







大语言模型
为更改扮演角色额外添加了实时切换语音模型的功能,采用post上传至api完成任务
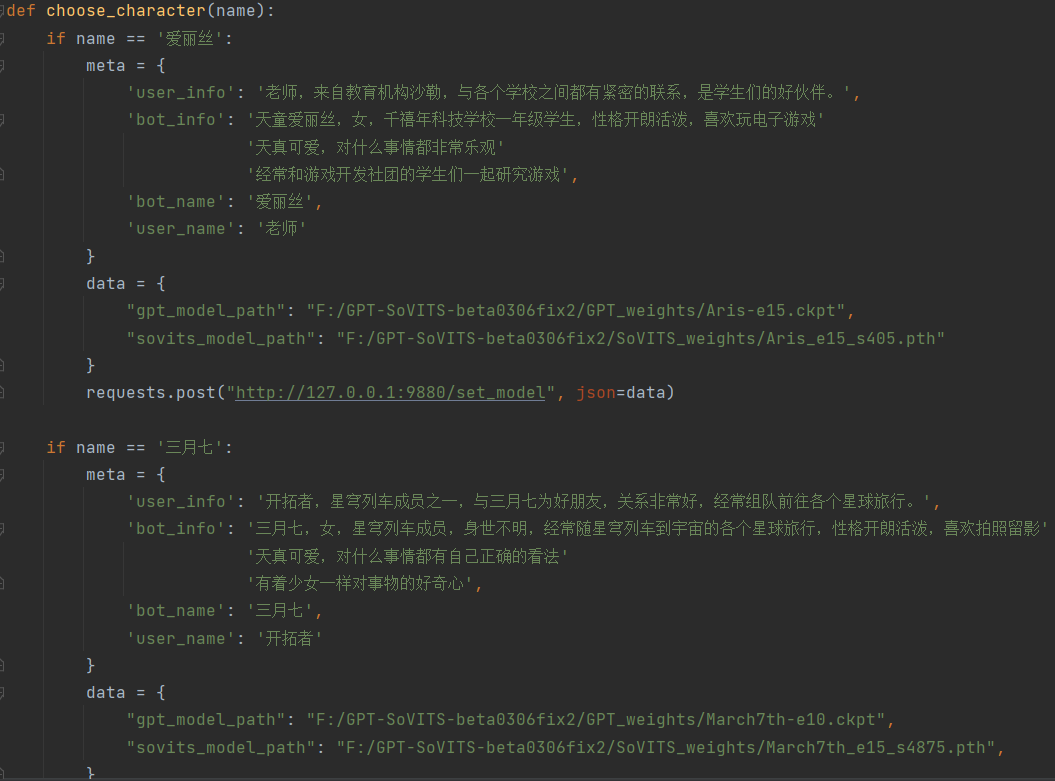
更新了大语言模型的接口调用,由于文档更新,charglm已经支持最新的接口调用方式,旧的仍然可以用,但是考虑到正则剔除文本括号和剔除转义符等操作简化,正式更新为新api接口调用方法和响应示例,同时更改键值对加入history list的方式
语音克隆模型
上周进行了三月七模型的初步训练。由于游戏剧情有配音,语音集相比爱丽丝要多很多,这周的目标就是充分利用这些语音,训练出一个更好的模型。
完整的语音集由B站@红血球AE3803收集并整合。该整合包括分段语音和对应的文本。
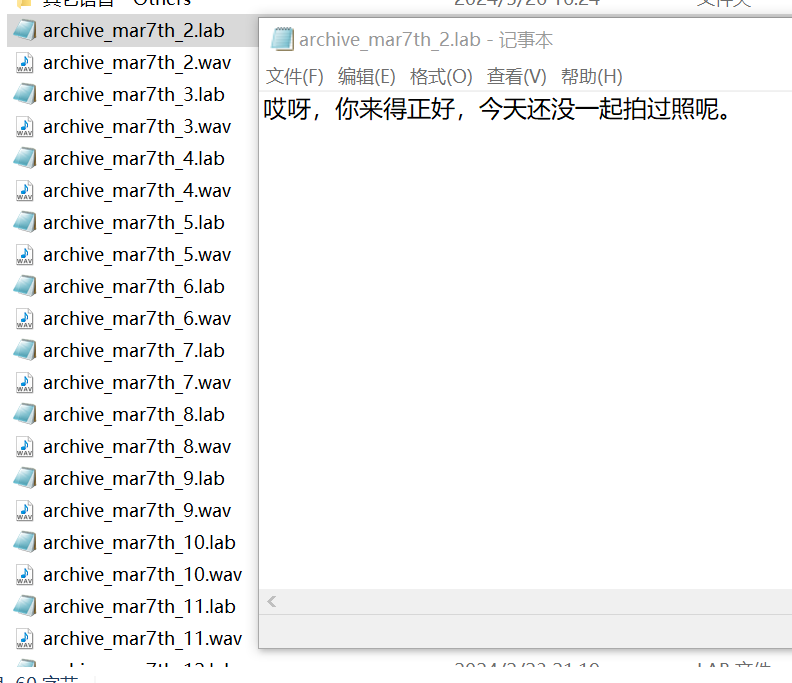
由于语音文本过于分散,编写了python脚本,使其组成了符合对应格式的list文本。

(虽然这个数据量和语音清晰程度,不用手动校对也能发挥作用)
然后再走一遍训练推理流程,训练出最后的sovits和GPT模型。
与上一周的模型相比,数据量成倍增加的模型效果更好,吞字破音电音得到了改善,语气也更加自然。
基于此数据集,正在考虑是否可以增加情感分类(参考情感分类训练,GPT-SoVITS情感特化模型效果及教程_哔哩哔哩_bilibili)不过根据视频来看,情感分类似乎优化并没有想象中的大,是否要分类有待商榷。
图像生成模型
上一次已经将调用API的环节基本收尾,相关的方法已经完备,现在我打算把API共享成公网的网址,以方便最后对接到UI。
根据网上的方法,我把webui.py中的share参数改为True,按理来说再次启动webui时就能拿到一个网址,但却出现了如下的报错:

估计是下载被墙了,没有下到对应的文件,但倒也指明了补救的方法,于是乎照办,成功得到了一个公网URL。
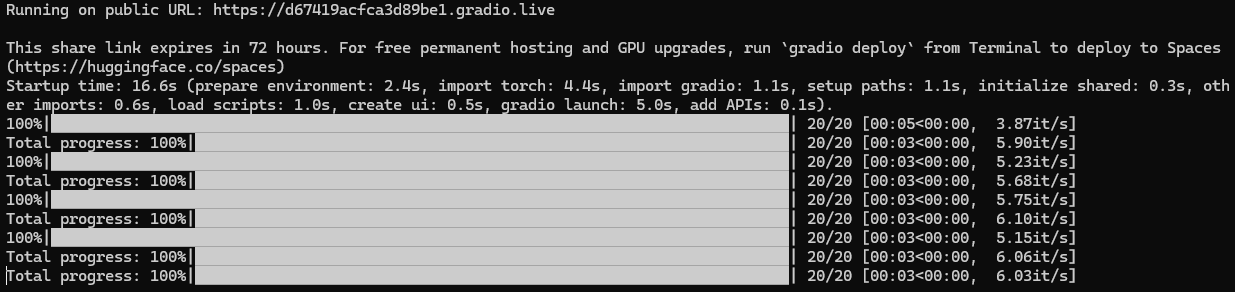
我尝试启动了两次,发现两次生成的网址是随机的,且同一个链接只能使用72小时,因此原来的代码也要做一定的修改,要解决两个问题:
- 把原来通过IP+端口的调用方式改为直接通过https链接调用;
- 在方法中加入网址链接参数,允许根据实时变更的链接调用API。
# 根据输入判断是否采用远端API
def generate_api_url(url):
if(url != '0'):
api = webuiapi.WebUIApi(baseurl= 'https://'+ url +'.gradio.live/sdapi/v1',
sampler = 'Euler a',
steps = 20)在另一台机器上测试,成功生成了全新的图片。

模型对接
尝试与stable-diffusion进行任务对接,同时完成了不同设备的文生图远程调用生成任务

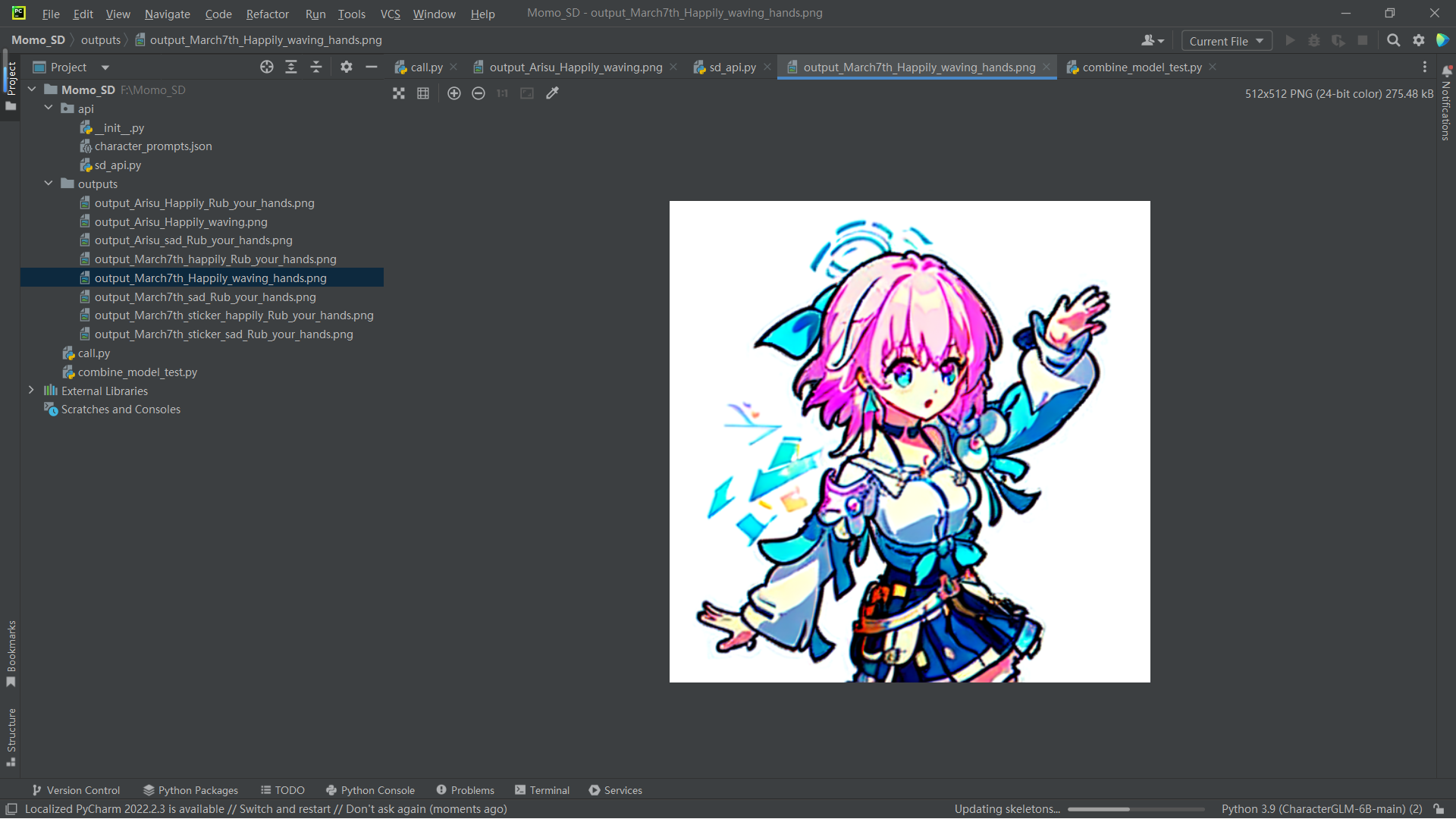
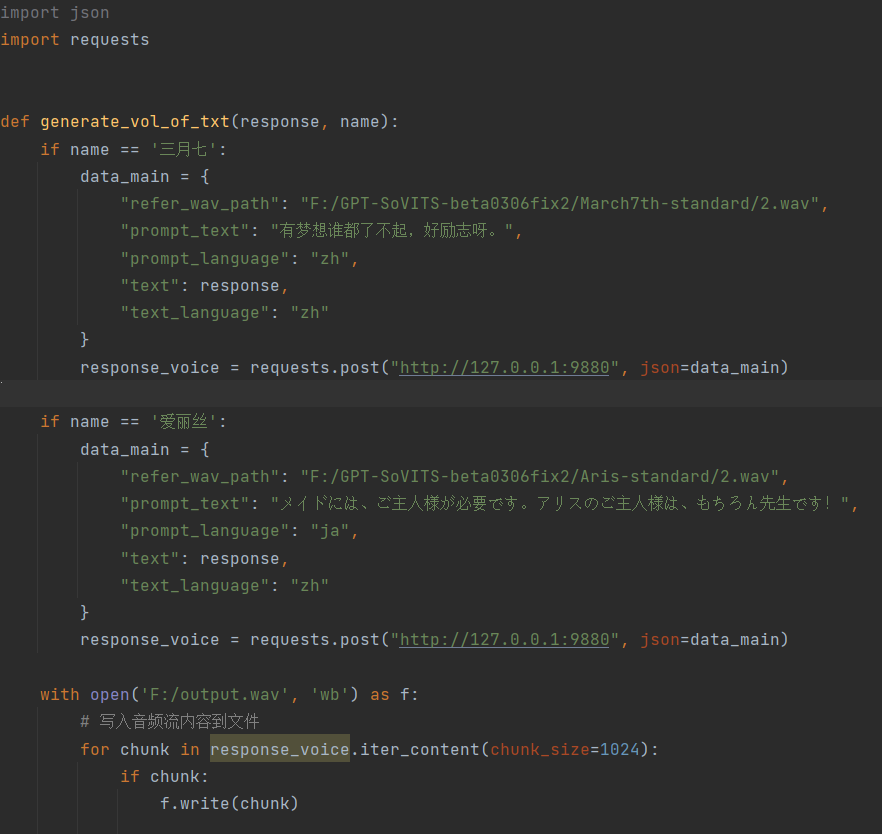
重新封装生成语音的方法体,考虑到频繁切换的性能消耗,将角色语音模型切换写到了choose_character方法中供app调用,位于LLMGenerate.py中,具体的任务实现单独写在VolumeGenerate.py中
用户界面
客户端程序初步实现了用户注册、登录、发送消息、接收消息等功能,
用户验证与注册
验证用户登录
def check_user(self, user, key):
self.sk.sendall(bytes("1", "utf-8"))
self.send_string_with_length(user)
self.send_string_with_length(key)
check_result = self.recv_string_by_length(1)
return check_result == "1"在check_user方法中,客户端首先发送请求类型“1”以表示登录请求。随后,客户端发送用户名和密码(通过send_string_with_length方法)。服务器返回一个长度为1的字符串,表示验证结果,“1”表示通过,“0”表示不通过。
注册用户
def register_user(self, user, key):
self.sk.sendall(bytes("2", "utf-8"))
self.send_string_with_length(user)
self.send_string_with_length(key)
return self.recv_string_by_length(1)注册方法与登录类似,只是请求类型变为了“2”。同样地,客户端发送用户名和密码,并接收服务器返回的结果。“0”表示注册成功,“1”表示用户名已存在,“2”表示其他错误。
消息发送与接收
发送消息
def send_message(self, message):
self.sk.sendall(bytes("3", "utf-8"))
self.send_string_with_length(message)发送消息的方法相对简单,首先发送请求类型“3”,然后发送消息内容。
接收消息
接收消息部分稍显复杂:
def recv_all_string(self):
length = int.from_bytes(self.sk.recv(4), byteorder='big')
b_size = 3 * 1024
times = math.ceil(length / b_size)
content = ''
for i in range(times):
if i == times - 1:
seg_b = self.sk.recv(length % b_size)
else:
seg_b = self.sk.recv(b_size)
content += str(seg_b, encoding='utf-8')
return content在recv_all_string方法中,首先从服务器接收一个4字节的长度值,然后根据这个长度值循环接收数据块,直到完整接收所有内容。这种方法可以处理变长字符串,确保数据的完整性。
客户端功能函数
除了核心的类方法,客户端还实现了一些功能函数用于处理UI逻辑和与用户的交互:
复制代码
def send_message():
content = main_frame.get_send_text()
if content == "" or content == "\n":
print("空消息,拒绝发送")
return
main_frame.clear_send_text()
client.send_message(content)该函数用于处理发送消息的按钮点击事件,首先获取用户输入的消息内容,如果内容为空,则拒绝发送。否则,清空输入框并调用客户端的send_message方法。
处理消息接收的线程方法
def recv_data():
time.sleep(1)
while True:
try:
_type = client.recv_all_string()
if _type == "#!onlinelist#!":
online_list = list()
for n in range(client.recv_number()):
online_list.append(client.recv_all_string())
main_frame.refresh_friends(online_list)
elif _type == "#!message#!":
user = client.recv_all_string()
content = client.recv_all_string()
main_frame.recv_message(user, content)
except Exception as e:
print("接受服务器消息出错,消息接受子线程结束。" + str(e))
break该方法在一个独立的线程中运行,用于持续接收服务器发送的消息。根据消息类型进行不同的处理,如更新在线用户列表或显示新的聊天消息。

















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









