






记录自己的学习而已,防止后续自己找不到自己的代码
test1
文件说明:21个lammpstrj文件每个文件前9行都是一些文件的说明,有10000条数据
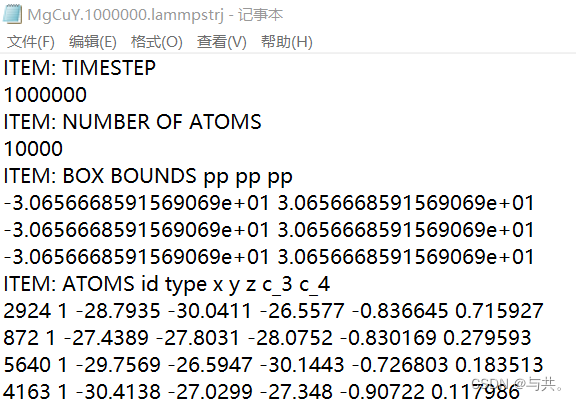
处理要求:1.以id排序;2.作图
# 1处理第一个需求,就是将文本文档分割,导出成文件
import pandas as pd
import glob
import matplotlib.pyplot as plt
import math
import numpy as np
#导入所需包#读入文件,将每个文本文件以空格分割开,并且得到一个已经分割好的列表,一行一行地读,一行为一个列表中的一个元素,并且一个元素又是一个
#列表,每个小列表里面包含分割好的数据,like:[[],[],[]]
def readTxt1():
data = []
with open("D:\\Astudy\\studydata\\test1\\MgCuY.1100000.lammpstrj","r") as f:
for line in f.readlines():
line = line.strip("\n")
line = line.split()
data.append(line)
print(data)
return data
list1 = readTxt1()
list2 = list1[0:9]
name = ["id","type","x","y","z","potential","kinetic"]
newtable = pd.DataFrame(columns=name,data=list2)
newtable.to_csv("D:\\Astudy\\studydata\\test1csv\\MgCuY.1000000.csv",index=False)
#list1是的得到一个列表,就是那个很大的列表
#list2是取list1的前9行,因为前9行不是数据,只是一些说明
#name是定义的10000个数据的每一列数据的名称
#newtable是生成一个dataframe,其表头是name,数据是list2
#将这个生成的dataframe输出至文件夹中,注意文件要加双斜杠
csv1 = pd.read_csv("D:\\Astudy\\studydata\\test1csv\\MgCuY.1000000.csv")
csv2 = csv1.sort_values("id")
csv2.to_csv("D:\\Astudy\\studydata\\test1csv\\MgCuY.1000000.csv",index=False)
#csv1是读入刚刚保存的csv文件
#csv2是以id的大小按行来排序
#将排序好的数据输出到文件夹中,注意,是覆盖了未排序的文件def readTxt1():
data = []
with open("D:\\Astudy\\studydata\\test1\\MgCuY.1500000.lammpstrj","r") as f:
for line in f.readlines():
line = line.strip("\n")
line = line.split()
data.append(line)
print(data)
return data
list3 = readTxt1()
list4 = list3[0:9]
data1 = pd.DataFrame(list4)
csv1 = pd.read_csv("D:\\Astudy\\studydata\\test1csv\\MgCuY.1500000.csv")
data2 = data1.append(csv1)
data2.to_csv("D:\\Astudy\\studydata\\test1csv1\\MgCuY.1500000.csv",index=False)
#采用一样的步骤先把前9行取出来弄成一个dataframe,再读出排好序的csv文件弄成一个dataframe,将两个dataframe进行连接后得到一个新的datdaframe
#把这个新的dataframe输出到文件夹中
#注意输出成新的csv文件的时候,务必写上index=False,只有加上这个才能表示不要最左边的索引tableone = pd.read_csv("D:\\Astudy\\studydata\\test1csv\\MgCuY.1000000.csv")
seriesx = tableone.x
seriesy = tableone.y
seriesz = tableone.z
seriessum = pd.concat([seriesx, seriesy,seriesy],axis=1, keys=['x', 'y','z'])
#由于算平均位移需要计算每个原子的xyz坐标,所以先取出这个3个坐标并用这三个值来进行计算
qucha = seriessum.diff()
squaresum = qucha.applymap(lambda x : x*x)
squaresum['Col_sum'] = squaresum.apply(lambda x: x.sum(),axis=1)
squaresum['kaifang'] = squaresum['Col_sum'].apply(lambda x: np.sqrt(x))
#dataframe.diff()函数表示的是按行做差,后一行减去前一行,第一行的数据就是NaN,如果想要以列来作差,那就在括号里面加一个默认参数:axis=1
#squaresum是计算了作差后的数据的平方,昨晚这一步得到的squaresum就是已经是每个取差后的数据平方后的dataframe,因为指定了applymap,意思就是
#每个数据都要进行相同的计算,就是整个dataframe的数据都要进行平方。
#squaresum['Col_sum']是在squaresum的最后加一列Col_sum,这一列Col_sum的数据就是每一行的和,因为指定了apply,所以只是对行进行计算而不是整个
#表格的数据进行计算,并且,为什么是行计算而不是列计算?因为指定了axis=1,如果不指定则默认为0,
#axis: {0 或 ‘index’, 1 或 ‘columns’}, 默认 0函数所应用的轴:
#0 或 ‘index’: 对每一列应用函数;1 或 ‘columns’: 对每一行应用函数。
#squaresum['kaifang']也是在squaresum最后加了新的一列,是对Col_sum这一列进行开方计算。
weiyi=float(squaresum['kaifang'].sum())
pjweiyi = weiyi/9999
#计算总的平均位移,加和求平均,一万个数据只有9999个位移
print(pjweiyi)
listsum = []
listsum.append(pjweiyi)
listsum
#设置一个list用来装总的原字平均位移,后续计算第二个之后继续用.append函数添加每一个文件的平均位移,有21个文件,就21次,重复的时候不要写入listsum = [],然后修改文件名称,下面的代码段同理
#计算第一类原子的平均位移,方法一样,只是取值不一样,指出了type为1的类型来计算,并且求平均的时候是(len(squaresum)-1)
table1 = pd.read_csv("D:\\Astudy\\studydata\\test1csv\\MgCuY.1000000.csv")
seriesx = table1.x[table1['type']==1]
seriesy = table1.y[table1['type']==1]
seriesz = table1.z[table1['type']==1]
seriessum = pd.concat([seriesx, seriesy,seriesy],axis=1, keys=['x', 'y','z'])
qucha = seriessum.diff()
squaresum = qucha.applymap(lambda x : x*x)
squaresum['Col_sum'] = squaresum.apply(lambda x: x.sum(),axis=1)
squaresum['kaifang'] = squaresum['Col_sum'].apply(lambda x: np.sqrt(x))
weiyi=float(squaresum['kaifang'].sum())
pjweiyi = weiyi/(len(squaresum)-1)
print(pjweiyi)
list1 = []
list1.append(pjweiyi)
list1table1 = pd.read_csv("D:\\Astudy\\studydata\\test1csv\\MgCuY.1000000.csv")
seriesx = table1.x[table1['type']==2]
seriesy = table1.y[table1['type']==2]
seriesz = table1.z[table1['type']==2]
seriessum = pd.concat([seriesx, seriesy,seriesy],axis=1, keys=['x', 'y','z'])
qucha = seriessum.diff()
squaresum = qucha.applymap(lambda x : x*x)
squaresum['Col_sum'] = squaresum.apply(lambda x: x.sum(),axis=1)
squaresum['kaifang'] = squaresum['Col_sum'].apply(lambda x: np.sqrt(x))
weiyi=float(squaresum['kaifang'].sum())
pjweiyi = weiyi/(len(squaresum)-1)
print(pjweiyi)
list2 = []
list2.append(pjweiyi)
list2table1 = pd.read_csv("D:\\Astudy\\studydata\\test1csv\\MgCuY.1000000.csv")
seriesx = table1.x[table1['type']==3]
seriesy = table1.y[table1['type']==3]
seriesz = table1.z[table1['type']==3]
seriessum = pd.concat([seriesx, seriesy,seriesy],axis=1, keys=['x', 'y','z'])
qucha = seriessum.diff()
squaresum = qucha.applymap(lambda x : x*x)
squaresum['Col_sum'] = squaresum.apply(lambda x: x.sum(),axis=1)
squaresum['kaifang'] = squaresum['Col_sum'].apply(lambda x: np.sqrt(x))
weiyi=float(squaresum['kaifang'].sum())
pjweiyi = weiyi/(len(squaresum)-1)
print(pjweiyi)
list3 = []
list3.append(pjweiyi)
list3#经过上面的操作,可以得到四个list:listsum,list1,list2,list3,将这四个list拼接成一个allsum的dataframe
allsum = pd.concat([pd.DataFrame(listsum),pd.DataFrame(list1),pd.DataFrame(list2),pd.DataFrame(list3)],axis=1)
allsum.columns = ['all','Mg','Cu','Y']
#修改表头名称
## 2.2作图、保存
ax = allsum.plot(kind = "bar",title = "figure" ,grid = True, ylim = [37,41.5])
ax.set_xlabel("files")
ax.set_ylabel("dis")
fig = ax.get_figure()
plt.show()
fig.savefig("D:\\Astudy\\studydata\\test1displace\\allsumdis.png")最后得到的图片就是这样样子。















 1821
1821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









