







目录
本专栏是团队进度的周报,会每两周更新一次团队在本项目上的进展,权当备份。
大语言模型部分
添加了更改扮演角色的方法,可以供app界面调用,传回内容为meta键值对。
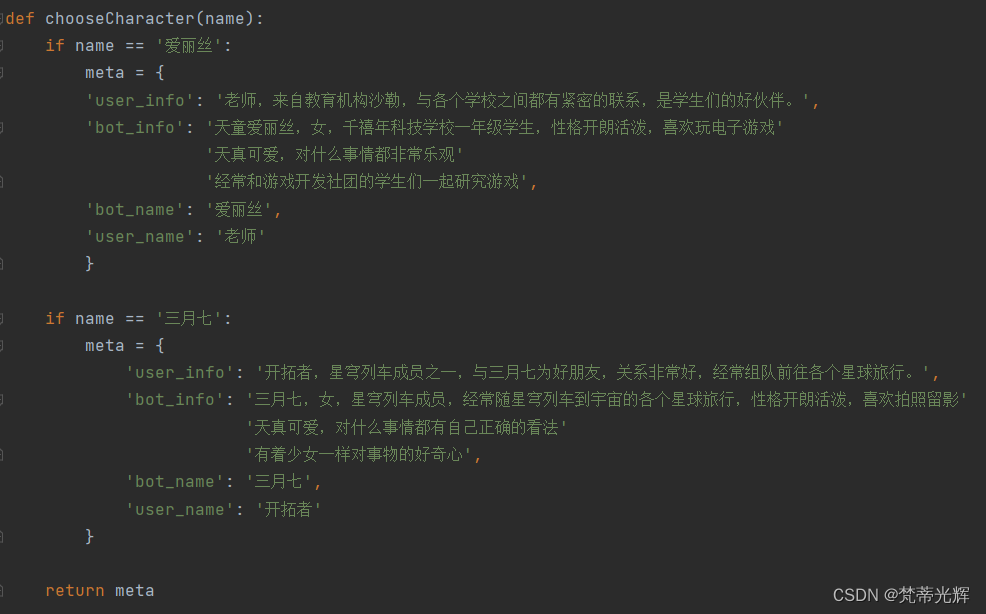
购买模型使用权,通过api进行大模型的远程调用,由于该大语言模型需要对话历史来稳定模型对话一致性,除开初次定义welcome-content外,每次都往prompt加入新的生成内容,并返回为可保存的字典list的history进行储存,每次新传入用户内容和history对话记录并调用方法即可。
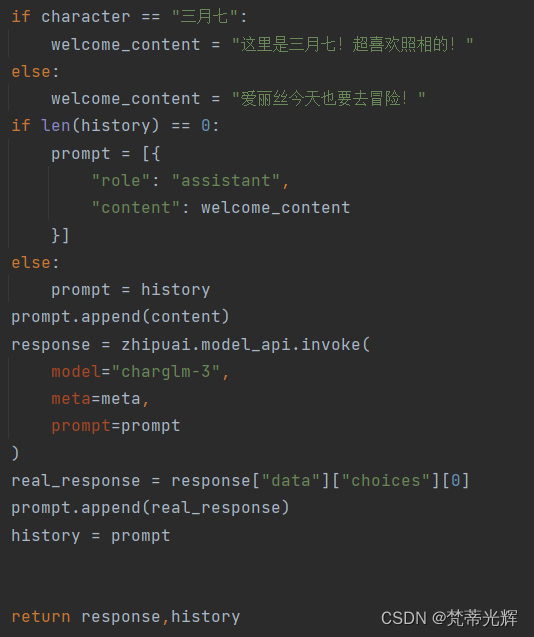
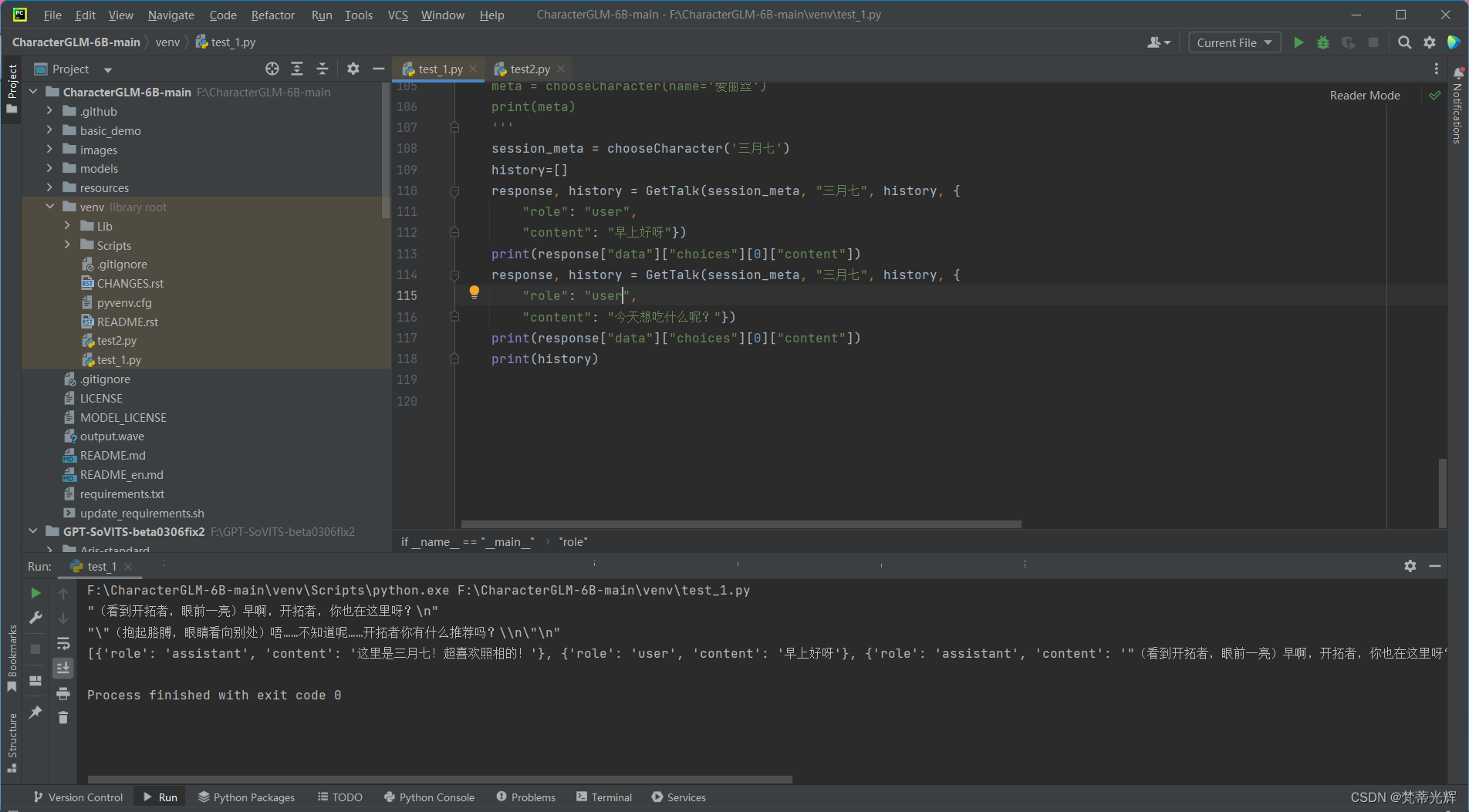
大模型返回内容content存在转义符的问题,继续通过GetTxt方法完善来剔除转义符并获得纯净的对话内容显示。
语音克隆模型部分
进度:新生成了两个语言模型,通过调整文本切分方式解决了模型的电音和咬字问题。
由于目标需要不止一个角色。于是在爱丽丝模型外,根据要求,训练了三月七的模型。
训练过程与爱丽丝的差不多,在wiki上寻找相应的文本和语音,下载导入,校对识别文本,训练sovits和GPT,再导入输入音频进行推理。
在推理的过程中,发现语音有一定的电音和咬字问题(模型的咬字一般偏窄)。经过一些调整后,发现如果将文本根据标点符号进行拆分(即,将符号处加换行处理)后,电音会得到大幅改善。
之后,为了更好地感受训练效果,又用了较为熟悉的角色阿米娅作为模型。阿米娅的语气较平稳,即使是训练后的语音也不容易产生违和感。
在训练后,将一句台词作为输出文本,输出语音。与原台词对应的语音对比后发现,模型语音的音色与角色有很高的相似度,但在情感上远不如真人的演绎。不过,如果在标点符号上加以暗示(如问号感叹号等),模型语音的情感倾向也比较明显。
图像生成模型部分
上一篇博文里实现了调用API来生成爱丽丝的图片,但这还不够,为了满足项目需求,还需要让程序能够自由调用多个角色的LoRA,所以这次,新角色三月七堂堂登场。

优化项目文件结构
在上一篇博文中,由于尚在测试,只是完成了一个简单的py文件,而最终对接时需要提供方法到客户端,因此我把调用api相关的功能全都封装到了子文件夹 ./api 下。

这时候在 call.py 中就可以方便地调用api了,为了接下来允许自由选择人物生图,我提前给生图方法加上了角色名的参数,从这里传参就能立马得到测试结果。
import api
characters = ["Arisu", "March7th_sticker", "March7th"]
test_expression = ['Happily', 'Rub your hands']
img_file_Location = api.SD_draw_expression(character_name = characters[0],character_expression = test_expression)
print('output image saved to ' + img_file_Location)Prompt的准备
由于不同的角色会有不同的Prompt,我决定采用Json文件来存储每个角色对应的Prompt,在生图过程中,把角色名和json文件进行比对,就可以获取到目标Prompt。
在civitai上查找三月七的LoRA,找到了普通版和Q版两个风格,不过这些LoRA当然天生和BA的画风不太协调,所以到时候写Prompt我会把BA风格的LoRA一并用上。
接下来我分别把他们写进了json,只要完善好新的生图方法就可以自由地调试:
{
"Arisu":[
{"prompt1": "(masterpiece, best quality:1), 1girl, solo, arisu, halo,"},
{"prompt2": "white background <lora:BlueSD:1>, <lora:tendouAliceV1:1>"}
],
"March7th_sticker":[
{"prompt1": "(masterpiece, best quality:1), 1girl, solo, pink_hair, chibi, pink_eyes, blue_eyes, multicolored_eyes, earrings,"},
{"prompt2": "white background <lora:BlueSD:0.8>, <lora:March_7th_Emote:1>"}
],
"March7th":[
{"prompt1": "(masterpiece, best quality:1), 1girl, solo, march7th, short hair, multicolored_eyes, pink hair, bangs, blue_eyes, long locks, ribbon earrings, shirt, skirt, choker, jacket,"},
{"prompt2": "white background <lora:BlueSD:1>, <lora:march7th:0.8>"}
]
}至于为什么每个角色有两段Prompt,前半段是角色的描述,后半段是画面背景和LoRA,而中间则是用于插入角色的表情和动作,主要是为了规范。
读取Json
用Python读取Json的方法很简单,这里不赘述,直接上代码:
import json
import os
def get_character_data(character_name):
# 从Json文件中找到对应角色,从而设置prompt
path = os.path.dirname(__file__)
with open(os.path.join(path, 'character_prompts.json'), 'r', encoding='utf8') as character_file:
character_data = json.load(character_file)
prompts = []
prompts.append(character_data[character_name][0]['prompt1'])
prompts.append(character_data[character_name][1]['prompt2'])
return prompts这个方法可以从同级目录下读取刚才的Json文件,并且根据传入的角色名获得该角色对应的两段Prompt,最后以数组形式返回给主方法,而主方法则只需要略微修改就能成功生图。
这一次的工作就以生成的图片告终了。

模型对接部分
目前考虑到生成语音任务的流程存在一定缺陷,主要问题在于如何分别定义和储存上下文所有的语音内容供实时调用,如果利用时间戳进行区分则不方便app查找并调用,考虑是否需要构建数据库或使用其他更快捷的方法。
用户界面部分
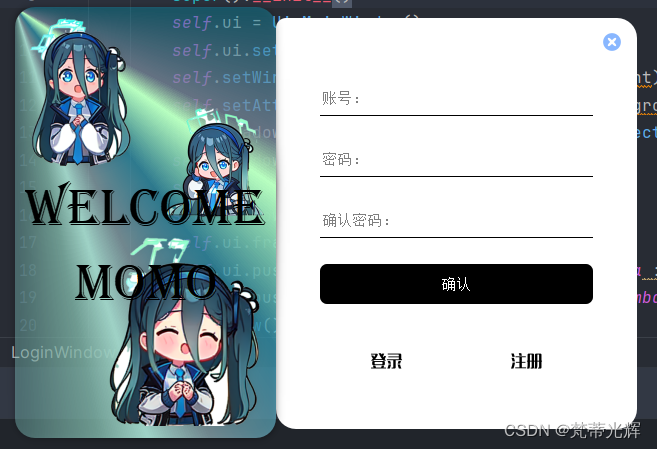
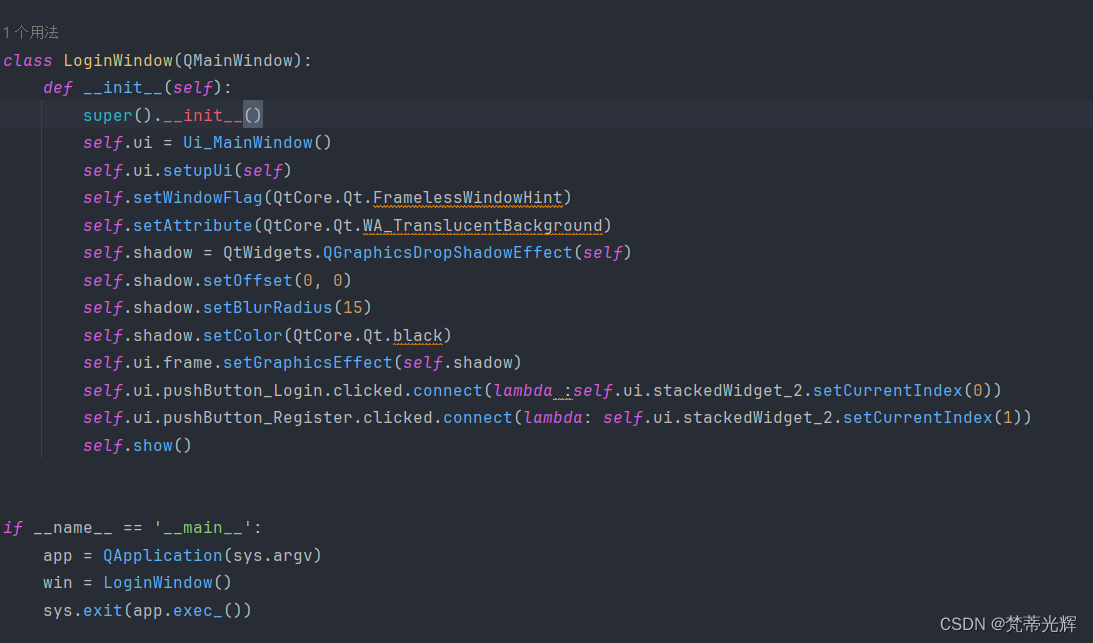
根据队友生成的图片进一步修改了登录界面,并给图像部分添加了阴影效果,世界上呈现3d感,同时为登录和注册按钮绑定了切换页面功能
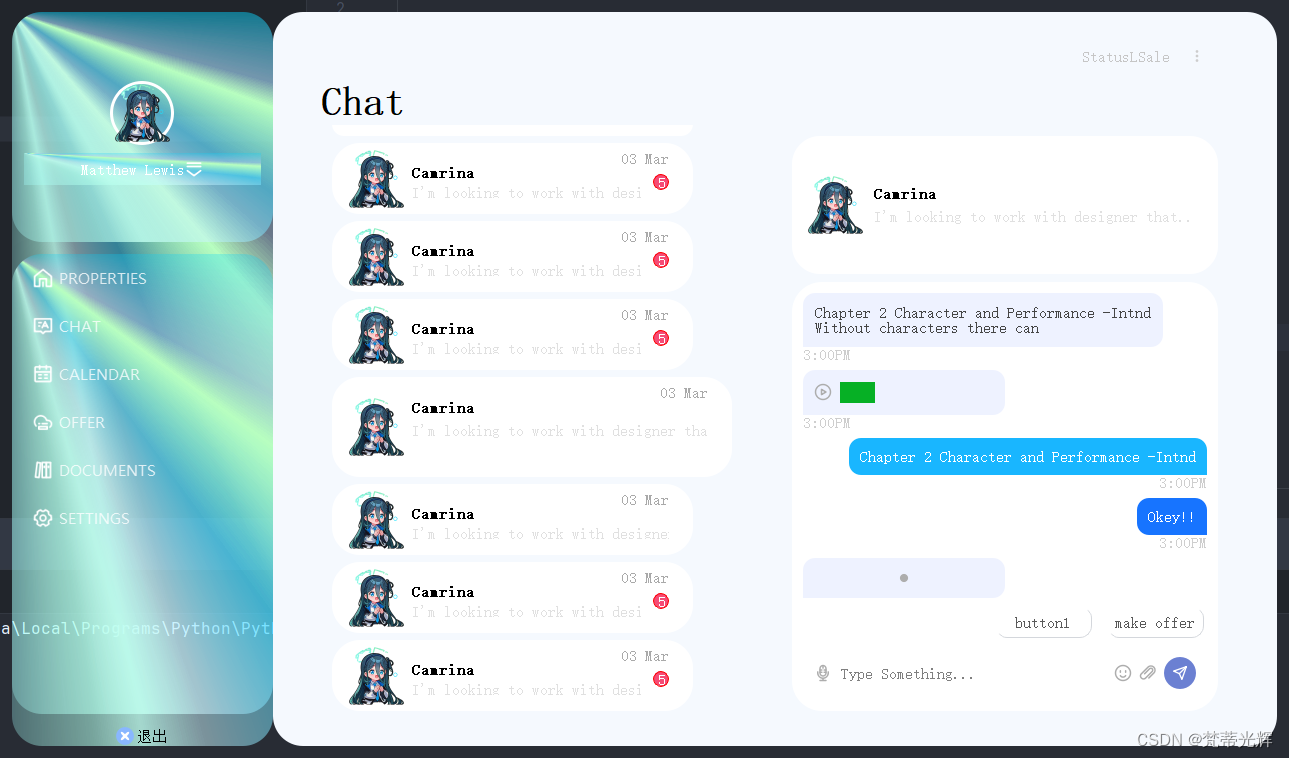
主页面目前根据网上界面参考,初步完成 了大致设置















 930
930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









