







目录
本专栏是团队进度的周报,会每两周更新一次团队在本项目上的进展,权当备份。
大语言模型部分
#阶段3 4月20日#
参考更大参数模型charglm-66B的用户手册,尝试学习了解LLM模型的api调用编写。
将具体的上下游任务工作流结合的代码封装成多个过程方法体以方便后续UI界面获得prompet和绘画模型api获取lora标签进行调用。
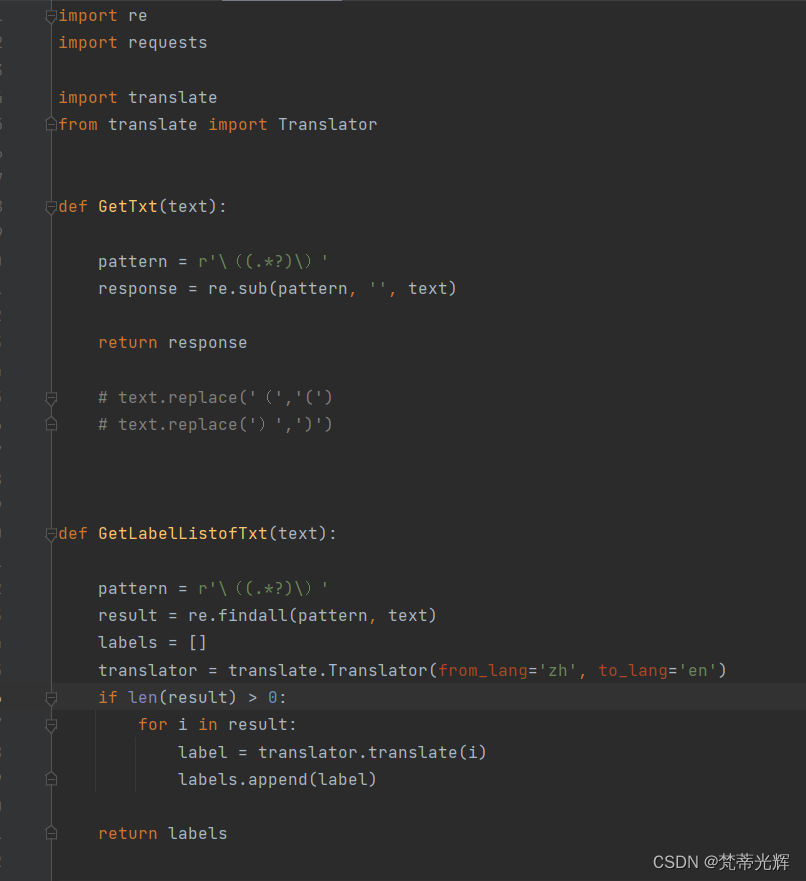

语音模型存在一定吞字问题,据考究应该是模型本身的影响。
语音克隆模型部分
上周初步实现了一遍GPT-SoVITS的流程,这周从wiki上下载了共30分钟的音频文件,完善语音模型。
按顺序依次下载分段语音并导入autoDL
接下来的流程和之前的一样,打标音频→一句句按着台本校对(虽然整合包的语音识别准确率很高,但是还是挨个复制粘贴了一遍)→训练→推理。
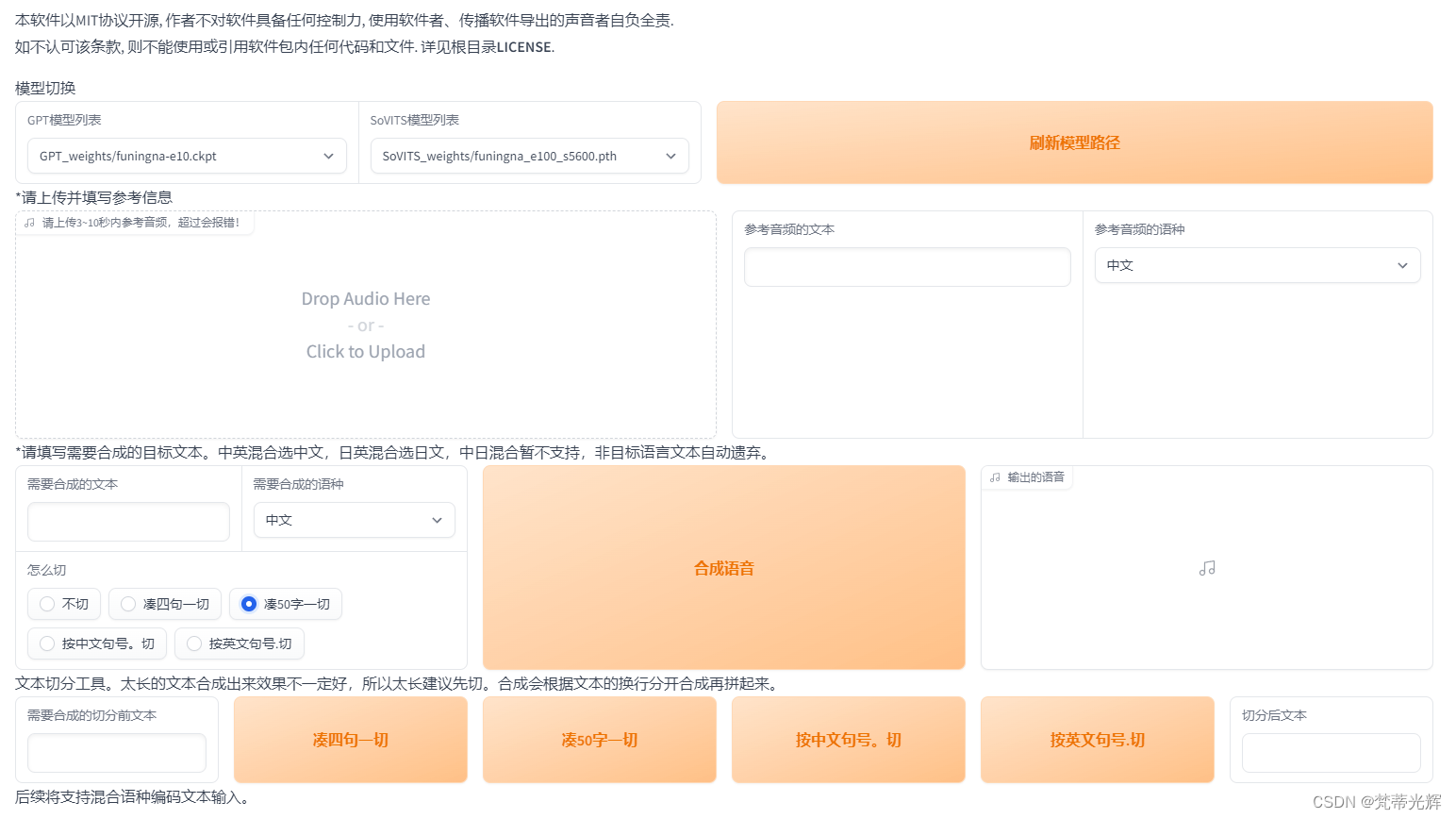
最后另存模型,与上次的模型进行比对。
结论是,扩大训练集的模型的咬字相比原模型更加自然,语气问题得到改善,但还是很大程度上依靠于参考模型。
以后可能会寻找更多的语音素材,以及改变步长等参数,寻找语音模型效果优化的方向。
图像生成模型部分
上一次工作成功部署了webui,并且调配出了满意的文生图效果,那么接下来就是向未来的前端提供一个方法,允许随时通过webui生成图片。这就不得不用到webui的API了。
根据webui官方仓库的Wiki,它已经提供了众多方法可供调用,其中就包括text2img文生图,且直接调用API可以充分设置各项参数,完美满足我们的需求。

带参数启动webui
根据wiki的指引,我在终端输入了带API启动的命令:
webui-user.bat --api接着打开http://127.0.0.1:7860/docs/,也即官方提供的API列表,然而却并没有找到上图的两个API。几经摸索,我在issue里找到了解法,编辑webui-user.bat文件,修改其中的启动参数行:
set COMMANDLINE_ARGS=--api在这里加入“--api”这一参数,并正常启动webui-user.bat,这才终于见到了text2imgapi。
借助第三方开源库调用API
官方在API文档里给出了许多可以直接调用的接口,但我选择采用第三方仓库sdwebuiapi来调用,这个库对官方的接口加以封装,使得调用起来更加简单粗暴了。这个库可以直接通过pip方便地安装,而Git仓库里也给出了使用的示例,用起来还是很轻松的。
工具齐全了,那就该敲点代码实际应用了。下面的代码提供了一个简单的方法,预先写死生图的参数(因为没有改变的需求),传入从GLM处提取到的角色表情描述文本,将这几段文本提示词插入prompt当中,接着调用API进行生图,最后把图片存储到本地并返回文件位置,以供前端后续使用。
import webuiapi
def draw_expression(charactor_expression):
# 本地部署的默认api
api = webuiapi.WebUIApi(host = '127.0.0.1',
port = 7860,
sampler = 'Euler a',
steps = 20)
# 调用api提供的txt2img接口,在通用prompt中插入从GLM处获取的表情描述
prompt = "(masterpiece, best quality:1), 1girl, solo, arisu, halo,"
for e in charactor_expression:
prompt += e + ','
prompt += "white background <lora:BlueSD:1>, <lora:tendouAliceV1:1>"
result1 = api.txt2img(prompt = prompt,
negative_prompt = "noisy, blurry, grainy,text, graphite, abstract, glitch, deformed, mutated, ugly, disfigured, (realistic, lip, nose, tooth, rouge, lipstick, eyeshadow:1.0), low contrast",
seed = -1,
styles = ["animate"],
cfg_scale = 8
)
# result1.image.show()
# 存储输出的图片,并返回文件名
if len(charactor_expression) == 0:
save_file_name = './outputs/output_no_expression'
else:
save_file_name = './outputs/output'
for i in charactor_expression:
save_file_name += '_' + i.replace(" ", "_")
save_file_name += '.png'
result1.image.save(save_file_name)
return save_file_name
test_expression = ['Greet happily', 'Rub your hands']
img_file_Location = draw_expression(charactor_expression = test_expression)
print('output image saved to ' + img_file_Location)万事俱备,启动webui,运行代码,可见在项目文件夹的指定位置果然得到了所需的图片。

用户界面部分
本周使用 Python 编程语言和多线程 socket 技术实现一个基本的聊天室服务器,包括登录、注册、发送消息和获取在线用户列表等功能。
技术实现
- Socket 编程:使用 Python 的 socket 模块来创建服务器端套接字,并监听客户端的连接请求。通过套接字进行数据的传输和通信。
- 多线程处理:为每个客户端连接创建一个独立的线程来处理请求,以实现并发处理多个客户端连接。
实现步骤
- 建立服务器套接字:使用 socket.socket() 函数创建一个服务器套接字,并绑定到指定的地址和端口。
- 接受客户端连接:使用 socket.accept() 函数接受客户端的连接请求,并创建新的线程来处理每个连接。
- 处理客户端请求:根据客户端发送的请求类型,执行相应的操作,包括登录、注册、发送消息和获取在线用户列表等。
- 并发处理:通过多线程技术实现并发处理多个客户端连接,确保服务器能够同时处理多个请求。
















 1161
1161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









