







 本文基于kaggle上的电商数据集进行分析,涵盖了数据清洗、退货情况研究以及客户RFM分析。在数据清洗阶段,处理了Description字段的缺失值和CustomerID的空值。对于退货,通过创建quantity_canceled标签来跟踪退货量,发现1月和12月的退货率较高可能与节假日购物有关。在RFM分析中,根据客户最近购买时间、购买频率和消费金额进行了客户分类,有助于理解客户行为和价值。
本文基于kaggle上的电商数据集进行分析,涵盖了数据清洗、退货情况研究以及客户RFM分析。在数据清洗阶段,处理了Description字段的缺失值和CustomerID的空值。对于退货,通过创建quantity_canceled标签来跟踪退货量,发现1月和12月的退货率较高可能与节假日购物有关。在RFM分析中,根据客户最近购买时间、购买频率和消费金额进行了客户分类,有助于理解客户行为和价值。
项目背景
这个数据集是kaggle上面的一个电商数据集,其中包含2010年12月12日至2011年12月9日之间在英国注册的非商店在线零售的所有交易。该公司主要销售各种独特的礼品之类,其中许多客户该公司是批发商。因此本次数据分析将对客户进行分析,并对客户进行相关分层处理。
数据清洗
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
import warnings
import missingno as msno
warnings.filterwarnings('ignore')
data = pd.read_csv('data.csv',encoding = 'utf-8', dtype = {'CustomerID' : str})
data.head()
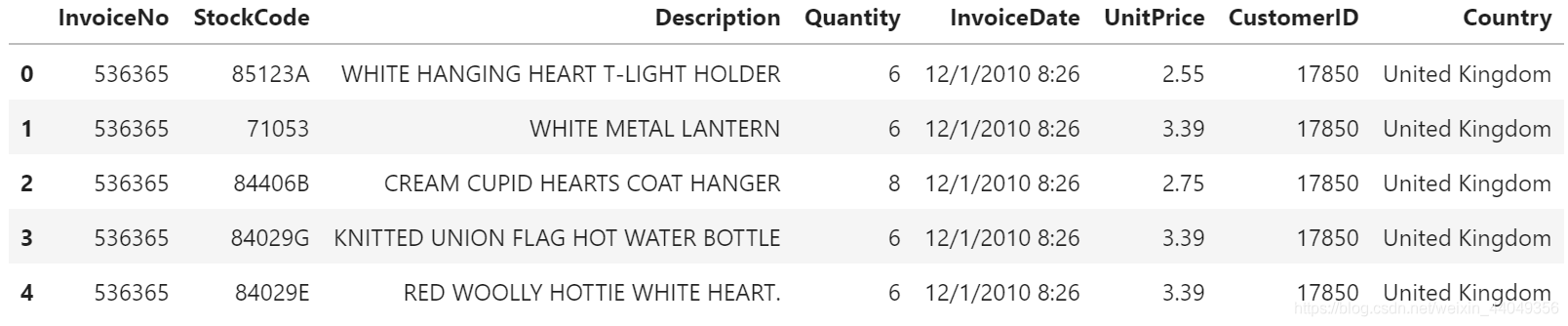
这就是data数据集的前五行。
接下来观看数据概况
data.describe()
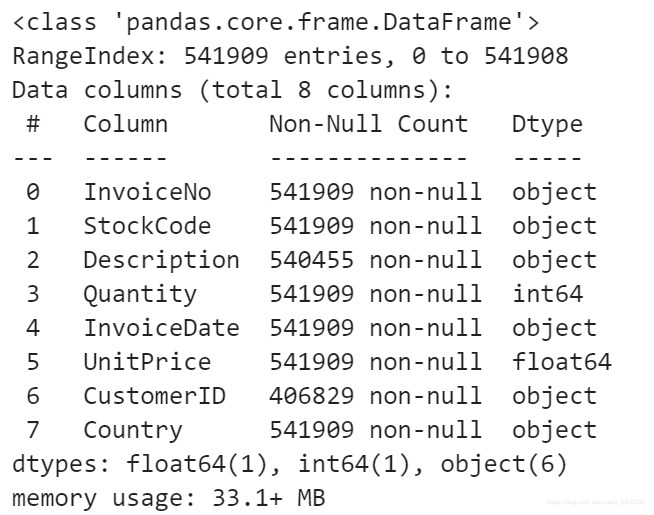
我们看到这里面Description和CustomerID字段都有相应的缺失,因此我们选择将这里面的数据进行处理。
首先我们选择将Description字段里面缺失的行删除,另外我们将CustinerID中确实字段填补为U。
data.dropna(axis = 0, subset = ['Description'], inplace = True)
data.CustomerID = data.CustomerID.fillna('U')
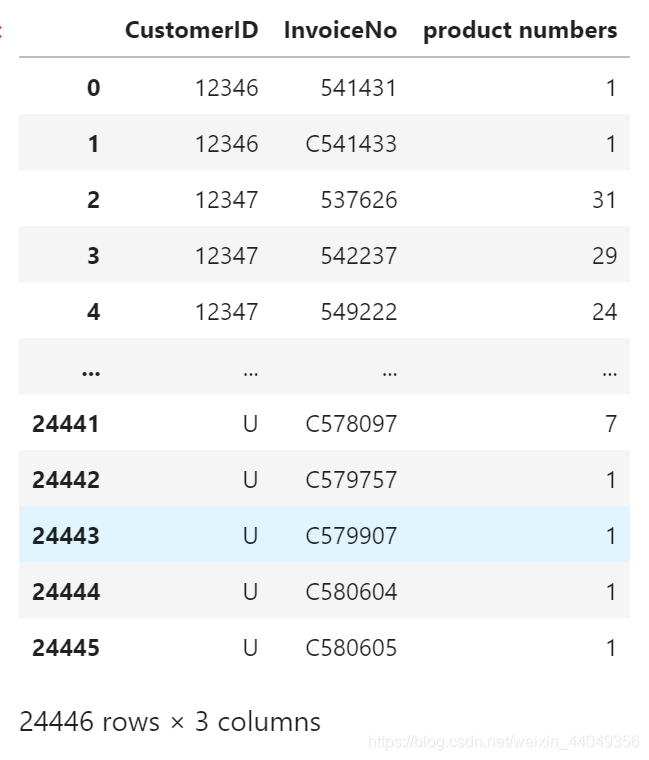
做好以上处理后我们看每个客户的每个订单的购买商品数量
temp = data.groupby(by=['CustomerID', 'InvoiceNo'], as_index=False)['StockCode'].count()
temp.rename(columns = {'StockCode': 'product numbers'})
退货情况分析
数据集标签InvioceNo里有一些编号包含’C’,这代表这些订单时退货订单,因此我们需要对这些退货订单进行处理。我们写一个函数,找出退货订单的原订单。这里面会有如下两种情况:
- 退货订单没有对应的原订单
- 退货订单存在一个或一个以上的原订单。
因此我们创建一个quantity_canceled的标签,用来记录每一个订单退货量,方便我们之后计算相应的单笔订单真实消费额。
data_cleaned = data.copy(deep = True)
data_cleaned['quantity_canceled'] = 0
unpaired_invoice = []
paired_invoice = []
for index, col in data.iterrows():
if col['Quantity'] > 0 or col['Description'] == 'Discount':
continue
#提取出和取消订单的商品配对的原订单
df_test = data[(data['CustomerID'] == col['Cu 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3382
3382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









