







Teacher Forcing
原来:预测1,1教2,2教3,3教4;
缺点:万一1错了,岂不对后面预测直接完了。
新方法:Teacher Forcing用于训练:
具体解释:先令1为True,1教2,再令2为True,2教3,以此类推。
补充昨天的缺失内容:
递归神经网络:输入(Input Layer)+隐层(Hidden Layer)+输出(Output Layer)
输入:t1,t2,t3,t4…tn(训练过程无法考虑时间序列,每个操作独立)
RNN:隐层多了一个往回的圈,把当前数据给下一次输入(有了相关性)
word2vec
将单词转化为特征向量
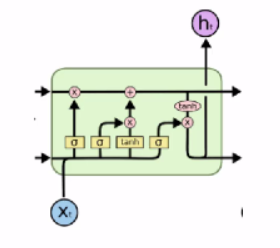
LSTM

参数C:控制模型复杂度,适当丢失信息;(启示:不是信息越多越好)
【理论部分】
训练集介绍:timit数据集
??.wav:音频内容
??.txt:文本内容
??.wrd:逐个词,出现时间的位置(时间对齐)
??.phn:逐个音标,时间标注
写代码前需要确定内容:
path:数据集的位置
label:数据标签
字典:每个字对应的id映射
考虑特殊字符0:起始字符,1:终止字符,2:…
创建语料表和特殊字符:句子开始,句子结束,‘-’空格
英文:a b c d 等
标点:\‘ , . 等
【实践部分】
【数据读入准备部分】:
写个读数据的小脚本
config(配置文件)

librosa包
请阅读《音频处理库—librosa的安装与使用》
https://blog.csdn.net/zzc15806/article/details/79603994
包括
✳音频读取函数load( )
重采样函数resample( )
✳短时傅里叶变换stft( )
幅度转换函数amplitude_to_db( )
频率转换函数hz_to_mel( )等
详细可参考librosa官网 http://librosa.github.io/ librosa/core.html
文本准备:
略(上面有)















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









