







一、实验环境
- 操作系统:Linux(与实验1保持一致);
- Hadoop版本:3.3.1;
- JDK版本:1.8;
- Hive版本:3.1.2
二、实验内容
安装Hive环境
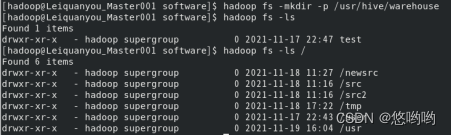
- 完成Hive安装,根据实验1所安装的Hadoop模式,选择Hive的配置模式;
- 将Hive的配置文件详细清单列出;









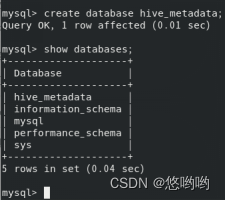
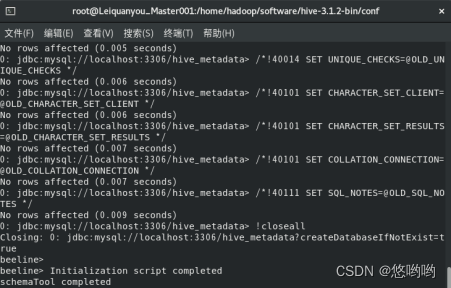
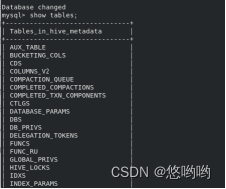
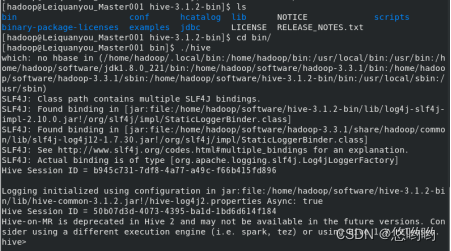
HiveQL练习
classid
dz1955001001
dz1955001001
dz1955001002
dz1955001002
dz1955002001
dz1955002001
dz1955002002
dz1955002002
dz1955003001
dz1955003001
dz1955003002
dz1955003002
dz1955004001
dz1955004001
dz1955004002
dz1955004002
完成以下操作:
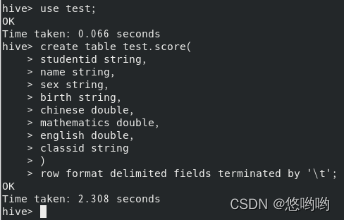
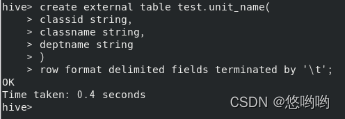
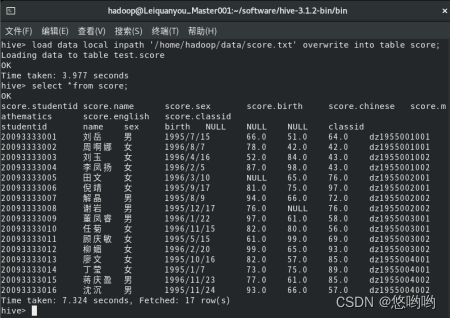
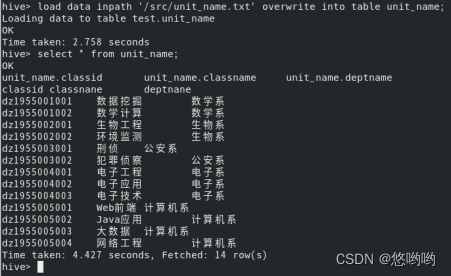
1.创建数据库(自己命名),score为内部表,unit_name为外部表,并加载数据。

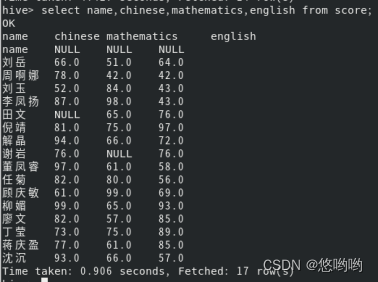
2.查询所有同学的语数英成绩
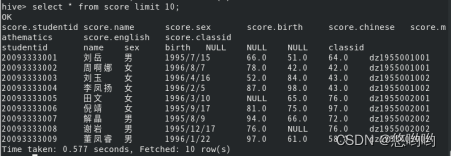
3.查看score表前十行数据
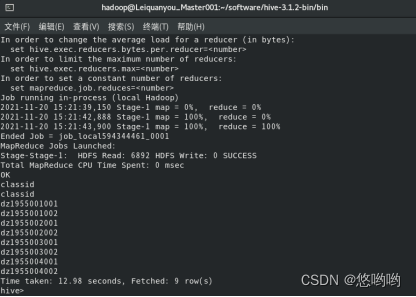
4.查看score表中不同的班级号
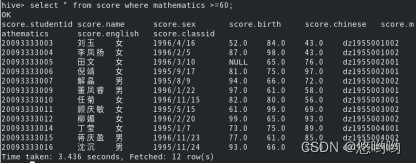
5.查看数学成绩及格的所有同学信息
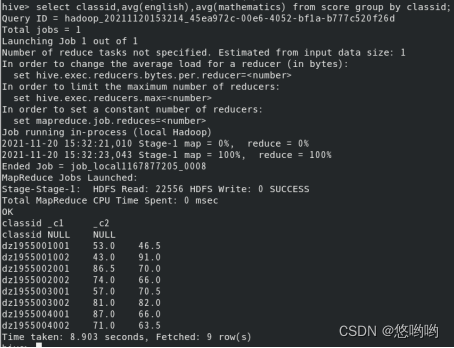
6.查看各个班英语、数学成绩平均分
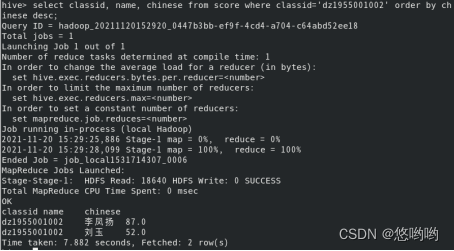
7.查看dz1955001002班的学生及语文成绩,并降序排序
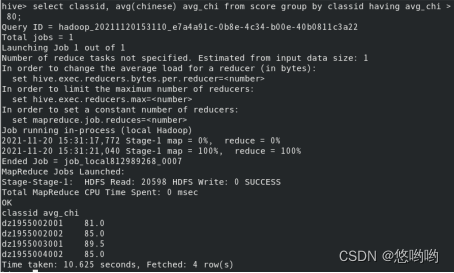
8.查看语文平均成绩大于80的班级
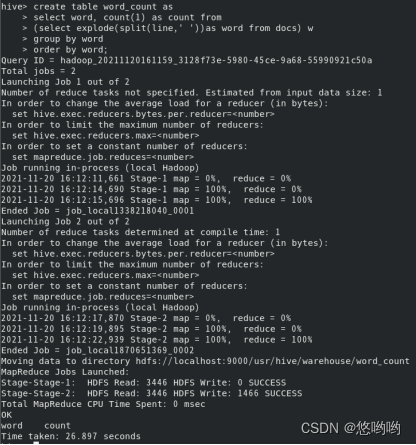
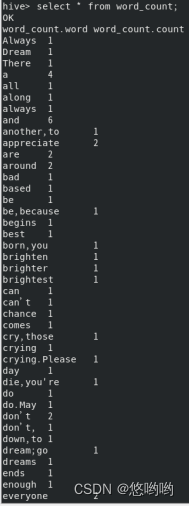
词频统计
重新使用实验2下载的英文短文,编写HiveQL程序,完成词频统计。要求给出代码及具体注释,程序运行结果截图。
出现的问题
1.hive的使用。
解决办法:
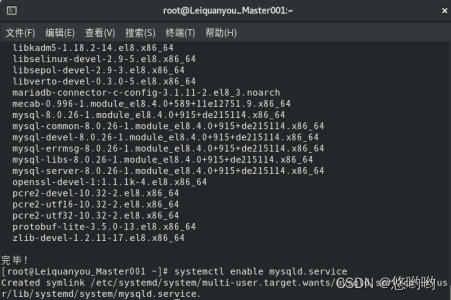
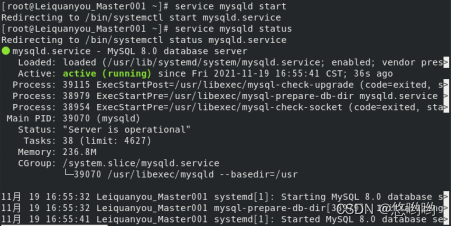
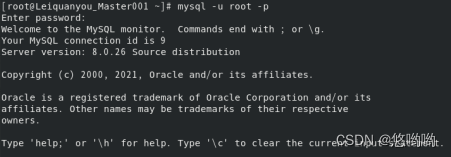
对于hive的使用,在hadoop集群里,先启动hadoop集群,再启动mysql服务,然后,再hive即可。
1、在hadoop安装目录下,sbin/start-all.sh。
2、在任何路径下,执行service mysql start (CentOS版本)、sudo /etc/init.d/mysql start (Ubuntu版本)
3、在hive安装目录下的bin下,./hive。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









