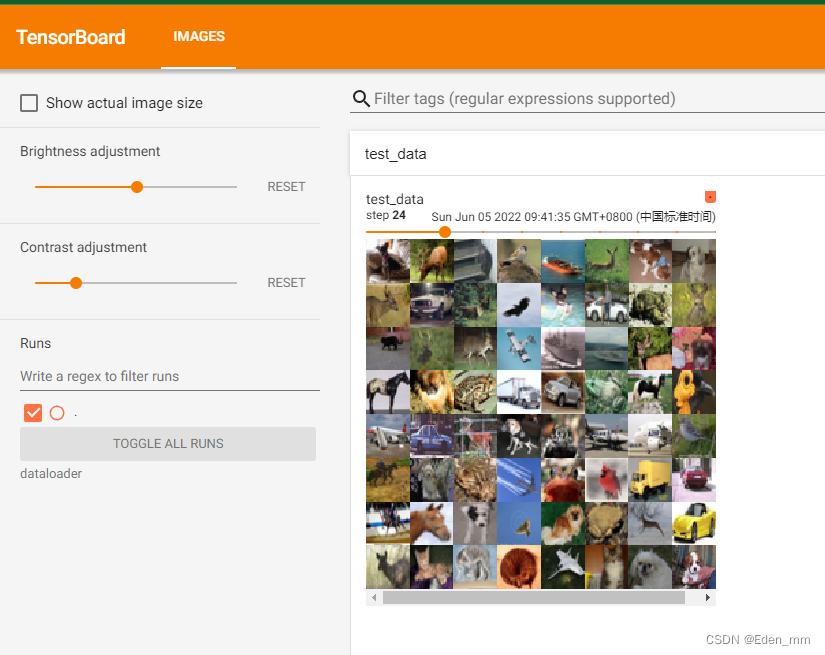
去掉不足64的最后一批次
import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=False, num_workers=0, drop_last=True)
# 测试数据集中第一张图片集
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
step = 0
for data in test_loader:
imgs, targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("test_data_drop_last", imgs, step) ####注意一定更改名字
step = step + 1
writer.close()
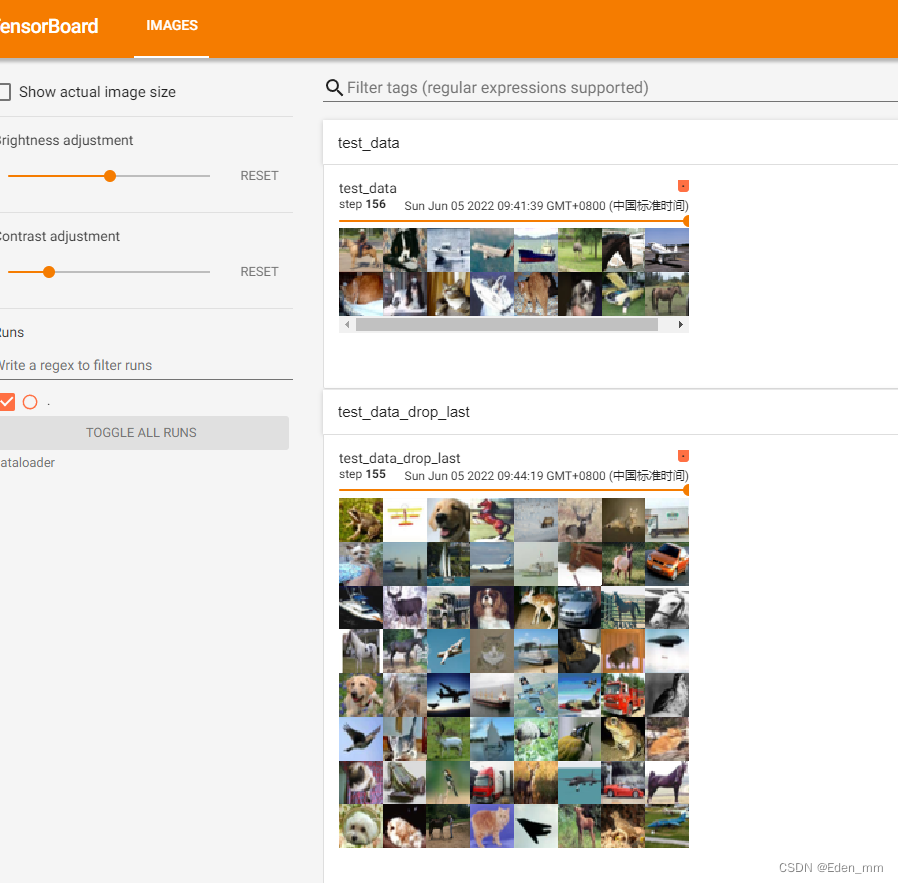
设置循环,

















 5259
5259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











