







前提:WIN11+VS2022+CUDA11.6
第1课 cuda入门
GPU能够通过内部极多进程的并行运算,取得比CPU高一个数量级的运算速度。但是GPU为了管理多进程,它需要在微架构上进行精心设计以满足深度学习计算对于带宽和缓存的需求。GPU是为了图像处理设计的,但它的构架并没有专门的图像处理算法,仅仅是对CPU的构架进行了优化。当前的多核CPU一般由4或6个核组成,以此模拟出8个或12个处理进程来运算。但普通的GPU就包含了几百个核,高端的有上万个核,这对于多媒体处理中大量的重复处理过程有着天生的优势,同时更重要的是,它可以用来做大规模并行数据处理
借用某老师的话说,CPU可以看做一个博士解一道超难的数学题目,GPU可以看做是一百个小学生在写海量的类似1+1的简单数学题。
第2.1课 cuda基本原理和命令
CPU与GPU之间通过PCIE传数据,即GPU不能直接调用CPU上的数据,
GPU、CPU参数传递:cudaMemcpy(*dst,*src,byte_size,类型)
类型:CPU->CPU cudaMemcpyHostToHost
CPU->GPU cudaMemcpyHostToDevice
GPU->CPU cudaMemcpyDeviceToHost
GPU->GPU cudaMemcpyDeviceToDevice
但是在GPU拿取CPU数据之前,要先在GPU的存储区上开辟一段空间用来存放该数据,
定义在GPU上的指针:cudaMalloc(**devPtr,byte_size)
示例:int * gpu_int;
cudaMalloc((void**)&gpu_int,sizeof(int));
同理,CPU也不能直接拿GPU上的数,也要先开辟空间去存,用malloc函数开辟就行。
所以用GPU运算的话顺序是:1.先开辟GPU空间,2.把数据从CPU复制到GPU。3.GPU调用函数对该数据进行运算,4.把结果从GPU传回CPU。
特别要注意的是,开辟空间之后一定要记得释放!!
显存的释放:cudaFree()
最好是cudaMalloc了之后立马跟一句cudaFree,两者成对出现,然后再在中间写函数。以免忘记导致显存空间越来越少,忘记了的话我也不知道该怎样解决。
接下来讲一下cuda函数的定义:
__global__ :之后跟的一定是void,无返回值。在GPU上定义,CPU上可以调用的函数。例如main函数可调用。而在CPU上定义的函数,在该函数体内是调用不了的。
__device__:在GPU上定义,GPU上调用的函数。这下__global__函数就可以调用了。但是CPU上调用不了该函数。
__host__:在CPU上定义的函数,一般在__device__前才会用到。这样CPU、GPU都可以调用。
GPU上的数组初始化:cudaMemset(*devptr,value,byte_size);
核函数(前缀__global__)调用:
dim3 griddim(x,y,z);//这是网格,内含多个线程块
dim3 blockdim(x,y,z);//这是线程块,内含多个线程
function<<<griddim.blockdim>>>(参数...)
如果grid或block是一维的,可以直接用整形数代替而不用dim3声明了。
来一个简单的程序实例:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <iostream>
using namespace std;
__device__ int add_one(int a)
{
return a + 1;
}
__global__ void show(int* a)
{
for (int i = 0; i < 10; i++)
{
//a[i] = add_one(a[i]);
printf("%d ", a[i]);
}
printf("\n");
}
__global__ void init_gpu(int* a)
{
for (int i = 0; i < 10; i++) {
a[i] = 100;
}
}
int main() {
int cpu_int[10] = { 10,10,10,10,10,10,10,10,10,10 };
printf("%d\n", cpu_int[0]);
int* gpu_int;
cudaMalloc((void**)&gpu_int, 10 * sizeof(int));
cudaMemset(gpu_int, 0, 10 * sizeof(int)); //gpu_int赋0值
show << <1, 1 >> > (gpu_int);//注意核函数调用形式
cudaMemcpy(gpu_int, cpu_int, 10 * sizeof(int), cudaMemcpyHostToDevice);//gpu_int赋cpu_int值
show << <1, 1 >> > (gpu_int);
init_gpu << <1, 1 >> >(gpu_int);//gpu_int赋100值
show << <1, 1 >> > (gpu_int);
cudaMemcpy(cpu_int, gpu_int, 10 * sizeof(int), cudaMemcpyDeviceToHost);//cpu_int赋gpu_int值
printf("\n cpu_int \n");
for (int i = 0; i < 10; i++)
{
printf("%d ", cpu_int[i]);
}
cudaFree(gpu_int);
cudaDeviceSynchronize();
return 0;
}输出结果应该是:
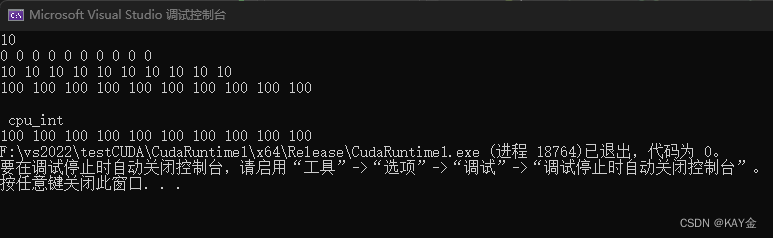
可以在show<<<1,1>>>();函数里调整一下线程数,可以看到他就会调用多次,帮助理解下节课线程、网格概念。
第2.2课 线程的理解
thread:线程。一个CUDA并行程序会被以多个threads来执行
block:线程块。数个threads会被群组成一个block,同一个block中的threads可以使用_symcyhreads()同步(该函数在程序中虽然会标红,但是可以执行),也可以通过shared memory(共享内存)通信。
grid:网格。多个blocks则会再构成grid。
【GPU存储结构分三级:local memory(本地内存,超快)、shared memory(共享内存,同一线程块内的线程可以读取,比global memory读取速度快几十倍)、global memory(全局内存,慢)】
这一块超难理解,重中之重!空间想象能力需求MAX!!!
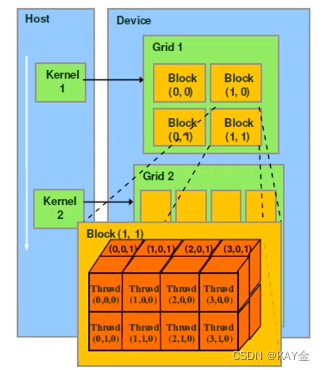
上图是一个2*2的grid/网格,每个元素是个4*2*2的block/线程块。
grid,block的维度使用dim3进行初始化,示例:
dim3 blocksize(3,2);
dim3 gridsize(3,3);
线程ID的获取:(重中之重!!!!)超难理解啊!!!!!请自行画图理解



第2.3课 矩阵运算
实例:一个20*20的矩阵,令其(x,y)坐标上的值等于x+y。
需要注意的是GPU上的函数没有报错机制,所以最好在函数内自己加上错误判断代码。
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <iostream>
#include<iomanip>
using namespace std;
//20*20的矩阵,坐标(x,y)赋值x+y
__device__ int coord_int(int x,int y)
{
return x+y;
}
__global__ void Matrix_init(int* a,int m,int n)
{
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x < m && y < n) { a[y * n + x] = coord_int(x, y); }
}
void show(int* a, int m, int n)
{
for (int i = 0; i < n; i++)
{
for (int j = 0; j < m; j++)
{
cout <<setw(2)<< a[m * i + j] << " ";
}
cout << endl;
}
}
int main() {
int* gpu_int;
cudaMalloc((void**)&gpu_int,400 * sizeof(int));//20*20矩阵
int cpu_int[400] = { 0 };
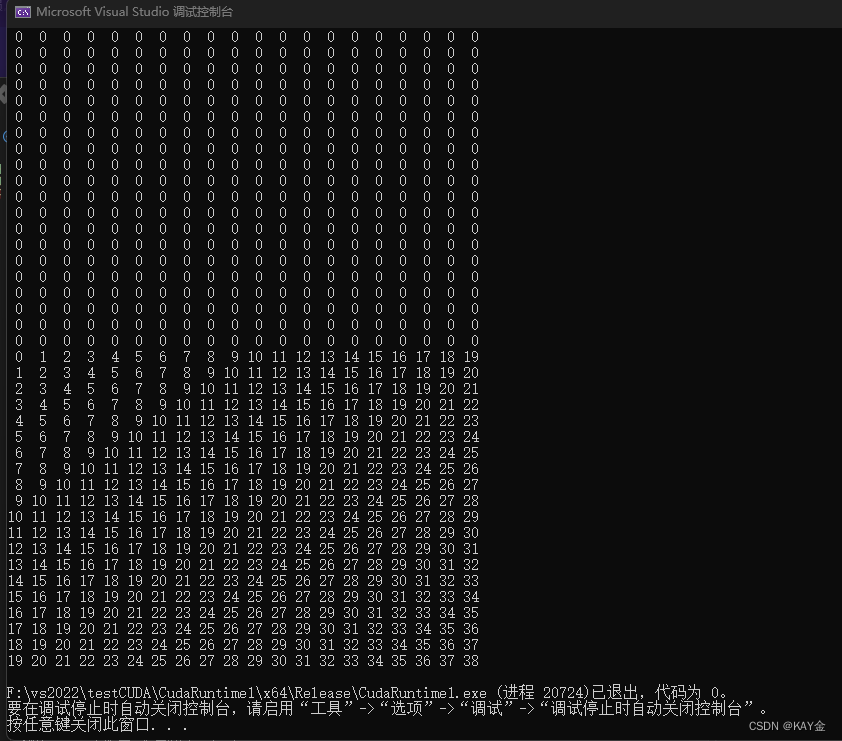
show(cpu_int, 20, 20);
//定义的比20*20大
dim3 blockdim(8, 8);
dim3 griddim(3, 3);
Matrix_init << <griddim, blockdim >> > (gpu_int, 20, 20);
cudaMemcpy(cpu_int, gpu_int, 400 * sizeof(int), cudaMemcpyDeviceToHost);//传回CPU
show(cpu_int, 20, 20);
cudaFree(gpu_int);
return 0;
}
实例:矩阵的加法、矩阵的乘法。
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <iostream>
#include<iomanip>
using namespace std;
//20*20的矩阵,坐标(x,y)赋值x+y
__device__ int coord_int(int x,int y)
{
return x+y;
}
__global__ void Matrix_init(int* a,int m,int n)
{
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x < m && y < n) { a[y * n + x] = coord_int(x, y); }
}
__global__ void Matrix_add(int* a, int* b, int* c, int m, int n)
{
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x < m && y < n) {
c[y * n + x] = a[y * n + x]+b[y * n + x];
}
}
__global__ void Matrix_multi(int* a, int* b, int* c, int m)//m*m的矩阵相乘
{
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int value = 0;
if (x < m && y < m) {
for (int i = 0; i <m; i++)
{
value += (a[y * m + i] * b[x + i * m]);//a的第y行,b的第x列
}
c[y * m + x] =value;
}
}
void show(int* a, int m, int n)
{
for (int i = 0; i < n; i++)
{
for (int j = 0; j < m; j++)
{
cout <<setw(2)<< a[m * i + j] << " ";
}
cout << endl;
}
}
int main() {
int* gpu_int;cudaMalloc((void**)&gpu_int, 400 * sizeof(int));//20*20矩阵
int cpu_int[400] = { 0 };
cout << "cpu_int矩阵值:" << endl;
show(cpu_int, 20, 20);
//定义的比20*20大
dim3 blockdim(8, 8);
dim3 griddim(3, 3);
Matrix_init << <griddim, blockdim >> > (gpu_int, 20, 20);
cudaMemcpy(cpu_int, gpu_int, 400 * sizeof(int), cudaMemcpyDeviceToHost);//传回CPU
cout << "gpu_int矩阵值:" << endl;
show(cpu_int, 20, 20);
int* gpu_add; cudaMalloc((void**)&gpu_add, 400 * sizeof(int));//20*20矩阵
Matrix_add << <griddim, blockdim >> > (gpu_int, gpu_int, gpu_add, 20, 20);//两矩阵相加的值给gpu_add
cudaMemcpy(cpu_int, gpu_add, 400 * sizeof(int), cudaMemcpyDeviceToHost);//传回CPU
cout << "相加后的矩阵值:" << endl;
show(cpu_int, 20, 20);
int* gpu_multi; cudaMalloc((void**)&gpu_multi, 400 * sizeof(int));//20*20矩阵
Matrix_multi << <griddim, blockdim >> > (gpu_int, gpu_int, gpu_multi, 20);//两矩阵相乘的值给gpu_multi
cudaMemcpy(cpu_int, gpu_multi, 400 * sizeof(int), cudaMemcpyDeviceToHost);//传回CPU
cout << "相乘后的矩阵值:" << endl;
show(cpu_int, 20, 20);
cudaFree(gpu_int);
cudaFree(gpu_add);
cudaFree(gpu_multi);
return 0;
}















 953
953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









