









学习资料来源:
ShowAI知识社区
Python机器学习算法入门教程

1. 逻辑回归算法(Logistic)
范数:
- L1: ∥ X ∥ 1 = ∑ i = 1 n ∣ x i ∣ \left \| X \right \|_{1} = \sum_{i= 1}^{n}\left | x_{i} \right | ∥X∥1=∑i=1n∣xi∣
- L2: ∥ X ∥ 2 = ∑ i = 1 n x i 2 \left \| X \right \|_{2} = \sqrt{\sum_{i= 1}^{n} x_{i}^{2}} ∥X∥2=∑i=1nxi2
回归算法:
- 1.Ridge回归(岭回归):平方损失+ α \alpha α ⋅ \cdot ⋅ L2
- 2.Lasso回归:平方损失+ α \alpha α ⋅ \cdot ⋅ L1
- 3.逻辑回归:逻辑损失+ α \alpha α ⋅ \cdot ⋅ L2
#logistic算法
from sklearn.linear_model import LogisticRegression # 从 scikit-learn库导入线性模型中的logistic回归算法
from sklearn.datasets import load_iris # 导入sklearn 中的自带数据集 鸢尾花数据集
from sklearn.model_selection import train_test_split # skleran 提供的分割数据集的方法
#载入鸢尾花数据集
iris_ds = load_iris()
# data 数组的每一行对应一朵花,列代表每朵花的四个测量数据,分别是:花瓣的长度,宽度,花萼的长度、宽度
print("data数组类型: {}".format(type(iris_ds['data'])))
print("前五朵花数据:\n{}".format(iris_ds['data'][:5]))
#分割数据集训练集,测试集
X_train_Lo, X_test, Y_train_Lo, Y_test = train_test_split(iris_ds['data'], iris_ds['target'],random_state=0)
#训练模型
model_Lo = LogisticRegression(max_iter=3000) # 设置最大迭代次数为3000,默认为1000.不更改会出现警告提示
model_Lo_fit = model_Lo.fit(X_train_Lo, Y_train_Lo) # 给模型喂入数据
#使用模型对测试集分类预测,并打印分类结果
print(model_Lo_fit.predict(X_test))
#最后使用性能评估器,测试模型优良,用测试集对模型进行评分
print(model_Lo_fit.score(X_test, Y_test))
# iris_target = data.target # 标签
# iris_df = pd.DataFrame(data=data.data, columns=data.feature_names)
# print(data.keys())
# print(data["DESCR"])
data数组类型: <class 'numpy.ndarray'>
前五朵花数据:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]]
[2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0
2]
0.9736842105263158
2. K近邻分类算法(KNN)

from sklearn.datasets import load_wine # 夹在红酒数据集
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
import numpy as np
wine_ds = load_wine()
print('红酒数据的键:\n{}'.format(wine_ds.keys()))
print('数据集描述:\n{}'.format(wine_ds['data'].shape))
# 训练
x_train_knn, x_test_knn, y_train_knn, y_test_knn = train_test_split(wine_ds['data'], wine_ds['target'],test_size=0.8, random_state=0)
model_KNN = KNeighborsClassifier(n_neighbors=10).fit(x_train_knn, y_train_knn)
score = model_KNN.score(x_test_knn, y_test_knn)
print(score)
# 给出一组数据对酒进行分类
x_wine_test = np.array([[11.8, 4.39, 2.39, 29, 82, 2.86, 3.53, 0.21, 2.85, 2.8, .75, 3.78, 490]])
predict_result = model_KNN.predict(x_wine_test)
print(predict_result)
print('分类结果:{}'.format(wine_ds['target_names'][predict_result]))
红酒数据的键:
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names'])
数据集描述:
(178, 13)
0.7342657342657343
[1]
分类结果:['class_1']
3. 贝叶斯定理
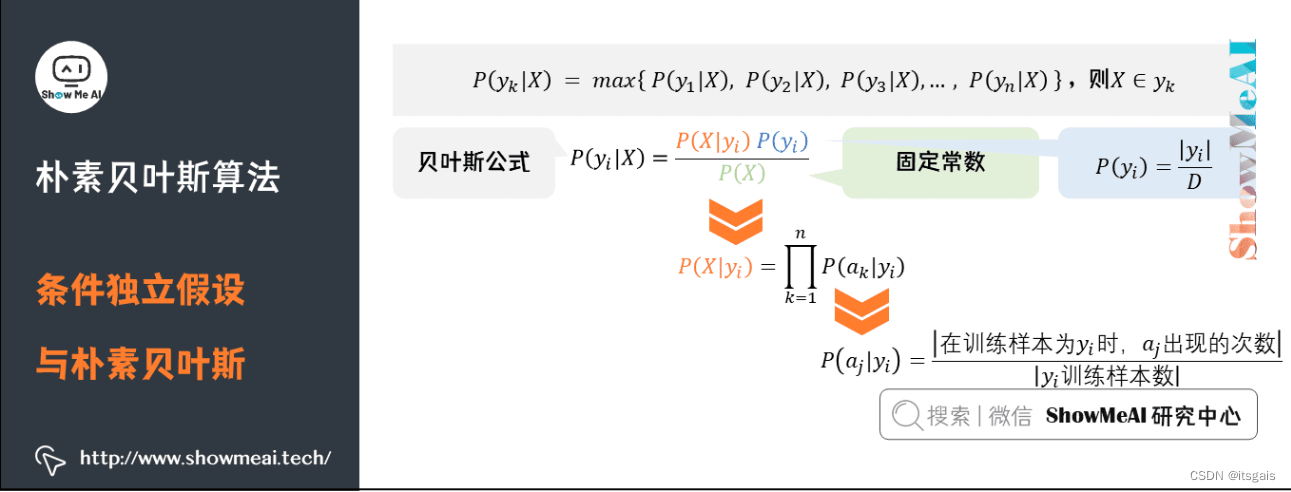
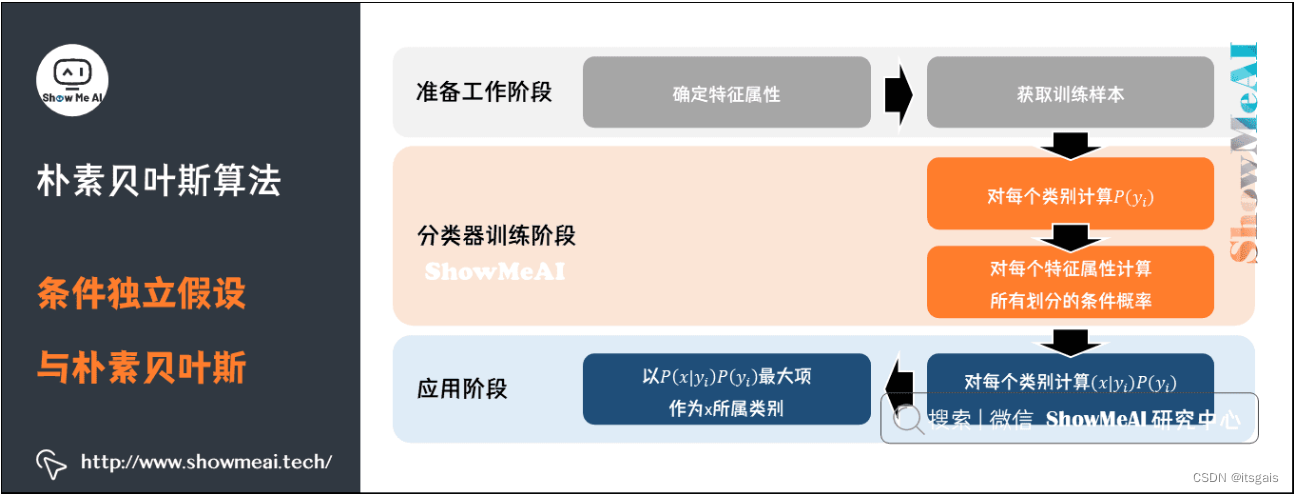
使用朴素贝叶斯算法,具体分为三步:
- 统计样本数,即统计先验概率 P(y) 和 似然度 P(x|y)。
- 根据待测样本所包含的特征,对不同类分别进行后验概率计算。
- 比较 y1,y2,…yn 的后验概率,哪个的概率值最大就将其作为预测输出。
from sklearn.datasets import load_iris
from sklearn.naive_bayes import GaussianNB # 导入朴素贝叶斯模型,选用高斯分类器
X_bayes, y_bayes = load_iris(return_X_y=True)
model_bayes = GaussianNB().fit(X_bayes, y_bayes)
result_bayes = model_bayes.predict(X_bayes)
print(result_bayes)
model_bayes_score = model_bayes.score(X_bayes, y_bayes)
print(model_bayes_score)
4. 决策树分类
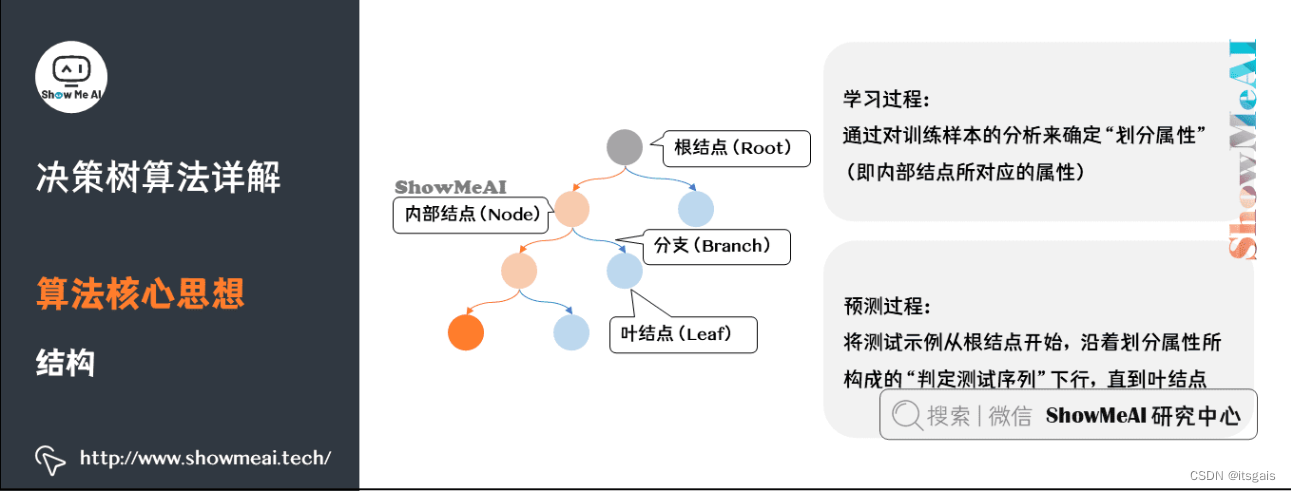
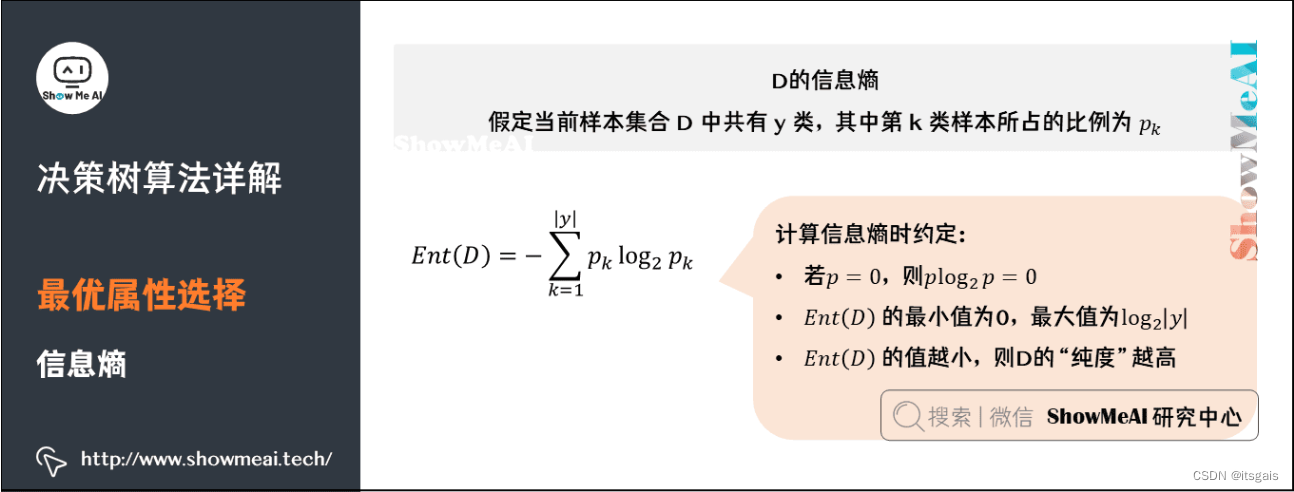



4.1 决策树实现步骤
通过前面内容的学习,我们已经大体掌握了决策树算法的使用流程。决策树分类算法的关键在于选择合适的“判别条件”,该判别条件会使正确的分类的样本“纯度”最高。想要选取合适的特征属性就需要使用“信息熵”与“信息增益”等计算公式。
- 1. 确定纯度指标
确定纯度指标,用它来衡量不同“特征属性”所得到的纯度,并选取使得纯度取得最大值的“特征属性”作为的“判别条件”。 - 2. 切分数据集
通过特征属性做为“判别条件”对数据集集合进行切分。注意,使用过的“特征属性”不允许重复使用,该属性会从特征集合中删除。 - 3. 获取正确分类
选择特征集合内的特征属性,直至没有属性可供选择,或者是数据集样本已经完成分类为止。切记要选择占比最大的类别做为分类结果。
import sklearn
from sklearn.datasets import load_wine
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
import numpy as np
print(sklearn.__version__)
wine_ds = load_wine()
x_train_tree, x_test_tree, y_train_tree, y_test_tree = train_test_split(wine_ds['data'], wine_ds['target'],test_size=0.2, random_state=0)
model_tree = DecisionTreeClassifier(criterion='entropy') # entropy:信息增益;gini: 基尼指数
model_tree.fit(x_train_tree, y_train_tree)
print(model_tree.score(x_test_tree, y_test_tree))
X_wine_test = np.array([[11.8, 4.39, 2.39, 29, 82, 2.86, 3.53, 0.21, 2.85, 2.8, .75, 3.78, 490]])
result_tree = model_tree.predict(X_wine_test)
print(result_tree)
print(wine_ds['target_names'][result_tree])
1.1.1
0.9444444444444444
[1]
['class_1']
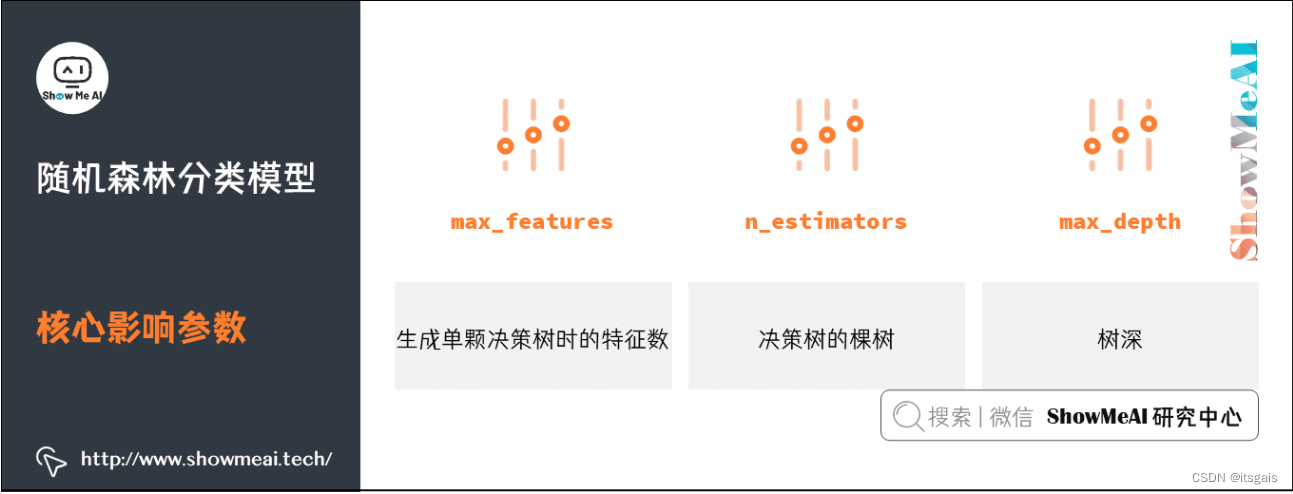
5. 随机森林算法


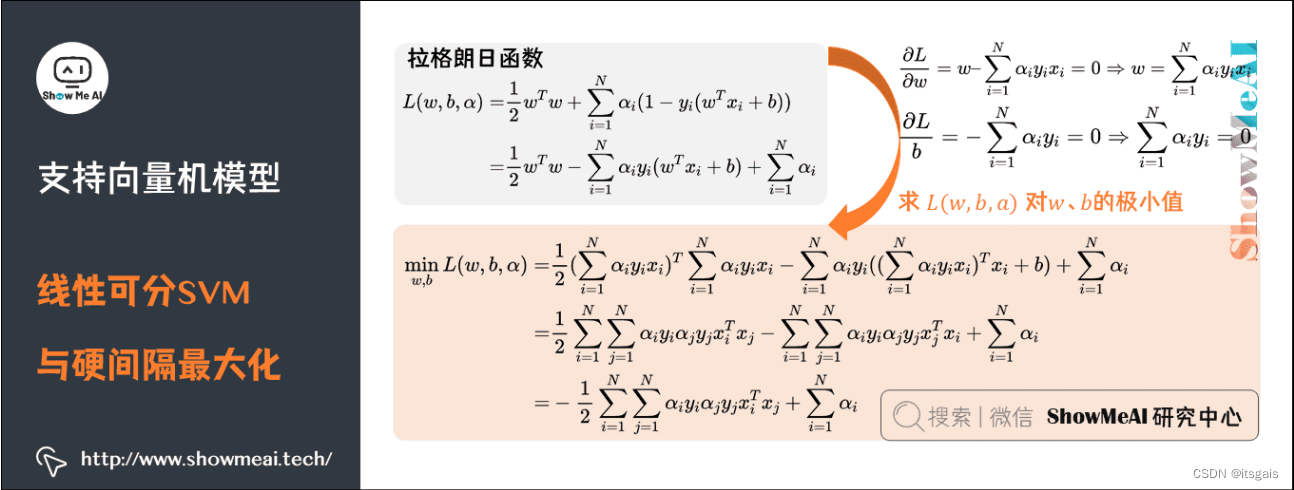
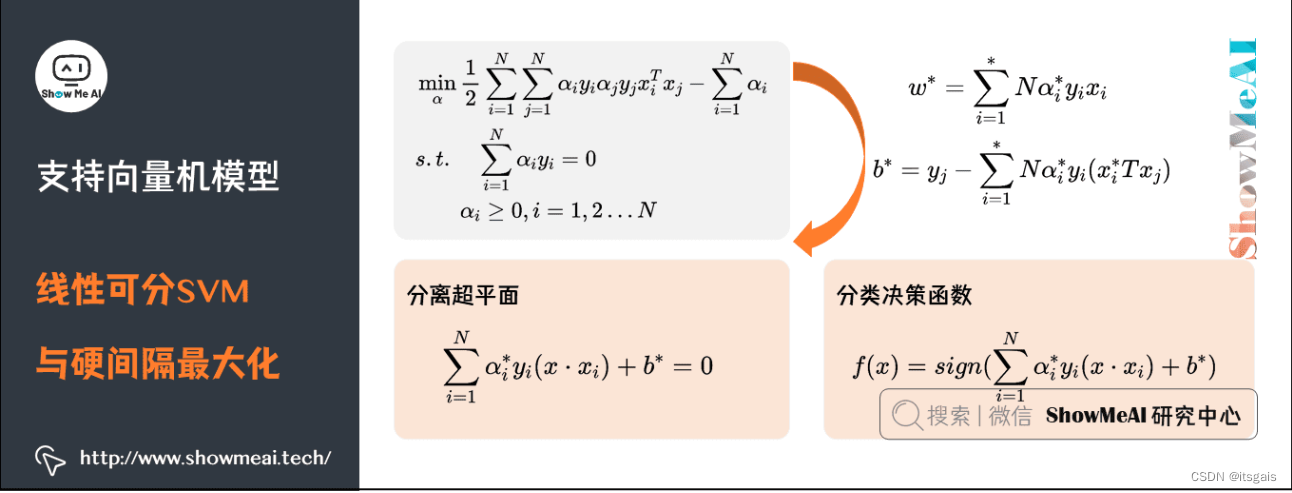
6. 支持向量机(SVM)——一种二分类模型
SVM 算法进行分类的大致过程进行总结,大致分为以下三步:
- 选取一个合适的数学函数作为核函数;
- 使用核函数进行高维映射,解决样本点线性不可分的问题;
- 最后用间隔作为度量分类效果的损失函数,找到使间隔最大的超平面,最终完成分类的任务。
# SVM_Test 1
from sklearn.datasets import load_iris
from sklearn.svm import SVC
import matplotlib.pyplot as plt
X, y = load_iris(return_X_y=True)
# kernel : {'linear', 'poly', 'rbf', 'sigmoid', 'precomputed'} or callable
model_svm = SVC(kernel='rbf').fit(X, y)
result_svm = model_svm.predict(X)
print(result_svm)
print(model_svm.score(X, y))
# 绘图
plt.figure()
plt.subplot(111)
plt.scatter(X[:, 0], X[:, 3], c=y.reshape((-1)), edgecolors='k', s=50)
plt.show()
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 2 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 1 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2
2 2]
0.9733333333333334

# SVM_Test 2
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, datasets
iris_ds, y = datasets.load_iris(return_X_y=True)
X = iris_ds[:, :2]
# gamma 值越大,SVM 就会倾向于越准确的划分每一个训练集里的数据,这会导致泛化误差较大和过拟合问题。
# C:错误项的惩罚参数 。它还控制平滑决策边界和正确分类训练点之间的权衡
# model_svm = svm.SVC(kernel='linear', C=1).fit(X, y)
# model_svm = svm.SVC(kernel='poly', degree=3).fit(X, y)
model_svm = svm.SVC(kernel='rbf', C=1).fit(X, y)
datasets.load_iris()
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
h = (x_max / x_min) / 100
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
plt.subplot(111)
Z = model_svm.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.Paired, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Paired)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('SVC with linear kernel')
plt.show()

7. 聚类算法:K-Means和K-Medoids
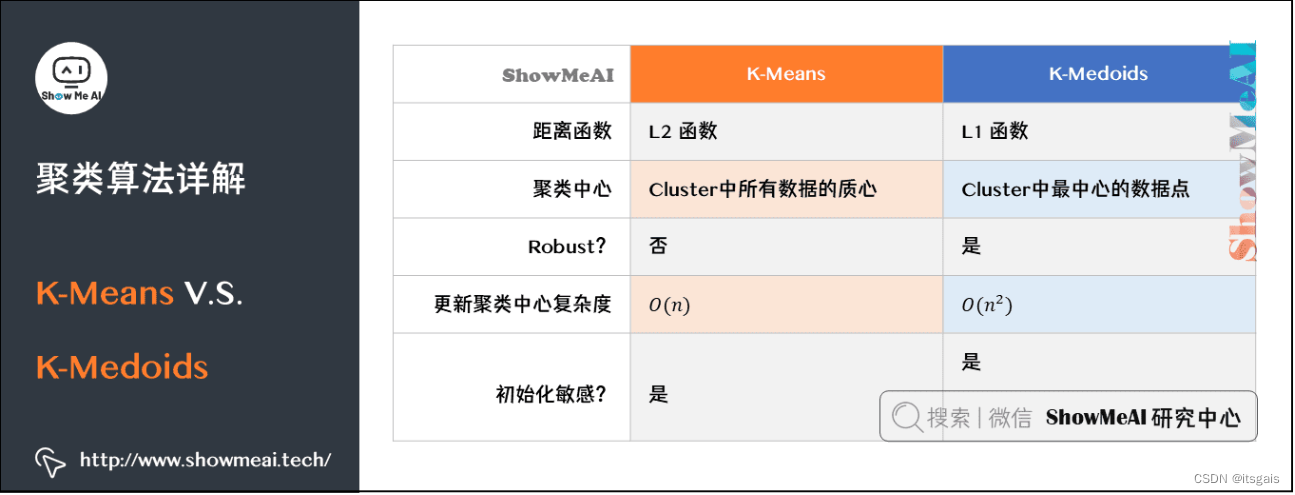
Kmeans.Kmeans() 参数介绍:
- algorithm:
- “auto” :默认值,自动根据数据值是否稀疏,来决定使用’full’是’elkan’
- “full”:表示使用传统的 K-measn 算法;
- “elkan”:表示使用 elkan-Means 算法,该算法可以减少不必要的距离计算,加快计算效率。
- n_cluster: 分类簇数量,默认8
- max_iter: 最大迭代次数,默认300
- n_init: 用不同的质心初始化值运行算法的次数,默认10
- init:
- " k-means++",默认值,用一种特殊的方法选定初始质心从而能加速迭代过程的收敛,效果最好;
- “random” 表示从数据中随机选择 K 个样本作为初始质心点;
- 提供一个 ndarray 数组,形如 (n_cluster,n_features),以该数组作为初始质心点。
- precompute_distance:
- “auto” :如果样本数乘以聚类数大于 12 million 的话则不予计算距离;
- True:总是预先计算距离;
- False:永远不预先计算距离。
- tol:算法收敛值,默认1e-4
- n_jobs: 计算所用进程数量
- random_state:随机数生成器种子
- verbose:默认值为 0,表示不输出日志信息;1 表示每隔一段时间打印一次日志信息;如果大于 1时,打印次数变得频繁
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
iris_ds = load_iris()
X = iris_ds.data[:, :2]
k = 3
km = KMeans(n_clusters=3).fit(X)
# labels_属性表示每个点的分簇号,会得到一个关于簇编号的数组
label_pred = km.labels_
# cluster_center 属性用来获取簇的质心点,得到一个关于质心的二维数组,形如[[x1,y1],[x2,y2],[x3,x3]]
centroids = km.cluster_centers_
fig = plt.figure(figsize=(12, 5))
plt.subplot(121)
plt.scatter(X[:, 0], X[:, 1], s=50)
plt.xlabel('花萼长度')
plt.ylabel('花萼宽度')
plt.title("未聚类之前")
plt.subplots_adjust(wspace=0.2)
plt.subplot(122)
plt.scatter(X[:, 0], X[:, 1], c=label_pred, s=50, cmap='cool')
# 绘制质心点
plt.scatter(centroids[:, 0], centroids[:, 1], c='black', marker='o', s=100)
plt.xlabel('花萼长度')
plt.ylabel('花萼宽度')
plt.title("K-Means算法聚类结果")
plt.show()

8. 聚类算法:DB-SCAN
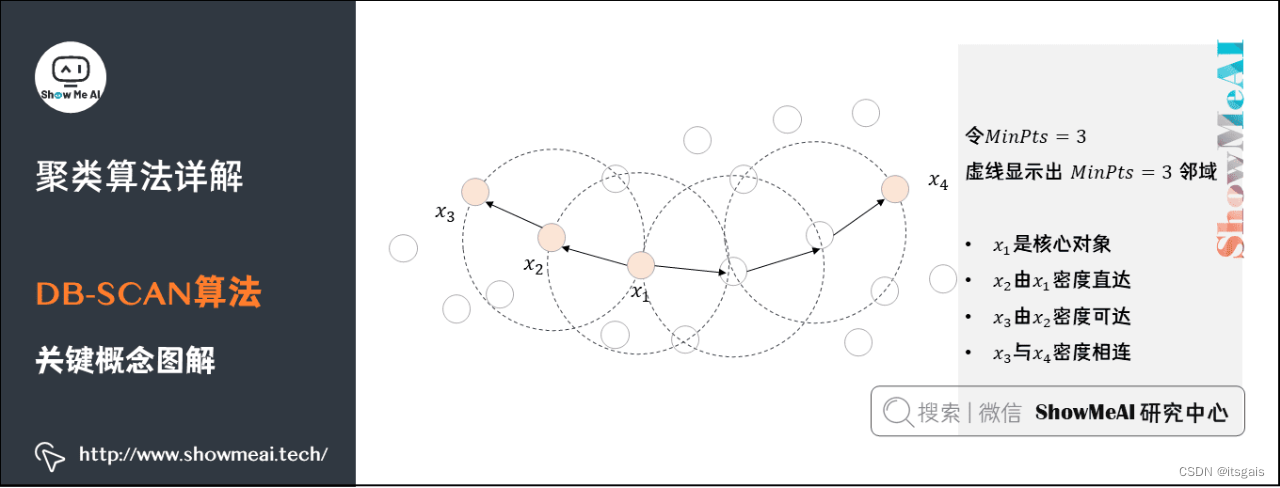
- 核心对象(Core Object):密度达到一定程度的点
- 密度直达:若 X i X_{i} Xi位于 X j X_{j} Xj的 ϵ \epsilon ϵ 邻域中,且 X j X_{j} Xj是核心对象,则称 X i X_{i} Xi由 X j X_{j} Xj密度直达
- 密度可达:对 X i X_{i} Xi与 X j X_{j} Xj,若存在样本序列 p 1 p_{1} p1, p 2 p_{2} p2, …, p n p_{n} pn,其中 p 1 p_{1} p1= X i X_{i} Xi, p n p_{n} pn= X j X_{j} Xj且 p i + 1 p_{i+1} pi+1由 p i p_{i} pi密度直达,则称 X j X_{j} Xj由 X i X_{i} Xi密度可达
- 密度相连(density-connected):所有密度可达的核心点就构成密度相连
9. 降维:PCA主成分分析

sklearn.decomposition.PCA的主要参数介绍:
- n_components: PCA降维后的特征维度数目
- whiten:是否进行白化,即对降维后的数据的每个特征进行归一化,让方差都为1,默认值是False
- svd_solver:奇异值分解SVD的方法,有4个可以选择的值:{auto, full, arpark, randomized}
除上述输入参数,还有两个 PCA 类的成员属性也很重要: - 1. explainedvariance:降维后的各主成分的方差值。
- 2. explainedvariance_ratio:降维后的各主成分的方差值占总方差值的比例
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=10000, n_features=3, cluster_std=[0.2, 0.1, 0.2, 0.2], random_state=1,
centers=[[3, 3, 3], [0, 0, 0], [1, 1, 1], [2, 2, 2]])
fig = plt.figure()
# ax = Axes3D(fig, rect=[0, 0, 1, 1], elev=30, azim=20)
ax = fig.add_subplot(projection='3d')
ax.scatter(X[:, 0], X[:, 1], X[:, 2], marker='x')

from sklearn.decomposition import PCA
model_pca = PCA(n_components=3) # n_components=维度/方差比例/'mle'
model_pca.fit(X)
X_new = model_pca.transform(X)
# y = np.ones(X_new.shape)
plt.scatter(X_new[:, 0], X_new[:, 1], marker='x')
plt.show()
print(model_pca.explained_variance_)
print(model_pca.explained_variance_ratio_)

[3.77913216 0.03326058 0.0322778 ]
[0.98295345 0.00865109 0.00839546]
10. 神经网络
Python 机器学习 Sklearn 库提供了多层感知器算法(Multilayer Perceptron,即 MLP),也就是我们所说的神经网络算法,它被封装在 sklearn.neural_network 包中,该包提供了三个神经网络算法 API,分别是:
- neural_network.BernoulliRBM,伯努利受限玻尔兹曼机算法,无监督学习算法;
- neural_network.MLPClassifier,神经网络分类算法,用于解决分类问题;
- neural_network.MLPRgression,神经网络回归算法,用于解决回归问题。
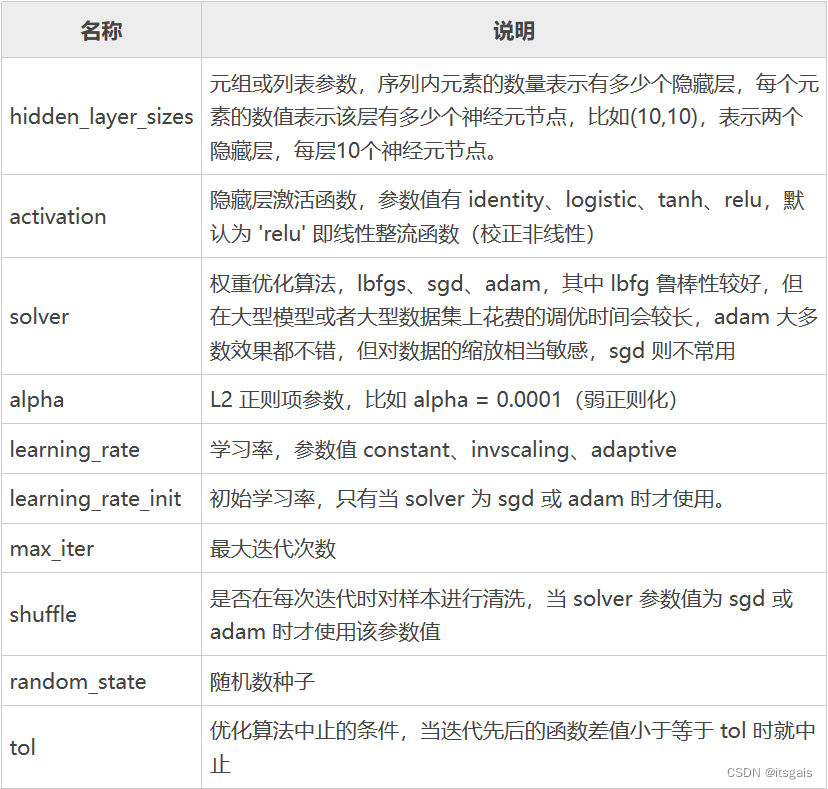
其中neural_network.MLPClassifier 分类器常用参数:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
def main():
iris = datasets.load_iris() # 加载鸢尾花数据集
# 用pandas处理数据集
data = pd.DataFrame(iris.data, columns=iris.feature_names)
print(iris.feature_names)
#数据集标记值 iris.target
data['class'] = iris.target
# 此处只取两类 0/1 两个类别的鸢尾花,设置类别不等于 2
data = data[data['class'] != 2]
# 对数据集进行归一化和标准化处理
scaler = StandardScaler()
# 选择两个特征值(属性)
X = data[['sepal length (cm)', 'petal length (cm)']]
#计算均值和标准差
scaler.fit(X)
# 标准化数据集(数据转化)
X = scaler.transform(X)
# 'class'为列标签,读取100个样本的的列表
Y = data[['class']]
# 划分数据集
X_train, X_test, Y_train, Y_test = train_test_split(X, Y)
# 创建神经网络分类器
mpl = MLPClassifier(solver='lbfgs', activation='logistic')
# 训练神经网络模型
mpl.fit(X_train, Y_train)
# 打印模型预测评分
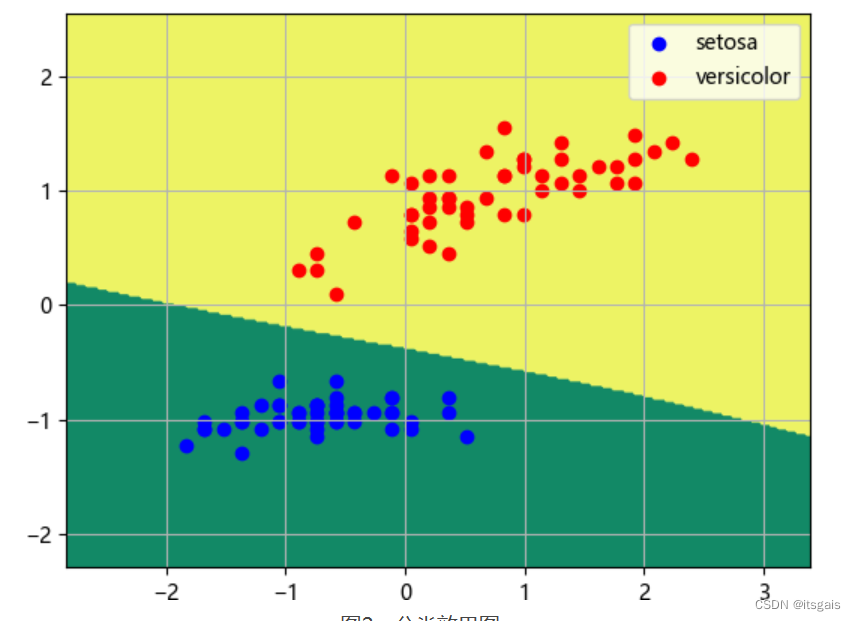
print('Score:\n', mpl.score(X_test, Y_test))
# 划分网格区域
h = 0.02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),np.arange(y_min, y_max, h))
Z = mpl.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
#画三维等高线图,并对轮廓线进行填充
plt.contourf(xx, yy, Z,cmap='summer')
# 绘制散点图
class1_x = X[Y['class'] == 0, 0]
class1_y = X[Y['class'] == 0, 1]
l1 = plt.scatter(class1_x, class1_y, color='b', label=iris.target_names[0])
class2_x = X[Y['class'] == 1, 0]
class2_y = X[Y['class'] == 1, 1]
l2 = plt.scatter(class2_x, class2_y, color='r', label=iris.target_names[1])
plt.legend(handles=[l1, l2], loc='best')
plt.grid(True)
plt.show()
main()















 326
326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









