










目录
Introduction
我们认为文档层次结构H(例如DMOZ层次结构)是一棵树,其中内部节点(类别节点)和叶子节点(文档),以及连接它们的边是先验已知的。
关于DMOZ,网上搜到的一个dmoz网站进行了截图,不知道是不是这个意思。

H中的每个节点Ni被映射到一个多项词分布MultNi,而到 叶节点D(文档)的每个路径cd 与 出现在这条路径上的多项混合物(MultC0 . . . MultCk, MultD) 相关。(好长一句话
【原文(部分)】Each node Ni in H is mapped to a multi-nomial word distribution MultNi, and each path cd to a leaf node D is associated with a mixture over the multinonials (MultC0 . . . MultCk, MultD) appearing along this path.
被结合的混合部分 使用 一个混合比例向量(θC0…θCk),因此路径cd产生的字符w的可能性为:
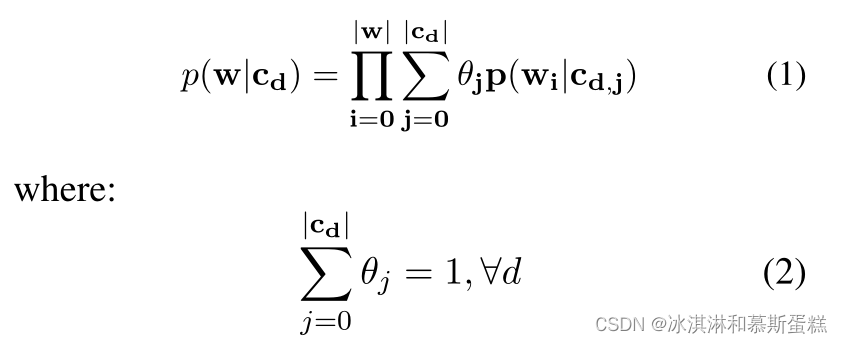 tips:这里的
θ
\theta
θ是混合比例,
θ
\theta
θi就是路径i的比例, p(wi|cd,j)应该是路径cdj下单词wi的概率。
tips:这里的
θ
\theta
θ是混合比例,
θ
\theta
θi就是路径i的比例, p(wi|cd,j)应该是路径cdj下单词wi的概率。
【原文(部分)】The mixture components are combined using a mixing proportion vector (θC0 . . . θCk), so that the likelihood of string w being produced by path cd is:…
作者提出了符合这个框架的两个模型,描述了它们如何允许p(wi|cd,j)和θ的推导,并给出了早期的实验结果,表明内容的显式层次信息确实可以用作内容建模目的的基础。
Information-Theoretic Approach
假设主题是先验已知的,这允许我们将主题签名(Topic Signatures)的概念扩展到分层设置。Lin和Hovy(2000)将Topic Signature描述为与目标概念高度相关的单词列表,并在标记数据上使用χ2估计器来决定将单词分配到主题。在这里,节点的子类别对应于主题。然而,由于层次结构是按照从泛型到特定的方式自然组织的,对于每个节点,我们选择在该节点的子节点之间具有最小辨别能力的单词。其基本原理是,如果一个单词能够很好地区分一个子节点和所有其他子节点,那么它就属于该子节点。
Word Assignment
该算法分两个阶段进行。在第一阶段,采用自底向上的方式遍历层次树,编译每个节点下的词频信息。在第二阶段,自上而下遍历层次结构,在每个步骤中,根据单词是否能够区分当前节点的子节点,将单词分配给当前节点。一旦一个单词被分配到一个给定的路径上,它就不能再分配到该路径上的任何其他节点。因此,在一条路径中,一个词总是具有它所指定的主题的含义。
【原文:】Once a word has been assigned on a given path, it can no longer be assigned to any other node on this path.
我还是蛮懵的,路径是不是 文档d到主题t之间的路径呢?一旦一个单词被分配到文档d到一个主题之间的路径,就不能再分配给其它节点,是不是就不能分配给这个主题到其他文档的路径的意思??那为什么说是“不能分配给该路径的其他节点??????”该路径还有什么节点啊???
Topic Definition & Mixing Proportions
根据最终的单词赋值,我们估计单词wi在主题Tk中的概率为:
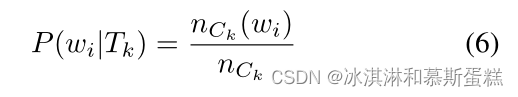
用nCk(wi)表示wi在Ck下的文档中出现的总次数,用nCk表示Ck下的文档中出现的总单词数。
==ck是路径,一个路径有多个文档???那这里的意思应该是:如 ck,j 表示路径从主题k出发,终点是文档k,那么ck就是从主题k出发的所有文档。 ==
给定单个词赋值,我们使用语料库级估计来评估混合比例,这是通过平均所有训练文档的混合比例来计算的。
HLLDA
我们考虑一种改进的分层LDA (Blei et al., 2010),其中底层树结构是已知的先验,不需要从数据推断。
该模型的生成故事,我们称之为分层标签lda (hLLDA),如算法1所示。

正如 Fixed Structure LDA,对于每个文档,用于推断的主题是从层次结构根到文档本身的路径上找到的主题。一旦目标路径cd∈H已知,模型就会在包含cd的主题集合上缩减为LDA。考虑到联合分布p(θ, z, w|cd)难以处理(Blei et al., 2003),我们使用collapsed Gibbs-sampling (Griffiths and Steyvers, 2004)来获得单个单词级别的分配。在所有其他单词赋值的条件下,将文档d中的第i个单词wi赋值给路径cd上的第j个主题的概率为:
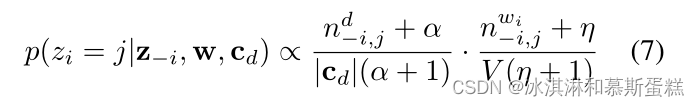
【原文(部分)】Once the target path cd ∈ H is known, the model reduces to LDA over the set of topics comprising cd. Given that the joint distribution p(θ, z, w|cd) is intractable (Blei et al., 2003), we use collapsed Gibbs-sampling (Griffiths and Steyvers, 2004) to obtain individual word-level assignments. The probability of assigning wi, the ith word in document d, to the jth topic on path cd, conditioned on all other word assignments, is given by:
其中,nd−i,j为文档d分配给话题j的词的频率,nwi−i,j为话题j中词wi的频率,α和η分别为路径-话题和话题词多项的Dirichlet参数,V为词汇量大小。方程7可以理解为将非标准化后置词级分配分布定义为当前水平混合比例θi与当前词-主题条件概率p(wi|zi)估计的乘积。通过对这个分布重复重新采样,我们获得了单个的单词赋值,这反过来使我们能够估计主题多项和每个文档的混合比例。
具体而言,主题多项估计为:
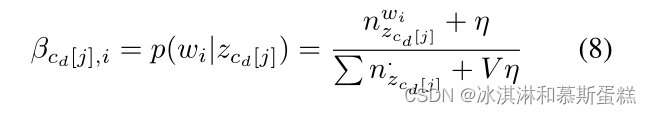
而每份文献的混合比例θd可以估计为:
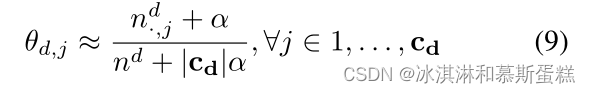
公式后面的也没怎么看懂,层次化到底怎么搞也是比较懵的,也没有搜到什么资料,还是比较少。如果有大佬发现问题请务必不吝赐教!















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









