







特征工程
前言
数据和特征决定了机器学习地上限,而模型和算法只是逼近这个上限而已
一、特征工程的重要性和处理
特征工程就是从原试数据中提取特征的过程,这些特征可以很好地描述数据,并且利用特征建立地模型在未知数据上的性能表现可以达到最优(或者接近最佳性能)。特征工程一般包括特征使用、特征获取、特征处理、特征选择和特征监控。
业界广泛流传着这样一句话:“数据和特征决定了机器学习地上限,而模型和算法只是逼近这个上限而已”,由此可见特征工程在机器学习中重要性。具体来说,特征越好、灵活性越强,构建的模型越简单、性能越出色。
特征工程的重要性:
- 特征越好,灵活性越强:好特征的灵活性在于你选择不复杂的模型,同时运行速度也更快】更容易理解和维护
- 特征越好,构建的模型越简单:好的特征,不需要花太多的时间去寻找最有效的参数,这大大降低了模型的复杂度
- 特征越好,模型的性能越出色:特征工程的最终目的就是提升模型的性能
特征工程的处理流程为首先去掉无用特征,接着去除冗余特征,如共线特征,并利用存在的特征、转换特征、内容中的特征以及其他数据源生成新特征,然后对特征进行转换(数值化、类别转换、归一化等),最后对特征进行处理(异常值、最大值、最小值、缺失值等),以符合模型的使用。
简单来说,特征工程的处理一般包括数据预处理、特征处理、特征选择等工作,而特征选择视情况而定,如果特征数量较多,则可以进行特征选择等操作
二、数据预处理和特征处理
1.数据预处理
在进行特征提取之前,要对数据进行预处理,具体包括数据采集、数据清洗、数据采样。
- 数据采集:
在数据采集之前需要明确几个问题:哪些数据对最后的预测结果有帮助,是否能采集到这一类数据,在线上实时计算时数据获取是否快捷。 - 数据清洗:
数据清洗也是很重要的一步,大多数时候机器学习算法就是一个加工机器,至于最后的产品如何,取决于原材料的好坏。数据清洗就是要去除“脏”数据,比如某些商品刷单数据。
那么,如何判定数据为“脏”数据呢?
简单属性判定:如身高3米多的人,一个人每月购买10万元的美发卡。
组合或统计属性判定:如号称在美国却一直都是国内的新闻阅读用户。
补齐可对应的缺省值:将不可信的样本丢掉,不用缺省值极多的字段。 - 数据采样:
数据在采集、清洗过后,正负样本是不均衡的,故要进行数据采样。数据采样的方法有随机采样和分层抽样。但由于随机采样存在隐患,可能某次随机采样的数据很不均匀,因此更多的是根据特征进行分层抽样。
正负样本不平衡的处理方法:
正样本>负样本,且量都特别大的情况:采用下采样的方法。
正样本>负样本,且量不大的情况,可采用以下方法采集更多的数据:上采样,比如图像 识别中的镜像和旋转;修改损失函数设置样本权重。
2.特征处理
特征处理的方法包括标准化、区间缩放法、归一化、定量特征二值化、定性特征哑编码、缺失值处理和数据转换。
1、标准化
标准化是依照特征矩阵的列处理数据,即通过求标准分数的方法,将特征转换成标准正态分布,并和整体样本分布相关。每个样本点都能对标准化产生影响。
标准化需要计算特征的均值和标准差,公式如下:
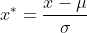
2、区间缩放法
区间缩放法的思路有很多种,常见的一种是利用两个最值(最大值和最小值)进行放缩。公式如下:
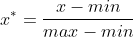
3、归一化
归一化是将样本的特征值转到同一量纲下,把数据映射到[0,1]或者[a,b]区间内,由于其仅有变量的极值决定,因此区间缩放法是归一化的一种。
归一化会改变数据的原试距离、分布和信息,但标准化一般不会
规则为L2的归一化公式如下:
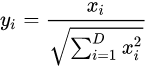
归一化和标准化的使用场景:
- 如果对输出结果范围有要求则有归一化
- 如果数据较为稳定,不存在极端的最大值或最小值,则用归一化
- 如果数据存在异常值和较多噪声,则用标准化,这样可以通过中心化间接避免异常值和极端值的影响。
- 支持向量机(SVM)、K近邻(KNN)、主成分分析(PCA)等模型都必须进行归一化或标准化操作。
4、定量特征二值化
定量特征二值化的核心在于设定一个阈值,大于阈值的赋值为1,小于或等于阈值的赋值为0。
5、定性特征哑编码
哑变量,也被称为虚拟变量,通常是人为虚设的变量,取值为0或1,用来反映某个变量的不同属性。将类别变量转换为哑变量的过程就是哑编码。而对于有n个类别属性的变量,通常会以1个类别特征为参照,产生n-1个哑变量。
引入哑变量的目的是把原来不能定量处理的变量进行量化,从而评估定性因素对因变量的影响。
通常会将原始的多分类变量转换为哑变量,在构建回归模型时,每一个哑变量都能得出一个估计的回归系数,这样使得回归的结果更容易解释,也更具有实际意义。
6、缺失值处理
当数据中存在缺失值时,用Pandas读取后特征均为NaN,表示数据缺失,即数据未知。















 108
108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









