







- 矢量加法可以提升速度,经可能多使用矢量加法而非循环
a = torch.zero(1000)
b= torch.zero(1000)
start = time()
d = a + b
print(time() - start)
-
pytorch 基于numpy的广播机制
a = torch.ones(3) b = 10 print(a + b) # tensor([11., 11., 11.] -
如果我们想要修改
tensor的数值,但是又不希望被autograd记录(即不会影响反向传播),那么我么可以对tensor.data进行操作
线性回归的本质
它是一个单层的神经网络,基本要素包括模型、训练数据、损失函数和优化算法。
模型是一个y= ax1+bx2+c的一个函数式
训练数据可以是自己生成的随机数,本次的训练数据labels是在随机生成的features乘以目标参数的结果加上正态分布的噪点。
损失函数有平方损失函数和交叉熵函数,他们影响了优化算法。
优化算法用损失函数得出的损失算梯度,梯度运算是通过对mini-batch的梯度的平均值乘以学习率得到的。修正参数。
softmax回归的本质
不同与线性回归输出连续值且只能输出一个值,softmax回归可以输出多个离散值。值的个数等于标签数。
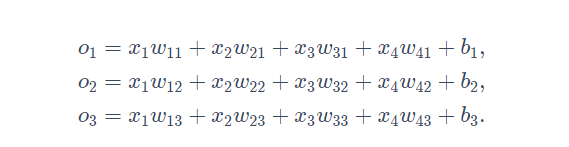
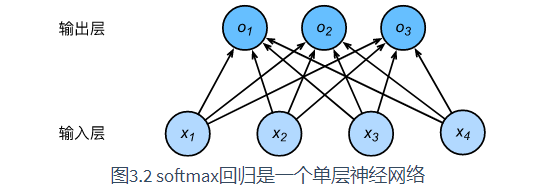
如处理分类问题时,一个简单的办法是将输出值o_i当作第i预测类别的置信度,并将值最大的输出所对应的类作为预测输出,例如,如果o1,o2,o3o_1,o_2,o_3o1,o2,o3分别为0.1,10,0.1 由于10最大,那么预测类别为2。
softmax运算符(softmax operator)会通过指数化每个值并归一化,使得所有的概率相加为1。
其损失函数使用交叉熵,因为我们在分类算法中不去考虑每个输出值到底是多少,我们只关心它们中最大的概率对应的样本是哪个。所以不适用过于严格的平方损失函数。交叉熵函数更适合衡量两个概率分布差异。
在对minist-fashion的分类实验中,使用的是相同的sgd优化函数。
分布差异。
在对minist-fashion的分类实验中,使用的是相同的sgd优化函数。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









