






开篇
很久没有更新啦!这个系列其实是自己的一个学习笔记啦!这个系列的特色就是我们不再通过看视频的方式入门深度学习。
开篇的时候(2023.07.01),我想的是围绕自然语言处理的一些基础方法(代码方面,先for 循环、if判断实现,再利用 pytorch框架实现,最后达到能根据论文方法写代码;同理,在理论上,从简单模型的评价指标:查全率、查准率到复杂模型、数据集上),逐步深度学习。
手边我有一本《动手学深度学习》,会参考其中的学习任务等。
大语言模型,我使用的是星火大模型(默认)或其他大模型(标注),代码部分会让模型写一部分,然后我们在读懂的基础上,进行二次修改,主打的就是一个快。
我建立了一个在线表格里面建立了学习的路径,因为我是想学什么就去试试。接近一年没有写代码了,估计都快忘光咯!
第一章 文本匹配系列
文本匹配的个人理解:文本a与文本b的关系问题,有哪里相似【*主要为相似度】、有哪里不同、有哪里相关…
第一节 词袋模型
基本概念

利用费曼学习法将大语言模型告诉自己的内容将给别人听:通过大模型的讲解,我们了解了词袋模型的概念,将每个词都看成是独立的,这里的词在英文是每个单词,但对应中文的是每个词语。
- 我喜欢看电影。
用单词出现次数来表示:【“我”:1.“喜欢”:1,“看”:1,“电影”,1】 - 我喜欢看电影,尤其好看电影。
用单词出现次数来表示:【“我”:1,“喜欢”:1,“看”:1,“电影”:2,尤其:1,“好看的”:1】
探索性思考:
- “看”和"好看的"在人来分很简单,但是使用什么样的方法,让一句话可以分成这样一个个的词汇呢?这个在英文里很简单,将一句话拆成一个个单词就实现了,而在中文里,能有效将一句话分成“期待的词汇”是怎么做的呢?
- 将这些句子用单词出现次数来表示后,该怎么应用呢?
1. 分词工具


详细 jieba文档介绍
看了四篇,选了一篇,大模型提供了以下案例,提要求,每行加注释:
import jieba # 导入jieba库
text = "我爱自然语言处理技术" # 定义一个字符串变量text,存储需要分词的文本
seg_list = jieba.cut(text, cut_all=False) # 调用jieba.cut()函数对text进行分词,cut_all参数表示是否使用精确模式,默认为False
print(" / ".join(seg_list)) # 将分词结果用" / "连接成一个字符串并打印出来
输出:我 / 爱 / 自然语言 / 处理 / 技术
明日更新预告:jieba库的学习与使用
2. 应用举例

讲解:
比较“我喜欢看电影“”与“我喜欢看电影,尤其好看的电影”两句话有许多词汇是重复的,我们定义
[‘我’,‘喜欢’,‘看’,‘电影’,‘尤其’,‘好看的’]
文档1的向量表示[1,1,1,1,0,0]
文档2的向量表示[1,1,1,2,1,1]
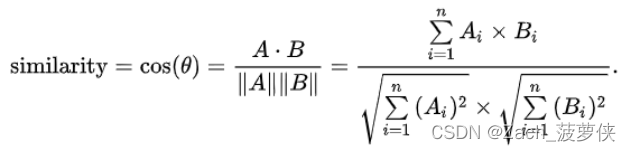
算了,懒得写了,让大模型算吧

综上,我们在原理层面已经学会了词袋模型的最初含义,它不仅仅在文本匹配中应用、在自然语言中应用,还在计算机视觉中有相当多的应用。
代码填空:
利用词袋模型构建向量,再使用余弦相似度计算两个文本相似程度(余弦相似度已经写好啦,转换为向量部分需要手写)
input:文本1
input:文本2
output:相似度
# 天黑了,想回去躺平,明天补一下!
# 2023.7.1 23:00 第一天还是更新一波吧
import jieba
def wenben2vector(wenben):
# 使用jieba将文本分为各个词
seg_list = jieba.cut(wenben)
# print(type(seg_list)) 没咋见过这个格式
# 将文本转化为list格式
wenben_list = list(seg_list)
# 在代码中发现问题,这里的vector实际上是两段文本共同决定的,因此只能做到这步啦
return wenben_list
def vector2similarity(list1,list2):
# 将两个list拼接起来
listnew = list1 + list2
# list1.extend(list2)
# 利用元组进行去重
listnew_qvchong = list(set(listnew))
# 获取向量长度
length = len(listnew_qvchong)
# print(listnew_qvchong)
# list2vector
vector1 = [0]*length
vector2 = [0]*length
for i in range(length):
# vector 的 第i个 值 是 list1 中的去重数据第i个元素的个数
vector1[i] = list1.count(listnew_qvchong[i])
vector2[i] = list2.count(listnew_qvchong[i])
# print(vector1)
# print(vector2)
# 公式: sum(a)* sum(b)/ 根号 (sum(a^2)x sum(b^2))
# 分子:对应位置相乘 numpy 可以直接 dot点乘
vector1_1 = [0]*length
for j in range(length):
vector1_1[j] = vector1[j] * vector2[j]
x1 = sum(vector1_1)
# 平方和计算
vector1_2 = [0]*length
vector2_2 = [0]*length
for j in range(length):
vector1_2[j] = vector1[j]**2
vector2_2[j] = vector2[j]**2
x2 = (sum(vector1_2)*sum(vector2_2))**(1/2)
similarity = x1 / x2
return similarity
def bow():
wenben1 = input('请输入文本1')
wenben2 = input('请输入文本2')
# wenben1 = "我需要购买一个电视机"
# wenben2 = "我购买了一个笔记本电脑"
wenben_list1 = wenben2vector(wenben1)
wenben_list2 = wenben2vector(wenben2)
similarity = vector2similarity(wenben_list1,wenben_list2)
print(similarity)
bow()
大模型给的参考1:
# 导入需要使用的库
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# 输入文本1和文本2
text1 = "我喜欢吃苹果"
text2 = "我不喜欢吃香蕉"
# 构建词袋模型,将文本转换为向量
vectorizer = CountVectorizer() # 创建CountVectorizer对象,用于将文本转换为向量
vec1 = vectorizer.fit_transform([text1]) # 将文本1转换为向量,并存储在vec1中
vec2 = vectorizer.transform([text2]) # 将文本2转换为向量,并存储在vec2中
# 计算余弦相似度
similarity = cosine_similarity(vec1, vec2) # 计算vec1和vec2之间的余弦相似度,结果存储在similarity中
print("相似度为:", similarity[0][0]) # 输出相似度值
参考案例2:
# 导入需要使用的库
import jieba
# 将文本转换为词袋向量
def wenben2vector(wenben):
vec = [] # 创建一个空列表,用于存储词袋向量
words = jieba.cut(wenben) # 使用jieba库将文本分词
for word in words:
if word not in stopwords: # 如果该词不是停用词,则将其添加到vec中
vec.append(word)
vec = list(set(vec)) # 将vec中的重复元素去除,并转换为列表类型
vec.sort() # 对vec进行排序
vector = [0] * len(vec) # 创建一个长度为vec长度的全零列表,用于存储词袋向量
for i in range(len(vec)):
vector[i] = vec.count(vec[i]) # 统计每个词在文本中出现的次数,并存储在vector中
return vector # 返回词袋向量
# 计算两个词袋向量之间的余弦相似度
def vector2similarity(vector1,vector2):
similarity = [] # 创建一个空列表,用于存储余弦相似度值
for i in range(len(vector1)):
similarity.append((vector1[i],vector2[i])) # 将两个词袋向量中对应位置的元素组成元组,存储在similarity中
similarity = sorted(similarity,key=lambda x:x[0]) # 按照第一个元素的大小对similarity进行排序
sum1 = sum([x[0] for x in similarity]) # 计算similarity中所有元素的第一个元素之和
sum2 = sum([x[1] for x in similarity]) # 计算similarity中所有元素的第二个元素之和
dot_product = sum1*sum2 # 计算similarity中所有元素的第一个元素与第二个元素的点积
norm1 = math.sqrt(sum1) # 计算similarity中所有元素的第一个元素的平方和的平方根
norm2 = math.sqrt(sum2) # 计算similarity中所有元素的第二个元素的平方和的平方根
similarity = dot_product/(norm1*norm2) # 根据余弦相似度公式计算相似度值,并存储在similarity中
return similarity # 返回余弦相似度值列表
# 从用户输入中获取文本1和文本2,并将它们转换为词袋向量,然后计算它们的余弦相似度
def bow():
wenben1 = input('请输入文本1') # 从用户输入中获取文本1
wenben2 = input('请输入文本2') # 从用户输入中获取文本2
vector1 = wenben2vector(wenben1) # 将文本1转换为词袋向量,并存储在vector1中
vector2 = wenben2vector(wenben2) # 将文本2转换为词袋向量,并存储在vector2中
similarity = vector2similarity(vector1,vector2) # 计算vector1和vector2之间的余弦相似度,并存储在similarity中
print("相似度为:",similarity[0][0]) # 输出相似度值
bow()

















 471
471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









