







状态机模型
在分析fork()和exec()之前,我们需要知道计算机的状态机模型。即从状态机的角度看程序的运行,理解进程和进程切换。
进程=状态机=内存+寄存器
换句话说,有了某一时刻的内存和寄存器值,我们就可以还原那一时刻的状态机状态
fork源码解析
fork()的作用是复制一个进程。所以在分析fork()的源码之前,我们先来想想如果要完完整整地fork()一个进程,需要复制哪些东西?
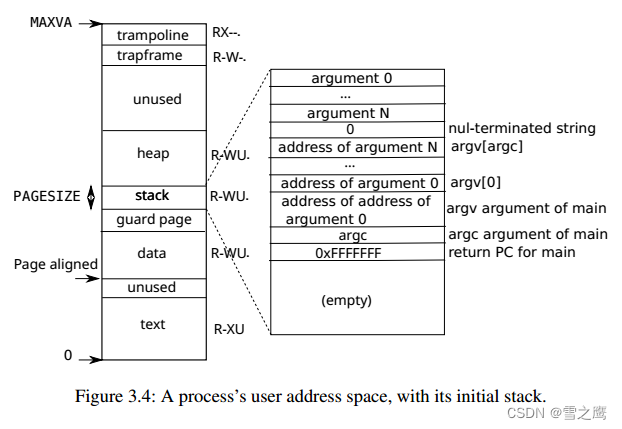
上图代表一个用户地址空间,一个进程就是有上图各部分组成的,包括代码段text,数据段data,堆区heap,栈区stack,trampoline page和trapframe page以及guard page。所以我们就是要原封不动地复制一个这样的用户地址空间。
下面的代码就是严格按照这张图编写的,配合理解效果最佳。
fork():
// Create a new process, copying the parent.
// Sets up child kernel stack to return as if from fork() system call.
int fork(void)
{
int i, pid;
struct proc *np;
struct proc *p = myproc();
// Allocate process.
// 分配一个proc结构体
if ((np = allocproc()) == 0)
{
return -1;
}
// Copy user memory from parent to child.
// 复制父进程的页表
if (uvmcopy(p->pagetable, np->pagetable, p->sz) < 0)
{
freeproc(np);
release(&np->lock);
return -1;
}
np->sz = p->sz;
np->parent = p; // 成为父子关系
// copy saved user registers.
*(np->tf) = *(p->tf); // tf的信息也要全部复制,这样才能保证复制后的进程同样正常运行
// Cause fork to return 0 in the child.
np->tf->a0 = 0; // 这一步是区分父进程与子进程的关键
// increment reference counts on open file descriptors.
// 复制已打开的文件
for (i = 0; i < NOFILE; i++)
if (p->ofile[i])
np->ofile[i] = filedup(p->ofile[i]);
np->cwd = idup(p->cwd);
safestrcpy(np->name, p->name, sizeof(p->name));
pid = np->pid;
np->state = RUNNABLE; // 子进程可以被调度
np->trace_mask = p->trace_mask;
release(&np->lock);
return pid;
}
fork()函数做的事情有两件:
- 复制整个用户地址空间
- 初始化新的proc
要复制一个一模一样的用户地址空间很简单,uvmcopy()就能做到。原理就是复制整个(p->size)页表,使它们指向同一个物理地址(COW Fork是这样,如果是xv6原始的fork需要复制整个物理内存)。
而复制完用户地址空间后,其它部分的代码就是在初始化刚刚分配的结构体proc了。这里部分的结构体变量是直接复制父进程的,包括sz,tf,ofile,cwd等,而改变的有parent,pid,context等。我们主要从fork()的返回值入手,分析fork()的整体流程。
if(fork() > 0)
{
// 父进程
}
else if(fork() == 0)
{
// 子进程
}
else
{
// 失败
}
我们都知道fork()的返回值有两种情况:父进程返回子进程的pid,子进程返回0。fork()源码解释了为什么。父进程很好解释,因为当前整个fork()函数的执行都是在父进程里执行的,最后的return pid自然返回的也是子进程的pid。而对于子进程,只有在np->state = RUNNABLE后,直到release(&np->lock)那一刻,子进程才是可以被调度器调度的(关于调度器可以参考这篇文章:xv6的Scheduling)。
在明白了xv6调度器的工作原理后,我们知道进程在运行时会被定时器打断,流程类似于yield()->sched()->swtch()->scheduler()->swtch()->sched()->yield()。但对于一个还没有运行的进程,这样的流程显然是不行的,它需要一个初始化的程序,这个程序就是forkret(),forkret()会在allocproc()函数里被调用。
allocproc():
// Look in the process table for an UNUSED proc.
// If found, initialize state required to run in the kernel,
// and return with p->lock held.
// If there are no free procs, return 0.
// 遍历然后分配一个UNUSED proc,并对结构体成员初始化
static struct proc *
allocproc(void)
{
struct proc *p;
for (p = proc; p < &proc[NPROC]; p++)
{
acquire(&p->lock);
if (p->state == UNUSED)
{
goto found;
}
else
{
release(&p->lock);
}
}
return 0;
// 对刚分配的UNUSED proc进行初始化
found:
p->pid = allocpid(); // 分配pid
// Allocate a trapframe page.
// 为trapframe分配物理空间
if ((p->tf = (struct trapframe *)kalloc()) == 0)
{
release(&p->lock);
return 0;
}
// For the Lab03:Allocate a usyscall page.
if ((p->usc = (struct usyscall *)kalloc()) == 0)
{
release(&p->lock);
return 0;
}
// An empty user page table.
// 分配页表
// 注意在这里进行了trampoline page和刚分配的trapframe page的映射,因为它是每个页表都需要的
p->pagetable = proc_pagetable(p);
// Set up new context to start executing at forkret,
// which returns to user space.
// 设置上下文context的ra和sp,进程第一次被调度时会跳转到forkret()函数
memset(&p->context, 0, sizeof p->context);
p->context.ra = (uint64)forkret;
p->context.sp = p->kstack + PGSIZE;
// For the Lab03
p->usc->pid = p->pid;
return p;
}
allocproc()主要是初始化了proc结构体,其中p->context.ra = (uint64)forkret就指定了第一次被调度的入口函数。原因是从调度器的视角来看,在需要调度一个新进程时,它会执行swtch(&c->scheduler, &p->context),其中&p->context当作参数传入,ra就是返回的函数地址。
forkret():
// A fork child's very first scheduling by scheduler()
// will swtch to forkret.
void forkret(void)
{
static int first = 1;
// Still holding p->lock from scheduler.
release(&myproc()->lock);
if (first)
{
// init进程创建时才会进入此处
// File system initialization must be run in the context of a
// regular process (e.g., because it calls sleep), and thus cannot
// be run from main().
// 放在context处:1.fsinit会调用sleep,而sleep只有在进程创建时才能使用(p->state=sleep)
// 2.新进程会从文件系统中读可执行文件,需要提前初始化好
first = 0;
fsinit(minor(ROOTDEV));
}
usertrapret();
}
forkret()首先会释放进程锁,然后判断first变量(用于init进程,之后分析),这里直接跳过这个判断。最后,它会直接调用usertrapret(),相比以前少了sched()和yield()两步,这就是进程第一次被调度和运行时被调度的区别。
usertrapret()之后的过程可以参考:xv6的Trap流程。总之,它会回到用户空间,返回到调用它的地方。还记得我们是怎么拷贝的父进程吗,他把父进程的text,data和stack等都拷贝了,所以我们返回的地址也是父进程应该返回的地址处,即fork()函数返回的地方。
回到最初的问题,为什么返回0?我们再回到fork()函数:
np->tf->a0 = 0
在Riscv中,寄存器a0会在函数返回时,用作存储返回值的寄存器。而存储于np->tf中的数据在进程返回用户空间时都会被恢复到各自对应的寄存器中,所以我们看到fork()的子进程返回0。
exec()源码解析
分析完了fork()函数,我们再来分析fork()的好兄弟exec(),它的作用是替换一个进程,通常紧跟在fork()函数后面。
exec()要稍微复杂一点,需要文件系统方面的知识(可参考:xv6的File system),这里不对细节过分深究,主要了解以下exec()的大体流程。
还是和fork()一样,我们先来想想要exec()(替换)一个进程,需要替换哪些东西?
把上面的图搬下来,在这里这张图的作用要更大一些。从图中可以知道,由于各部分用途不同,我们需要替换掉text,data,而stack和heap,trampoline page和trapframe page则是重新分配。
exec():
int exec(char *path, char **argv)
{
char *s, *last;
int i, off;
uint64 argc, sz, sp, ustack[MAXARG + 1], stackbase;
struct elfhdr elf;
struct inode *ip;
struct proghdr ph;
pagetable_t pagetable = 0, oldpagetable;
struct proc *p = myproc();
begin_op(ROOTDEV); // FS事务开始
if ((ip = namei(path)) == 0) // 解析出path对应的inode
{
end_op(ROOTDEV);
return -1;
}
ilock(ip);
/*****text+data替换*****/
// Check ELF header
if (readi(ip, 0, (uint64)&elf, 0, sizeof(elf)) != sizeof(elf)) // 校验elf header
goto bad;
if (elf.magic != ELF_MAGIC)
goto bad;
if ((pagetable = proc_pagetable(p)) == 0) // 获得页表
goto bad;
// Load program into memory.
sz = 0;
for (i = 0, off = elf.phoff; i < elf.phnum; i++, off += sizeof(ph))
{
if (readi(ip, 0, (uint64)&ph, off, sizeof(ph)) != sizeof(ph)) // 读取program header
goto bad;
if (ph.type != ELF_PROG_LOAD)
continue;
if (ph.memsz < ph.filesz)
goto bad;
if (ph.vaddr + ph.memsz < ph.vaddr)
goto bad;
if ((sz = uvmalloc(pagetable, sz, ph.vaddr + ph.memsz)) == 0) // 建立pa与va的映射
goto bad;
if (ph.vaddr % PGSIZE != 0)
goto bad;
if (loadseg(pagetable, ph.vaddr, ip, ph.off, ph.filesz) < 0) // 完成pa内容的填充(即把可执行文件指向pa)
goto bad;
}
iunlockput(ip);
end_op(ROOTDEV); // FS事务结束
ip = 0;
p = myproc();
uint64 oldsz = p->sz;
/*****stack分配*****/
// Allocate two pages at the next page boundary.
// Use the second as the user stack.
// 再增加两页作为用户栈和guard page
sz = PGROUNDUP(sz);
if ((sz = uvmalloc(pagetable, sz, sz + 2 * PGSIZE)) == 0) // 再分配两页,一页stack,一页guard page
goto bad;
uvmclear(pagetable, sz - 2 * PGSIZE); // 用作guard page
sp = sz;
stackbase = sp - PGSIZE;
// 参数传入
// Push argument strings, prepare rest of stack in ustack.
for (argc = 0; argv[argc]; argc++)
{
if (argc >= MAXARG)
goto bad;
sp -= strlen(argv[argc]) + 1;
sp -= sp % 16; // riscv sp must be 16-byte aligned
if (sp < stackbase)
goto bad;
if (copyout(pagetable, sp, argv[argc], strlen(argv[argc]) + 1) < 0)
goto bad;
ustack[argc] = sp;
}
ustack[argc] = 0;
// push the array of argv[] pointers.
sp -= (argc + 1) * sizeof(uint64);
sp -= sp % 16;
if (sp < stackbase)
goto bad;
if (copyout(pagetable, sp, (char *)ustack, (argc + 1) * sizeof(uint64)) < 0)
goto bad;
// arguments to user main(argc, argv)
// argc is returned via the system call return
// value, which goes in a0.
p->tf->a1 = sp;
// Save program name for debugging.
for (last = s = path; *s; s++)
if (*s == '/')
last = s + 1;
safestrcpy(p->name, last, sizeof(p->name));
// Commit to the user image.
oldpagetable = p->pagetable;
p->pagetable = pagetable; // 替换新页表
p->sz = sz; // p->sz代表从text到stack的大小(sz最后幅值的地方在stack分配处)
p->tf->epc = elf.entry; // initial program counter = main
p->tf->sp = sp; // initial stack pointer
proc_freepagetable(oldpagetable, oldsz); //释放旧页表
if (p->pid == 1)
vmprint(p->pagetable);
return argc; // this ends up in a0, the first argument to main(argc, argv)
bad:
if (pagetable)
proc_freepagetable(pagetable, sz);
if (ip)
{
iunlockput(ip);
end_op(ROOTDEV);
}
return -1;
}
我们将exec()分为三部分进行分析:
- text+data替换
- stack分配
- 参数写入
text+data替换
在看代码之前,我们先了解一下一个可执行文件的构成。它由ELF header,Program header和Segment构成。
- ELF header-标识Program header
- magic:必须与ELF_MAGIC匹配,表示xv6可运行的文件(linux,windows也是如此)、
- phnum:Program header的个数
- phoff:Program header的位置
- Program header-标识Segment
- vaddr:Segment的起始位置
- memsz:Segment在内存中的大小
- filesz:Segment在磁盘中的大小
- off:Segment在inode中的偏移
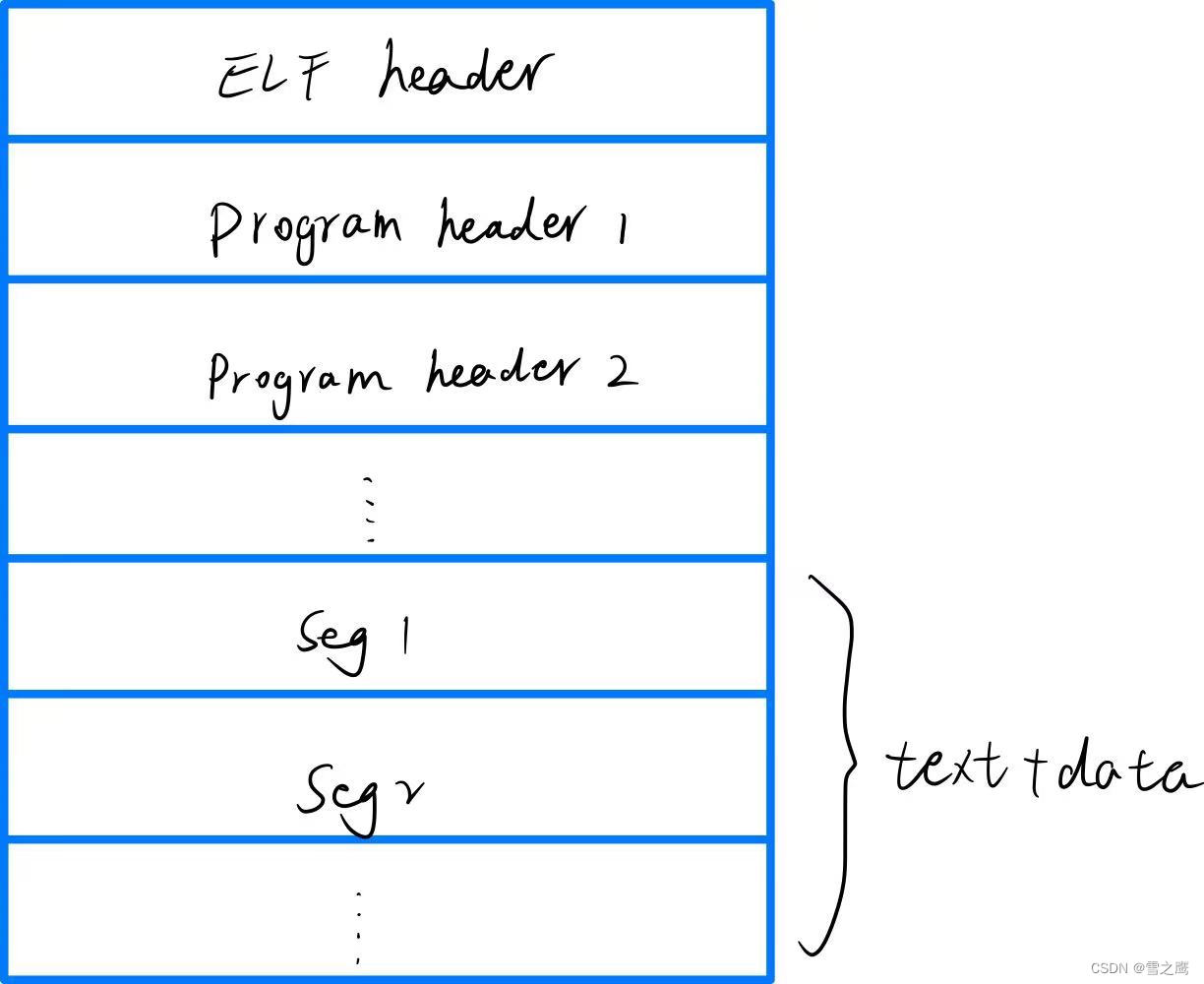
上图就是各部分在文件中的分布,拿“ls”举例,“ls”的text和data就在这里面,而stack和heap属于加载到内存才有的。我们通过ELF header得到Proram header,在得到对应的Segment(代码段或数据段)。
在得到Program header后,我们首先需要通过uvmalloc()在页表中建立起新的va和pa的映射,然后调用loadseg()把pa对应的内容替换掉,我们text和data的替换就完成了。
loadseg():
// Load a program segment into pagetable at virtual address va.
// va must be page-aligned
// and the pages from va to va+sz must already be mapped.
// Returns 0 on success, -1 on failure.
// 将可执行文件(cat,ls...)写入到va指向的内存中
static int
loadseg(pagetable_t pagetable, uint64 va, struct inode *ip, uint offset, uint sz)
{
uint i, n;
uint64 pa;
if ((va % PGSIZE) != 0)
panic("loadseg: va must be page aligned");
for (i = 0; i < sz; i += PGSIZE)
{
pa = walkaddr(pagetable, va + i); // 得到va对应的pa
if (pa == 0)
panic("loadseg: address should exist");
if (sz - i < PGSIZE)
n = sz - i;
else
n = PGSIZE;
if (readi(ip, 0, (uint64)pa, offset + i, n) != n) // 填充pa
return -1;
}
return 0;
}
loadseg()函数负责段的替换,将可执行文件(cat,ls…)写入到va指向的内存中。
stack分配
按照图很容易看出代码的逻辑。在替换掉代码段和数据段之后再新增两页,一页用于guard page,一页用于stack。并且由最后的p->sz = sz可以得到,我们的进程大小=text+data+stack。
stack分配结束后,还剩下相当大一部分区域用于heap。heap并不需要单独为它初始化,它也会通过页表与物理内存映射,但编译器不会为我们像stack一样做类似压栈出栈的处理,相反它选择什么都不做。所以我们在使用时只要是分配了这段内存,就需要即使释放它。
参数写入
我们的新进程运行时是需要参数的,这就需要把exec()里的参数传递给进程,也就是传递给main()函数。
int main(int argc, char *argv[])
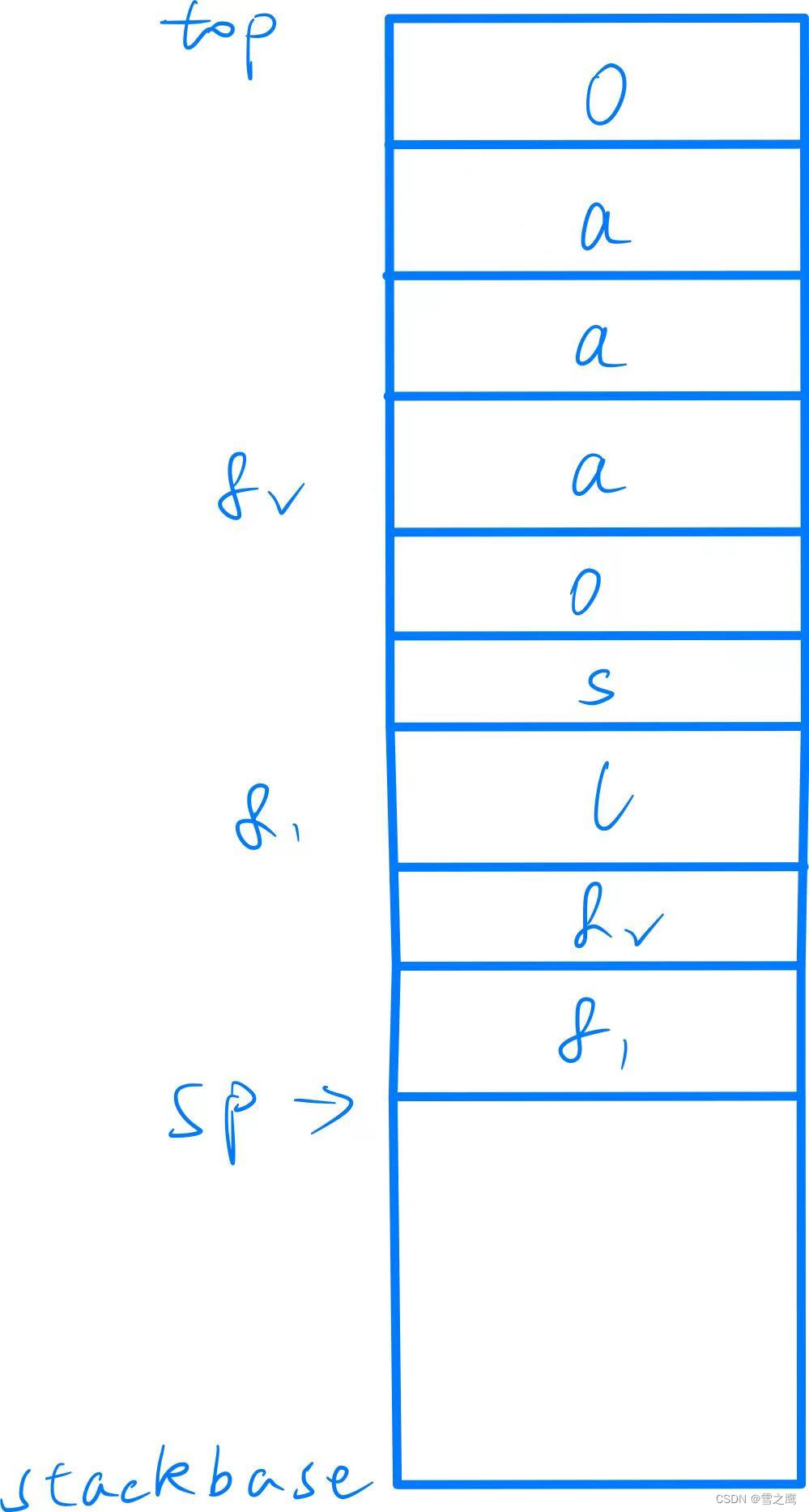
exec()中需要传递给新进程的参数通过保存在新进程堆栈里完成传递。以exec(“ls”, “aaa”)为例,它在堆栈中的分布如上图所示。在保存完字符串“ls”,“aaa”之后,我们还需要字符串的地址,用于告知字符串的位置,地址会紧跟在字符之后保存。此时sp的位置,就是第一个参数的字符串地址。
搞定了要传入的参数,还需要把参数传递给函数main(),在分析之前需要补充一个知识。
Riscv xv6中函数调用遵循__fastcall约定,即参数传递是通过寄存器(a0-a7)进行(而非堆栈),每个函数都会从这些寄存器中读取属于它的参数。
而传递给a0和a1的代码在exec()中是这两处:
p->tf->a1 = sp; // 将sp指针(指向参数的地址)赋值给a1
...
return argc; // 将参数的个数幅值给a0
p->tf里面存储的数据都会在系统调用结束时返回对应的寄存器。至此,exec()分析完成。
xv6的第一个进程
在分析完fork()和exec()后,我们可以看看xv6的第一个进程是怎样启动的。
main():
// start() jumps here in supervisor mode on all CPUs.
void
main()
{
if(cpuid() == 0){
···
userinit(); // first user process
__sync_synchronize();
started = 1;
}
...
scheduler();
}
在内核启动的main()中,第一个用户进程在userinit()中定义,随后在scheduler()调用后被调度。
userinit():
// a user program that calls exec("/init")
// od -t xC initcode
uchar initcode[] = {
0x17, 0x05, 0x00, 0x00, 0x13, 0x05, 0x05, 0x02,
0x97, 0x05, 0x00, 0x00, 0x93, 0x85, 0x05, 0x02,
0x9d, 0x48, 0x73, 0x00, 0x00, 0x00, 0x89, 0x48,
0x73, 0x00, 0x00, 0x00, 0xef, 0xf0, 0xbf, 0xff,
0x2f, 0x69, 0x6e, 0x69, 0x74, 0x00, 0x00, 0x01,
0x20, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00};
// Set up first user process.
void userinit(void)
{
struct proc *p;
p = allocproc();
initproc = p;
// allocate one user page and copy init's instructions
// and data into it.
uvminit(p->pagetable, initcode, sizeof(initcode));
p->sz = PGSIZE;
// prepare for the very first "return" from kernel to user.
p->tf->epc = 0; // user program counter
p->tf->sp = PGSIZE; // user stack pointer
safestrcpy(p->name, "initcode", sizeof(p->name));
p->cwd = namei("/");
p->state = RUNNABLE;
release(&p->lock);
}
在xv6中,第一个进程直接以机器码的形式运行,存储在在initcode的数组里。直接看当然看不出它在干什么,反汇编这段代码:
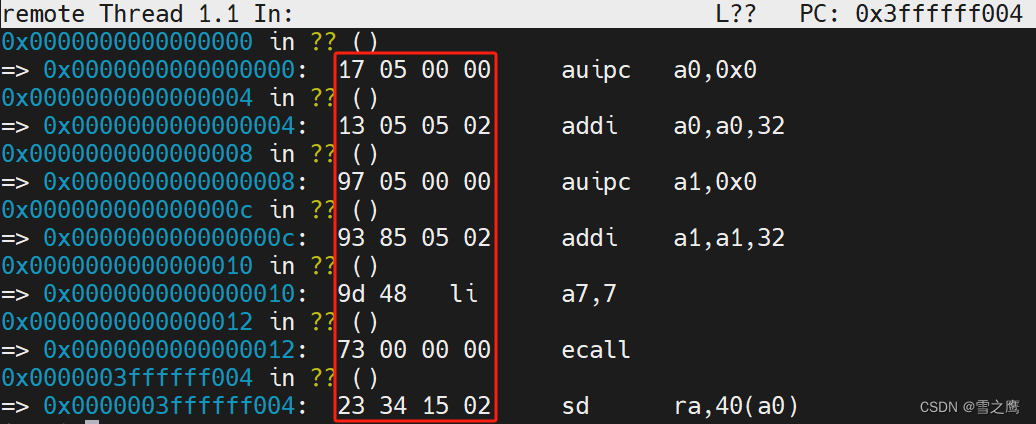
结合代码和注释,这段代码的作用是执行init进程。当scheduler()函数被调用后,它会作为唯一的进程被调度。被调度后程序执行7号系统调用,对应exec(),而传入的参数就是"init",也就是我们的“始祖”进程。
而这里还有一个之前忽略掉的细节。还记的forkret()吗?allocproc()会设置返回函数为forkret()。forkret()中的if就在这里执行的,它里面只有一个函数:
fsinit(minor(ROOTDEV))
fsinit()用于文件系统的初始化。这里有一个疑问了,为什么文件系统的初始化要放在进入第一个进程前的上下文中呢?放在main()函数里或者第一个进程里不行吗?
为什么不在main()中被调用?那说明fsinit()文件系统初始化函数肯定和其它系统初始化函数有不同。这个不同点就在sleep()函数,fsinit()会调用sleep()函数而其它初始化函数不会(sleep()函数可参考:xv6中的sleep()),而sleep()函数是由进程调用的。所以对于一个进程都没有创建的内核初始化函数main()来说,调用sleep()是会出问题的。
所以,我们应该在第一个进程创建后就立刻调用fsinit(),这样才能保证后续的程序正常使用有关文件系统的系统调用(比如initcode中的exec())。

















 398
398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









